Justinas Tamasevicius
Head of Engineering

Justinas Tamasevicius is Head of Engineering with over two decades of expertize in software development. What started as a self-taught passion during his school years has evolved into a distinguished career spanning backend engineering, system architecture, and infrastructure development.
In his current role, Justinas leads the engineering department, driving innovation and delivering high-performance solutions while maintaining a keen focus on efficiency and quality.
With deep technical expertize in software architecture, database optimization, and DevOps practices, Justinas has grown from a backend engineer into a versatile technology leader. He particularly enjoys tackling complex challenges in system performance optimization and developing automated solutions that streamline development processes.
When not immersed in the world of technology, Justinas finds balance in practicing Aikido and pursuing his musical interests. He's a nature enthusiast who loves tending to his garden and traveling to new destinations.
Connect with Justinas via LinkedIn.

How to Scrape Target Product Data: A Complete Guide for Beginners and Pros
Target is one of the largest retailers in the US, offering a wide range of products, from electronics to groceries. Scraping product data can help you track prices, monitor trends, or build comparison tools to enhance your purchasing decisions. This guide outlines the process, provides suggestions, and provides instructions on how to extract data, such as prices and ratings, efficiently.
Justinas Tamasevicius
Last updated: Jul 07, 2025
6 min read
Web Scraping With Java: The Complete Guide
Web scraping is the process of automating page requests, parsing the HTML, and extracting structured data from public websites. While Python often gets all the attention, Java is a serious contender for professional web scraping because it's reliable, fast, and built for scale. Its mature ecosystem with libraries like Jsoup, Selenium, Playwright, and HttpClient gives you the control and performance you need for large-scale web scraping projects.
Justinas Tamasevicius
Last updated: Nov 26, 2025
10 min read
How To Scrape Websites With Dynamic Content Using Python
You've mastered static HTML scraping, but now you're staring at a site where Requests + Beautiful Soup returns nothing but an empty <div> and <script> tags. Welcome to JavaScript-rendered content, where you get the material after the initial request. In this guide, we'll tackle dynamic sites using Python and Selenium (plus a Beautiful Soup alternative).
Justinas Tamasevicius
Last updated: Dec 16, 2025
12 min read

How to Scrape Zillow Data: Complete Guide for Real Estate Data
Zillow hosts millions of real estate listings across the U.S., but manually collecting that data is slow and error-prone. This guide walks you through how to scrape Zillow data effectively and ethically. You’ll learn what kind of data is accessible, which tools to use, and how to handle anti-scraping challenges to keep your pipeline running smoothly.
Justinas Tamasevicius
Last updated: Jun 23, 2025
6 min read
Methods, Tools, and Best Practices for Scraping Yahoo Finance
Yahoo Finance is one of the most comprehensive free financial data platforms available, offering real-time stock prices, historical data, and company fundamentals. However, scraping such a platform presents challenges like sophisticated anti-bot measures, JavaScript-heavy rendering, and dynamic content loading. This guide offers practical, tested methods for efficiently extracting Yahoo Finance data while navigating these obstacles.
Justinas Tamasevicius
Last updated: Oct 09, 2025
9 min read
How to Build Production-Ready RAG with LlamaIndex and Web Scraping (2026 Guide)
Production RAG fails when it relies on static knowledge that goes stale. This guide shows you how to build RAG systems that scrape live web data, integrate with LlamaIndex, and actually survive production. You'll learn to architect resilient scraping pipelines, optimize vector storage for millions of documents, and deploy systems that deliver real-time intelligence at scale.
Justinas Tamasevicius
Last updated: Oct 24, 2025
16 min read
Error Code 1010: Causes, Solutions, And Prevention For Cloudflare Users And Website Owners
Cloudflare’s Error 1010 can be a real headache for website owners and visitors. It usually appears when its security detects something unusual or automated, even if it’s a genuine request. In this article, we'll outline what the Error 1010 code means, why it occurs, how to identify it, and the best solutions to fix and prevent it.
Justinas Tamasevicius
Last updated: Oct 03, 2025
4 min read

How to Fix the “Your IP Address Has Been Banned” Error
Web scraping is one of the most effective ways to collect publicly available data at scale, but without the right infrastructure, it often leads to a familiar roadblock: the “Your IP Address Has Been Banned” error. This message means a website has blocked your IP address after detecting automated or unusually frequent requests. Fortunately, IP bans are both fixable and preventable. In this guide, we explain what causes IP bans during web scraping, how to recover when one happens, and the best practices for keeping your scraping operations running smoothly without interruption.
Justinas Tamasevicius
Last updated: Mar 23, 2026
6 min read

How to scrape eBay: Methods, Tools, and Best Practices for Data Extraction
eBay is the second-largest online marketplace in the US, and unlike traditional eCommerce platforms, it's an open marketplace where people auction cars, sell rare collectibles, and seal personal deals directly with buyers. That makes it one of the richest targets for web scraping and data extraction – you get access to auction bids, final sale prices, seller ratings, and historical records of what buyers actually paid, not just listed prices. In this guide, you'll learn how to scrape eBay with Python, covering the tools, methods, and best practices to extract data cleanly and at scale without getting blocked.
Justinas Tamasevicius
Last updated: Mar 30, 2026
23 min read
No-Code Web Scraper With Playwright MCP: How to Scrape Any Website With Playwright MCP
Playwright MCP is one of the most accessible ways to get started if you need data from a website but do not want to write scraping code. It enables an AI application or agent to control a browser, interact with web pages, and extract content just like a regular user would. In this article, you’ll learn what Playwright MCP is, how to set it up, and how to use it to scrape websites with natural language.
Justinas Tamasevicius
Last updated: Apr 14, 2026
14 min read

How To Set Axios POST Headers and Manage Headers Across All Request Types
Axios POST headers are one of the most important items for JavaScript developers working with HTTP. Configure them incorrectly, and your requests fail, authentication breaks, or data gets rejected. The good news? Axios gives developers several ways to manage headers, including inline on individual requests, globally via defaults, through reusable instances, and dynamically with interceptors. This guide explores how to use Axios to set headers across all request types, covering POST, GET, PUT, and DELETE requests, plus common pitfalls and fixes.
Justinas Tamasevicius
Last updated: Apr 22, 2026
22 min read

Puppeteer vs. Playwright: Which Tool Is Better for Web Scraping?
Puppeteer vs. Playwright is a real architectural decision for any production scraping project. The two libraries share a common origin: Playwright was built at Microsoft by engineers who previously worked on Puppeteer at Google. Yet they're different on browser coverage, language bindings, and scraping ergonomics. Performance, stealth, proxy integration, and parallel execution decide which tool fits your pipeline.
Justinas Tamasevicius
Last updated: Apr 24, 2026
8 min read

Golang Headless Browser: Complete chromedp Tutorial
A plain Go HTTP client only sees the HTML the server returns. That's enough for static pages. It breaks down when JavaScript renders the real content later, which is common on SPAs, infinite-scroll interfaces, and login-protected flows. chromedp solves that by driving Chrome or Chromium through the Chrome DevTools Protocol, or CDP, without a separate WebDriver layer. In this tutorial, you’ll set up chromedp, extract dynamic content, interact with pages, route traffic through proxies, run Chrome in Docker, and scale scraping with goroutines.
Justinas Tamasevicius
Last updated: Apr 30, 2026
16 min read
Minimum Advertised Price Monitoring: How to Build an Automated MAP Tracker in Python
Minimum Advertised Price (MAP) violations don't announce themselves. One day, your authorized retailer lists your product at $299. The next, a competitor screenshots their $199 listing and sends it to your entire channel. Manufacturers, brand managers, and eCommerce teams are running automated data pipelines because the case for external data is clearest when the alternative is catching violations three weeks late. In this article, we’ll walk through what MAP monitoring is, the legal distinctions that matter, and how to build a production-ready automated tracker in Python.
Justinas Tamasevicius
Last updated: Mar 20, 2026
16 min read
How To Find All URLs on a Domain
Whether you're running an SEO audit, planning a site migration, or hunting down broken links, there's one task you'll inevitably face – finding every URL on a website. It sounds simple, but it isn't. Search engines don't index everything, sitemaps are often outdated, and dynamic pages hide behind JavaScript. This guide walks you through every major discovery method, from quick Google search operators and no-code scrapers to custom Python scripts.
Justinas Tamasevicius
Last updated: Feb 09, 2026
16 min read
Elixir Web Scraping: A Practical Step-by-Step Guide
Elixir web scraping solves one of the hardest problems in high-volume data collection: concurrency without thread overhead. The BEAM virtual machine (Erlang's runtime) runs each HTTP request as a lightweight process, not an OS thread, so you can fetch thousands of pages concurrently. If a process crashes, the supervisor restarts it automatically. This guide builds a complete Elixir scraper from scratch, covering static pages, paginated targets, JavaScript-heavy sites, and anti-bot countermeasures.
Justinas Tamasevicius
Last updated: May 19, 2026
25 min read

AutoGPT Integration Guide: Set Up, Customize, and Connect Your AI Agents to External Data
Most AutoGPT tutorials stop at "get it running", but that's the easy part. The harder part that determines whether your agents are useful is connecting them to live data, and AutoGPT helps you fix that. This guide covers AutoGPT local setup, UI navigation, custom Python block development, and the integration patterns that turn AutoGPT into a production workflow tool.
Justinas Tamasevicius
Last updated: Apr 23, 2026
8 min read

How to Scrape IMDb Data: Step-by-Step Guide with Python
To scrape IMDb data with Python at scale, you work with the 6 data layers IMDb sends to the browser instead of parsing the rendered HTML. IMDb is a Next.js application sitting behind AWS Web Application Firewall (AWS WAF) Bot Control, and the data lives in JSON-LD blocks, hydration payloads, and an internal GraphQL endpoint. To reach any of them past IMDb's WAF, you need more than plain requests and a real User-Agent, and the rest of this guide builds the setup that holds up.
Justinas Tamasevicius
Last updated: May 26, 2026
25 min read
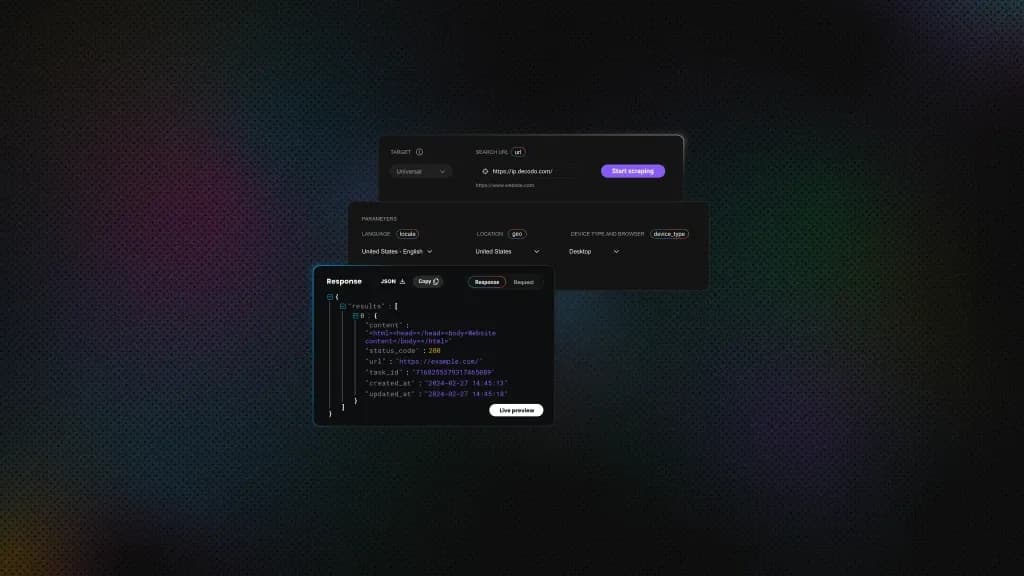
Ultimate Guide to Error 1020: Causes, Fixes, and Prevention
When the website's firewall security settings block your request, Error 1020 will appear. This means that the restriction has been enforced even before your device gets to the website. People using automation tools, website administrators, and ordinary internet users encounter this problem. This post will help you understand what causes it and how to fix it.
Justinas Tamasevicius
Last updated: Aug 12, 2025
8 min read

API vs. Web Scraping: How to Choose the Right Data Collection Method
Web data extraction typically follows two main paths: requesting through an API or directly scraping target pages. If you're building distributed data pipelines, your choice can impact scalability, reliability, and overall cost. In this guide, we'll explore what each path entails, provide a detailed comparison between them, and explain when to use APIs, web scraping, or both.
Justinas Tamasevicius
Last updated: May 27, 2026
12 min read

Open WebUI tools: how to give your local LLM real-time internet access with a scraping API
Local LLMs are powerful, but their knowledge ends at the training cutoff. Without internet access, a model running on your own hardware can’t check current prices, read recent news, or retrieve updated documentation. Open WebUI’s Tools system solves this by letting models call custom Python functions during a conversation. In this tutorial, you’ll connect the Decodo Web Scraping API to a custom Open WebUI tool, so your model can fetch live web content on demand.
Justinas Tamasevicius
Last updated: May 28, 2026
12 min read

Puppeteer Infinite Scroll: A Practical Scraping Guide
If you try to run curl on an infinite scroll page and then search (grep) for the content, the result will show zero matches. The required items aren't available in the initial HTML. The content is loaded using fetch requests that the page sends when a scroll event is triggered. This guide will cover: diagnosing the target, three scroll strategies, verification, speed, anti-detection methods, and a real-world walkthrough.
Justinas Tamasevicius
Last updated: May 29, 2026
25 min read

How to Use a Proxy for Telegram: Setup Guide for Android, iOS, Desktop, and Web
Telegram is a popular messaging platform, but it doesn’t come without privacy, security, speed, and availability challenges. To overcome these, you may opt to use a proxy for Telegram. If you’re in the market for a proxy that will be a perfect match for this platform, here is a full guide that explains when and why you’d need a proxy, available types, step-by-step setup instructions, troubleshooting, and security tips to access the app anywhere safely.
Justinas Tamasevicius
Last updated: Mar 19, 2026
9 min read

MechanicalSoup Python: A Complete Guide to Scraping, Forms, and Proxies
When you need to scrape 50 pages of search results behind a login wall, raw Requests + Beautiful Soup force you to track cookies and assemble form payloads by hand, while Selenium launches a full browser for pages that don't even use JavaScript. MechanicalSoup sits between those extremes. It wraps Requests and Beautiful Soup into a stateful browser that handles web scraping sessions, forms, and navigation automatically. This guide covers everything from installation to proxy-powered production scrapers.
Justinas Tamasevicius
Last updated: Jun 03, 2026
16 min read
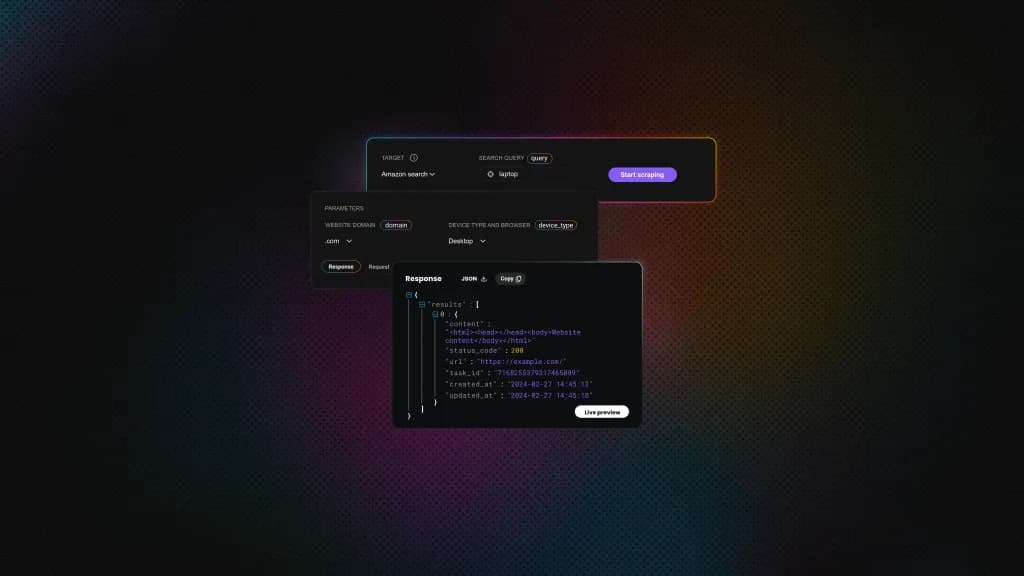
Scraping Yelp: A Step-by-Step Tutorial
Yelp doesn't make scraping easy. The data you need is spread across multiple backend systems (no single endpoint gives you everything), and standard HTTP libraries get blocked before the first response. This guide covers every extraction method with Python, including the TLS impersonation and anti-bot techniques you need to avoid blocks at scale.
Justinas Tamasevicius
Last updated: Mar 12, 2026
15 min read

How to Web Scrape a Table with Python: a Complete Guide
HTML tables are one of the most common ways websites organize data – financial reports, product listings, sports scores, population statistics. But this data is locked in the webpage's layout. To use it, you need to extract it. This guide will show you how to do it using Python, starting with simple static tables and working up to complex dynamic ones.
Justinas Tamasevicius
Last updated: Nov 10, 2025
9 min read

How to Scrape Websites with PowerShell: A Complete Guide
PowerShell is already where many Windows admins, DevOps teams, and automation-minded developers handle repetitive work. That makes web scraping a natural next step when you need product prices, uptime signals, public data for reports, or quick checks from the terminal. PowerShell works well here because output is pipeable, objects are native, and CSV and JSON exports are built in. In this guide, you'll build a scraper that fetches pages, parses HTML, handles pagination and errors, uses proxies when needed, and exports structured data.
Justinas Tamasevicius
Last updated: May 04, 2026
12 min read

How to Use a Proxy With node-fetch: Setup, Rotation, and Troubleshooting Guide
A node-fetch proxy routes your fetch requests through an intermediary server, so the target site sees the proxy's IP instead of yours. It's the standard fix for IP blocks, geo-restrictions, and rate limiting in Node.js scraping. The catch: neither node-fetch nor Node's native fetch supports proxies natively, so you need an external agent library to bridge the gap.
Justinas Tamasevicius
Last updated: May 26, 2026
9 min read

How to Bypass PerimeterX: Detection Methods, Tools, and Practical Workarounds
PerimeterX, now HUMAN, is a cybersecurity platform that employs multiple detection techniques to accurately identify and block threats to web applications. Since numerous high-traffic websites rely on PerimeterX, it's almost inevitable that developers will encounter it when web scraping. This guide explains how PerimeterX detects bots, how to bypass it (tools and strategies), and how to troubleshoot common failures.
Justinas Tamasevicius
Last updated: Apr 21, 2026
12 min read
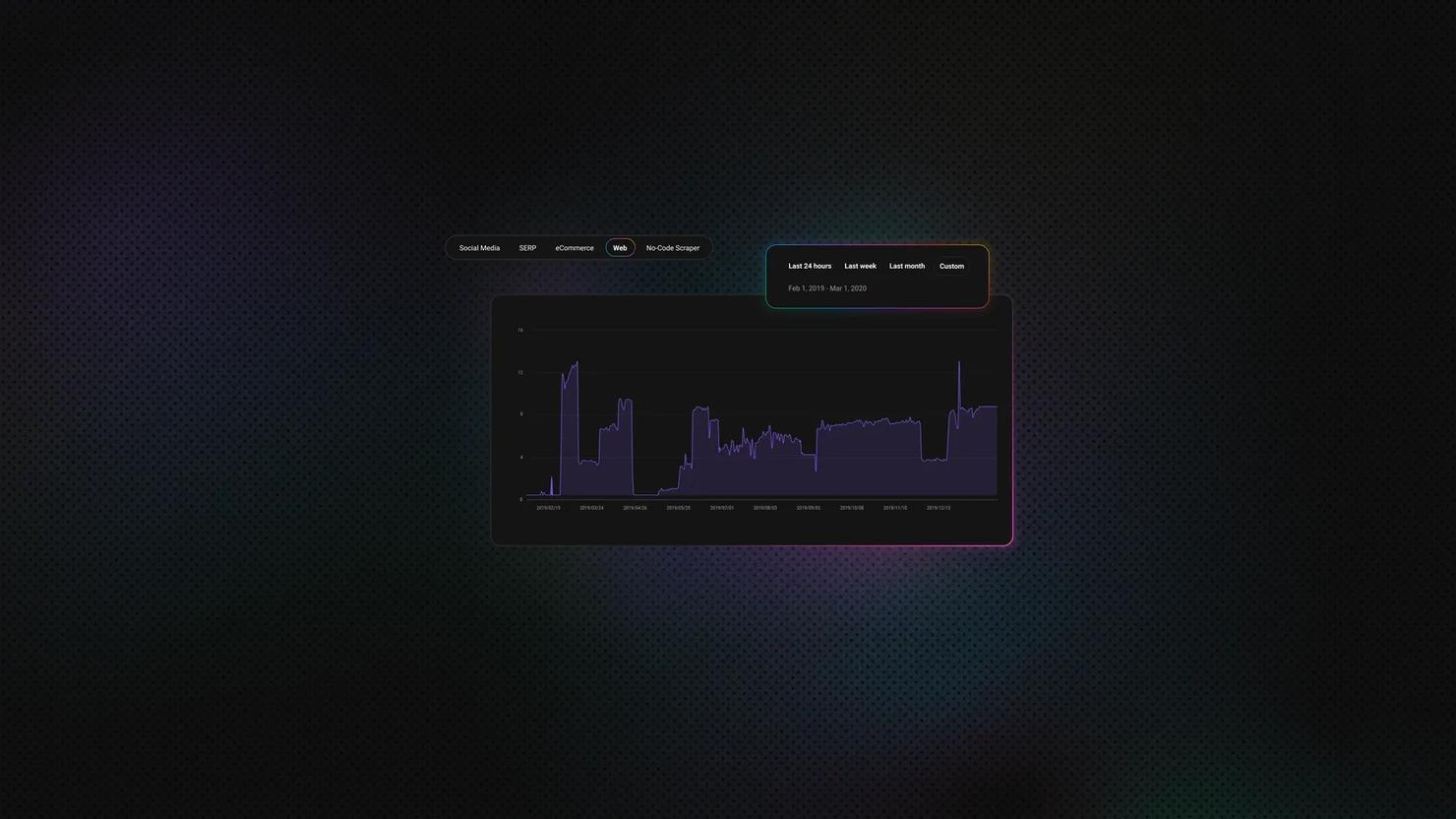
Web Scraping at Scale Explained
Scraping projects usually start simple: a Python script, the Beautiful Soup parsing library, and a list of URLs. That's enough for small jobs. Once you're past a few hundred thousand pages, you start hitting problems: timeouts, IP bans, parsers returning empty fields because someone changed a div to a span. At that point, it's not a coding problem anymore, it's an infrastructure problem. This guide covers the architecture, proxy management, anti-bot evasion, pipelines, costs, compliance, where the industry is headed, and build vs. buy decisions.
Justinas Tamasevicius
Last updated: Feb 18, 2026
10 min read
How to Automate Web Scraping Tasks: Schedule Your Data Collection with Python, Cron, and Cloud Tools
Web scraping becomes truly valuable when it is automated. It allows you to track competitor prices, monitor job listings, and continuously feed fresh data into AI pipelines. But while building a scraper that works can be exciting, real-world use cases require repeatedly and reliably collecting data at scale, which makes manual or one-off scraping ineffective.
Scheduling enables this by ensuring consistent execution, reducing errors, and creating reliable data pipelines. In this guide, you will learn how to automate scraping using 3 approaches: in-script scheduling with Python libraries, system-level tools like cron or Task Scheduler, and cloud-based solutions such as GitHub Actions.
Justinas Tamasevicius
Last updated: Apr 01, 2026
12 min read
Crawl4AI Tutorial: Build Powerful AI Web Scrapers
Traditional scrapers return raw HTML. Turning that raw data into structured AI-ready data takes 50%+ extra engineering time, and pushing it directly into an LLM quickly becomes expensive at scale. Crawl4AI was built for that gap: Playwright rendering, automatic Markdown conversion, and native LLM extraction in one open-source framework. This guide takes you from a basic page crawl to production-ready structured data extraction.
Justinas Tamasevicius
Last updated: Apr 15, 2026
15 min read

No-Code Web Scraping With n8n: Build Automated Data Workflows Without Writing Code
No-code web scraping with n8n lets you build automated scrapers on a visual canvas – no Python, no server, no terminal. You need prices tracked weekly or listings monitored daily, but can't code a scraper or run one. This guide shows you how to use only drag-and-drop nodes that run on schedule in the cloud.
Justinas Tamasevicius
Last updated: Jun 10, 2026
23 min read

Web Crawling vs Web Scraping: What’s the Difference?
When it comes to gathering online data, two terms often create confusion: web crawling and web scraping. Although both involve extracting information from websites, they serve different purposes and employ distinct methods. In this article, we’ll break down these concepts, show you how they work, and help you decide which one suits your data extraction needs.
Justinas Tamasevicius
Last updated: Jul 01, 2025
7 min read

500 Internal Server Error: Causes, Fixes, and How to Prevent It
A 500 Internal Server Error means the server encountered a generic internal error while processing your request. It's frustrating because the message is deliberately vague. This guide is for you if you run a website, build or maintain applications, or send programmatic requests, whether you are fixing your own site or dealing with 500s from external targets while collecting data from the web.
Justinas Tamasevicius
Last updated: May 05, 2026
9 min read

Watir Ruby: How To Automate Browsers and Scrape Web Data Step by Step
Watir is an open-source Ruby library for automating web browsers through code. Built on top of Selenium WebDriver, it wraps browser communication in a clean, Ruby-idiomatic API so you can focus on clicking buttons, filling forms, navigating pages, and extracting data without managing the underlying complexity. It's particularly useful for scraping JavaScript-heavy sites, automating form submissions, and collecting content that only appears after user interaction. This guide walks you through the full process, from setup to a working Watir scraper with proxy support.
Justinas Tamasevicius
Last updated: Jun 11, 2026
22 min read

How to Parse HTML With Regex: A Practical Guide
Yes, you can parse HTML with regex – but only for specific tasks. Regex works well on flat targets like meta tags, sitemap URLs, or inline JSON-LD. But on nested or JavaScript-rendered markup, it fails silently, and you often don’t notice until the data is already wrong. This guide explains when regex works on HTML and when it breaks, includes working Python for the common extraction tasks (meta tags, JSON-LD, bulk extraction), and covers when to switch to a parser or get past a page that blocks you.
Justinas Tamasevicius
Last updated: Jun 15, 2026
7 min read
How to Scrape ZoomInfo: A Complete Step-by-Step Guide
ZoomInfo is a goldmine for B2B teams – over 100M company profiles and 260M contacts, all in one place. But getting that data isn’t easy. With strict defenses like CAPTCHAs, browser fingerprinting, and aggressive IP bans, most scrapers fail after just a few requests. That’s where this guide comes in. We’ll show you how to bypass ZoomInfo’s countermeasures and extract clean, actionable data at scale.
Justinas Tamasevicius
Last updated: Jun 10, 2025
10 min read

OnlyFans Scraping: The Complete Guide 2026
In recent years, there has been a significant shift in the way content creators, influencers, and artists connect with their audience and monetize their talents. OnlyFans, a subscription-based social media platform, has emerged as a website that allows creators to share exclusive content directly with their dedicated followers for a subscription fee.
OnlyFans scraping, which involves extracting publicly available data from the website, has sparked an interest. In this blog post, we’ll delve into this scraping world, its possible use cases, and the benefits it offers. Excited to learn more? Buckle up, and let’s begin!
Justinas Tamasevicius
Last updated: Jan 15, 2026
6 min read

Block Requests in Puppeteer: A Practical Guide to Faster, Leaner Scraping
When you scrape the web with Puppeteer, you almost always pull in data you want alongside extras you don't need, like images, fonts, and tracking scripts that increase your request count, slow your pages, and drain your proxy bandwidth. In this guide, you'll learn how to block unnecessary requests with request interception and Chrome DevTools Protocol (CDP) so your scraper runs faster and scales more efficiently.
Justinas Tamasevicius
Last updated: Jun 16, 2026
16 min read

How to use a proxy with Ruby: configure, authenticate, and rotate with Net::HTTP and Faraday
As a Ruby developer, you must have used proxies for multiple applications, including web scraping, API integration, and geo-targeted testing. Without a proxy, every request leaves from the same IP, which is the fastest way to get rate-limited or blocked. In this guide, you'll learn how to configure a Ruby proxy with Net::HTTP and Faraday, add authentication, rotate IPs, and connect Ruby applications to Decodo residential proxies.
Justinas Tamasevicius
Last updated: Jun 26, 2026
7 min read

BotBrowser: What It Is, How To Set It Up, and Why It Matters for Fingerprint Defense
Browser fingerprinting allows websites to identify and track users across devices and sessions without relying on cookies. The W3C and major browser vendors flag it as a privacy threat that regulators are actively working to address. BotBrowser is an open-source, privacy-focused Chromium-based browser core designed to maintain a consistent fingerprint across operating systems. This guide covers its features, setup, validation, and practical use cases.
Justinas Tamasevicius
Last updated: Jul 01, 2026
8 min read

How To Scrape JSON Data in Python: Complete Tutorial
JSON is the format that most web APIs and modern websites use to send their data. This tutorial shows how to scrape JSON data in Python – fetching it, parsing it, modifying it, and exporting clean files. You'll also learn about the tools for messy or oversized responses, and how to get data when sites block you with fingerprinting.
Justinas Tamasevicius
Last updated: Jul 03, 2026
19 min read
Go vs. Python: A 2026 Developer's Guide
The Go vs Python comparison is a key discussion among developers. Go (Golang), created at Google, excels in performance, scalability, and concise syntax for distributed systems. Meanwhile, Python prioritizes readability and rapid development with a vast library ecosystem. Understanding these core differences is crucial for developers choosing tech stacks in 2026 and beyond. Let's dive in!
Justinas Tamasevicius
Last updated: Jan 13, 2026
9 min read
Python Web Crawlers: Guide to Building, Scaling, and Maintaining Crawlers
TL;DR: A web crawler is a program that systematically navigates the web by following links from page to page. Python is the go-to language for building crawlers thanks to libraries like Requests, Beautiful Soup, and Scrapy. This guide covers everything from your first 50-line crawler to a production-grade Scrapy setup with proxy integration, JavaScript rendering, and distributed architecture. If you've ever had to collect data from hundreds or thousands of pages and done it manually, this is for you.
Justinas Tamasevicius
Last updated: Mar 02, 2026
10 min read

Rebrowser: What It Is, How It Patches Playwright and Puppeteer, and How To Use It
Rebrowser is an open-source project that patches Playwright and Puppeteer to strip the automation signals that anti-bot systems detect. Its main target is the Runtime.Enable CDP command, which both libraries call by default and which vendors flag as automation. This article explains what the patches change, how to install and run them, and how to pair rebrowser with proxies.
Justinas Tamasevicius
Last updated: Jul 13, 2026
7 min read
undetected ChromeDriver in Python: Avoid Bot Detection When Web Scraping
Undetected ChromeDriver is a Python library that patches Selenium’s ChromeDriver to avoid bot detection when web scraping. Standard Selenium ChromeDriver is blocked by most protected websites within the first few requests: anti-bot services like Cloudflare, DataDome, and HUMAN (formerly PerimeterX) read automation flags, WebDriver properties, and browser-fingerprint gaps before the first page finishes loading. The undetected_chromedriver library works as a drop-in Selenium WebDriver replacement (swap webdriver.Chrome() for uc.Chrome()) and reduces those signals. But it does not hide your IP address, so this guide also shows how to pair it with residential proxies and behavioral techniques to stay unblocked.
Justinas Tamasevicius
Last updated: Jul 13, 2026
18 min read
JavaScript vs. Python: Which Is Better for Web Scraping in 2026?
Python and JavaScript are 2 languages that dominate web scraping, but for different reasons. The real question isn't which language is "better," but rather what task you're building for. This article compares both languages in terms of libraries, performance, support for dynamic content, and anti-bot strategies, while also showing why the overall architecture matters more than your language choice.
Justinas Tamasevicius
Last updated: Jul 14, 2026
8 min read

Web Scraping with Camoufox: A Developer's Complete Guide
If you're scraping with Playwright or Selenium, you've hit this. Your script works on unprotected sites, but Cloudflare, PerimeterX (HUMAN Security), and DataDome detect the headless browser and block it within seconds. Stealth plugins help, but each browser update breaks the patches. Camoufox takes a different approach – it modifies Firefox at the binary level to spoof browser fingerprints, making automated sessions look like real user traffic. This guide covers Camoufox setup in Python, residential proxy integration, real-world test results against protected targets, and when browser-level tools aren't enough.
Justinas Tamasevicius
Last updated: Mar 31, 2026
14 min read

Kasada Bypass: How to Get Past Kasada Anti-bot Protection in 2026
Kasada is a bot-mitigation service protecting ticketing, limited-release retail, and financial platforms. Unlike Cloudflare, Akamai, or HUMAN, it shows no CAPTCHA and runs a proof-of-work challenge that a real browser solves by loading the page. A Kasada bypass, therefore, starts with a browser, not an HTTP client. This guide covers detection, the 5 layers, the tools, and the DIY limit.
Justinas Tamasevicius
Last updated: Jul 20, 2026
10 min read
Puppeteer Download File: A Complete Guide for Node.js Developers
Puppeteer makes browser automation feel easy until you need to save a file to disk. Triggering a download in headless mode isn't the same as clicking a button in a real browser, and the default behavior in headless Chrome won't help you. This guide covers the full Puppeteer download file workflow: configuring CDP correctly, picking the right method for your scenario, detecting when a file truly finished, and scaling to batch jobs without leaking memory or corrupting your queue.
Justinas Tamasevicius
Last updated: Jun 08, 2026
25 min read
Puppeteer Form Submit: A Practical Guide to Reliable Form Automation
Submitting forms with Puppeteer goes beyond just clicking a button on the browser or typing text into an input box. Puppeteer is a Node.js library that can control a headless or headful Chromium (browser) instance through the DevTools Protocol. That means you can use Puppeteer to automatically locate form fields, fill input boxes with necessary values, trigger the action of submitting a form, and confirm whether that form submission actually worked. If you’re into web scraping, or you’re testing your own product, or even automating anything in a browser with JavaScript, you’ll inevitably run into form fields and submit buttons that you will need to get passed programmatically with Puppeteer.
Justinas Tamasevicius
Last updated: Jun 04, 2026
25 min read

Web Scraping With Perl: A Step-by-Step Guide for 2026
Web scraping with Perl is popular for elite text processing and superior execution speed. Perl has first-class regex built right into the language, no imports, no setup, which makes extracting structured data fast and precise. In this guide, you'll go from a Perl HTTP request to a scraper that fetches and parses web data, handles sessions, and exports data.
Justinas Tamasevicius
Last updated: Jul 22, 2026
21 min read
How to Scrape Glassdoor: Tools, Methods, and Tips
Every Glassdoor scraping tutorial that uses Selenium or Playwright fails for the same reason: Cloudflare anti-bot protection fingerprints the TLS connection and blocks non-browser traffic. Glassdoor has internal API endpoints that return the same structured JSON that the frontend uses, without rendering a page. Because these endpoints accept standard HTTP calls, you can bypass Cloudflare by calling them with Python and curl_cffi for browser-grade TLS fingerprinting, plus Decodo residential proxies for IP rotation. This guide covers 4 complete scrapers for reviews, jobs, interviews, and company profiles.
Justinas Tamasevicius
Last updated: Apr 13, 2026
15 min read
How to Scrape Indeed for Job Data: A Comprehensive Guide
Indeed hosts millions of job listings across industries and locations, making it a valuable data source for analysts, recruiters, data engineers, and founders who need real-time job intelligence. Scraping job data is challenging because sites change and anti-bot defenses evolve. This guide walks you through a resilient, modern approach that works reliably today – and scales when you need it to.
Justinas Tamasevicius
Last updated: Sep 12, 2025
14 min read
How to Scrape Wikipedia: Complete Beginner's Tutorial
Wikipedia has over 60 million articles, making it a valuable resource for machine learning training data, research datasets, and competitive intelligence. This tutorial guides you through extracting your first article to building crawlers that navigate Wikipedia's knowledge graph. You'll learn to extract titles, infoboxes, tables, and image references, then scale up to crawling entire topic clusters.
Justinas Tamasevicius
Last updated: Dec 16, 2025
23 min read
Asynchronous Web Scraping in Python: Build Faster Scrapers With asyncio and aiohttp
A scraper that fetches pages one at a time spends most of its time waiting on the network. Asynchronous web scraping in Python (built on asyncio and aiohttp) fixes that by handling many requests at once on a single event loop. This guide walks through building a working async scraper, then covers the proxy, retry, and anti-bot escalation patterns you'll need at scale.
Justinas Tamasevicius
Last updated: May 18, 2026
25 min read
Concurrency vs. Parallelism: Key Differences and When To Use Each
A bootstrapped data operation found that their web scrapers crawled to a halt as they tried to scale from 100 to 10,000 URLs. This is a common challenge with sequential processing and exactly why understanding concurrency vs parallelism is key to building efficient, scalable systems. This guide explains both concepts, their key differences, and limitations, so you can quickly decide the best mechanism for your project.
Justinas Tamasevicius
Last updated: Mar 10, 2026
10 min read

HTTPX vs. Requests vs. AIOHTTP: How to Choose the Right Python HTTP Client
Requests, HTTPX, and AIOHTTP all make HTTP requests, but they differ in how they handle concurrency. Requests is synchronous and has been the default since 2011. HTTPX gives you both sync and async with HTTP/2 support. AIOHTTP is async-only and faster at high concurrency, but has a steeper learning curve. The right choice depends on your async model, whether you need WebSockets or HTTP/2, and how much code you're willing to rewrite. This article covers architecture, performance data, proxy setup, migration paths, and common mistakes in production scraping setups.
Justinas Tamasevicius
Last updated: Mar 03, 2026
12 min read