Web Scraping API
Web Scraping API extracts structured data from websites at scale, combining 100+ pre-built templates with per-request control. Built for developers shipping AI applications, data pipelines, and automated workflows.
14-day money-back option

100+
pre-built templates
99.99%
success rate
200
requests per second
125M+
IPs worldwide
Free
starter plan
Trusted by:
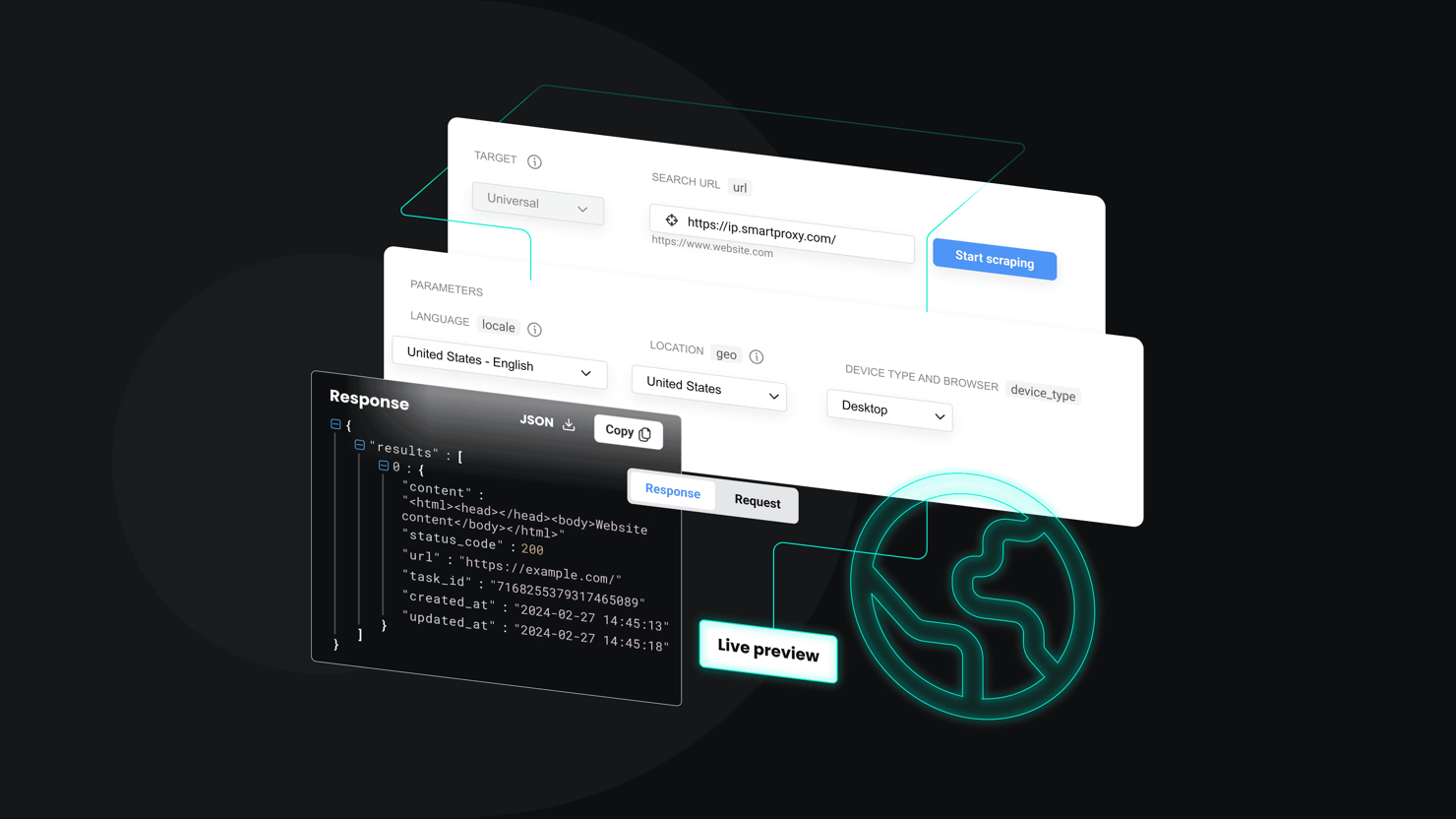
100+ templates, single API for all your data needs
Pick a template, set your parameters, and get structured data back in seconds, no scraper code required.
Unlock the full power of our Scraping API.
Grab your API key and start building with a freemium plan—no credit card required.
What does Web Scraping API cost?
Choose a plan based on your scraping volume. All plans include the same powerful features – you only pay for what you use. Start with the free plan to test before committing.
Plan prices
+VAT / Billed monthly
Rate limit
All prices shown are per 1K req.
Plan price
$0
+VAT / Billed monthly
Request type
Price per 1k req.
2K req.
$0.50
1K req.
$0.75
1K req.
$1.00
667 req.
$1.50
Rate limit
10 req/s
Plan price
$19
+VAT / Billed monthly
Request type
Price per 1k req.
38K req.
$0.50
25K req.
$0.75
19K req.
$1.00
12K req.
$1.50
Rate limit
10 req/s
Plan price
$49
+VAT / Billed monthly
Request type
Price per 1k req.
163K req.
$0.30
75K req.
$0.65
54K req.
$0.90
39K req.
$1.25
Rate limit
25 req/s
Plan price
$99
+VAT / Billed monthly
Request type
Price per 1k req.
707K req.
$0.14
165K req.
$0.60
116K req.
$0.85
82K req.
$1.20
Rate limit
50 req/s
Need more?
Request type
Price per 1k req.
Custom
Custom
Custom
Custom
Rate limit
Custom
For low-security sites and simple access
For accessing guarded or sensitive pages
With each plan, you access:
99.99% success rate
Results in HTML, JSON, CSV, XHR or PNG
MCP server
JavaScript rendering
AI integrations
100+ pre-built templates
Supports search, pagination, and filtering
LLM-ready markdown format
24/7 tech support
14-day money-back
SSL Secure Payment
Your information is protected by 256-bit SSL

Why do industry experts recommend Decodo?
Proxyway's independent market analysis puts us as one of the best providers for cost-efficient use cases. Spend less time managing budgets and more time analyzing real-time data.
Attentive service
The professional expertise of the Decodo solution has significantly boosted our business growth while enhancing overall efficiency and effectiveness.
N
Novabeyond
Easy to get things done
Decodo provides great service with a simple setup and friendly support team.
R
RoiDynamic
A key to our work
Decodo enables us to develop and test applications in varied environments while supporting precise data collection for research and audience profiling.
C
Cybereg
What are ready-made scraping templates?
Pre-built scrapers that let you start collecting data with just a few clicks. No custom code required - each template is optimized for specific websites and data types.
- All
- Amazon
- Bing
- Google
- Reddit
- Target
- TikTok
- Walmart
- ...




How does Web Scraping API work?
Our Web Scraping API mimics real user traffic to outsmart anti-bot systems and capture accurate data. The API delivers results in HTML, JSON, CSV, or Markdown format and automatically retries the request several times if it fails.
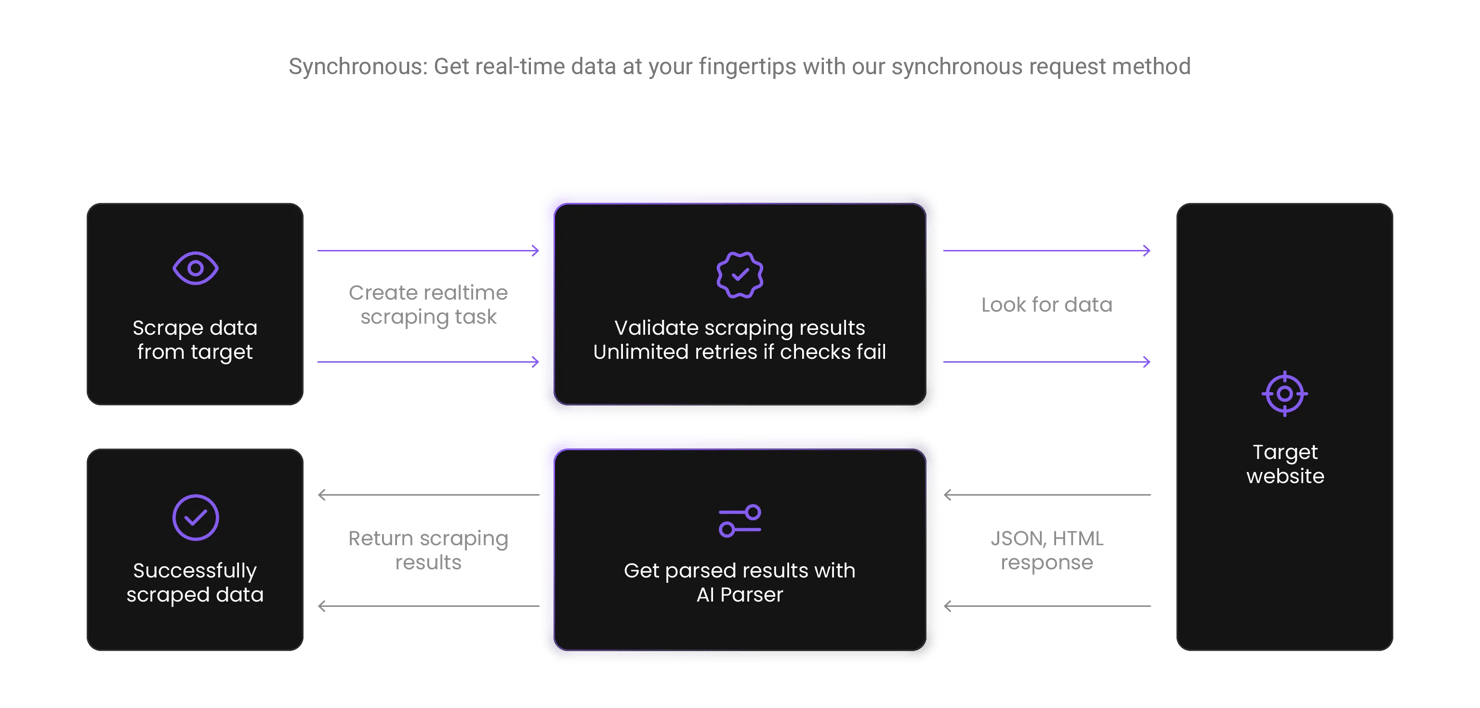
Why AI developers choose Decodo over other scraping APIs?
Manual scraping
Other APIs
Decodo
Manage proxy rotation yourself
Limited proxy pools
125M+ residential, mobile, datacenter, and ISP proxies
Build CAPTCHA solvers
Frequent CAPTCHA blocks
Advanced browser fingerprinting
Handle retries manually
Pay for failed requests
Only pay for successful requests
Maintenance overhead
Complex documentation
Ready-made scraping templates
Days to implement
Limited output formats
HTML, JSON, CSV, PNG, XHR, and Markdown formats
Start collecting data in seconds
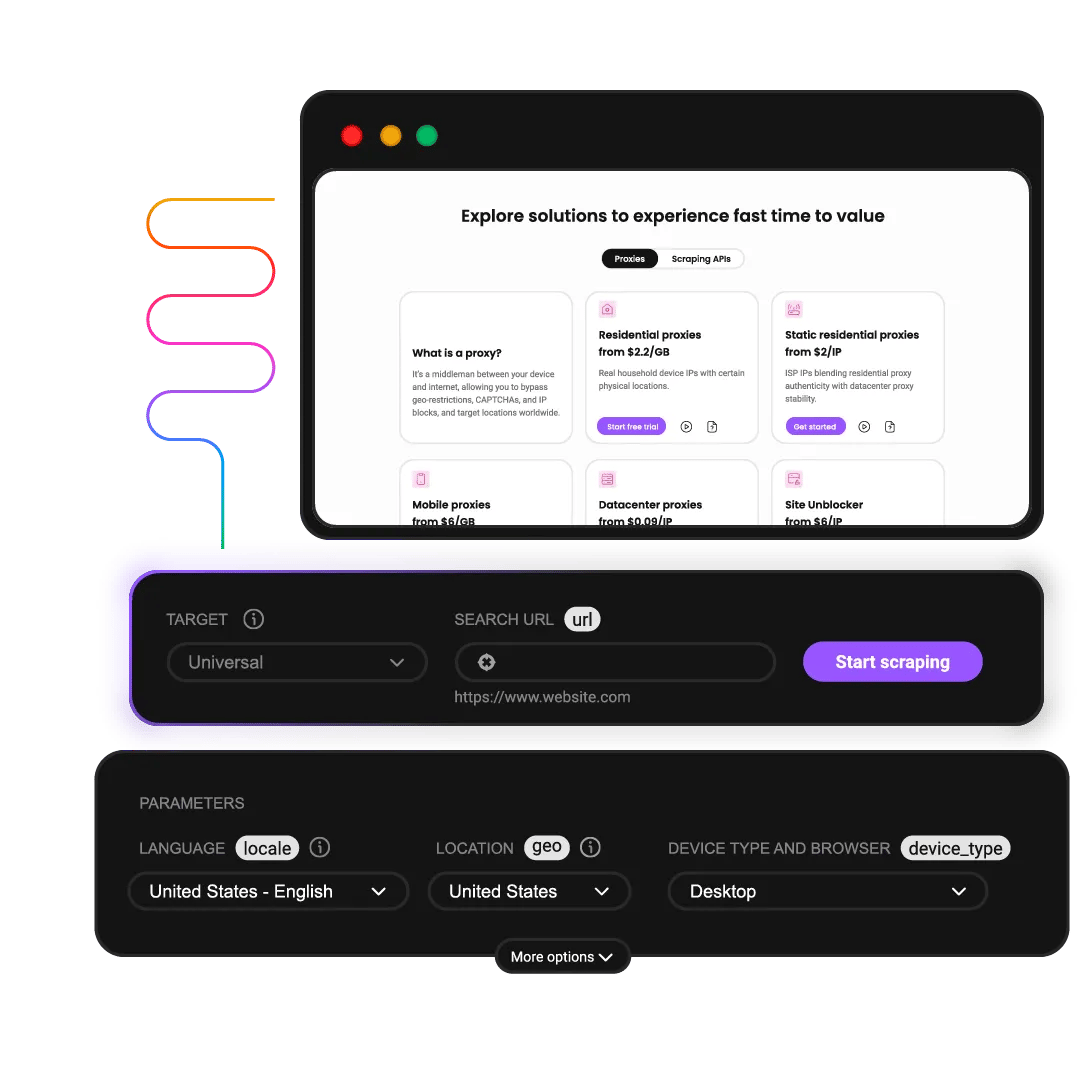
Ready-made scrapers
You bring the URL, we bring structured data. 100+ pre-built scrapers for Google, Amazon, Indeed, Zillow, TikTok, and more. Optimized parameters, zero code, and maintained by Decodo, so you never have to touch them again.
Developer resources
How do I integrate the Web Scraping API into my workflow? Streamline development with code samples in Python, PHP, and Node.js via our GitHub, explore our extensive documentation, or get started with our quick start guide.
Cost efficiency
How do I avoid overpaying for web scraping? The upgraded Web Scraping API lets you enable JavaScript rendering and premium proxies only when needed. Pay for simple requests at lower rates, scale up with advanced features as your project grows.
Stop overpaying for scraping plans
The new Web Scraping API lets you enable JS rendering and premium proxies only when needed.

Why do enterprise teams trust Decodo?
Decodo's proxy and scraping infrastructure is built for teams where failure isn't an option. Whether you're gathering competitive intelligence, monitoring prices at scale, or running mission-critical AI data pipelines.
With one of the largest ethically-sourced residential proxy networks in the world and ISO/IEC 27001:2022 certification for proxies and Scraping API, Decodo delivers the reliability, speed, and geo-coverage that enterprises and developers depend on.
From eCommerce to advanced AI use cases, Decodo adapts to the demands of any project without compromise. And you can trust us – Decodo has been recognized by G2 as one of the best security products in 2026.
Learn more about web scraping
Improve your scraping workflows with our library of step-by-step guides, expert tips, and developer articles.
Most recent

Claude Skills vs. MCP: What's the Difference and When To Use Each
Claude Skills and MCP both extend what Claude can do, but they solve different problems. A Skill packages knowledge and procedure into a folder Claude reads when a task calls for it. MCP is a protocol that connects Claude to live tools and data. This guide gives you plain definitions, an honest comparison, and a working example of both on the same task.
Zilvinas Tamulis
Last updated: Jul 30, 2026
15 min read
Most popular

What is an API?
An application programming interface (API) works like a messenger. It allows different software systems to communicate without developers having to build custom links for every connection. For instance, one service might supply map data to a mobile app, while another handles payment processing for online transactions. In these times, that demands seamless integration, and APIs play a vital role. They automate tasks, enable large-scale data collection, and support sophisticated functions like web scraping and proxy management. By bridging diverse platforms and streamlining data exchange, they help businesses stay competitive and reduce the complexity of managing multiple, often inconsistent endpoints.
Kotryna Ragaišytė
Last updated: Mar 06, 2025
6 min read
What Is Web Scraping? A Complete Guide to Its Uses and Best Practices
Web scraping is a powerful tool driving innovation across industries, and its full potential continues to unfold with each day. In this guide, we'll cover the fundamentals of web scraping – from basic concepts and techniques to practical applications and challenges. We’ll share best practices and explore emerging trends to help you stay ahead in this dynamic field.
Dominykas Niaura
Last updated: Jan 29, 2025
10 min read

What is Data Scraping? Definition and Best Techniques (2026)
The data scraping tools market is growing significantly, valued at approximately $875.46M in 2026. The market is projected to grow more due to the increasing demand for real-time data collection across various industries.
Vytautas Savickas
Last updated: Jan 30, 2026
6 min read

How to Scrape YouTube Search Results With Web Scraping API
OK, OK. You prolly know it already, but let us remind ya. YouTube is a site that allows users to upload, watch, and interact with videos. Since 2005, it has become the MVP platform for various things – starting from storing fav clips or songs and ending with marketing for companies to promote their products.
Hundreds of hours of content are uploaded to YouTube every minute. It means it’s impossible to scrape the search results manually, well, unless you're a superhero. Fortunately, we have great news – our Web Scraping API can do the job for ya.
Mariam Nakani
Last updated: Aug 12, 2022
3 min read

Web Crawling vs Web Scraping: What’s the Difference?
When it comes to gathering online data, two terms often create confusion: web crawling and web scraping. Although both involve extracting information from websites, they serve different purposes and employ distinct methods. In this article, we’ll break down these concepts, show you how they work, and help you decide which one suits your data extraction needs.
Justinas Tamasevicius
Last updated: Jul 01, 2025
7 min read

Beautiful Soup Web Scraping: How to Parse Scraped HTML with Python
Web scraping with Python is a powerful technique for extracting valuable data from the web, enabling automation, analysis, and integration across various domains. Using libraries like Beautiful Soup and Requests, developers can efficiently parse HTML and XML documents, transforming unstructured web data into structured formats for further use. This guide explores essential tools and techniques to navigate the vast web and extract meaningful insights effortlessly.
Zilvinas Tamulis
Last updated: Mar 25, 2025
14 min read
Frequently asked questions
Do I need a credit card to start using Web Scraping API?
No. Decodo offers a free plan that requires no credit card. You can test the API immediately after signing up and upgrade to a paid plan when you're ready.
How do I cancel or change my plan?
You can cancel or modify your plan anytime from your dashboard. We also offer a 14-day money-back on all paid plans. Keep in mind that the terms apply.
What is a Web Scraping API?
A Web Scraping API is an automated data extraction solution that allows real-time data collection from websites without geo-restrictions, CAPTCHAs, or IP blocks. Decodo's API handles everything from JavaScript rendering to geo-targeting to deliver structured data ready for your workflows.
Is it legal to use a Web Scraping API?
Scraping publicly available data is generally legal, but you should check each website's terms of service for specific conditions and restrictions. When in doubt, consult a legal expert before scraping.
How does Web Scraping API handle CAPTCHAs and IP blocks?
The API handles anti-bot measures automatically. It rotates IPs from our 125M+ pool, uses browser fingerprinting to appear as real users, and retries failed requests. You're only charged for successful responses.
How do I integrate Web Scraping API with AI workflows?
Web Scraping API integrates with automation tools like n8n, LangChain, OpenClaw, and the MCP server. With support for JSON and Markdown outputs, it's designed for AI agents and LLM pipelines.
The Best Value Web Scraping API Built for AI Development
100+ ready-made templates, AI-native integrations, and pricing that matches your unique data collection needs.
14-day money-back option