Scraping the Web with Selenium and Python: A Step-By-Step Tutorial
Modern websites rely heavily on JavaScript and anti-bot measures, making data extraction a challenge. Basic tools fail with dynamic content loaded after the initial page, but Selenium with Python can automate browsers to execute JavaScript and interact with pages like a user. In this tutorial, you'll learn to build scrapers that collect clean, structured data from even the most complex websites.
Dominykas Niaura
Last updated: Jul 30, 2025
10 min read
Set up your environment
Let’s set up a clean, isolated Python environment for web scraping with Selenium. You'll install the necessary tools, create a virtual environment, and verify everything works properly.
Prerequisites
Make sure you have the following installed:
- Python 3.9 or later. Download it from the official website and follow the instructions for your OS.
- A modern browser. Ensure you have at least one of these browsers installed: Chrome, Firefox, or Edge. Modern Selenium automatically manages drivers, but you need the actual browser software installed.
Create a virtual environment
Creating a virtual environment ensures that your project dependencies don’t conflict with those of other Python projects. Use Python’s built-in venv module:
This creates a .venv folder with an isolated Python environment.
Activate the virtual environment using the appropriate command for your OS:
Once activated, your terminal shows (.venv) – you’re now working inside the virtual environment.
Install dependencies
Install Selenium using pip:
Run your first Selenium script
Now that your environment is ready, let’s build your first scraper using Selenium. This simple script will open a browser, load a webpage, and extract the full HTML from scrapingcourse.com/ecommerce/.
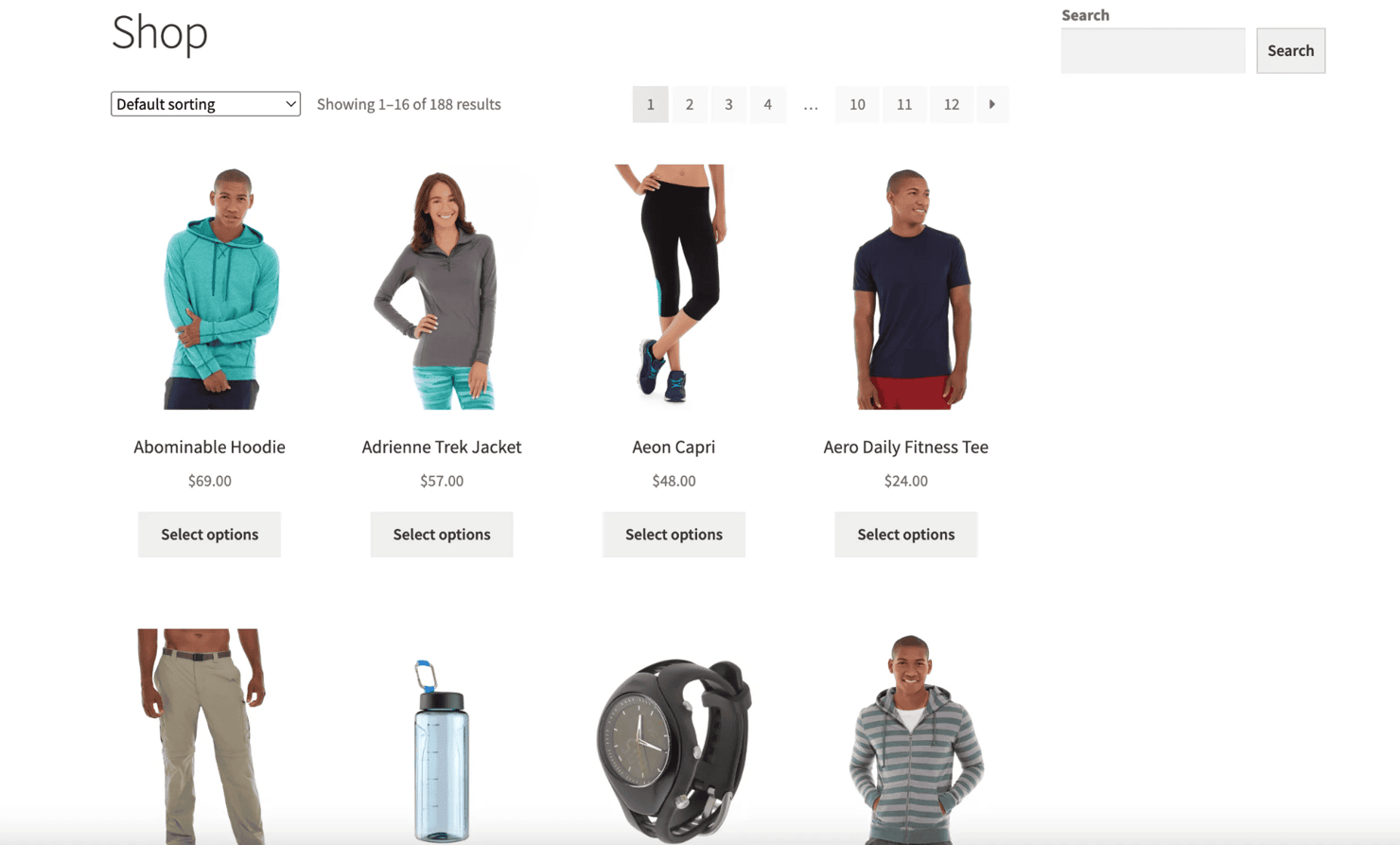
Create a file named main.py in your project directory and add the following code:
Open your terminal and run: python main.py
You’ll see a Chrome window launch, navigate to the test page, and then close.
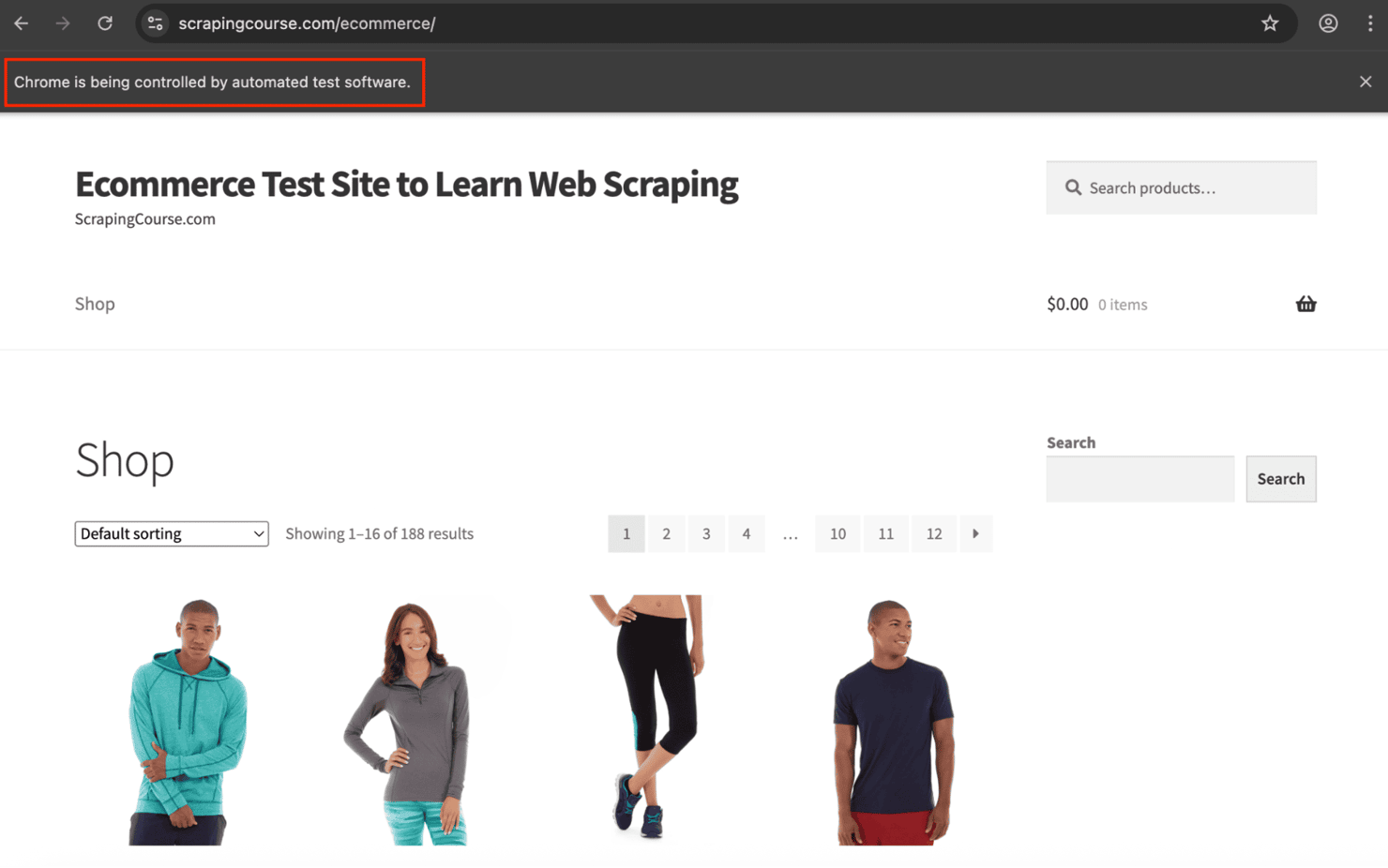
The HTML will print directly to your terminal. Example output:
If you’re seeing similar output, your scraper is up and running!
Visible vs headless mode
By default, Selenium opens a visible browser window. However, in production or automation workflows, it’s common to run in headless mode, which launches the browser in the background and reduces resource usage.
Here’s how to enable it:
Locate elements with Selenium
Selenium offers multiple strategies for locating elements on web pages. Choosing the right one ensures your scraper stays reliable across site changes and content variations.
Core location methods
There are two essential methods:
Method 1: find_element()
Returns the first matching element:
This is helpful when you're targeting a unique element. If no match is found, it raises a NoSuchElementException – so wrap it in a try-except block when needed.
Method 2: find_elements()
Returns all matching elements in a list:
This returns an empty list ([]) if no match is found. Use it when targeting multiple elements or when you want to prevent errors from missing matches.
Comparison example
Consider this HTML:
Here's the Python code:
Tip: Even when targeting one element, use find_elements() and check the list length to avoid crashes on missing elements.
Element locator strategies
By.ID – unique identifier targeting
Best for: precise, stable targeting – IDs are unique and unlikely to change.
By.CLASS_NAME – style-based targeting
Best for: reusable patterns like product listings or buttons.
By.TAG_NAME – tag-type targeting
Best for: gathering bulk content (e.g., all links or paragraphs).
By.CSS_SELECTOR – attribute and structure targeting
Best for: advanced patterns, nested selectors, and attribute-based filtering.
By.XPATH – structure-based navigation
Best for: deeply nested or text-dependent queries.
Read our xpath vs css selector guide for a deeper comparison.
By.LINK_TEXT – exact text matching
Note: Case-sensitive and requires an exact match of the link’s visible text.
By.PARTIAL_LINK_TEXT – flexible text matching
Best for: dynamic or partially known link text.
Inspect elements using DevTools
To locate the right selector:
- Right-click the element
- Click Inspect
- Review the HTML structure
- Choose the most stable and specific selector available
For example, on a demo eCommerce site, products appear inside <li> tags with a "product" class.
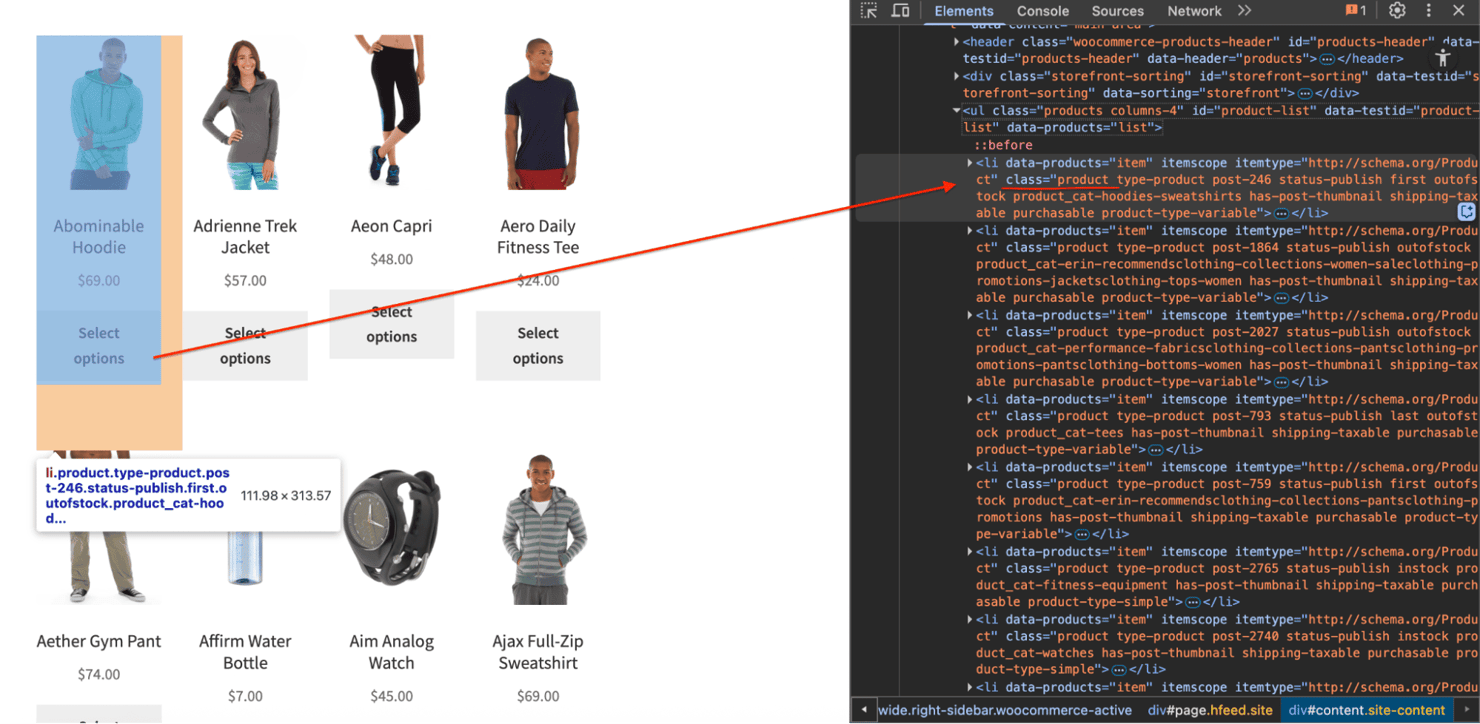
Learn more about how to inspect elements on any website.
Always test selectors against different page states or slight layout changes. Prefer strategies that tolerate minor DOM shifts for reliable web scraping.
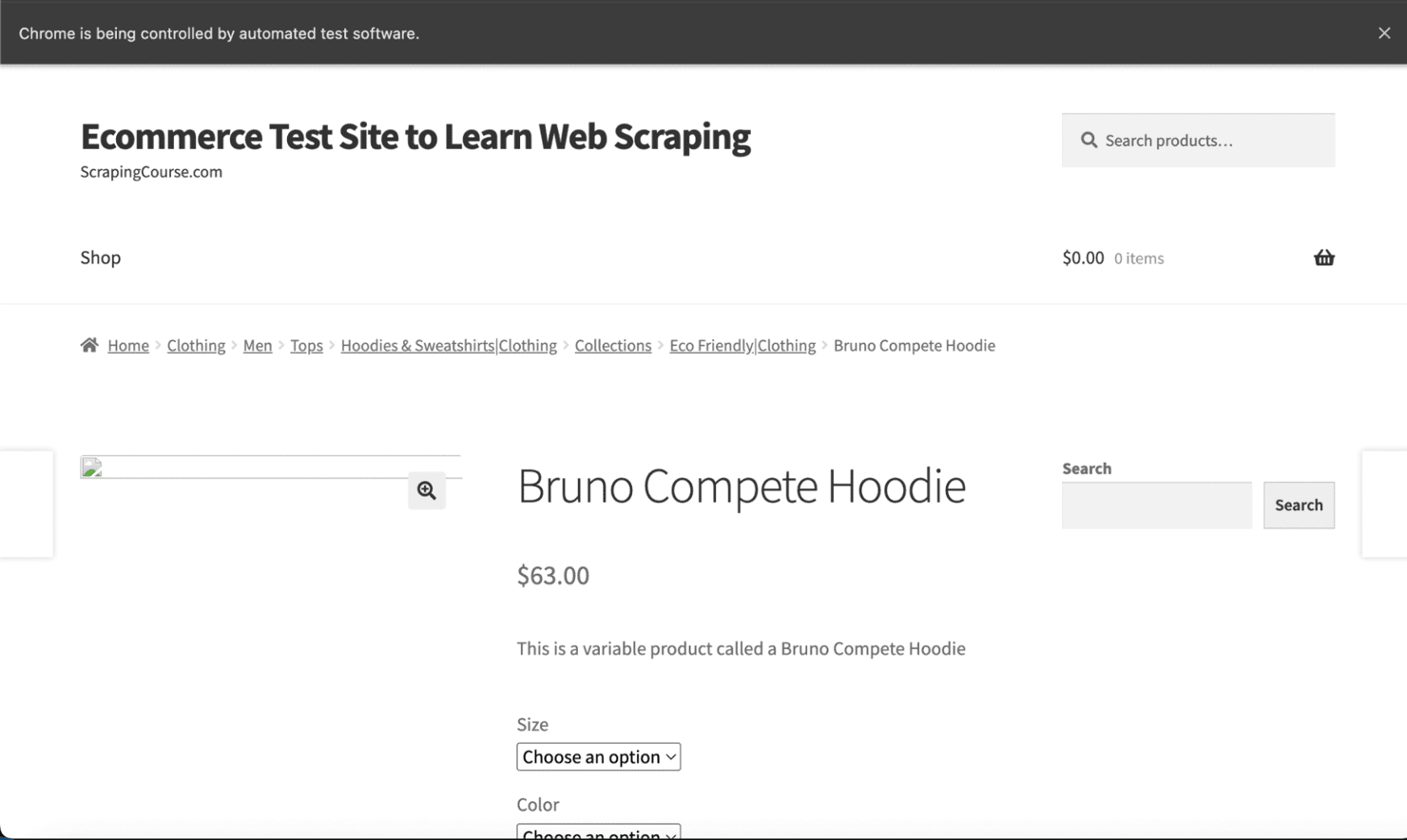
Extract product data from the page
Let’s walk through how to extract product information from a demo eCommerce site using Selenium. You’ll learn how to scrape both single and multiple products using flexible CSS selectors.
Single product walkthrough
Each product is wrapped in an <li> tag with the class "product". This consistent structure makes it easy to extract details using a shared selector.
Start by importing the By class:
Now, extract data from the first product container:
Here’s the full script, including browser setup:
Sample output:
Loop through all products
Extracting one product is useful for testing selectors. But in real-world scraping, you'll typically loop through all items on the page.
All product cards use the class "product", which we can target using find_elements():
Then loop through and collect the data:
Here’s the complete script:
Your output will look like this:
Great! You’ve now built a fully functional product scraper using Selenium.
Handle dynamic content
Modern websites often load content asynchronously using JavaScript. Elements may appear after the page visually loads, and Selenium needs explicit handling to wait for these elements to be available.
Instead of relying on time.sleep() (which slows things down unnecessarily), use smarter wait strategies.
Use explicit waits with WebDriverWait
If a page injects elements dynamically, find_element() might fail because the content hasn't finished rendering yet. WebDriverWait helps by pausing execution until specific conditions are met.
Start by importing the required modules:
Wait for all products to appear:
Here is how WebDriverWait works:
- Polling frequency – checks every 500ms by default
- Timeout – raises a TimeoutException if the condition isn't met in time
- Non-blocking – continues immediately once the condition is satisfied
- Exception handling – can ignore specific exceptions during polling
Constructor breakdown:
Here:
- driver – your active browser session
- timeout – max duration (in seconds) to wait
- poll_frequency – check interval (default: 0.5s)
- ignored_exceptions – list of exceptions to suppress (optional)
Here are the common expected_conditions:
- presence_of_element_located
- presence_of_all_elements_located
- element_to_be_clickable
- visibility_of_element_located
- invisibility_of_element_located
Wait for full page load with JavaScript
Selenium’s driver.get() typically waits for the initial HTML, but may not wait for dynamically injected content. Use document.readyState to ensure the full page – scripts, styles, and all – has loaded.
What does document.readyState mean? This JavaScript property reflects the loading state of the page:
- "loading" – the document is still parsing.
- "interactive" – DOM is parsed, but other resources (like images) may still be loading.
- "complete" – the entire page and sub-resources are fully loaded.
Use this when scraping:
- Single-page apps (SPAs)
- AJAX-heavy websites
- Pages where the content lags after visual load
Handle pagination and infinite scroll
Many modern websites use dynamic UI patterns like infinite scrolling or paginated listings to display large datasets. Scraping these pages requires more than just locating elements – it involves simulating user behavior and handling asynchronous content loads.
Scrape infinite scroll pages
Infinite scroll is common on product feeds, social media, and news aggregators. Content is appended to the DOM via JavaScript as users scroll, meaning Selenium must mimic that behavior to collect all items.
Here’s how to automate infinite scrolling:
Why this works
- Tracks document.body.scrollHeight to detect dynamic content injection.
- Scrolls repeatedly until no height change is detected.
- Uses small delays to allow content to render.
- Stops only after confirming no new content appears.
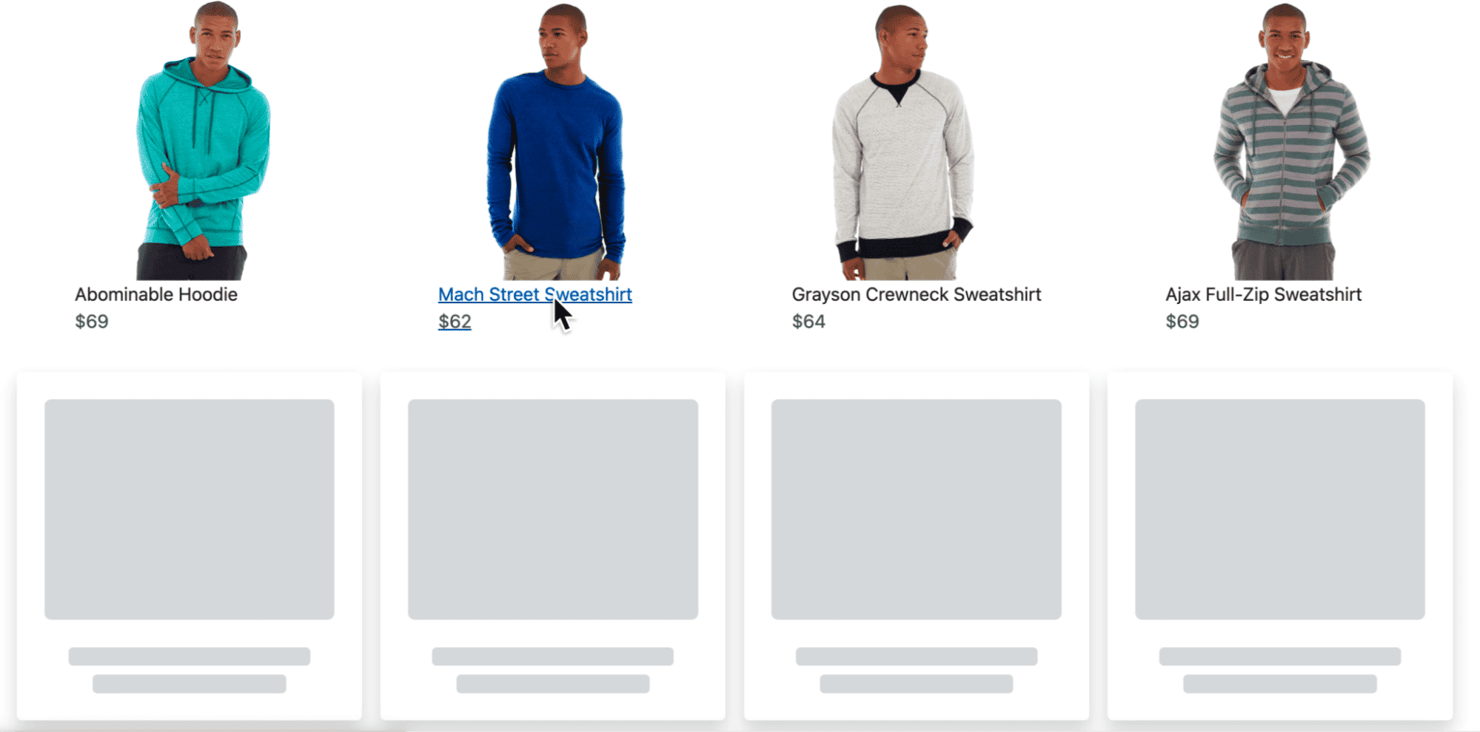
Scrape paginated listings
Classic pagination splits content across numbered pages or a "Next" icon or button.
To scrape all data, your script needs to:
- Extract items on the current page.
- Click the navigation arrow.
- Wait for the new content to load.
- Repeat until pagination ends.
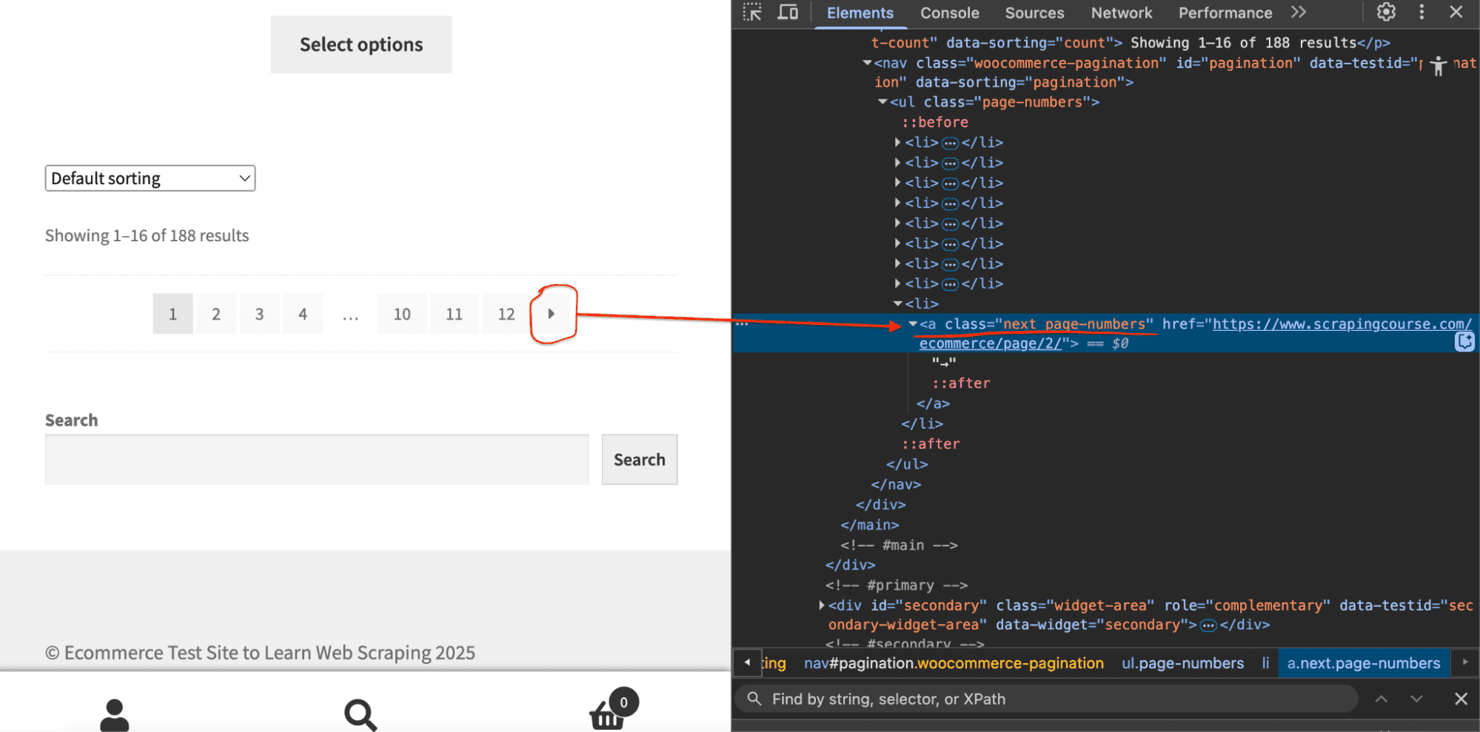
Here’s a resilient solution:
Read our guide on pagination in web scraping to go deeper.
Capture screenshots for debugging
Visual debugging is one of the most effective ways to troubleshoot scraping issues, especially when running in headless mode, where you can’t see what the browser is rendering.
Screenshots help you quickly identify:
- Page rendering issues
- Missing or delayed content
- Element visibility problems
- JavaScript execution errors
They’re also useful for documenting production failures or layout changes.
Capture full-page screenshots
Use save_screenshot() to capture the full visible portion of the browser:
Here’s the screenshot output:
Best for: confirming page load, checking layout, or inspecting element visibility.
Capture screenshots during key scraping steps
For complex flows, such as scrolling, pagination, or multi-step scraping, capture screenshots at different stages to track behavior and identify failures.
All screenshots are saved in the screenshots/ folder with timestamps for easy tracking.
Capture specific elements
Sometimes, you only want to capture a single UI component, like a product card or a pagination bar.
Best for: debugging layout issues on key elements or documenting UI changes.
Here’s the screenshot output:

Screenshot method reference
Here are several ways to capture screenshots in Selenium:
Avoid blocks with proxies
Most websites today implement anti-bot defenses – from rate limiting and IP fingerprinting to geofencing and browser challenges. If your scraper keeps failing or returns inconsistent results, you likely need proxies.
Why proxies matter for web scraping
Proxies act as intermediaries between your scraper and the target site. They offer four essential benefits:
- IP rotation. Avoid blocks by distributing requests across multiple IPs.
- Authentic traffic. Residential proxies mimic real users on real devices.
- Geo-targeting. Route traffic through specific countries, cities, or ZIPs.
- Scalability. Unlock multi-region scraping without tripping rate limits.
Unlike datacenter IPs, residential proxies are tied to real consumer devices and ISP-assigned IPs, making them harder to detect.
Our case study shows how proxy-based scraping doubled reliability and revenue for a data team scraping at scale.
Use proxies in Selenium with Selenium Wire
The base Selenium package doesn’t support authenticated proxies out of the box. Selenium Wire adds:
- Full proxy support (auth included)
- Request/response inspection
- Advanced networking control
Install it with compatible packages:
Configure a proxy like this:
Use residential proxies on protected sites
Sites like Amazon, Walmart, and other major eCommerce platforms are notoriously hard to scrape without rotating, real-user IPs.
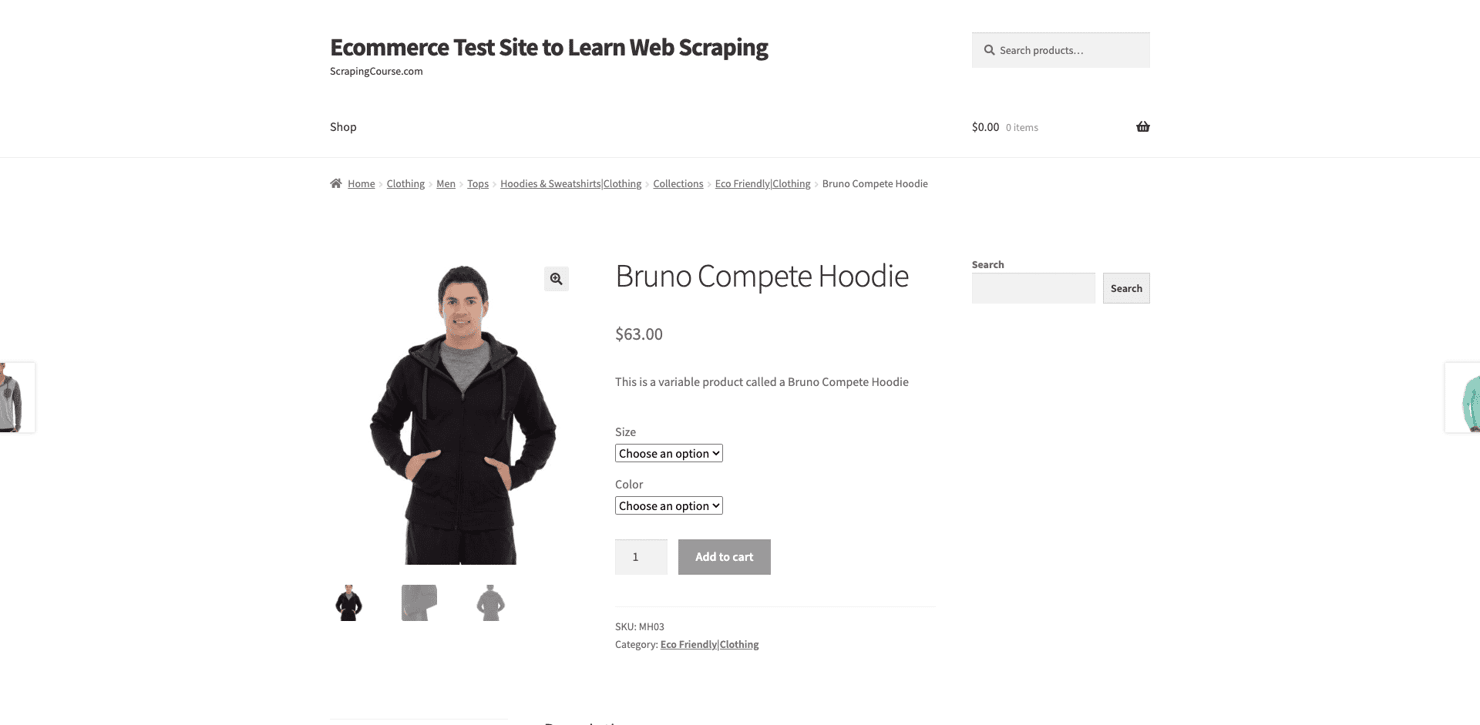
Scraping a product page without protection:
This can trigger CAPTCHAs, empty or broken HTML, 403 Forbidden, or 429 Too Many Requests errors. Learn more in our guide to anti-bot systems and how to bypass them effectively.
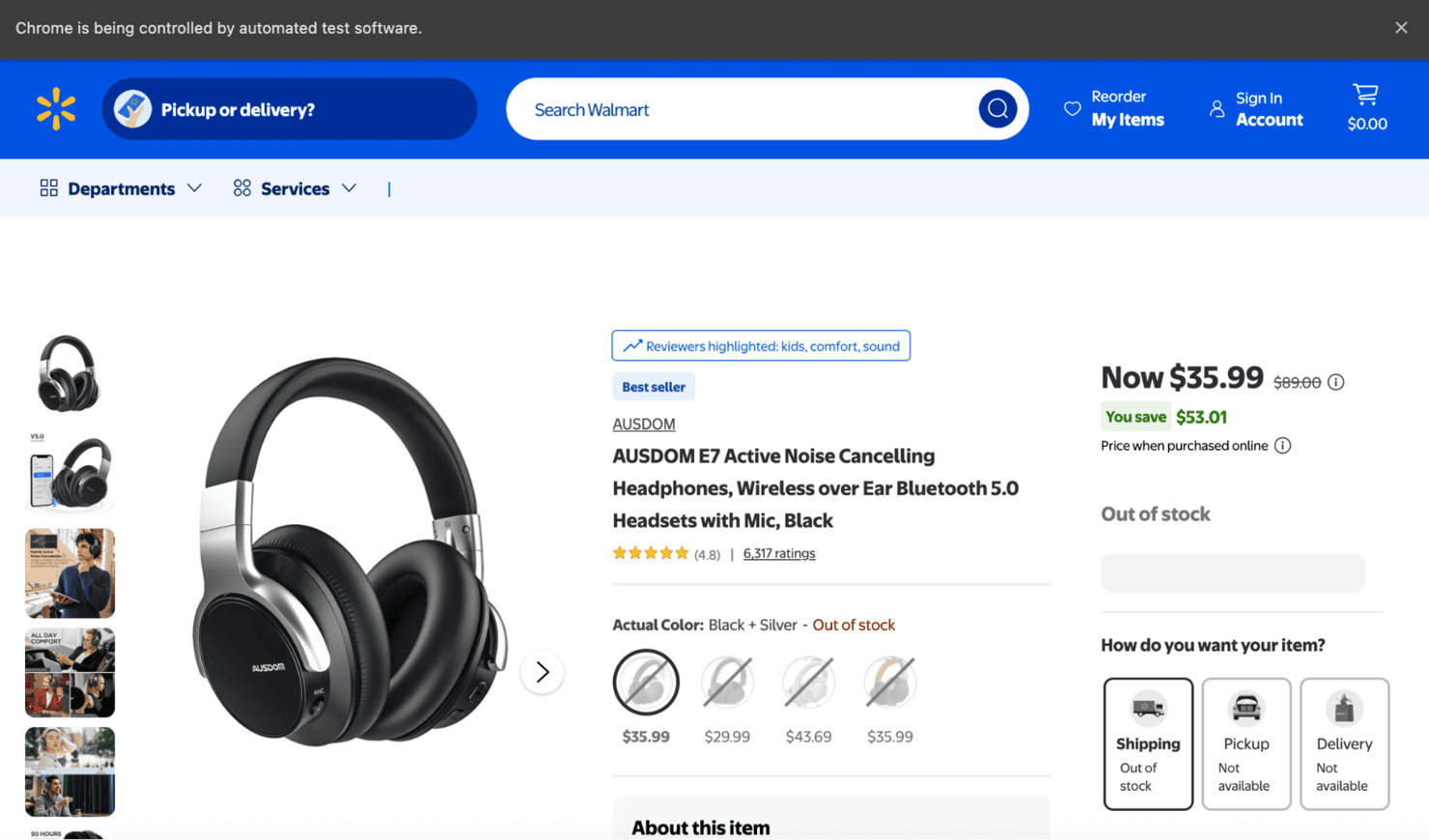
Example CAPTCHA from Walmart when running the above code:

Scrape protected pages with proxies
Re-run the same scraper using Decodo's residential proxy network:
You’ll now access the real page content like below:
Scale with Decodo’s proxy network
Decodo’s residential proxies give you:
- 115M+ ethically-sourced IPs
- 195+ countries and regions
- Targeting by country, city, ZIP, or ASN
- Rotating or sticky sessions
- <0.5s response time
- Unlimited concurrency
You can get started in minutes with our quick start guide or test things with a free trial.
Performance optimization
Most scraping tasks don’t need to load images, videos, ads, or notifications. Blocking these unnecessary assets can dramatically improve speed and reduce bandwidth, especially on media-heavy sites like retail platforms or travel listings.
Why block images and assets? The average mobile web page is nearly 2 MB, and nearly half of that is images. If your scraper only needs text or metadata, there’s no reason to download them.
Primary target: images
Images are the largest payload on most product or blog pages. You can disable image loading using Chrome’s prefs setting:
The result is you’ll skip all image downloads, reducing page size by up to 1.5–3×.
You can optionally block notifications:
Use eager page-load strategy
By default, Selenium waits for every resource (including fonts, ads, and iframes) before it continues. That’s often unnecessary.
Use eager mode to return control once DOMContentLoaded fires:
This approach is ideal for pure data scraping, without layout rendering, CSS checks, or visual capture. In real‑world tests on large eCommerce pages, you can observe 20–50 % faster load times.
When not to block assets
Blocking images and styling is a powerful optimization, but it’s not always appropriate. Skip this technique if:
- You’re capturing screenshots or testing the visual layout.
- Your target data includes images, videos, or UI states.
- You’re doing UX simulations or responsive layout checks.
- You’re actively debugging layout or JS rendering issues.
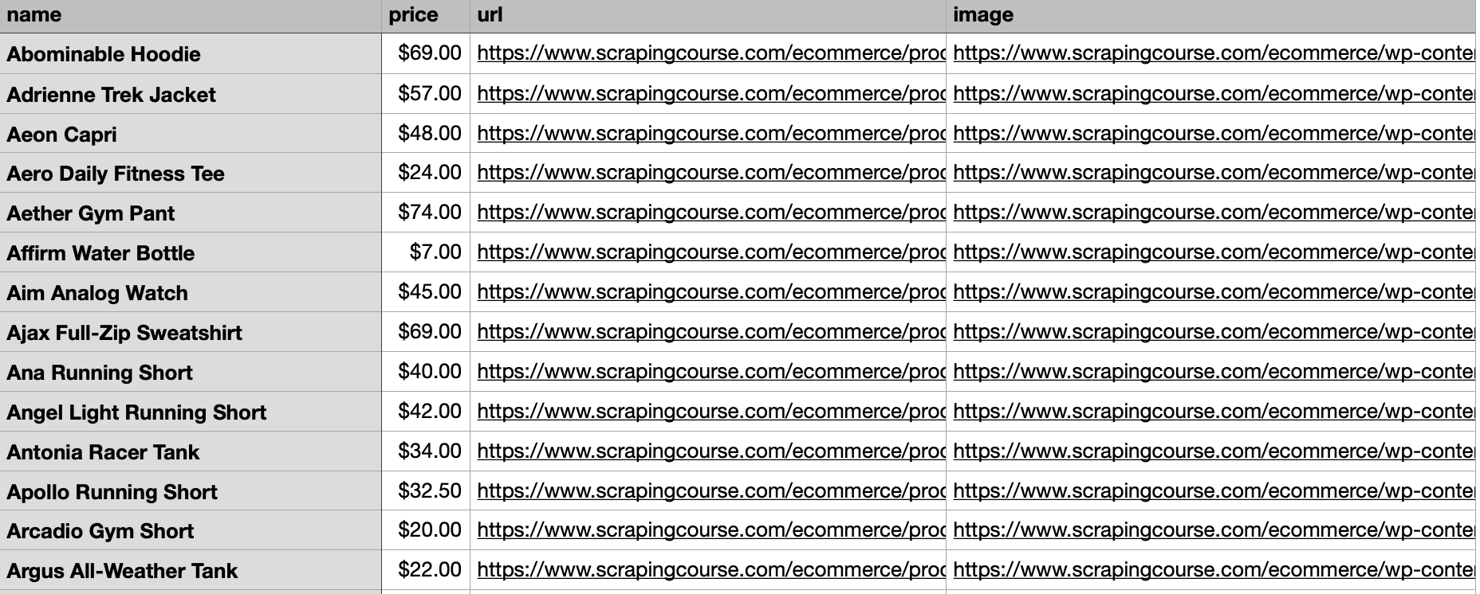
Export data to CSV
After extracting product data, the next step is to save it in a structured format. CSV is the go-to choice for loading into spreadsheets, databases, or data pipelines.
Write CSV with csv.DictWriter
Use Python’s built-in csv module to write a list of dictionaries into a clean, structured file:
If your data is already structured as a list of dictionaries, use writer.writerows(all_products) for a faster bulk write.
The following script scrapes every product across paginated pages, then writes all results to products.csv in one go:
Best practices and next steps
By now, you have a working Selenium scraper that can handle dynamic content. To wrap up, here are some best practices and suggestions for expanding your web scraping skills:
- Respect website policies. Always check a site's robots.txt and terms of service. Ethical scraping means not overloading servers with excessive requests and respecting usage policies.
- Avoid detection. Use rotating proxies, randomize your User-Agent string, and introduce small, human-like delays between interactions. Selenium’s default speed is fast and robotic – slowing it down mimics organic behavior and reduces the risk of being blocked.
- Handle CAPTCHAs. Many sites use CAPTCHAs to deter scraping. Solving these challenges often requires third-party services or AI/ML solutions – consider if the data justifies the cost. The ultimate solution is comprehensive APIs that handle anti-bot measures automatically.
- Scale carefully. Scraping thousands of pages can be resource-heavy. Selenium isn’t always the most efficient choice at scale. For larger tasks, consider headless browsers or distributed scraping frameworks like Playwright, Puppeteer (for Node.js), or even Scrapy for pure crawling workflows.
- Consider APIs and specialized services. Sometimes the best approach is to use an official API rather than scraping. Many websites offer APIs that are safer and more reliable than scraping. Additionally, companies provide scraping API services for various use cases, including social media, search engines, and eCommerce, that handle complexity and anti-bot measures for you.
- Learn and iterate. Web scraping combines technical skill with problem-solving. Each website presents unique challenges. Stay current with new tools and techniques – for example, libraries like SeleniumBase offer higher-level wrappers around Selenium, which might suit some projects better.
Wrapping up
We hope this tutorial helped you better understand how to target and extract data from JavaScript-heavy websites using Selenium with Python. Mastering this skill is essential for collecting data from pages that rely on client-side rendering.
Don’t forget – pairing Selenium with reliable residential proxies or a Web Scraping API ensures your data extraction remains smooth, stable, and undetected. Whether you’re getting started or refining a mature pipeline, this setup gives you the flexibility and power to scale any web data project.
About the author

Dominykas Niaura
Technical Copywriter
Dominykas brings a unique blend of philosophical insight and technical expertise to his writing. Starting his career as a film critic and music industry copywriter, he's now an expert in making complex proxy and web scraping concepts accessible to everyone.
Connect with Dominykas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.