How to Scrape Bing Search with Python
Bing scraping is the automated extraction of rankings, ads, snippets, and search features from Bing's SERPs. Since Microsoft retired all official Bing Search APIs in 2025, scraping and third-party SERP APIs are the main ways to access this data programmatically. This guide covers Python-based approaches using Requests, Beautiful Soup, Playwright, and Decodo's Web Scraping API.
Zilvinas Tamulis
Last updated: Jul 13, 2026
12 min read
TL;DR
- Bing scraping extracts SERP data – titles, URLs, descriptions, rank position, related keywords, and rich snippets – from bing.com/search using HTTP requests or browser automation
- Use Requests + Beautiful Soup for static result pages; switch to Playwright when you need JS rendering, pagination via &first=, or richer elements
- Always track rank position alongside each result and capture "People Also Search For" suggestions – they are the two highest-value fields most tutorials skip
- For scale, route requests through residential or datacenter proxies, or offload the whole stack to Decodo's Web Scraping API and consume clean JSON
What is Bing scraping?
Bing scraping covers the full pipeline of fetching pages from bing.com/search, parsing the returned HTML, and writing the structured fields somewhere useful. The fields you typically extract are:
- Organic results – title, URL, description, and rank position per result
- Related searches – the "People Also Search For" block at the bottom of every SERP
- "People Also Ask" – the expandable question accordion in the middle of the page
- Rich snippets – FAQ accordions, knowledge panels, news cards, recipe cards
- AI/Copilot answer – the generated summary box with cited sources
- Pagination data – Bing uses the &first= parameter (1-indexed, increments of 10)
Two delivery methods dominate. Static parsing (Requests + Beautiful Soup) is lightweight and fast, but cannot see JavaScript-rendered elements like the Copilot answer. Browser automation (Playwright) drives a real Chromium/Firefox/WebKit instance, executes JS, handles pagination clicks, and lets you screenshot the page for debugging – at the cost of more setup and slower runs. For production scale, most teams route through proxies (residential or datacenter) or offload the entire stack to a managed Web Scraping API.
Bing is structurally similar to Google but uses different class names (b_algo for organic results, b_rs for related searches, b_ans for answer/rich blocks) and a different pagination parameter – which is why a Bing scraper isn't a drop-in port of a Google scraper.
Why scrape Bing search?
While Google often takes center stage, Bing has its own set of perks that make it worth a look, especially for those digging into unique data. Scraping Bing search results can unlock insights you might miss elsewhere, thanks to its expanded content variety, cleaner search results, and stronger regional relevance.
Bing's algorithm often surfaces pages that are different from those of Google, which can be especially useful when you're scouting competitors or trying to find less mainstream content. For example, researching niche industry blogs might uncover gems on Bing that never crack Google's top 10.
Because fewer companies actively target Bing for SEO, its results also tend to be less influenced by aggressive keyword-stuffing or content farms. This means you're more likely to get genuinely informative pages rather than a sea of clickbait and affiliate-heavy articles.
The final benefit is that Bing is the default search engine on Microsoft devices, giving it a stronger foothold in specific regions and enterprise environments. If you're analyzing user behavior in the United States or among corporate audiences, Bing might actually give you a clearer picture than Google.
In short, Bing isn't just the "other" search engine – it's a valuable data source with unique advantages, especially when you're looking for fresh perspectives, cleaner results, or region-specific insights.
Use cases for scraping Bing search results
Now that we've covered why Bing is worth scraping, let's look at how you can actually put that data to work.
For SEO geeks out there, Bing provides a fresh angle for understanding how your site – or your client's – appears in search results. You can monitor keyword rankings, track changes over time, and spot pages that perform well on Bing but not on Google.
Bing search results can also help uncover audience preferences, trending topics, and content gaps. For example, a startup preparing to launch a product can analyze Bing SERPs to see what questions users are asking and which solutions currently dominate the space.
Want to know who's gaining traction in your specific market? Scraping Bing makes it easy to track which competitors are ranking for particular keywords or getting featured in results. This helps businesses fine-tune their messaging or identify opportunities others have missed.
In a nutshell, scraping Bing isn't just about gathering simple data – it's about gaining an edge in how you optimize, strategize, and expand your business.
Get the Latest AI News, Features, and Deals First
Get updates that matter – product releases, special offers, great reads, and early access to new features delivered right to your inbox.
Tools and methods to scrape Bing search
So you've got a solid reason and a clear use case – now it's time to talk tools. There are several ways to scrape Bing search results, depending on your goals, budget, and level of technical know-how. Here's a list of the most common methods:
- Manual scraping. Copying and pasting search results into a spreadsheet might work for one-off research, but it quickly becomes unsustainable. It's slow, error-prone, and definitely not what you'd call developer-friendly. Excellent for a demo, terrible for data at scale.
- Python (Requests + Beautiful Soup). For simple HTML pages, Python's Requests and Beautiful Soup libraries are lightweight and practical. This approach is perfect for quick scripts where JavaScript rendering isn't a factor, like grabbing titles, URLs, and snippets from basic result pages.
- Playwright. Playwright lets you automate entire browser sessions, making it ideal for scraping JavaScript-heavy or dynamic content. It's great for more advanced use cases, such as extracting rich snippets or simulating real user behavior across pages.
- APIs and third-party scrapers. Since Microsoft retired all official Bing Search APIs on August 11, 2025, third-party SERP scraping APIs are now the only programmatic route to structured Bing data. Decodo's Web Scraping API, for example, handles everything from rotating proxies to parsing HTML – so you can focus on the data, not the infrastructure.
When scraping Bing at scale or on a frequent basis, proxy usage is essential to avoid being blocked. Proxies mask your IP address and help distribute requests across multiple locations, making it harder for Bing to detect scraping activity. Rotating residential or datacenter proxies, like those offered by Decodo, can dramatically increase success rates and keep your scraping smooth and uninterrupted.
Regardless of whether you're building your scraper with Python or leaning on a third-party API, there's no shortage of ways to extract Bing search data. Just be sure to pick the method that matches your scale – and don't skip the proxies unless you like 403 errors.
Reliable residential proxies for scraping
Kick off your 3-day free trial and scrape Bing without hitting roadblocks or rate limits.
How to scrape Bing search results using Python
Setting up your environment
Now that you know the why and how to scrape Bing search results, it's time to set up your Python environment. We're going to get started with Requests and Beautiful Soup and then move on to Playwright for more dynamic pages. Here's how to get started:
- Install Python. First, make sure Python 3.7 or later is installed on your machine. You can download it from the official Python website. To check if it's installed, run:
- Create and activate a virtual environment (recommended). It's a good practice to isolate your scraping project using a virtual environment to avoid clutter and library conflicts:
3. Install the required libraries. You'll need a few Python packages to get started:
4. Install the browser binaries. After installing Playwright, run the following command to install the necessary browser binaries:
5. Test your setup. Here's a simple script to verify everything is working. This script uses Requests and Beautiful Soup to fetch and parse Bing's homepage:
If you see a title like "Search - Microsoft Bing" printed in your terminal, congrats – you're all set to start scraping! Next, we'll dive into how to actually extract search results.
Basic Bing search scraping with Python
Before we dive into browser automation, let's start with the basics – making an HTTP request and parsing the HTML response. This method is excellent for simple scraping tasks where JavaScript isn't heavily involved. We'll use Python's Requests library to fetch the page and Beautiful Soup to extract the data.
Note that Bing may return different HTML or block the request entirely if it detects automated access, so this approach works best for small-scale tests or when paired with rotating user-agent headers and proxies.
For proxy details and credentials, visit the Decodo dashboard, purchase a plan that suits your needs, and get the username, password, and endpoint information.
The script above does the following:
- Defines the prerequisites. Proxy credentials, user-agent header, query, and target URL are all written here and are later used in the script.
- Makes a request. The script sends an HTTP GET request through a proxy server, together with a user-agent. This ensures that the request is undetected and allows you to repeat it multiple times.
- Finds the title, URL, and description. Once all containers have been found, the script then loops through them and finds the title (h2), URL (href), and description (p).
- Parses the response. Once Requests grabs the HTML page, Beautiful Soup steps in to analyze it and parse the required information. Here, it finds all <li> elements with the class "b_algo", which is the container where each search result is located.
- Prints the results. While still inside the loop, results are printed, then the process is repeated until all results from the search result page are found.
Important: When using proxies, your IP location can affect Bing's language and locale settings. Unlike Google, Bing may return no results if the query is in English, but your proxy appears to be from a region like France or Germany. To avoid this, either:
- Use universal search terms (e.g., brand names), or
- Manually set the language and region in your search request by adding the setlang and cc (country code) parameters:
Extracting search result rankings
Ranking position is one of the most valuable data points SEO and SERP-monitoring projects can collect. It's crucial to know if a target page sits in #1 or #25. This helps you monitor competitors, see how keywords perform, and generally measure how effective the SEO campaigns really are over time.
The easiest way to capture rankings is to use Python's enumerate() function while looping through the search results. It automatically assigns a position number to every result returned on the page.
Example output:
If you're working on larger projects, your best option is combining rank extraction with Bing's pagination parameter, &first=, for better results. Bing displays 10 results per page, so you can actually calculate a continuous ranking across multiple pages. To do so, just adjust the starting rank based on the page offset. This way, you're able to build complete ranking datasets and analyze visibility far beyond the first page of results.
Using XPath selectors for more resilient scraping
We used CSS selectors, such as li.b_algo, in our examples to find Bing search results. CSS selectors are very useful. They're simple and can be the fastest way to grab that data you're after. Yet, they can be unreliable. This typically happens if Bing changes class names or page structure, even if that modification is very small.
So it's best not to target elements by their classes only. Use XPath to locate elements based on their position and relationships within the document structure. This approach strengthens scrapers when confronted with changes. At the same time, developers have more flexibility when they're extracting data from complex pages. Pretty nifty.
Let's look at an example. The XPath expressions below target Bing result titles and descriptions:
Example output:
This doesn't mean that you can't use CSS selectors. On the contrary, you can use them for many scraping tasks. However, XPath does have better targeting capabilities. Generally, it's your best go-to tool when you're working on large-scale scraping projects or targeting pages with complex HTML structures. To learn more, see the XPath vs CSS selectors guide.
Advanced techniques and common challenges when scraping Bing
As you expand your Bing scraping setup, you'll quickly hit limitations with simple HTTP requests and HTML parsing. Bing's search engine results page includes dynamic elements, paginated content, and bot-detection mechanisms that make scraping with just Requests and Beautiful Soup unreliable at scale. This is where Playwright comes in, offering a browser automation layer that behaves much closer to a real user.
Here's why Playwright is a better choice for scraping Bing:
- JavaScript rendering. Bing uses JavaScript to load certain rich elements (such as knowledge panels and news cards). Playwright executes JS like a real browser, letting you scrape the complete, rendered page, not just the raw HTML.
- Pagination control. Unlike basic scraping, where pagination can be inconsistent or fail altogether, Playwright allows you to click "Next" buttons and dynamically load additional search result pages with full browser context.
- Simulated human behavior. With support for keyboard input, scrolling, mouse movement, and delays, Playwright makes your bot mimic a real user, helping you avoid detection and bans.
- Better CAPTCHA avoidance. While not foolproof, Playwright can bypass some of Bing's light anti-bot measures simply by acting more like a browser than a bot.
- Screenshot and debugging capabilities. Playwright can capture screenshots or even record videos of the scraping session, making it easier to debug changes in the DOM or scraping failures.
Here's an example Playwright script that navigates to https://bing.com/, enters the search query, and scrapes the first 3 result pages. It also takes a screenshot of each page, so you can see what the pages looked like during the process and if any issues were encountered:
Using APIs for scraping Bing
Here's a key thing to keep in mind going forward: Microsoft retired all official Bing Search APIs on August 11, 2025. Bing Web Search, Custom Search, News, Image, Video, Visual, Entity, Local Business, Spell Check, and Autosuggest are all gone. There is no public replacement, only the paid Grounding with Bing Search inside Azure AI Agents, which is a chat-grounding product, not a SERP API. That means a third-party SERP scraping API is no longer a "nice alternative" to the official API. Instead, it's the only remaining programmatic path to Bing SERP data.
Now, let's take a look at the Playwright script we just built as an example. Sure, it gets the job done, but it's long, a bit finicky, and definitely not the most beginner-friendly. Setting up browser automation, handling page loads, navigating pagination, rotating proxies, and praying Bing doesn't throw a CAPTCHA mid-run... It's a lot. Honestly, even experienced developers don't love maintaining scraping scripts that can break overnight with a minor UI change.
Instead of juggling libraries and debugging selectors, scraping APIs handle everything for you – HTTP requests, JavaScript rendering, proxy rotation, CAPTCHA bypassing, and more. They're convenient when you need scale, reliability, and fast iteration.
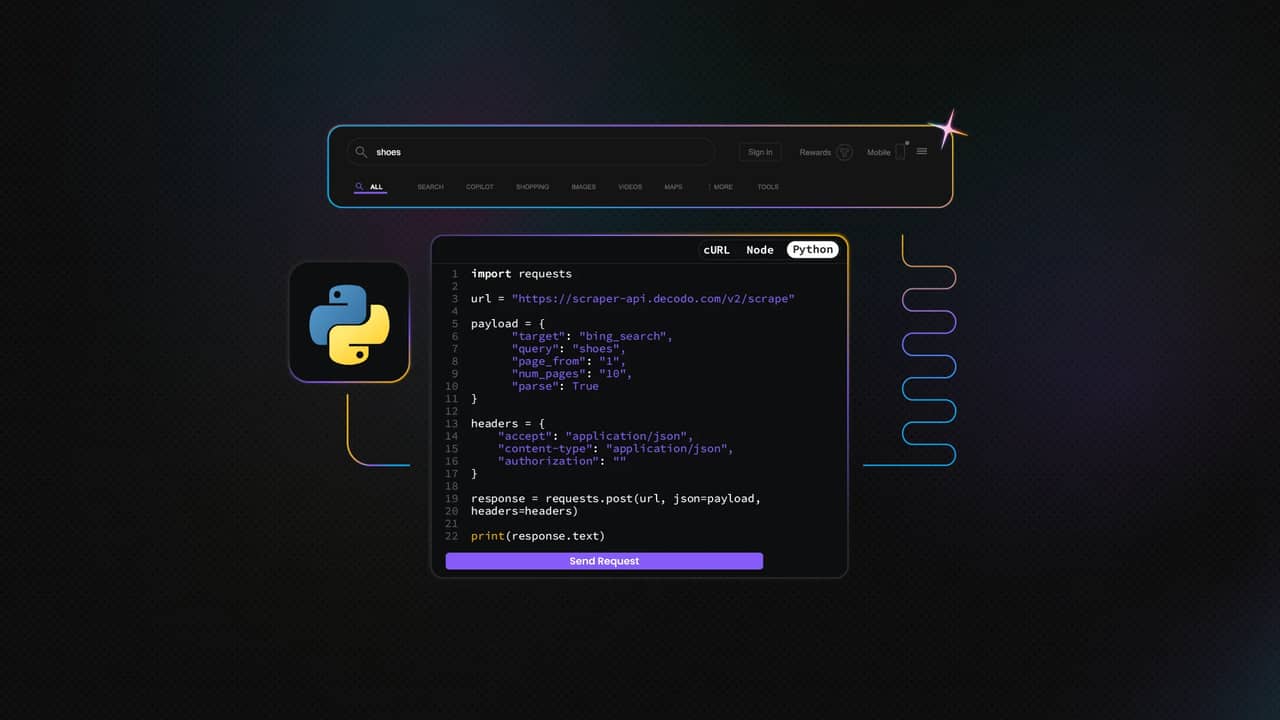
If you're looking for a rock-solid solution, Decodo's Web Scraping API is a great choice. It's built for performance, includes premium proxy rotation, built-in error handling, and works out-of-the-box with primary targets like Bing. Here's what a simple API request would look like with Python:
It may be hard to believe, but the API does almost exactly what the previous long Playwright script did. It even comes with a user-friendly web UI where you can easily configure and schedule requests, plus export results in JSON or table formats with just a few clicks.
Final notes
Scraping Bing search results with Python opens up a world of opportunities – from uncovering regional insights to tracking competitors in a less saturated search space. With tools like Python's Requests, Beautiful Soup, Playwright, and Decodo's Web Scraping API, you've got plenty of options to fit your needs and scale. Just remember: if you're scraping frequently or at volume, don't forget proxies – they're your best friend on this adventure. Try out the methods covered here and see what kind of insights Bing has that Google is hiding.
APIs retired, data still flowing
Decodo's Web Scraping API returns structured Bing results with rankings, snippets, and ads parsed for you. No proxy setup, no CAPTCHA bypass logic, no blocked requests.
About the author

Zilvinas Tamulis
Technical Copywriter
A technical writer with over 4 years of experience, Žilvinas blends his studies in Multimedia & Computer Design with practical expertise in creating user manuals, guides, and technical documentation. His work includes developing web projects used by hundreds daily, drawing from hands-on experience with JavaScript, PHP, and Python.
Connect with Žilvinas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.