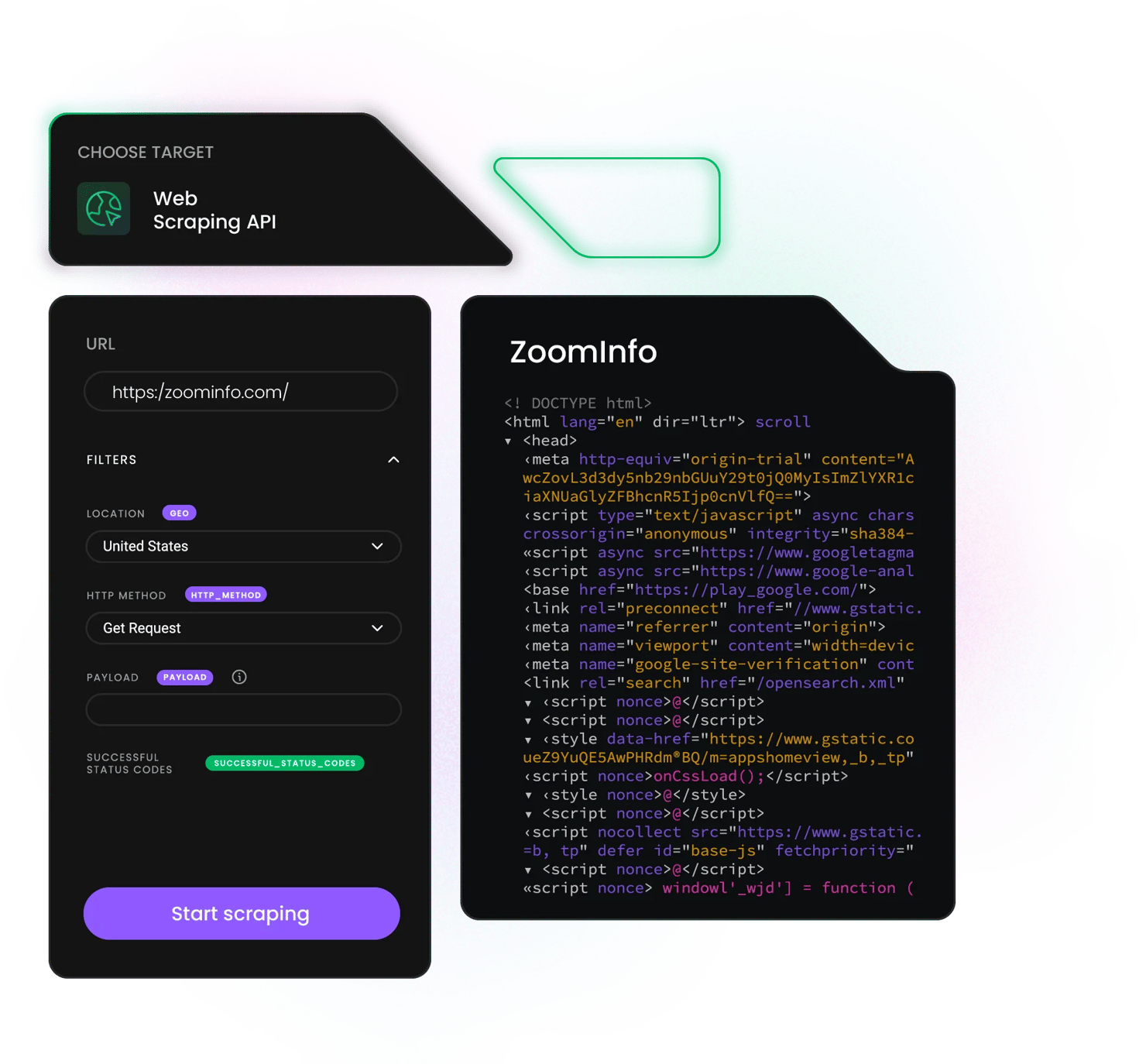
ZoomInfo Scraper API
Extract B2B data with our ZoomInfo scraper API* – access company profiles and key decision-maker contacts to gain market insights and get ahead of the competition, all without CAPTCHAs or IP blocks.
* This scraper is now a part of the Web Scraping API.
14-day money-back option
99.99%
success rate
125M+
ethically-sourced IPs
Zero
CAPTCHAs
LLM-ready
Markdown format
Free
starter plan
Trusted by:
Why data teams choose Decodo
Manual scraping
Other APIs
Decodo
Proxy rotation needed
Limited proxy pool
125M+ residential, mobile, ISP, and datacenter proxies
Custom CAPTCHA solving
Frequent CAPTCHA blocks
Advanced browser fingerprinting
Retry handling required
Charges for failed requests
Billing for successful scrapes only
High maintenance
Complex documentation
100+ ready-made scraping templates
Long setup time
Limited output formats
HTML, JSON, CSV, XHR, PNG, or Markdown formats
Gain a competitive edge with ZoomInfo scraping API
What is a ZoomInfo scraper API?
ZoomInfo scraper API is a specialized tool for collecting data from ZoomInfo's B2B database. It automatically rotates proxies, renders JavaScript, and retries failed scrapes to deliver stable results with zero maintenance.
Extract such data from ZoomInfo as:
- Company details
- Description
- Organizational structure
- Key employees
- Company insights
- Technographic stack
- Funding and acquisition data
- Highlights and scoops
- Related news and media
- Frequently Asked Questions
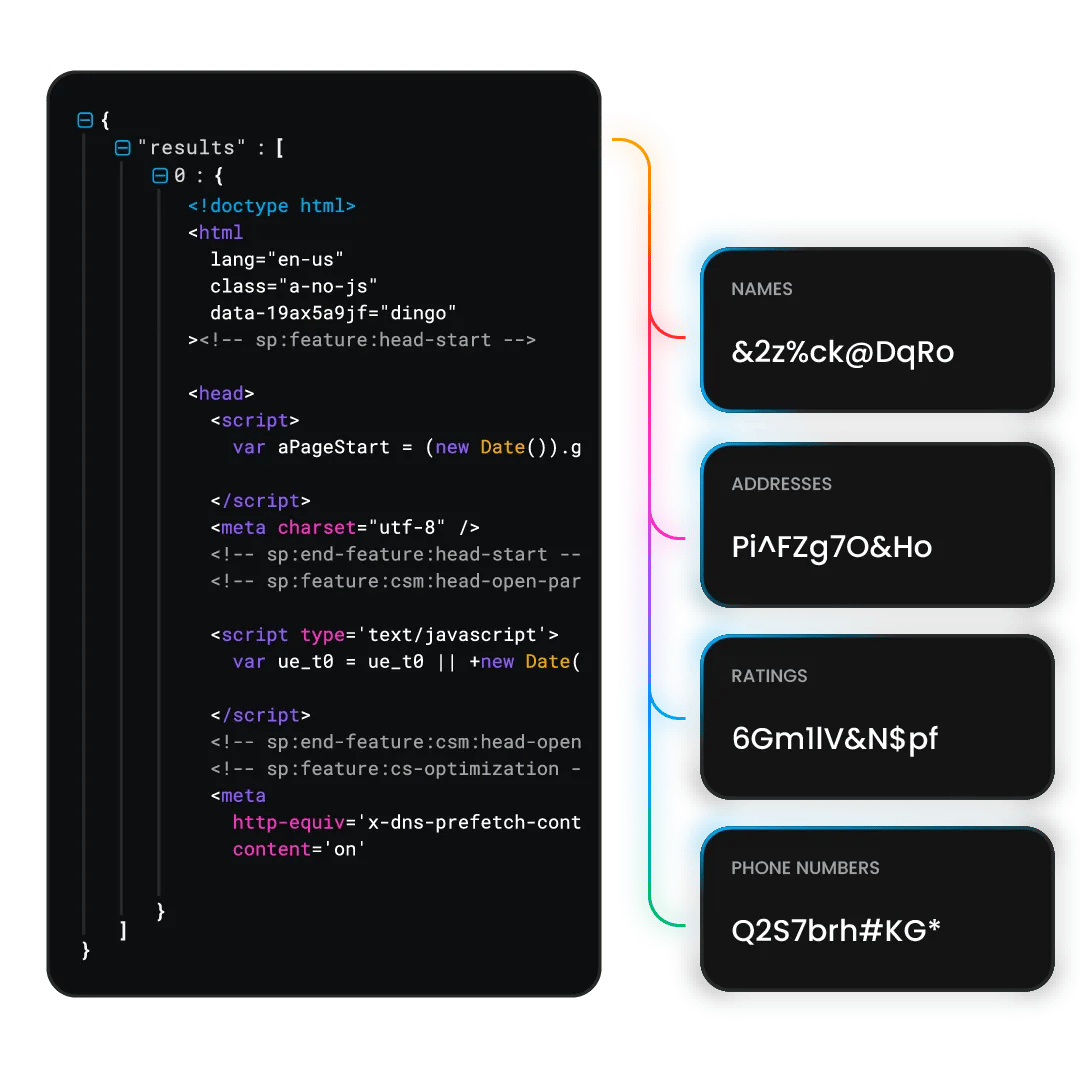
Collect key data from ZoomInfo
Our Web Scraping API combines a scraper, a parser, and a pool of 125M+ IPs into a single solution. This tool offers a number of powerful features:
Built-in scraper and parser
- JavaScript rendering
- Integrated browser fingerprints
- Easy real-time API integration
- Vast country-level targeting options
- CAPTCHA handling
See our ZoomInfo scraping API in action
Give our API a test drive to see just how quick and easy data collection really is.
Build scalable company web data projects
Lead generation and enrichment
Make targeted prospect lists with company profiles, decision-maker contacts, and tech stacks from ZoomInfo.
Competitive intelligence
Track competitor hiring trends, tech stack adoption, and funding activity to stay ahead of market shifts.
Market research and analysis
Extract company data across industries to identify market trends, technology adoption patterns, and expansion opportunities.
Sales intelligence
Power account-based marketing campaigns with real-time company insights, organizational charts, and technographic data.
Streamline how you collect ZoomInfo data
Start collecting ZoomInfo data with an API that handles proxies, retries, and anti-bot systems automatically.
Instant results
Receive data in <0.2s with unlimited concurrent sessions. Output in HTML, XHR, or Markdown, whichever fits your workflow.
99.99% success rate
Get reliable data extraction with 99.99% success rates. Failed requests retry automatically, and you only pay for successful scrapes.
Real-time or on-demand results
Run instant scraping requests or schedule tasks in advance to automate your ZoomInfo data collection.
Advanced anti-bot measures
Leverage integrated browser fingerprints and JavaScript rendering to mimic real user traffic and avoid anti-bot measures.
Simple integration
Build your data collection setup in minutes using our quick start guides and ready-made code examples.
Proxy integration
Access ZoomInfo without CAPTCHAs, geo-restrictions, and IP blocks with built-in 125M+ residential, mobile, datacenter, and ISP proxies.
API Playground
Test different scraping configurations in the API Playground before going live with your integration.
Built for AI
Automate and simplify your workflows with AI-powered integrations like our MCP server, n8n node, and LangChain.
What does Web Scraping API cost?
Choose a plan based on your scraping volume. All plans include the same powerful features – you only pay for what you use. Start with the free plan to test before committing.
Plan prices
+VAT / Billed monthly
Rate limit
All prices shown are per 1K req.
Plan price
$0
+VAT / Billed monthly
Request type
Price per 1k req.
2K req.
$0.50
1K req.
$0.75
1K req.
$1.00
667 req.
$1.50
Rate limit
10 req/s
Plan price
$19
+VAT / Billed monthly
Request type
Price per 1k req.
38K req.
$0.50
25K req.
$0.75
19K req.
$1.00
12K req.
$1.50
Rate limit
10 req/s
Plan price
$49
+VAT / Billed monthly
Request type
Price per 1k req.
163K req.
$0.30
75K req.
$0.65
54K req.
$0.90
39K req.
$1.25
Rate limit
25 req/s
Plan price
$99
+VAT / Billed monthly
Request type
Price per 1k req.
707K req.
$0.14
165K req.
$0.60
116K req.
$0.85
82K req.
$1.20
Rate limit
50 req/s
Need more?
Request type
Price per 1k req.
Custom
Custom
Custom
Custom
Rate limit
Custom
For low-security sites and simple access
For accessing guarded or sensitive pages
With each plan, you access:
99.99% success rate
Results in HTML, JSON, CSV, XHR or PNG
MCP server
JavaScript rendering
AI integrations
100+ pre-built templates
Supports search, pagination, and filtering
LLM-ready markdown format
24/7 tech support
14-day money-back
SSL Secure Payment
Your information is protected by 256-bit SSL

Read reviews from teams already scraping with Decodo
Join 135K+ clients and industry's leaders already using our solutions.
Attentive service
The professional expertise of the Decodo solution has significantly boosted our business growth while enhancing overall efficiency and effectiveness.
N
Novabeyond
Easy to get things done
Decodo provides great service with a simple setup and friendly support team.
R
RoiDynamic
A key to our work
Decodo enables us to develop and test applications in varied environments while supporting precise data collection for research and audience profiling.
C
Cybereg
Featured in:
Frequently asked questions
Is scraping ZoomInfo legal?
Scraping publicly available data is legal as long as it respects the website’s terms of service and applicable laws. When in doubt, talk to a legal professional before collecting data.
What are the common use cases for the ZoomInfo scraper API?
Teams use the ZoomInfo scraper API for lead generation, enriching contact databases, tracking competitor hiring and funding activity, analyzing market trends, and building targeted prospect lists.
Does the ZoomInfo scraper API handle JavaScript-heavy pages?
Yes. The API uses headless browser technology to render JavaScript-heavy pages and extract data from frameworks like React, Angular, and Vue.js. This mimics real browser behavior to bypass anti-scraping measures.
What is session persistence and do you support it?
Session persistence keeps the same user session across multiple requests by using sticky IPs and preserving cookies, headers, and authentication tokens. This helps you track data changes over time, access account-specific content, and avoid repeated CAPTCHAs. You can enable this feature in our ZoomInfo scraper API by entering a session name in the Session ID field, or adding a session_id code line into your request.
What happens if a request fails?
ZoomInfo scraper API automatically retries failed requests with different IPs and optimized settings to work around CAPTCHAs, rate limits, and server errors.
What unblocking solutions are built into the ZoomInfo scraper API?
The scraper combines automatic IP rotation, integrated browser fingerprints, and JavaScript rendering to handle anti-bot measures like CAPTCHAs and IP blocks. The API also includes access to 125M+ IPs spanning 195+ locations for geo-targeting and IP diversity.
Start Scraping ZoomInfo Data Today
Extract B2B to gain market insights and get ahead of the competition, all without CAPTCHAs or IP blocks.
14-day money-back option