Wikipedia Scraper API
Collect article content, infoboxes, citations, and more with our ready-to-use Wikipedia scraper API* – real-time results without CAPTCHAs, IP blocks, or setup hassles.
* This scraper is now a part of the Web Scraping API.
125M+
IPs worldwide
99.99%
success rate
200
requests per second
100+
ready-made templates
Free
starter plan
Be ahead of the Wikipedia scraping game
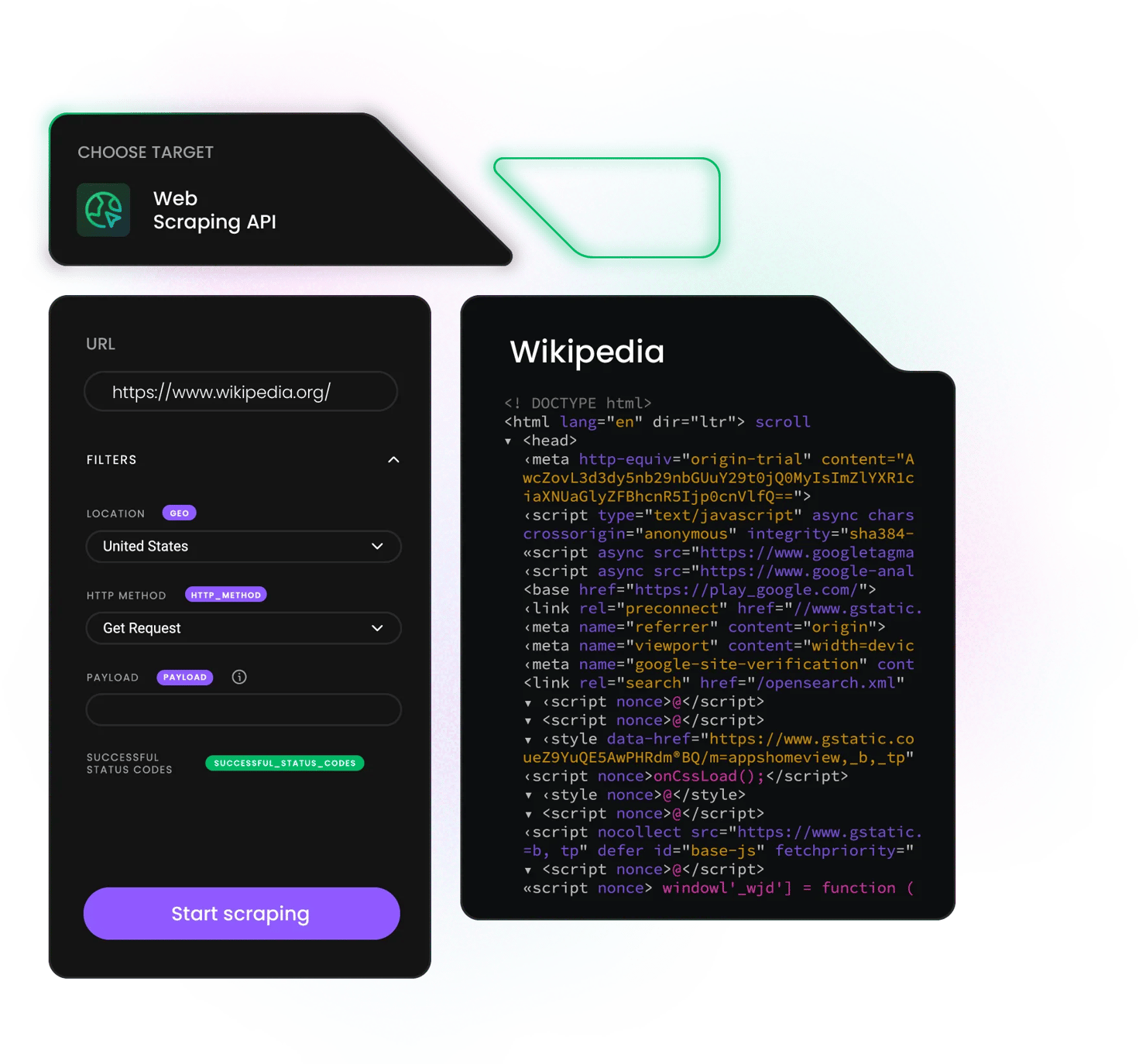
Extract data from Wikipedia
Web Scraping API is a powerful data collector that combines a web scraper and a pool of 125M+ residential, mobile, ISP, and datacenter proxies.
Here are some of the key data points you can extract with it:
- Article titles, summaries, and full content
- Infobox data (dates, locations, statistics)
- Internal and external links
- Categories and page hierarchies
- Tables, references, and citations
What is a Wikipedia scraper?
A Wikipedia scraper is a solution that extracts data from the Wikipedia website.
With our Web Scraping API, you can send a single API request and receive the data you need in HTML format. Even if a request fails, we’ll automatically retry until the data is delivered. You'll only pay for successful requests.
Designed by our experienced developers, this tool offers you a range of handy features:
Built-in scraper
JavaScript rendering
Easy API integration
195+ geo-locations, including country-, state-, and city-level targeting
No CAPTCHAs or IP blocks
Scrape Wikipedia with Python, Node.js, or cURL
Our Wikipedia Scraper API supports all popular programming languages for hassle-free integration with your business tools.
Unlock the full potential of Wikipedia scraper API
Scrape Wikipedia with ease using our powerful API. From JavaScript rendering to built-in proxy integration, we help you get the data you need without blocks or CAPTCHAs.
Flexible output options
Retrieve clean HTML results ready for your custom processing needs.
100% success
Get charged for the Wikipedia data you actually receive – no results means no costs.
Real-time or on-demand results
Decide when you want your data: scrape instantly, or schedule the request for later.
Advanced anti-bot measures
Use advanced browser fingerprinting to navigate around CAPTCHAs and detection systems.
Easy integration
Plug our Wikipedia scraper into your apps with quick start guides and code examples.
Proxy integration
Access data globally with 125M+ global IPs to dodge geo-blocks and IP bans.
API Playground
Run test requests instantly through our interactive API Playground available in the dashboard.
What does Web Scraping API cost?
Choose a plan based on your scraping volume. All plans include the same powerful features – you only pay for what you use. Start with the free plan to test before committing.
Plan prices
+VAT / Billed monthly
Rate limit
All prices shown are per 1K req.
Plan price
$0
+VAT / Billed monthly
Request type
Price per 1k req.
2K req.
$0.50
1K req.
$0.75
1K req.
$1.00
667 req.
$1.50
Rate limit
10 req/s
Plan price
$19
+VAT / Billed monthly
Request type
Price per 1k req.
38K req.
$0.50
25K req.
$0.75
19K req.
$1.00
12K req.
$1.50
Rate limit
10 req/s
Plan price
$49
+VAT / Billed monthly
Request type
Price per 1k req.
163K req.
$0.30
75K req.
$0.65
54K req.
$0.90
39K req.
$1.25
Rate limit
25 req/s
Plan price
$99
+VAT / Billed monthly
Request type
Price per 1k req.
707K req.
$0.14
165K req.
$0.60
116K req.
$0.85
82K req.
$1.20
Rate limit
50 req/s
Need more?
Request type
Price per 1k req.
Custom
Custom
Custom
Custom
Rate limit
Custom
For low-security sites and simple access
For accessing guarded or sensitive pages
With each plan, you access:
99.99% success rate
Results in HTML, JSON, CSV, XHR or PNG
MCP server
JavaScript rendering
AI integrations
100+ pre-built templates
Supports search, pagination, and filtering
LLM-ready markdown format
24/7 tech support
14-day money-back
SSL Secure Payment
Your information is protected by 256-bit SSL

What people are saying about us
We're thrilled to have the support of our 130K+ clients and the industry's best
Attentive service
The professional expertise of the Decodo solution has significantly boosted our business growth while enhancing overall efficiency and effectiveness.
N
Novabeyond
Easy to get things done
Decodo provides great service with a simple setup and friendly support team.
R
RoiDynamic
A key to our work
Decodo enables us to develop and test applications in varied environments while supporting precise data collection for research and audience profiling.
C
Cybereg
Trusted by:
Decodo blog
Build knowledge on our solutions and improve your workflows with step-by-step guides, expert tips, and developer articles.
Most recent

Bots vs. Humans: How AI Tools Are Rewriting Who Uses the Internet
In June 2026, bot traffic vs human traffic flipped for the first time. Cloudflare Radar measured 57.4% of web requests as automated and 42.6% as human. AI tools drove the change. This article breaks down where bots dominate, which countries skew human, and what businesses building or buying AI tools should do about it.
Benediktas Kazlauskas
Last updated: Jul 08, 2026
5 min read
Most popular
Residential vs Datacenter Proxies: Which Should You Choose?
At first glance, residential and datacenter proxies may seem the same. Both types act as intermediaries that hide your IP address, allowing you to access restricted websites and geo-blocked content. However, there are some important differences between residential and datacenter proxies that you should know before making a decision. We’re happy to walk you through the differences so you can choose what's right for you.
Vilius Sakutis
Last updated: Apr 22, 2026
7 min read

Google Sheets Web Scraping: An Ultimate Guide for 2026
Google Sheets is a powerful data management tool, but few people know it can also pull data directly from the web without a single line of code. Using built-in import functions, you can scrape website content, parse tables, and pull live feeds straight into your spreadsheet. In this guide, you'll learn how to use IMPORTXML for XPath-based data extraction, IMPORTHTML for grabbing tables and lists, IMPORTFEED for RSS and Atom content, IMPORTDATA for CSV files, and IMPORTRANGE to link scraped data across spreadsheets. We'll also cover Google Apps Script for automation, common errors and how to fix them, and when to reach for a dedicated scraping tool instead.
Zilvinas Tamulis
Last updated: Mar 30, 2026
6 min read

Manage Your Business Reputation with SERP Scraping API
A widely available internet leaves the door open for people to find information about everything. For example, everyone can check a business's online presence before trusting it. So, everything that could be found online about your brand helps your potential audience evaluate if you’re legit.
Statistics only prove that – 9 out of 10 online shoppers admit that reviews influence their buying decisions. It stands to reason – checking unbiased opinions helps avoid low-value products and potential scams. And who wants that? So, for businesses analyzing their customers’ reviews becomes a not-to-miss-out factor.
However, reviews are just one part of the game. Brand reputation management consists of various elements that form the customers' perception of the company. If it’s still a gray area for you, this blog post could be your starting point.
Ella Moore
Last updated: Jun 20, 2022
7 min read

How to Scrape Google Without Getting Blocked
Nowadays, web scraping is essential for any business interested in gaining a competitive edge. It allows quick and efficient data extraction from a variety of sources and acts as an integral step toward advanced business and marketing strategies.
If done responsibly, web scraping rarely leads to any issues. But if you don’t follow data scraping best practices, you become more likely to get blocked. Thus, we’re here to share with you practical ways to avoid blocks while scraping Google.
James Keenan
Last updated: Feb 20, 2023
8 min read

What Is SERP Analysis And How To Do It?
SERP (Search Engine Results Page) analysis involves examining search engine results for specific keywords to understand website rankings. It helps identify the content, format, and optimization strategies used by top-ranking pages and uncovers opportunities for improving rankings. In this blog post, we’re exploring what SERP analysis is, how to conduct it, and how it can help you.
James Keenan
Last updated: Feb 20, 2023
7 min read

What is an API?
An application programming interface (API) works like a messenger. It allows different software systems to communicate without developers having to build custom links for every connection. For instance, one service might supply map data to a mobile app, while another handles payment processing for online transactions. In these times, that demands seamless integration, and APIs play a vital role. They automate tasks, enable large-scale data collection, and support sophisticated functions like web scraping and proxy management. By bridging diverse platforms and streamlining data exchange, they help businesses stay competitive and reduce the complexity of managing multiple, often inconsistent endpoints.
Kotryna Ragaišytė
Last updated: Mar 06, 2025
6 min read
How to Scrape Hotel Listings: Unlocking the Secrets
Scraping hotel listings is a powerful tool for gathering comprehensive data on accommodations, prices, and availability from various online sources. Whether you're looking to compare rates, analyze market trends, or create a personalized travel plan, scraping allows you to efficiently compile the information you need. In this article, we'll explain how to scrape hotel listings, ensuring you can leverage this data to its fullest potential.
Vilius Sakutis
Last updated: Nov 13, 2025
5 min read

What is Data Scraping? Definition and Best Techniques (2026)
The data scraping tools market is growing significantly, valued at approximately $875.46M in 2026. The market is projected to grow more due to the increasing demand for real-time data collection across various industries.
Vytautas Savickas
Last updated: Jan 30, 2026
6 min read

How to Scrape YouTube Search Results With Web Scraping API
OK, OK. You prolly know it already, but let us remind ya. YouTube is a site that allows users to upload, watch, and interact with videos. Since 2005, it has become the MVP platform for various things – starting from storing fav clips or songs and ending with marketing for companies to promote their products.
Hundreds of hours of content are uploaded to YouTube every minute. It means it’s impossible to scrape the search results manually, well, unless you're a superhero. Fortunately, we have great news – our Web Scraping API can do the job for ya.
Mariam Nakani
Last updated: Aug 12, 2022
3 min read

Web Crawling vs Web Scraping: What’s the Difference?
When it comes to gathering online data, two terms often create confusion: web crawling and web scraping. Although both involve extracting information from websites, they serve different purposes and employ distinct methods. In this article, we’ll break down these concepts, show you how they work, and help you decide which one suits your data extraction needs.
Justinas Tamasevicius
Last updated: Jul 01, 2025
7 min read
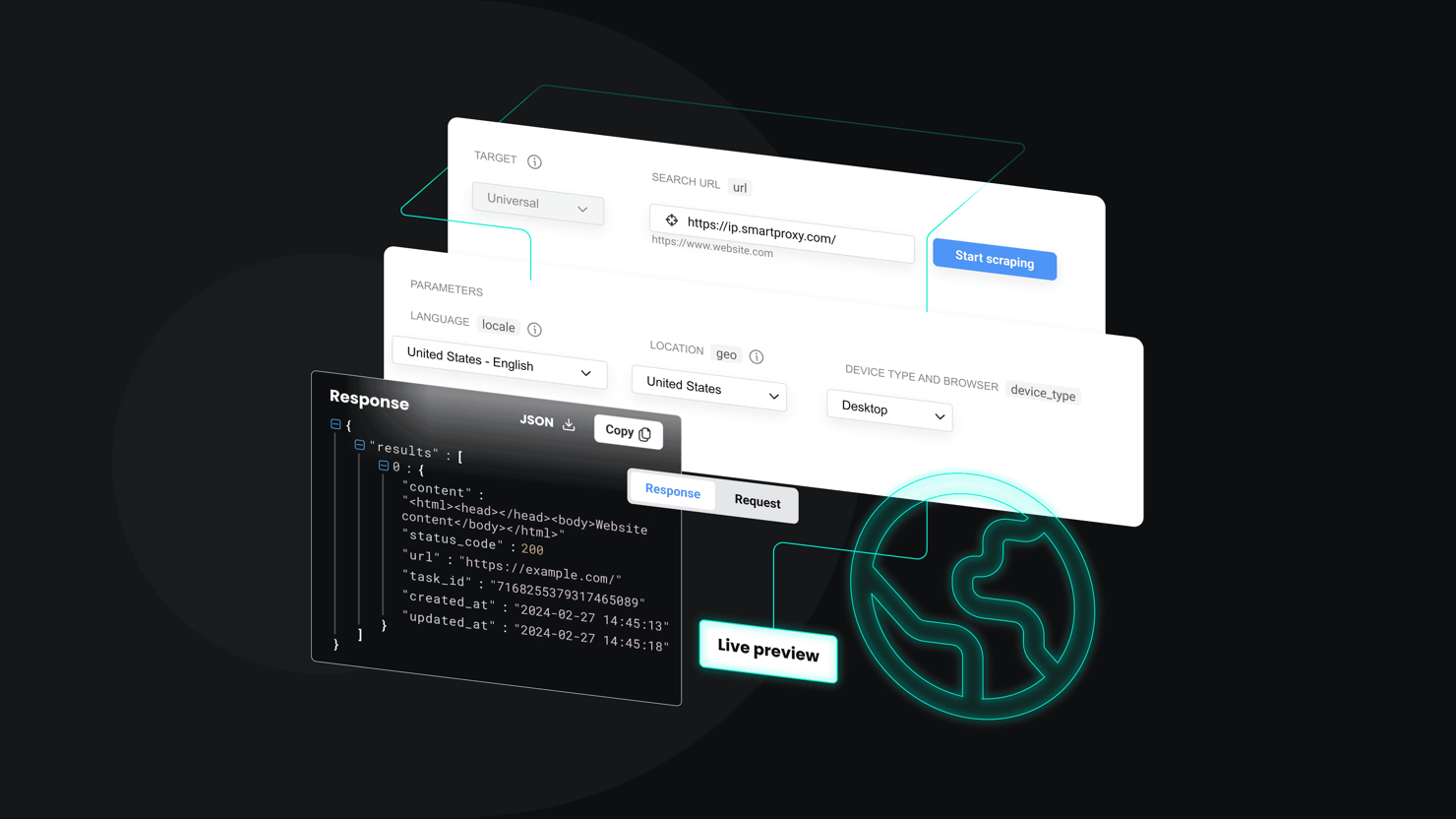
What Is Web Scraping? A Complete Guide to Its Uses and Best Practices
Web scraping is a powerful tool driving innovation across industries, and its full potential continues to unfold with each day. In this guide, we'll cover the fundamentals of web scraping – from basic concepts and techniques to practical applications and challenges. We’ll share best practices and explore emerging trends to help you stay ahead in this dynamic field.
Dominykas Niaura
Last updated: Jan 29, 2025
10 min read

Beautiful Soup Web Scraping: How to Parse Scraped HTML with Python
Web scraping with Python is a powerful technique for extracting valuable data from the web, enabling automation, analysis, and integration across various domains. Using libraries like Beautiful Soup and Requests, developers can efficiently parse HTML and XML documents, transforming unstructured web data into structured formats for further use. This guide explores essential tools and techniques to navigate the vast web and extract meaningful insights effortlessly.
Zilvinas Tamulis
Last updated: Mar 25, 2025
14 min read
Frequently asked questions
Is it legal to scrape data from Wikipedia?
Yes, scraping publicly available data from Wikipedia is generally legal as long as you comply with its Terms of Use and the Creative Commons Attribution-ShareAlike License (CC BY-SA 3.0). Wikipedia’s content is openly available for reuse, modification, and distribution, provided you give appropriate attribution, indicate any changes made, and maintain the same licensing.
We also recommend consulting a legal professional to ensure compliance with local data collection laws and the website’s Terms and Conditions.
What are the most common methods to scrape Wikipedia?
You can extract publicly available data from Wikipedia using a few methods. Depending on your technical knowledge, you can use:
- MediaWiki API – ideal for structured access to content like page summaries, categories, and revisions. Supports JSON output, rate-limited but reliable.
- Python libraries – use tools like wikipedia, wikitools, or mwclient to interact with Wikipedia’s API in an object-oriented way.
- HTML parsing with custom scripts – when the API doesn’t offer what you need (e.g., full page layout), fall back on tools like Beautiful Soup or Scrapy for direct scraping from the website.
- Page dumps – Wikimedia also provides full content dumps in XML or SQL format, best suited for offline analysis or large-scale data mining.
- All-in-one scraping API – tools like Decodo’s Web Scraping API help users to collect real-time data from Wikipedia with just a few clicks.
How can I scrape Wikipedia using Python?
Python is one of the most efficient languages for scraping Wikipedia thanks to its rich ecosystem of libraries. Here's how to get started:
- Using the Wikipedia API with the wikipedia library:
- Using Requests and BeautifulSoup for HTML parsing:
For large-scale or structured scraping, use Scrapy, which offers advanced control over crawling and data pipelines.
How do proxy servers help in scraping Wikipedia?
While Wikipedia is relatively open, proxy servers can still be useful when scraping at scale:
- Bypass IP rate limits – Wikipedia monitors request frequency per IP. Rotating proxies help distribute traffic.
- Avoid CAPTCHAs – though rare, some automated detection systems may present CAPTCHAs, proxies help reduce this risk.
- Geo-specific scraping – in some research scenarios, accessing localized versions of Wikipedia may require proxies from specific regions.
Why is Wikipedia a valuable source for data scraping?
Wikipedia is one of the most comprehensive, community-driven, and regularly updated encyclopedias on the internet. It’s valuable for:
- Research and academic studies
- Knowledge graphs and semantic search
- AI and LLMs training
- Market trend analysis
- Content enhancing
What are the benefits of using a Wikipedia scraper for businesses?
Businesses can leverage Wikipedia data for a wide range of use cases:
- Track emerging trends and brand mentions.
- Running market research.
- Enhance SEO strategy by discovering long-tail keywords and expanding topic coverage.
- Training machine learning algorithms and NLP models using high-quality textual data.
- Automatically enrich internal databases or chatbots with publicly available data.
- Enhancing content with publicly available information.
Wikipedia Scraper API for Your Data Needs
Gain access to real-time data at any scale without worrying about proxy setup or blocks.
14-day money-back option