Proxy for Scraping Amazon: The Ultimate Guide
Scraping Amazon without proxies leads to IP bans, CAPTCHAs, and rate limits, making data collection nearly impossible. Proxies are essential for bypassing these defenses and accessing vital pricing and product data. This guide explains why scraping Amazon is challenging, how proxies can help, and which types of proxies are most effective for reliable, large-scale Amazon data extraction.
Dominykas Niaura
Last updated: May 05, 2025
5 min read
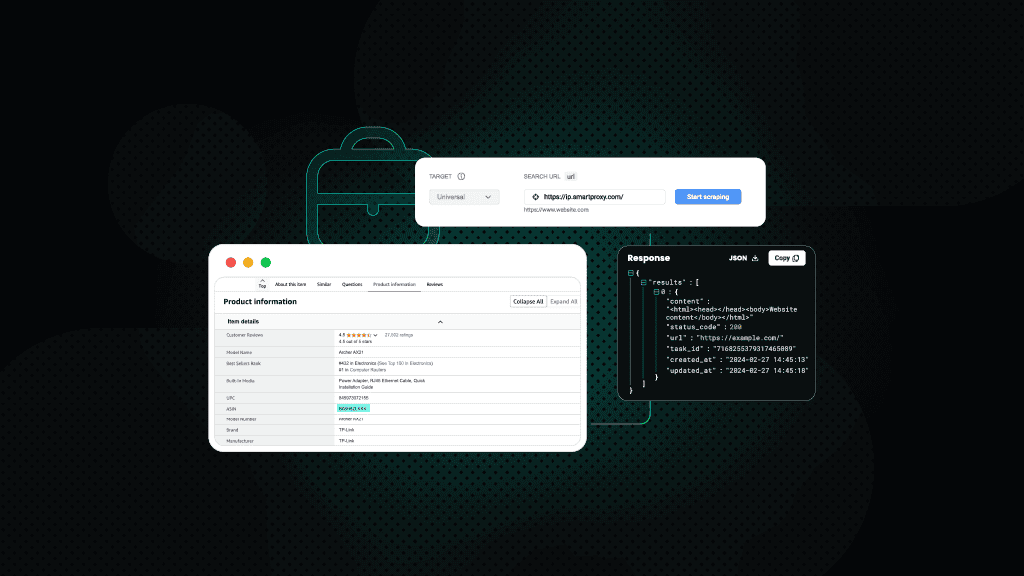
Why you need a proxy for scraping Amazon
Amazon has strict anti-scraping defenses, including IP tracking, bot detection, and aggressive rate limiting. If you send thousands of requests from a single IP, Amazon will treat it as suspicious behavior and block you almost instantly.
Proxies solve this issue by masking your IP address and distributing requests across a pool of different IPs, especially with rotating proxies that assign a new IP for every connection. This makes your scraping activity appear more human-like and much harder to detect.
Besides bypassing restrictions, proxies also give you access to geo-restricted content and let you make multiple concurrent requests without raising flags. This is crucial when you're scraping at scale.
How to choose the right proxy
Before diving into proxy types, it’s important to understand how to choose the right proxy setup for your needs. Key factors include speed, anonymity, cost, and rotation frequency.
High-speed proxies ensure fast data extraction, while strong anonymity helps avoid detection by Amazon’s anti-bot systems. For large-scale scraping, proxies with frequent rotation are essential to distribute requests and mimic organic traffic patterns.
Avoid free proxies at all costs – they're slow, unreliable, and often shared by multiple users. Worse yet, many free proxy services log your data or inject malware if you download their applications. Paid proxies offer dedicated IPs, better performance, and much-needed security when dealing with a platform as strict as Amazon.
For reliable Amazon scraping, we recommend a trusted proxy provider, like Decodo, Oxylabs, Webshare, or another established industry leader. They offer features tailored for web scraping, such as dependable IPs, high uptime, and support for handling CAPTCHAs and rate limits.
Best types of proxies for scraping Amazon
Not all proxies are created equal, especially when it comes to scraping difficult websites like Amazon. The type of proxy you use can make or break your operation.
Datacenter proxies are fast and cheap but also the most likely to get blocked. These IPs come from cloud servers and often share the same subnet. If Amazon bans one, the entire subnet might go down, taking hundreds of your IPs with it.
Mobile proxies offer the highest level of anonymity by using real mobile network IPs. They’re great for tough targets like Amazon, but they come at a premium price.
Residential proxies are the most effective option. Since they come from real user devices with legitimate ISPs, they're much harder for Amazon to detect and block. They're ideal for long-term, consistent scraping without raising red flags.
For large-scale scraping, make sure your proxies are the rotating kind. Such proxies automatically switch IP addresses with each request or at set intervals, helping you avoid detection and manage high-volume data extraction efficiently.
Choosing the right proxies depends on your budget, the scale of your scraping, and your need for reliability. For most users, a large pool of rotating residential proxies is the best choice.
Setting up a proxy for Amazon scraping
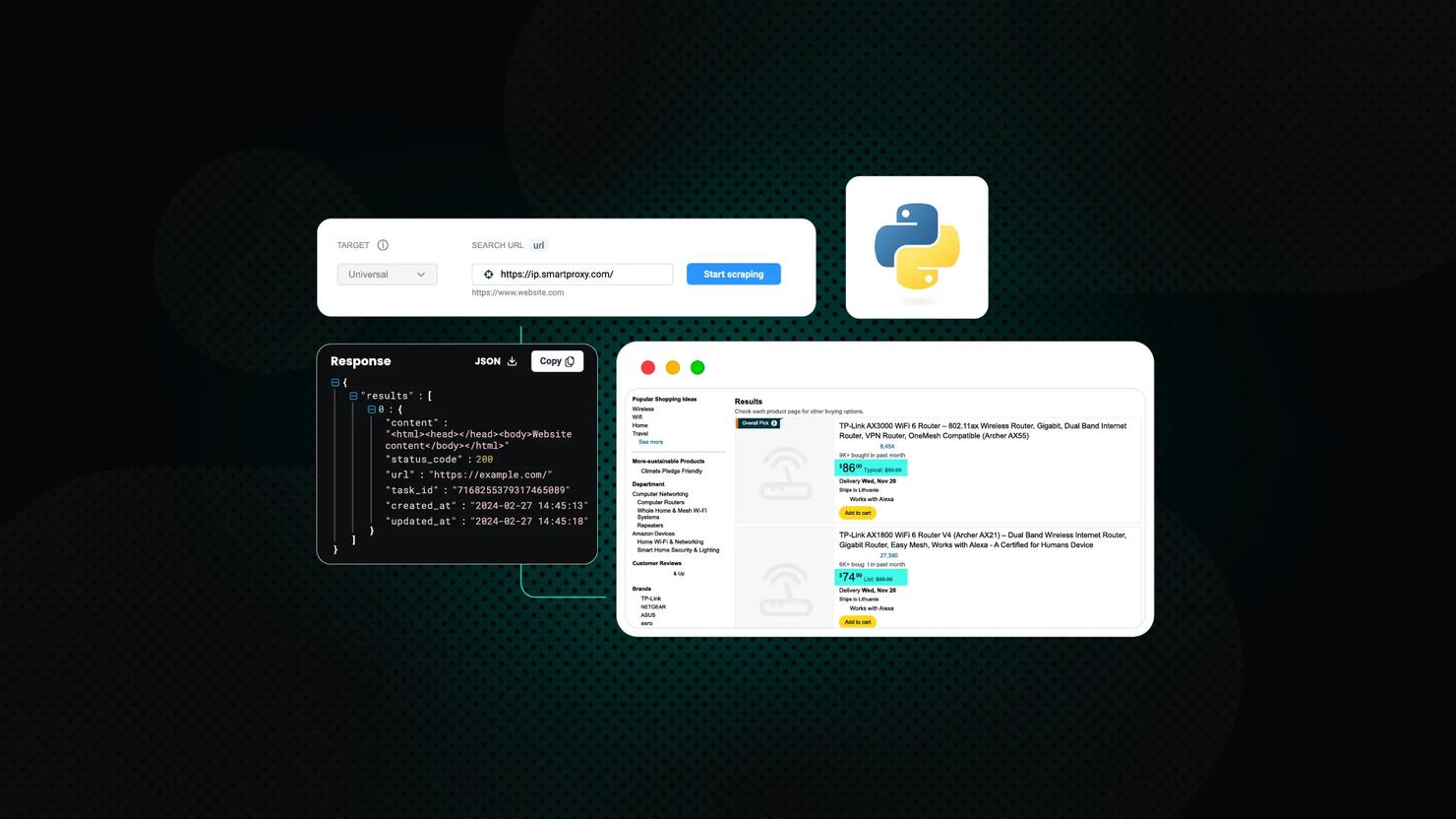
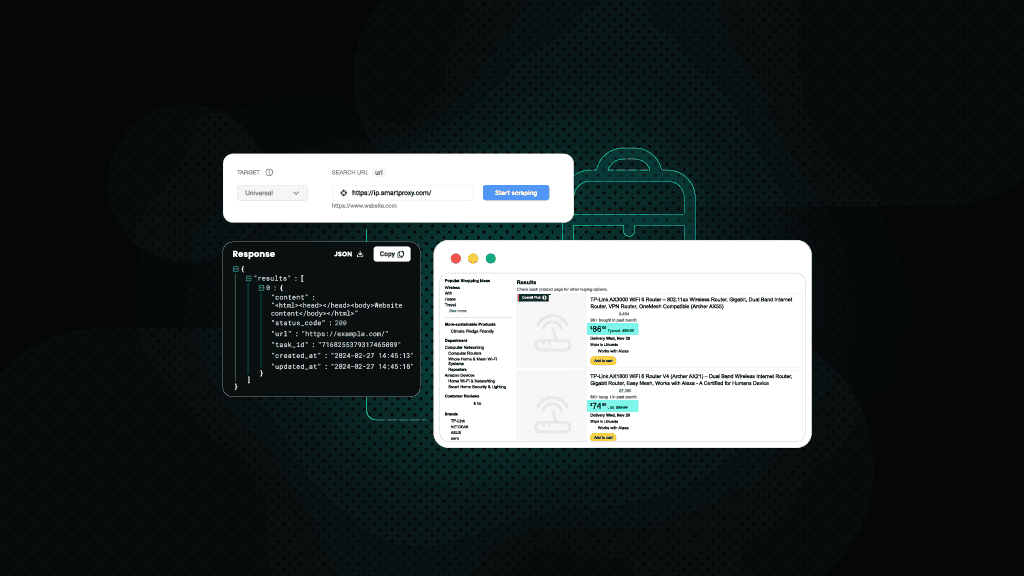
Setting up your scraper correctly is just as important as choosing the right proxy. Whether you’re using Python with Requests, Scrapy, or Selenium, most libraries let you easily configure proxies by passing them as parameters. For example, in Requests, you can use the proxies argument; in Scrapy, set proxies in the middleware; and in Selenium, configure them through browser options.
Implementing Decodo's proxies into your scraping script is quick and easy. After purchasing a proxy plan on the dashboard, head to the Proxy setup tab to find and customize your proxy endpoint. If you select Python from the language options below, you'll see a code snippet showing how to use the Requests library with your proxy credentials:
Alternatively, if you're scraping through a browser (manually or via automation tools like Puppeteer or Selenium), proxies can be set up using browser extensions or through launch arguments. This is useful when you need to interact with JavaScript-heavy pages or simulate real user behavior. Decodo offers convenient free browser extensions for Chrome and Firefox, allowing you to manage and switch proxies directly from your browser.
To avoid detection, it’s crucial to rotate user agents, introduce realistic delays, and use headless browsers, which simulate a browser without displaying the UI. Also, clear cookies and cache, and set your scraper to mimic real user behavior, such as scrolling, clicking, and hovering.
Always test your setup on small data batches to debug issues early, and regularly check your scraped results for quality and completeness. The more human-like your scraper appears, the better your chances of staying under Amazon’s radar.
To streamline the scraping process, you can opt for a scraping API that includes automatic proxy rotation, CAPTCHA solving, and built-in rate limit handling. Tools like our Amazon scraper deliver fast, structured data and come with solid documentation for easy integration.
Common challenges & how to overcome them
The primary hurdle when scraping Amazon is probably its anti-bot systems, which are some of the toughest around. One common challenge is CAPTCHA walls triggered by suspicious behavior. To handle this, use scraping tools or APIs that support automated CAPTCHA solving, or integrate third-party solvers like 2Captcha or Anti-Captcha.
IP bans are another major roadblock. They often happen when too many requests are made from the same IP within a short time. Avoid this by using rotating residential or mobile proxies, randomizing request patterns, and limiting the frequency of your scraping to stay under the radar.
Bot detection can also be triggered by things like missing headers, odd behavior patterns, or using the same user agent repeatedly. Always set realistic user agents, rotate them regularly, and simulate human-like interaction with delays, mouse movements, and page scrolling.
Alternatives to scraping Amazon
While scraping can unlock a wealth of product and pricing data, it’s not the only option. One alternative is to use Amazon’s official API, such as the Product Advertising API. It provides structured access to product details, pricing, and availability. However, usage is limited and requires approval, making it less flexible for large-scale data collection.
Another option is to rely on third-party price tracking tools like Keepa or CamelCamelCamel. These services already monitor Amazon pricing trends and can give you historical and real-time data through their own APIs or dashboards, saving you time and effort on building and maintaining scrapers.
If your goal is to analyze trends or monitor competitors, these alternatives can be reliable, low-maintenance solutions, especially when scraping isn’t feasible.
To sum up
Scraping Amazon is tough due to strict anti-bot measures, but with the right setup, it’s indeed possible. Using rotating residential proxies, handling CAPTCHAs, mimicking human behavior, and avoiding free proxies are key to staying undetected. When done right, scraping can help your business compete with better data without getting blocked in the process.
About the author

Dominykas Niaura
Technical Copywriter
Dominykas brings a unique blend of philosophical insight and technical expertise to his writing. Starting his career as a film critic and music industry copywriter, he's now an expert in making complex proxy and web scraping concepts accessible to everyone.
Connect with Dominykas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.