
Decodo Knowledge Hub
The go-to place for developers and curious minds. Here you'll find many tutorials, integrations and code guides to immediately start building or setting up your next application together with Decodo proxies.
Getting started with Decodo solutions
What are proxies?
A proxy is an intermediary between your device and the internet, forwarding requests between your device and the internet while masking your IP address.
Residential Proxies
Real, physical device IPs that provide a genuine online identity and enhance your anonymity online. Learn more
ISP Proxies
IPs assigned by Internet Service Providers (ISPs), offering efficient and location-specific online access with minimal latency. Learn more
Mobile Proxies
Mobile device based IPs offering anonymity and real user behavior for mobile-related activities on the internet. Learn more
Datacenter Proxies
Remote computers with unique IPs for tasks requiring scalability, fast response times, and reliable connections. Learn more
Site Unblocker
A powerful application for all proxying activities offering dynamic rendering, browser fingerprinting, and much more. Learn more
Find the right integrations for your project
Easy Decodo proxy setup with popular applications and third-party tools. Check out these guides to get started right away.

Chrome
Learn more

Safari
Learn more

Firefox
Learn more
Edge
Learn more
Decodo Chrome Extension
Learn more
Decodo Firefox Extension
Learn more

FoxyProxy extension
Learn more
Insomniac
Learn more
SwitchyOmega extension
Learn more

Ghost
Learn more

iPhone
Learn more

Android
Learn more

Waterfox
Learn more
Axios
Learn more
Shadowrocket
Learn more
Dolphin Anty
Learn more
Discover our scraping templates
Explore our extensive template library for all your scraping needs.






Decodo blog
Most recent

Bots vs. Humans: How AI Tools Are Rewriting Who Uses the Internet
In June 2026, bot traffic vs human traffic flipped for the first time. Cloudflare Radar measured 57.4% of web requests as automated and 42.6% as human. AI tools drove the change. This article breaks down where bots dominate, which countries skew human, and what businesses building or buying AI tools should do about it.
Benediktas Kazlauskas
Last updated: Jul 08, 2026
5 min read
Most popular

How to Send a cURL GET Request
Tired of gathering data inefficiently? Well, have you tried cURL? It’s a powerful and versatile command-line tool for transferring data with URLs. Its simplicity and wide range of capabilities make it a go-to solution for developers, data analysts, and businesses alike. Simply put, the cURL GET request method is the cornerstone of web scraping and data gathering. It enables you to access publicly available data without the need for complex coding or expensive software. In this blog post, we’ll explain how to send cURL GET requests, so you’re ready to harness its fullest potential.
Dominykas Niaura
Last updated: Jan 02, 2024
7 min read

How to Bypass CAPTCHA With Puppeteer: A Step-By-Step Guide
Since their inception in 2000, CAPTCHAs have been crucial for website security, distinguishing human users from bots. They are a savior for website owners and a nightmare for data gatherers. While CAPTCHAs enhance website integrity, they pose challenges for those reliant on automated data gathering. In this comprehensive guide, we delve into the fundamentals of Puppeteer, focusing on techniques for CAPTCHA detection and avoidance using Puppeteer. We also explore strategies for how to bypass CAPTCHA verification, methods for solving CAPTCHAs with specialized third-party services, and the alternative solutions provided by our Site Unblocker.
Dominykas Niaura
Last updated: Dec 04, 2023
10 min read

A Complete Guide to Web Data Parsing Using Beautiful Soup in Python
Beautiful Soup is a widely used Python library that plays a vital role in data extraction. It offers powerful tools for parsing HTML and XML documents, making it possible to extract valuable data from web pages effortlessly. This library simplifies the often complex process of dealing with the unstructured content found on the internet, allowing you to transform raw web data into a structured and usable format.
HTML document parsing plays a pivotal role in the world of information. The HTML data can be used further for data integration, analysis, and automation, covering everything from business intelligence to research and beyond. The web is a massive place full of valuable information; therefore, in this guide, we’ll employ various tools and scripts to explore the vast seas and teach them to bring back all the data.
Zilvinas Tamulis
Last updated: Nov 16, 2023
14 min read

Scraping the Web with Selenium and Python: A Step-By-Step Tutorial
Modern websites rely heavily on JavaScript and anti-bot measures, making data extraction a challenge. Basic tools fail with dynamic content loaded after the initial page, but Selenium with Python can automate browsers to execute JavaScript and interact with pages like a user. In this tutorial, you'll learn to build scrapers that collect clean, structured data from even the most complex websites.
Dominykas Niaura
Last updated: Jul 30, 2025
10 min read
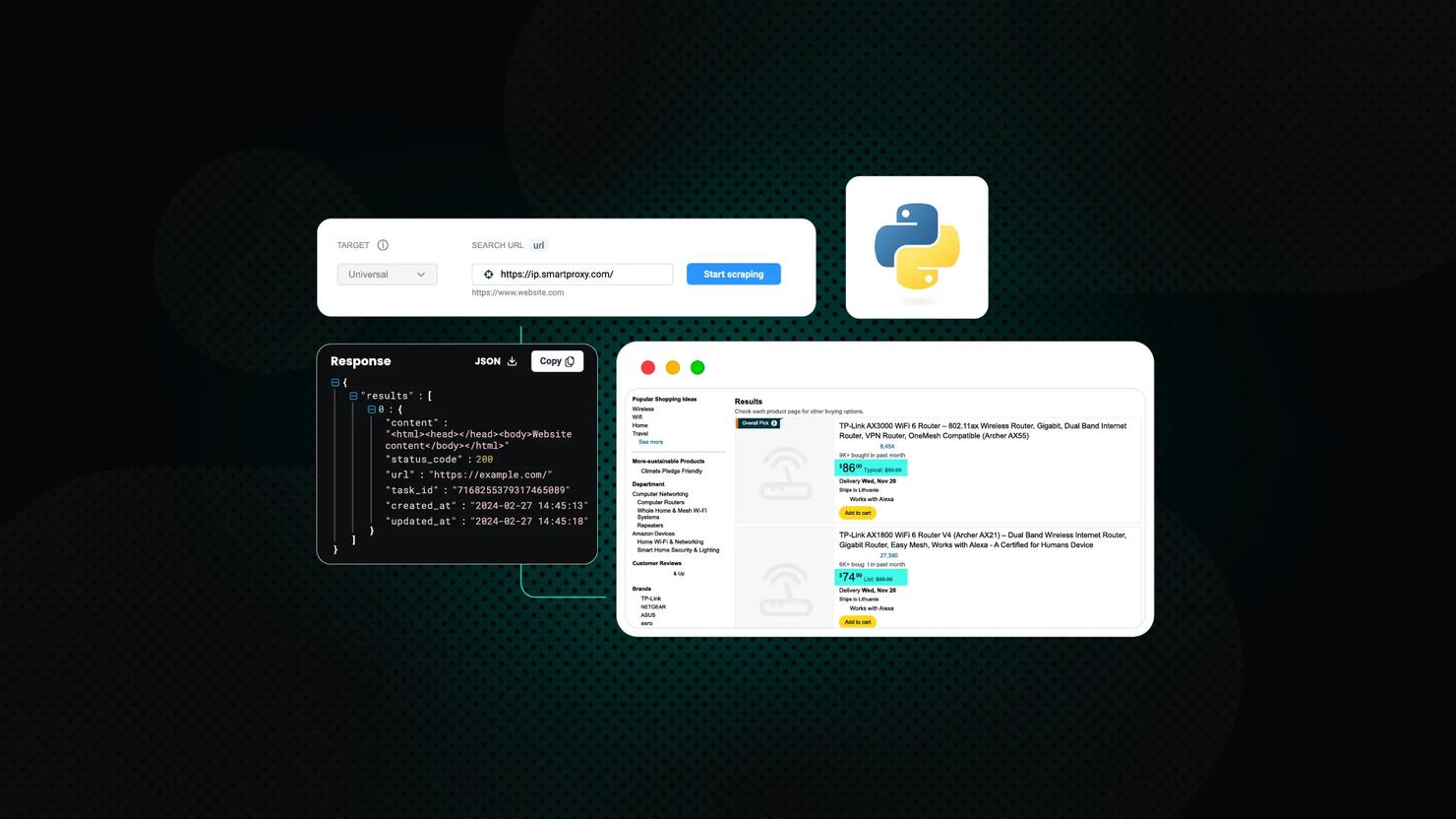
Scraping Amazon Product Data Using Python: Step-by-Step Guide
This comprehensive guide will teach you how to scrape Amazon product data using Python. Whether you’re an eCommerce professional, researcher, or developer, you’ll learn to create a solution to extract valuable insights from Amazon’s marketplace. By following this guide, you’ll acquire practical knowledge on setting up your scraping environment, overcoming common challenges, and efficiently collecting the needed data.
Zilvinas Tamulis
Last updated: Mar 27, 2025
15 min read

A Comprehensive Guide on Using Proxy with cURL in 2026
Whether you're a developer or an IT professional, data is an essential element of your everyday tasks. One of the most popular tools for data transfer is cURL (client for URL), which is embedded in almost every device that transfers data over different internet protocols.
However, when it comes to transferring data through a proxy, using cURL becomes even more critical. So, let's delve into the basics of cURL and proxies, discuss how it works, and get valuable tips on how to use cURL with proxy settings.
So, buckle up, pal, and get ready to learn how to use cURL with proxy and why it is essential in data transfer.
Vytautas Savickas
Last updated: Jan 14, 2026
7 min read
How to Bypass CAPTCHAs: The Ultimate Guide 2026
So, there you are, casually surfing the net, when… a CAPTCHA appears out of the blue, interrupting your flow. Yes, it’s that little test making sure you’re not a robot, and let’s face it – it can really slow down your processes. The great news? You don’t have to be stuck. It’s possible to bypass CAPTCHAs. So, buckle up, and let’s dive into the tricks that make these roadblocks the past.
Martin Ganchev
Last updated: Jan 15, 2026
10 min read
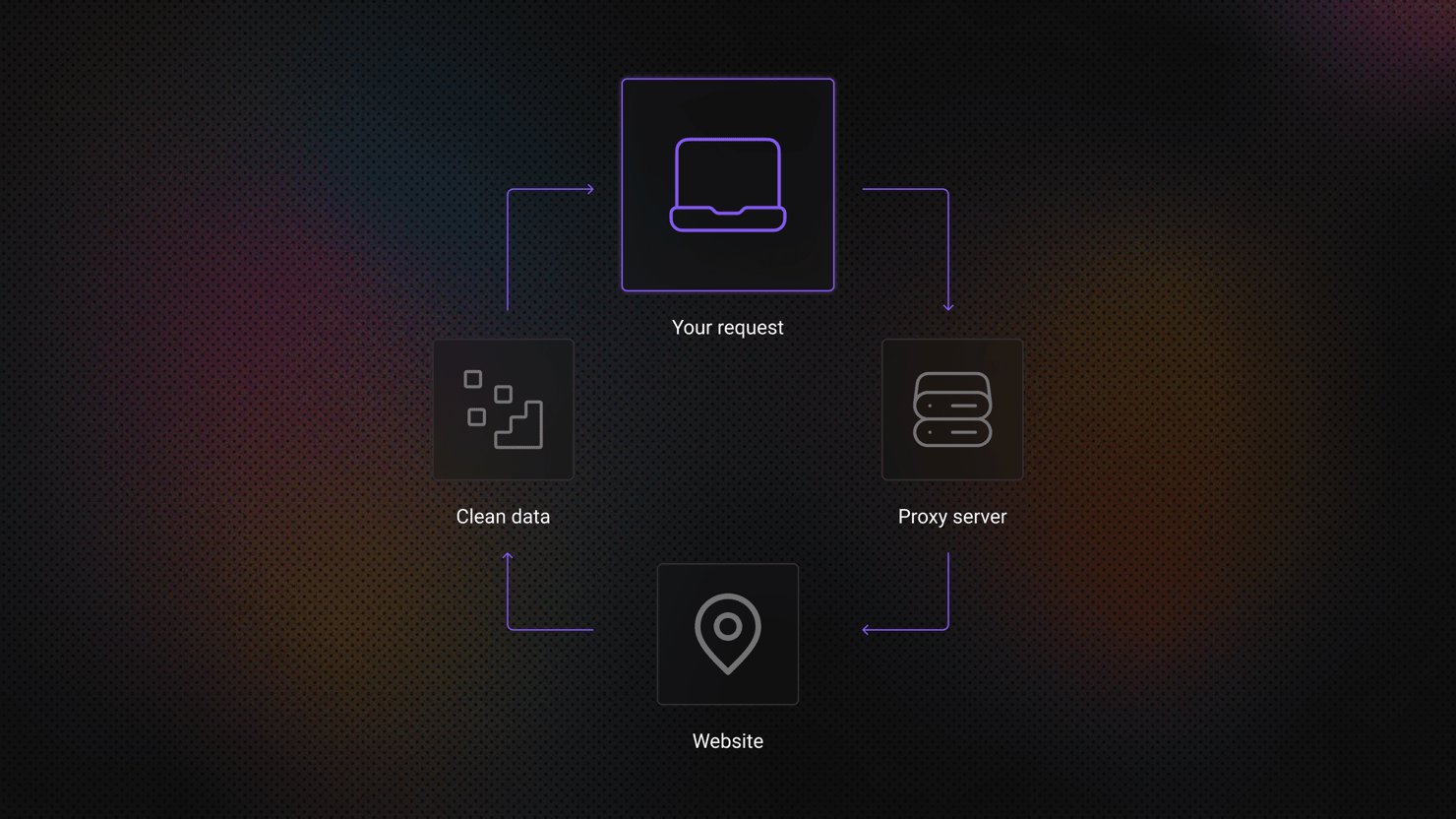
What Is an SSL/HTTPS Proxy: How It Works and When to Use It
An SSL proxy, often called an HTTPS proxy, is an intermediary server that forwards web requests between a user and a website through an encrypted HTTPS connection. Instead of connecting directly to the destination server, the client routes traffic through the proxy, which helps secure data transmission and manage outgoing requests.
Lukas Mikelionis
Last updated: Mar 18, 2026
4 min read

What to do when getting parsing errors in Python?
This one’s gonna be serious. But not scary. We know how frightening the word “programming” could be for a newbie or a person with a little technical background. But hey, don’t worry, we’ll make your trip in Python smooth and pleasant. Deal? Then, let’s go!
Python is widely known for its simple syntax. On the other hand, when learning Python for the first time or coming to Python after having worked with other programming languages, you may face some difficulties. If you’ve ever got a syntax error when running your Python code, then you’re in the right place.
In this guide, we’ll analyze common cases of parsing errors in Python. The cherry on the cake is that by the end of this article, you’ll have learnt how to resolve such issues.
James Keenan
Last updated: May 24, 2023
12 min read

What Is a Backconnect Proxy? A Complete Guide in 2026
Whether you call yourself a seasoned proxy user or just starting to leverage the power of proxies, it's always good to learn a thing or two. And this time, we're talking about backconnect proxies. In short, backconnect proxies allow you to remain anonymous while accessing the internet by constantly rotating your IP address. These proxies are useful for individuals or companies who need to navigate internet restrictions, monitor competitors, or run web scraping tools.
In this guide, we'll explore everything you need to know about backconnect proxies, how they work, and what benefits you're in for. Shall we begin?
Vytautas Savickas
Last updated: Jan 07, 2026
6 min read

How to Scrape Images From Any Website With Python
If you need a bunch of images and the thought of saving them one by one already feels tedious, you're not alone. This can be especially draining when you're preparing a dataset for a machine learning project. The good news is that web scraping makes the whole process faster and far more manageable by letting you collect large quantities of images in just a few steps. In this blog post, we'll walk you through a straightforward way to grab images from a static website. We'll use Python, a few handy libraries, and proxies to keep things running smoothly.
Dominykas Niaura
Last updated: Nov 20, 2025
10 min read
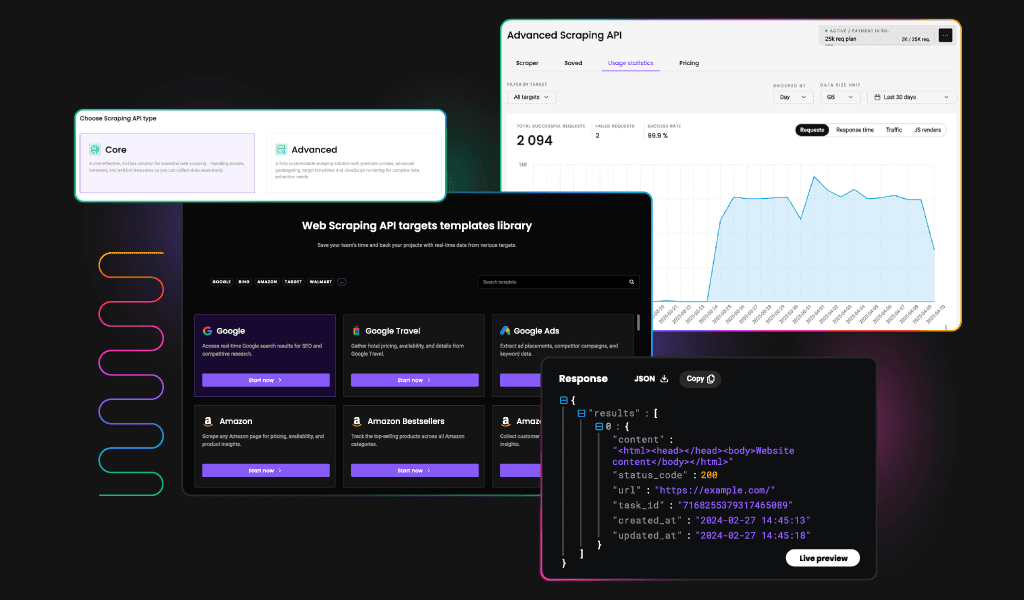
New Web Scraping API: One API for All Your Scraping Needs
Web scraping should be simple. Yet, choosing the right solution often feels like a challenge – different APIs for different targets, multiple subscriptions, and unnecessary complexity. That’s why we’re introducing a more convenient way to collect data from various targets – our four scraping APIs are becoming one, more powerful than ever, Web Scraping API. Now, you can collect data from all targets – eCommerce, SERPs, social media, and web, with one unified API.
Gabriele Vitke
Last updated: Apr 07, 2025
4 min read
How to Scrape Amazon Prices Using Excel
If you’re here, you already know Amazon constantly tweaks product prices. The eCommerce giant makes around 2.5 million price changes daily, resulting in the average item seeing new pricing roughly every ten minutes. For sellers, marketers, and savvy shoppers, that creates both a challenge and an opportunity.
This comprehensive guide walks you through proven methods – from Excel's built-in tools to powerful scraping APIs that can simplify your Amazon price monitoring workflow.
Zilvinas Tamulis
Last updated: Mar 31, 2025
8 min read

Web Crawling vs Web Scraping: What’s the Difference?
When it comes to gathering online data, two terms often create confusion: web crawling and web scraping. Although both involve extracting information from websites, they serve different purposes and employ distinct methods. In this article, we’ll break down these concepts, show you how they work, and help you decide which one suits your data extraction needs.
Justinas Tamasevicius
Last updated: Jul 01, 2025
7 min read
How to Scrape Amazon Reviews
Amazon is the go-to destination for online shoppers – and with that comes a treasure trove of customer reviews. These reviews provide invaluable insights for businesses looking to understand consumer preferences, researchers tracking market trends, and shoppers making well-informed decisions. In this guide, we’ll explore the types of data you can extract from Amazon reviews, outline various scraping methods, and show you how to efficiently scrape reviews using Python and our powerful residential proxies.
Dominykas Niaura
Last updated: Aug 04, 2025
10 min read

Difference Between SOCKS5 Proxy vs. HTTP Proxy
Choosing the right proxy type is essential for optimizing performance, security, and efficiency in web data collection. SOCKS and HTTP proxies serve different technical needs, from handling large-scale web scraping projects to managing automation and secure connections. In this article, we’ll compare SOCKS (SOCKS5 in particular) and HTTP proxies, explore their advantages, and help you determine which option best supports your data-driven tasks. By the end, you’ll have the clarity to make an informed decision and scale your operations with confidence.
Vilius Sakutis
Last updated: Mar 06, 2025
7 min read
Scrape TikTok Like a Pro: Step-by-Step Methods, Tools, and Tips
TikTok has become a goldmine of user-generated content and social media insights. With over 1 billion active users creating millions of videos daily, the platform offers unprecedented opportunities for data analysis, trend monitoring, and business intelligence. This comprehensive guide shows you how to scrape TikTok data effectively using Python.
Last updated: Jan 07, 2026
10 min read
How to Save Your Scraped Data
Web scraping without proper data storage wastes your time and effort. You spend hours gathering valuable information, only to lose it when your terminal closes or your script crashes. This guide will teach you multiple storage methods, from CSV files to databases, with practical examples you can implement immediately to keep your data safe.
Dominykas Niaura
Last updated: Aug 29, 2025
10 min read
How to Run Python Code in Terminal
The terminal might seem intimidating at first, but it's one of the most powerful tools for Python development. The terminal gives you direct control over your Python environment for such tasks as running scripts, managing packages, or debugging code. In this guide, we'll walk you through everything you need to know about using Python in the terminal, from basic commands to advanced troubleshooting techniques.
Dominykas Niaura
Last updated: Jan 20, 2026
10 min read
Random IP Address: Examples, Use Cases, Risks, and Alternatives
From web scraping to getting around geo-blocks, IPs play a huge role in how the internet works behind the scenes. But there’s a flip side – using a free or random IP from a sketchy provider can cause way more trouble than you’d expect. It can break compliance rules, mess with your data, or even lead to bigger operational and reputational problems. Dive into this article to learn more about the risks of random IP addresses.
Kotryna Ragaišytė
Last updated: Aug 19, 2025
8 min read
Top 10 MCPs for AI Workflows in 2026
MCP has shifted from niche adoption to widespread use, with major platforms like OpenAI, Microsoft, and Google supporting it natively. Public directories now feature thousands of MCP servers from community developers and vendors, covering everything from developer tools to business solutions.
In this guide, you'll learn what MCP is and why it matters for real-world AI agents, which 10 MCP servers are currently most useful, and how to safely choose and combine MCPs for your setup.
Mykolas Juodis
Last updated: Jan 13, 2026
9 min read
What Is Janitor AI? Features, Pricing, and Use Cases Guide
Launched in June 2023, Janitor AI quickly became a standout in the conversational AI space. More than just a chatbot platform, it combines human creativity with AI flexibility, making it ideal for developers building dynamic tools and casual users seeking lifelike, role-play-ready companions. Time to meet your chiseled, charismatic AI partners and see what they’re really made of.
Zilvinas Tamulis
Last updated: Aug 05, 2025
13 min read
How to Bypass Google CAPTCHA: Expert Scraping Guide 2026
Scraping Google can quickly turn frustrating when you're repeatedly met with CAPTCHA challenges. Google's CAPTCHA system is notoriously advanced, but it’s not impossible to avoid. In this guide, we’ll explain how to bypass Google CAPTCHA verification reliably, why steering clear of Selenium is critical, and what tools and techniques actually work in 2026.
Dominykas Niaura
Last updated: Apr 08, 2026
10 min read
How to Scrape Google Lens: A Step-By-Step Guide
Google Lens has revolutionized how we interact with visual content – it allows users to search the web using images rather than text queries. This powerful visual search engine can identify objects, text, landmarks, products, and much more from uploaded images. In this guide, we'll explore the types of data that can be scraped from Google Lens, examine various methods for extracting this information, and demonstrate how to efficiently collect visual search results using our Web Scraping API.
Dominykas Niaura
Last updated: Jul 24, 2025
10 min read
How to Leverage Claude for Effective Web Scraping
Web scraping has become increasingly complex as websites deploy sophisticated anti-bot measures and dynamic content loading. While traditional scraping approaches require extensive manual coding and maintenance, artificial intelligence offers a transformative solution. Claude, Anthropic's advanced language model, brings unique capabilities to the web scraping landscape that can dramatically improve both efficiency and effectiveness.
Dominykas Niaura
Last updated: Jan 06, 2026
10 min read


Frequently asked questions
What is the Decodo Knowledge Hub?
The Decodo Knowledge Hub is the go-to resource for individual developers, teams and those who want to learn more in-depth about proxies and web scraping. It serves as a repository of information, guides, various code tutorials, integration & configuration examples and best practices.
What types of content and resources are available in the Knowledge Hub?
The Knowledge Hub features informative articles, tutorials, and integration guides on how to set up proxies in code and applications. It also offers comprehensive information about Decodo products, such as different types of proxies, scraping APIs, and powerful proxy tools.
How frequently is the content in the Knowledge Hub updated, and how can I stay informed about new additions or changes?
The Knowledge Hub is updated together with new product or feature releases, so you can be sure to always find information about anything new. Various code tutorials, integration guides, and many other valuable resources are added every couple of weeks. You'll soon be able to subscribe to our newsletter to stay informed about the latest content and trends in the proxy world!
What if I cannot find an answer here?
If you don't see an answer to your question, check out our documentation, Discord, or contact our 24/7 live chat support that will be more than happy to help you with your issue.
The Fastest Residential Proxies
Dive into a 115M+ ethically-sourced residential IP pool from 195+ locations worldwide. Now from $4/GB*!
14-day money-back option