Proxies for Real-Time Price Monitoring
Track competitor prices, monitor MAP compliance, and improve dynamic pricing strategies with 125M+ proxies that handle CAPTCHAs, geo-restrictions, and IP blocks automatically.
14-day money-back option

125M+
ethically-sourced IPs
99.99%
uptime
#1
response time
195+
locations worldwide
24/7
tech support
Tackle price scraping challenges with zero hassle
Bypass blocks, overcome layout changes, and reduce costs at scale with our proxy solutions for price monitoring.
Geo-specific price insights
Track location-based prices using IPs from 195+ locations with continent, country, state, city, ZIP code, or ASN targeting.
Zero interruptions
Leverage browser fingerprinting and JavaScript rendering to avoid triggering CAPTCHAs and IP blocks across popular eCommerce websites.
Simplified data extraction
Automate collection of structured pricing data inside our intuitive dashboard without building or maintaining scrapers.
Lower operating costs
Take advantage of pay-per-success requests at the lowest price on the market. Plus, test it risk-free with a 7-day trial or 14-day money-back option.
AI-ready solution
Integrate with our MCP server, n8n node, or Langchain to streamline how you collect and process pricing data.
Layout-proof monitoring
Use our Web Scraping API to handle dynamic websites and layout changes without breaking your data collection.
Explore our proxy solutions for price tracking
Choose among residential, datacenter, mobile, and ISP proxies for your price monitoring needs.
Residential proxies
Datacenter proxies
Mobile proxies
ISP proxies
Use cases
Accessing pricing data reliably from websites with advanced anti-bot measures.
Cost-effective solution for tracking prices across multiple, lighter security online retailers simultaneously.
Scrape pricing data on mobile-first platforms or monitoring that demands top-tier anonymity.
Monitor pricing on protected sites with residential trust and datacenter speed.
Features
115M+ IP pool, Advanced targeting, <0.5s response time, 99.92% success rate, HTTP(S) & SOCKS5 support, Pay As You Go option.
500K+ shared and dedicated IPs, 99.94% success rate, <0.3s response time, HTTP(S) & SOCKS5 support, most budget-friendly option.
3G/4G/5G proxies, 10M+ IPs, 99.75% success rate, 700+ reliable carriers, HTTP(S) & SOCKS5 support, Pay As You Go option.
Shared and dedicated IPs from premium ISP and ASN providers, <0.2s average response time, HTTP(S) & SOCKS5 support, worldwide locations.
Pay for
GBs
GBs, shared or dedicated IPs
GBs
GBs, shared or dedicated IPs
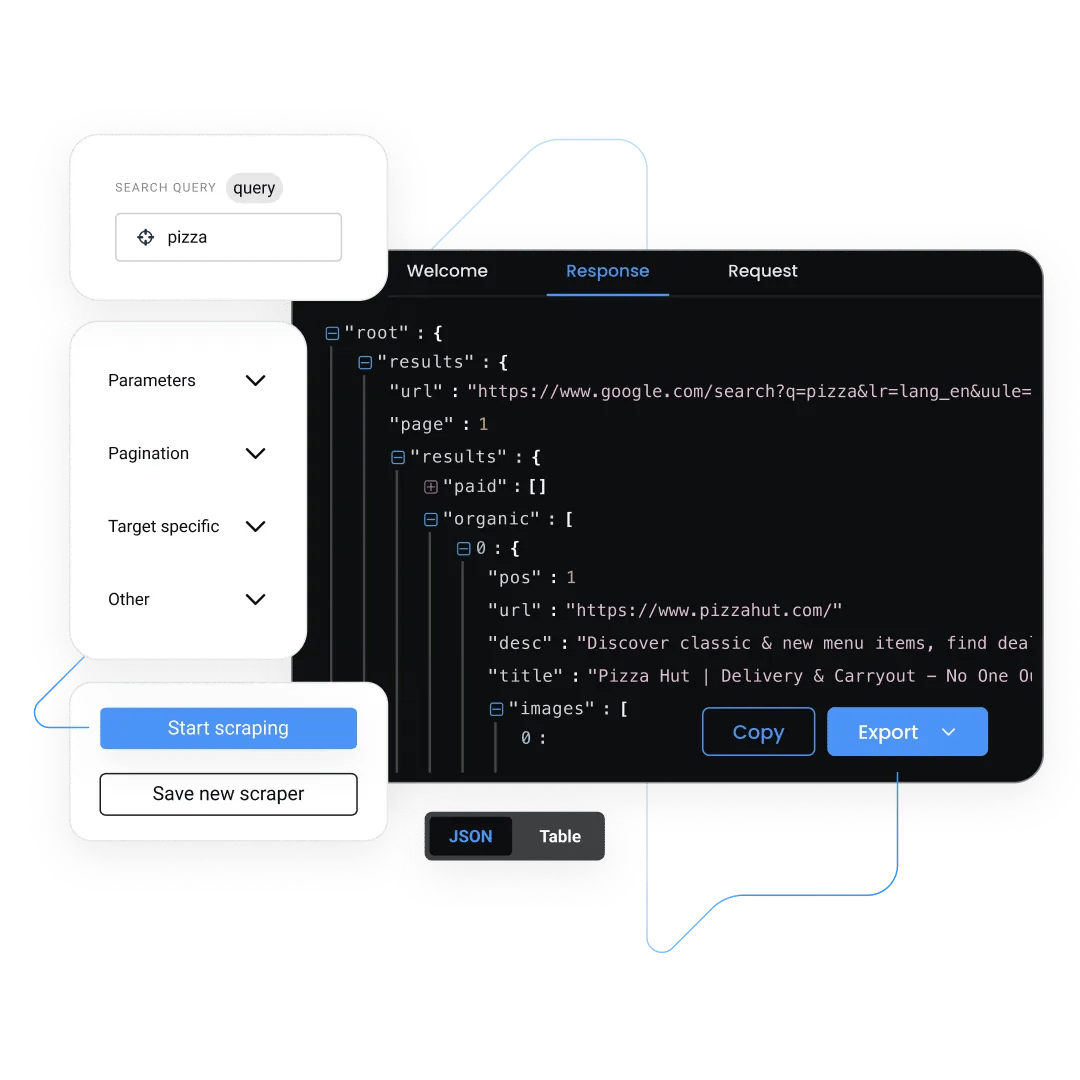
Simplify how you monitor pricing on popular eCommerce platforms
Integrate our Web Scraping API into your workflows in minutes and extract accurate, structured price data instantly:
- Automatic proxy management to bypass CAPTCHAs and IP blocks
- Retailer targeting down to ZIP-level
- Supports all major eCommerce platforms
- HTML, JSON, XHR, and Markdown outputs
- AI-ready integrations, including MCP server, n8n node, and Langchain
- Task automation hourly, daily, weekly, monthly, or at custom intervals
- 100+ ready-made templates and quick start guides
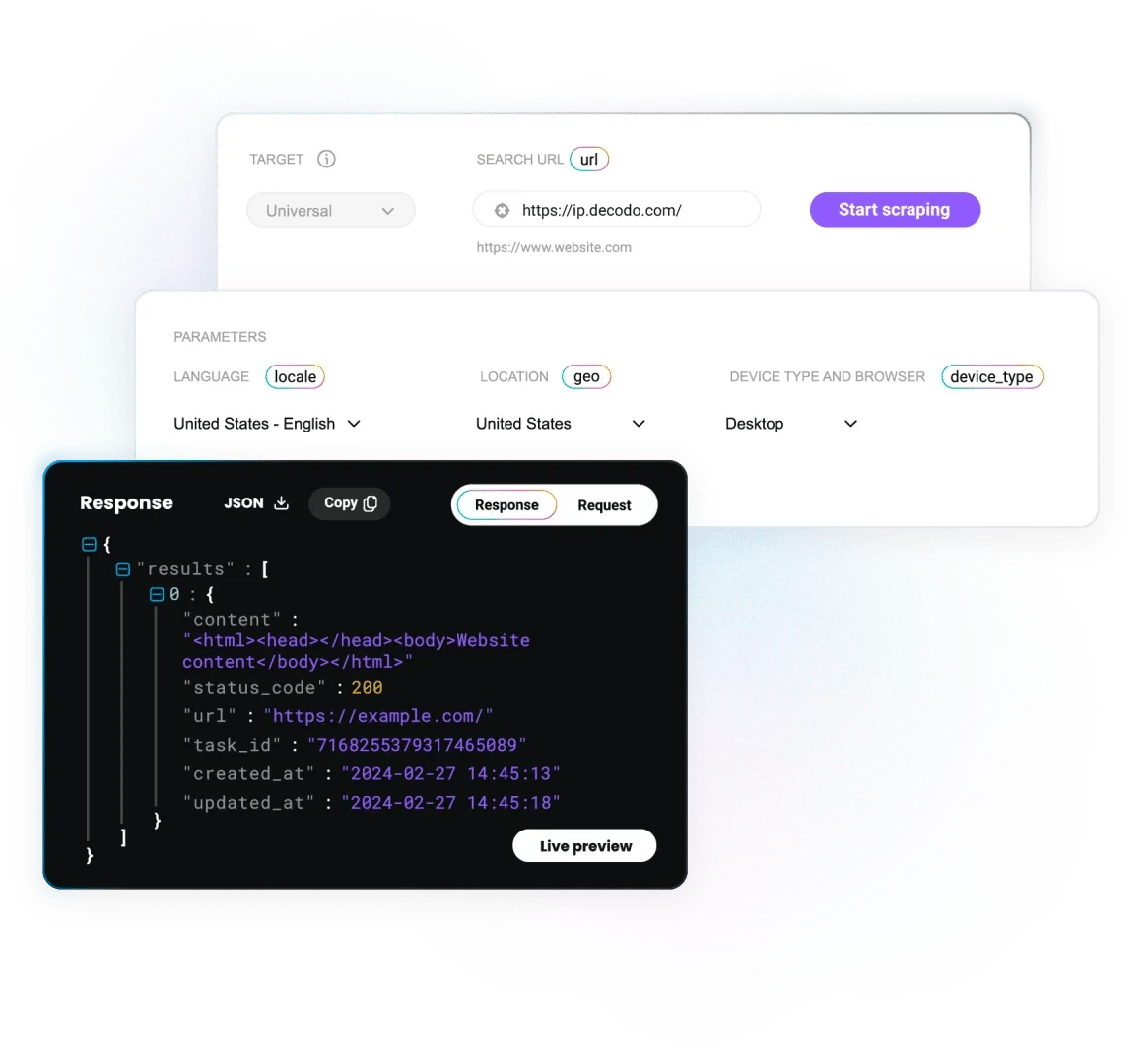
Why choose Decodo for your price monitoring projects?
Power your price tracking projects with reliable proxies, global reach, and top performance at the best price on the market:
- 125M+ IP pool across 195+ locations
- 99.99% uptime
- Flexible, pay-per-success pricing, 7-day free trial, and 14-day money-back option
- 24/7 tech support, simplified onboarding, setup, and a user-friendly dashboard
- Compliance, ethical IP sourcing, and industry recognition
See what people think about our web scraping solutions
135K+ users, and counting, rely on Decodo for their web data projects.
Attentive service
The professional expertise of the Decodo solution has significantly boosted our business growth while enhancing overall efficiency and effectiveness.
N
Novabeyond
Easy to get things done
Decodo provides great service with a simple setup and friendly support team.
R
RoiDynamic
A key to our work
Decodo enables us to develop and test applications in varied environments while supporting precise data collection for research and audience profiling.
C
Cybereg
Featured in:
Frequently Asked Questions
What is automated price monitoring?
Automated price monitoring means tracking product pricing across retailers using proxies and scrapers. The collected data lets you analyze trends, optimize pricing strategies, and stay competitive.
Can I monitor prices on Amazon, eBay, or other eCommerce platforms?
Yes. Our proxies can collect data from Amazon, Walmart, eBay, Shein, Etsy, and many other eCommerce platforms. You can also use our Web Scraping API to handle CAPTCHAs, IP blocks, and render JavaScript automatically, so you can collect pricing data from any platform without interruptions.
How do I choose the best proxy type for price monitoring?
Each proxy type offered by Decodo has its strengths for monitoring pricing:
- Residential proxies are best for accessing pricing data reliably from websites with advanced anti-bot measures.
- Mobile proxies are used to get pricing data on mobile-first platforms, or for monitoring that demands a high level of anonymity.
- Static residential (ISP) proxies allow you to monitor pricing on fairly protected sites with a balance of residential trust and datacenter speed.
- Datacenter proxies are the most cost-effective option for price tracking, especially when collecting data from multiple, lighter-security online retailers.
Our Web Scraping API automatically picks the best type for each scraping task from a pool of 125M+ IPs across 195+ locations.
How do I avoid CAPTCHAs while tracking prices?
You can avoid triggering CAPTCHAs by using our Web Scraping API, which automatically rotates IPs, uses integrated browser fingerprints, and JavaScript rendering to mimic natural human traffic on websites.
Why do I need proxies for price monitoring?
Many websites block requests from the same IP that are repeated in a very short time. By rotating proxies and using other tactics like browser fingerprinting, you can make it look like different users are visiting the website. This lets you access thousands of pricing data points in seconds.
Do I need coding skills?
No, simple setups using our Web Scraping API don’t require coding. Our dashboard and ready-made templates let you collect data without code. Advanced setups need basic programming skills, but our documentation walks you through integration step-by-step.
Grow Your Price Intelligence Operations Without Hassle
Extract accurate pricing data from retailers worldwide, whether you're monitoring hundreds of products or millions
14-day money-back option