How to Scrape Google Maps: A Step-By-Step Tutorial 2025
Ever wondered how to extract valuable business data directly from Google Maps? Whether you're building a lead list, analyzing local markets, or researching competitors, scraping Google Maps can be a goldmine of insights. In this guide, you’ll learn how to automate the process step by step using Python – or skip the coding altogether with Decodo’s plug-and-play scraper.
Dominykas Niaura
Aug 18, 2025
10 min read
The benefit of scraping Google Maps
Let’s start with the "why." Google Maps is already rich and only gets richer every day with invaluable data that’s continually updated. There are restaurants, cafes, bars, supermarkets, hotels, pharmacies, auto repair shops, gyms, historical landmarks, theaters, parks… you name it. Google Maps covers virtually every category of interest.
The data extracted from Google Maps can be a pivotal resource for businesses and analysts alike. It’s used for many applications, such as market research, price aggregation, brand monitoring, competitor analysis, and more. Furthermore, this wealth of information can support customer engagement strategies, location planning, and service optimization, which is helpful for competitive positioning in various industries.
How to scrape Google Maps with Python and proxies
One way to retrieve data from Google Maps is via the official Google Maps API, but that approach comes with limitations like usage quotas, data restrictions, and fees for high-volume access. For developers who want more flexibility, scraping the Google Maps frontend is still a powerful workaround, especially when combined with proxies to stay under the radar.
In this guide, we’ll use Playwright – a fast, modern alternative to Selenium. It pairs well with proxies and handles dynamic websites like Google Maps more reliably. We’ll also use regular expressions to extract structured data and export our results to a CSV file.
Our example target will be Google Maps results for London establishments serving the famous West Asian dish – falafel.
Setting up your environment and imports
Make sure you have a coding setup that allows you to write and run scripts. This could be through a platform like Jupyter Notebook, an Integrated Development Environment (IDE) such as Visual Studio Code, or a basic text editor paired with a command-line tool.
You’ll need to have installed Python 3.7+ on your system and use the following command on Command Prompt (Windows) or Terminal (macOS, Linux) to install the necessary libraries for the script we’ll be using to scrape Google Maps:
Now create a new Python script file and import these libraries:
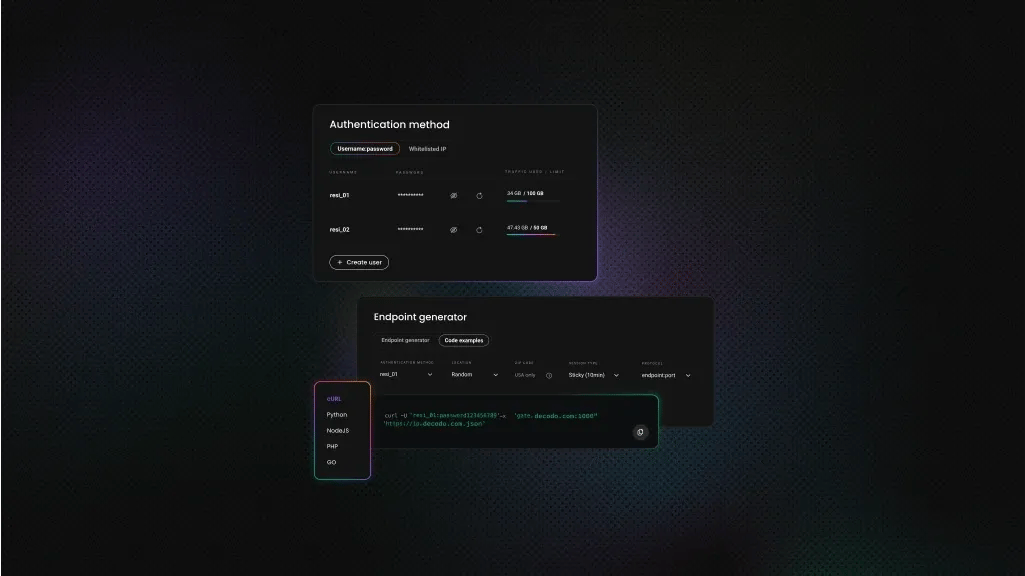
Getting residential proxies
Using proxies in a scraping project is essential for smooth and continuous data collection. Proxies mask your scraping activity by routing requests through various IP addresses, helping to maintain anonymity and avoid IP detection and bans from target websites like Google Maps.
Furthermore, proxies enable users to scale their efforts without hitting rate limits and access content across different regions. For this tutorial, we recommend using our residential proxies, but you can try datacenter, mobile, or ISP proxies, depending on your case.
- Create a Decodo account on our dashboard.
- Find residential proxies by choosing Residential on the left panel.
- Choose a subscription, Pay As You Go plan, or opt for a 3-day free trial.
- In the Proxy setup tab, configure the location, session type, and protocol according to your needs.
- Copy your proxy address, port, username, and password for later use. Alternatively, you can click the download icon in the lower right corner of the table to download the proxy endpoints (10 by default).
Integrating proxies
Let’s integrate residential proxies into this Playwright script. You can adjust the server address in the Decodo dashboard based on your desired location or session type, and make sure to replace the placeholder credentials with your own proxy username and password in the code. For this tutorial, we’ve chosen Europe as the general region and a sticky session of up to 10 minutes:
Extracting place information
This function pulls key details from each Google Maps result (like name, rating, review count, and address). It combines HTML attribute access with regular expressions to clean and standardize the data.
Google recently updated their web structure so that much of a listing’s information is bundled into the same text block, rather than being split into separate elements. That means we can’t just target ratings or addresses directly – we need logic to break these chunks apart and filter out the noise (like service options, phone numbers, or marketing blurbs).
The multiple patterns and keyword lists in this function make that possible. You can easily adapt the function to your needs by adding more keywords or patterns to the lists inside – great for targeting specific business types or cleaning up region-specific formats.
Navigating and scraping Google Maps
This method handles the full scraping workflow. From launching the browser and navigating to Google Maps, to scrolling through results and extracting listing data. It uses Playwright to automate interactions, such as accepting cookie prompts, simulating scrolls to load more businesses, and identifying the HTML elements that contain the data we need.
It’s also flexible: you can modify the search query, number of scrolls, or Google domain (like .com, .co.uk, .de, etc.) to adapt it for different regions and languages. Combined with the extract_place_info method, it loops through each result, extracts structured data, and appends it to a list for saving.
Saving results to a CSV file
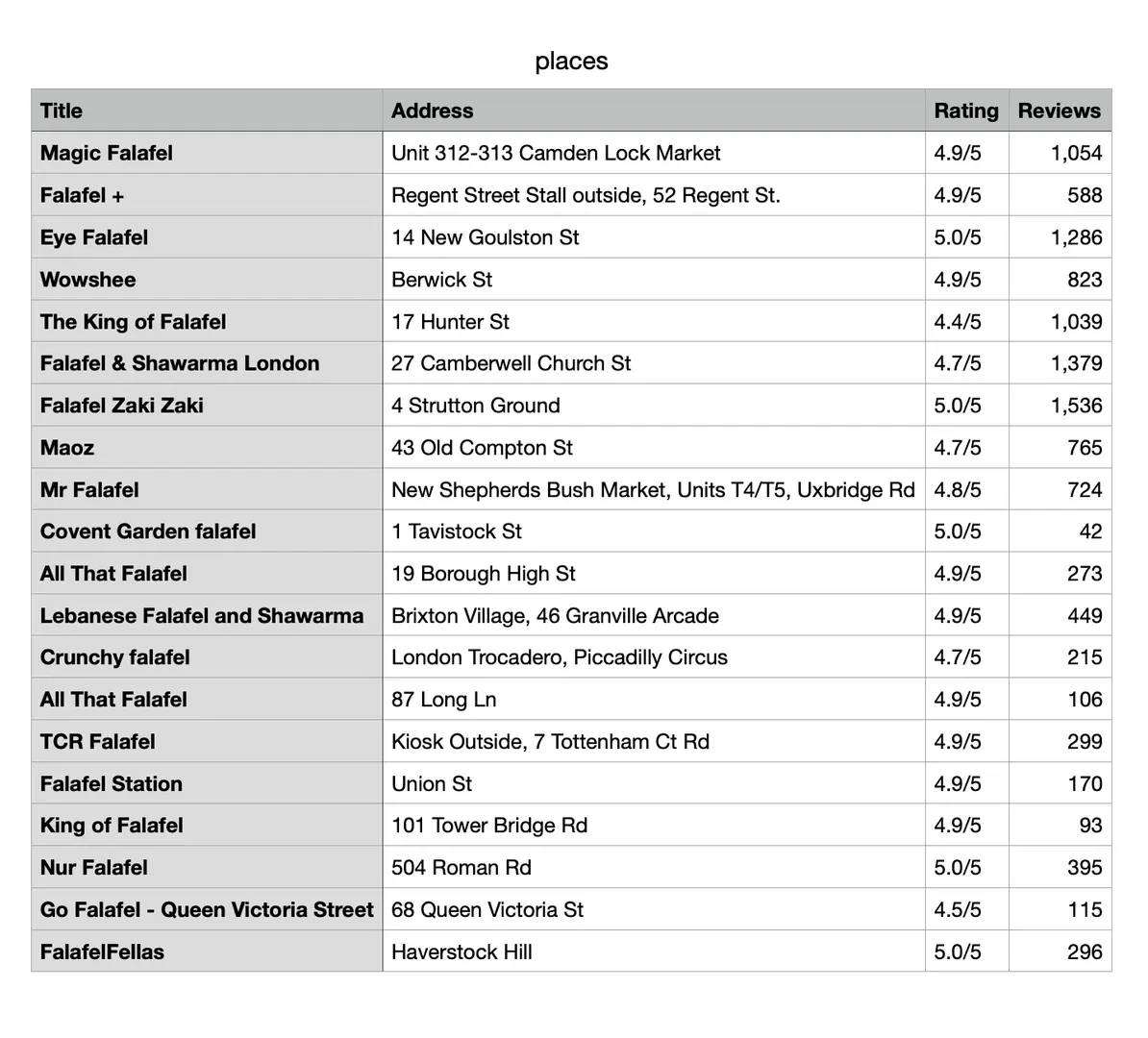
Once the data has been scraped and structured, we need a way to store it for later use. The save_to_csv method handles this by writing all collected places into a CSV file with four columns: Title, Address, Rating, and Reviews.
By default, the file is saved as places.csv in your working directory, but you can change the filename or path to fit your project. Each place is written as a new row, making the data easy to open in Excel, Google Sheets, or any data analysis tool.
Running the scraper
Finally, the main function ties everything together. It initializes the scraper, runs a search (in this case, falafel in London), and prints out the results in the terminal with titles, addresses, ratings, and review counts.
You can easily swap the query or domain to target different business types and countries. For example, gyms in London (.co.uk) or supermarkets in Rome (.it). If results are found, the function also saves them to a CSV file for later use, completing the full scraping workflow from query to clean dataset.
The full Google Maps scraping code
Here’s our full script for scraping Google Maps to find falafel places in London:
After running this script, the terminal will display the number of places found along with each place's title, address, rating, and review count. It will also confirm that the data has been saved to a CSV file.
You’ve now scraped Google Maps for falafel in London, but you can quickly appropriate this script for any other target of interest in any other location.
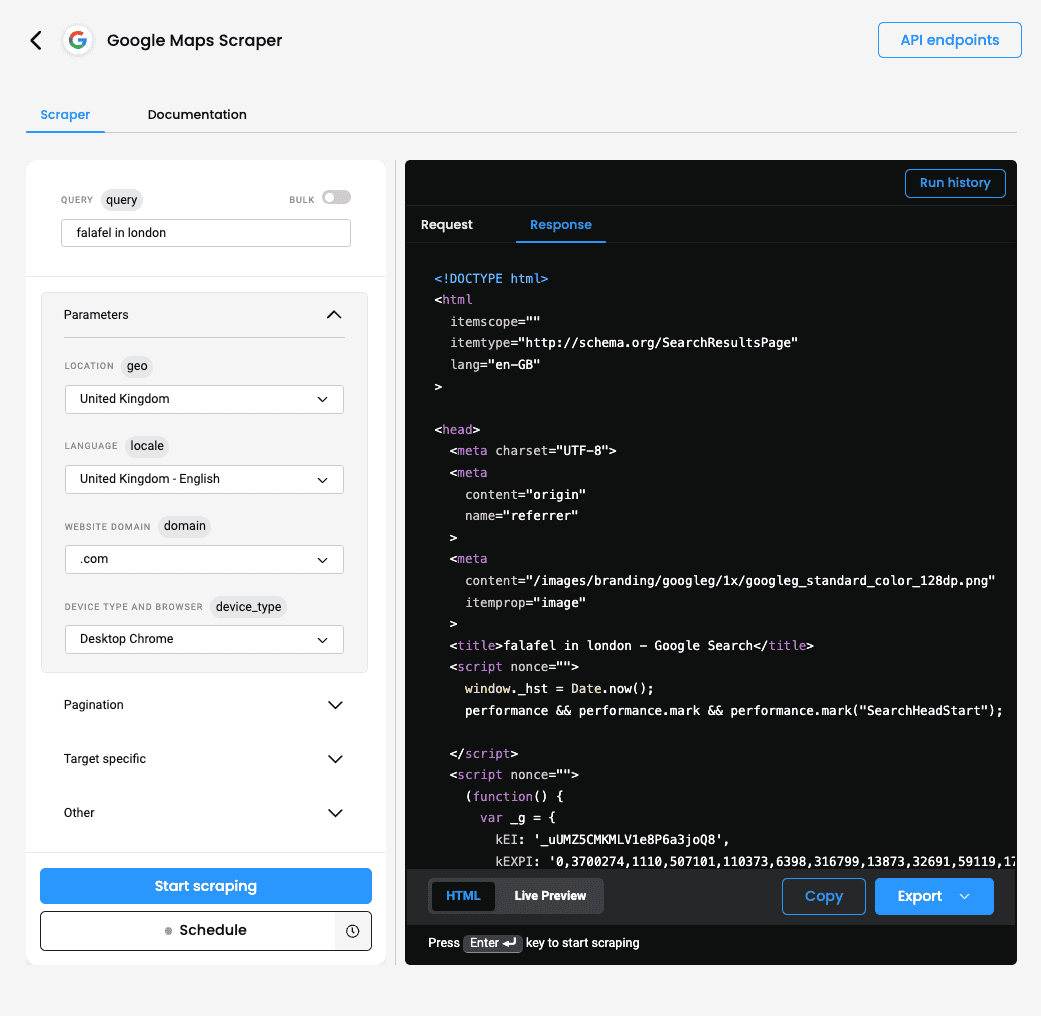
How to use our ready-made Google Maps scraper
Another option for scraping Google Maps is to use our Web Scraping API with the Advanced plan or free trial, both of which include ready-made scrapers designed specifically for this target. This approach removes the need to build custom code; however, the results are returned in HTML, so you'll probably want to parse them for better readability. Here's how to get started:
- Log in or create an account on our dashboard.
- On the left panel, click Scraping APIs and Pricing.
- Choose the Advanced plan or claim a 7-day free trial to test our service.
- In the Scraper tab, set the target to be Google Maps.
- Enter your query and configure parameters such as location, language, website domain, device type, browser type, pagination, JavaScript rendering, and more.
- Click Send Request or click the three dots to schedule your task.
- Copy or export the result in HTML format.
Using this ready-made scraper for Google Maps simplifies the data-gathering process, making it a convenient choice for those who prefer a no-code solution.
To sum up
Congratulations on learning how to scrape Google Maps using Python and residential proxies! The key takeaway is to tailor your script to the specific needs of your target, and stay alert for any changes Google may make that could affect your scraping logic. With reliable proxies on your side, you'll be well-equipped to gather business data (or even that elusive falafel spot). Prefer to skip the coding? Decodo’s ready-made scraper is here to help.
About the author

Dominykas Niaura
Technical Copywriter
Dominykas brings a unique blend of philosophical insight and technical expertise to his writing. Starting his career as a film critic and music industry copywriter, he's now an expert in making complex proxy and web scraping concepts accessible to everyone.
Connect with Dominykas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.