How to Train an LLM on Your Own Data: 2026 Step-by-Step Guide
Large language models (LLMs) are universal tools that improve text understanding and generation across different tasks. However, they often lack specific industry knowledge. Training a model on your own data is important for adjusting, accurate, and efficient responses. This article will guide you through the training process, best practices, and challenges to help you get started with confidence.
Mykolas Juodis
Last updated: Jan 05, 2026
8 min read
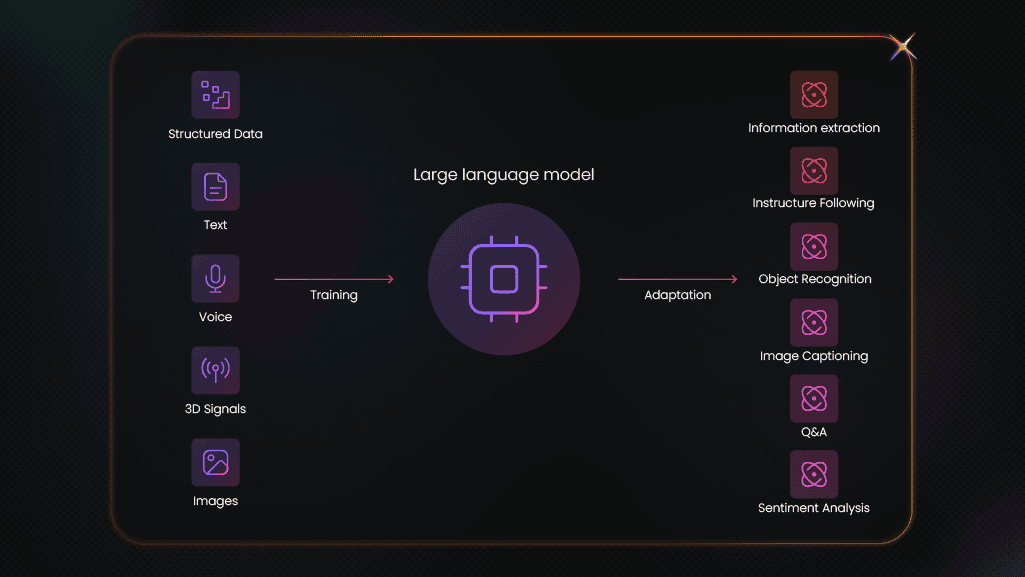
What does it mean to train an LLM on your own data?
First, it's important to understand that customizing an LLM on your own dataset comes down to two core decisions: how you adapt the model weights and which model you start from. Below, we break down these distinctions so you can choose the approach that best fits your goals and resources.
LLM training vs. fine‑tuning
- Training from scratch involves initializing model weights and optimizing on large datasets, a resource‑intensive process.
- Fine-tuning begins with a pre-trained base model and adapts it using your specific data, resulting in a faster and more cost-effective approach.
Off‑the‑shelf vs. custom‑trained
- Off‑the‑shelf models deliver broad capabilities but may underperform on niche tasks.
- Custom-trained models leverage your data to excel in specialized domains such as legal, medical, or internal knowledge bases.
Why train an LLM on your own data?
Using a generic, off‑the‑shelf LLM can get you up and running quickly, but it won't automatically understand the nuances, terminology, or workflows unique to your organization. By training (or fine‑tuning) the model on your own data, you unlock targeted improvements that directly impact performance, control, and ROI. Consider these key advantages:
- Improved accuracy for domain‑specific tasks. Custom data reduces hallucinations and boosts relevance in specialized queries.
- Enhanced data privacy and control. Keeping data in‑house mitigates third‑party risks and compliance concerns.
- Better performance and efficiency. Fine‑tuned models converge faster, requiring less computing than training from scratch.
- Customization for unique business needs. Tailor outputs, tone, and behavior to match brand voice or regulatory requirements.
However, you should also consider potential challenges, like data sparsity, licensing restrictions, or computational limitations that may appear and require mitigation.
Prerequisites for training an LLM
Before you start the training process, you must ensure your project is built on a solid foundation – the right data, infrastructure, and expertise. These prerequisites fall into three essential categories:
- Data requirements. High‑quality, representative data in formats like JSON, CSV, or plain text; ensure usage rights and anonymization where needed.
- Technical infrastructure. Access to GPU/TPU clusters or managed services, sufficient storage, and frameworks like Hugging Face Transformers or TensorFlow.
- Team expertise and planning. Machine learning engineers, data scientists, DevOps for orchestration and a clear project plan and evaluation strategy.
Step‑by‑step guide: how to train an LLM on your own data

Training or fine‑tuning a large language model might seem complex, but it’s a lot more manageable when broken into steps. Whether you're building a customer-facing chatbot or an internal knowledge assistant, this workflow will guide you from early planning to real-world deployment.
#1 – Define your objectives
First, decide what you want your model to do. Whether it’s acting as a chatbot, summarizing documents, serving as an internal knowledge assistant, or something else entirely. Clearly defining the use case will guide every step that follows, from data collection to training and deployment.
Once your AI's goal is set, you’ll need to choose the right evaluation metrics to measure performance. Common metrics include accuracy (how often the model gets it right), latency (how fast it responds), and clarity (how easy its outputs are to understand). Depending on your use case, you might also consider relevance, completeness, or user satisfaction scores to ensure the model meets real-world expectations.
#2 – Collect and prepare your data
The next step is gathering the right data. This can be done manually, with the help of web scraping tools like Decodo's Web Scraping API, or by purchasing pre-made datasets. Training data might come from internal sources, such as support tickets or product documentation, or from publicly available websites like Wikipedia, Google, or other relevant targets.
Then, it’s time to clean up the data by fixing formatting issues and removing duplicates. This step ensures consistency across your dataset, standardizing things like dates, capitalization, or naming conventions, and eliminates repeated entries that could skew your model’s results. Clean, deduplicated data lays the groundwork for accurate training and better overall performance.
#3 – Choose your model architecture
Pick a base model that aligns with your project goals, available resources, and technical expertise. The model you choose should be powerful enough to handle your use case, but also practical in terms of compute requirements, memory usage, and scalability.
For example, if you’re planning to run the model locally and only have access to modest computing power, LLaMA 2–7B could be a solid choice as it offers a good balance between performance and resource demands. On the other hand, if you're building a high-traffic application or need fast performance, you might consider larger models like GPT-4.1, hosted in the cloud, though it comes with higher costs for a single API call and specific infrastructure requirements.
#4 – Set up your environment
Before training, prep your playground. Provision a GPU-powered environment — whether that’s your local workstation, a remote server, or a managed cloud instance like AWS, GCP, or Lambda Labs.
Install core dependencies: Python, your deep learning framework of choice (PyTorch or TensorFlow), Hugging Face’s Transformers, and experiment tracking tools like Weights & Biases or MLflow.
Keep it modular, version-controlled, and reproducible. You'll thank yourself later.
#5 – Tokenize and format your data
Models don’t read — they parse tokens. Use a tokenizer aligned with your architecture (e.g., GPT-2 tokenizer for GPT-style models) to split input text into model-digestible units.
Leverage libraries like tokenizers or datasets from Hugging Face to streamline preprocessing. If your inputs are messy, your outputs will be too.
#6 – Train or fine-tune the model
Configure the learning rate, batch size, epochs, gradient clipping, eval steps — every hyperparameter affects performance and cost. Always start small — train on a limited sample to catch issues before you scale.
Once stable, run your full fine-tuning cycles. Use GPUs efficiently, checkpoint often, and track metrics in real-time with tools like W&B.
#7 – Evaluate and validate
Training’s done? Now pressure-test your model. Choose metrics aligned with your task – F1 for classification, ROUGE for summarization, BLEU for translation, or perplexity for language modeling.
Complement numbers with human evaluation: run real prompts, check edge cases, and test on unseen data. You’re not just proving it works — you’re checking if it fails gracefully.
#8 – Deploy and monitor
Ship your model using FastAPI, Flask, or Hugging Face’s inference toolkit. Wrap it in Docker for easy deployment across environments.
Set up observability by monitor latency, response quality, usage patterns, and drift.
Include a feedback loop, your model should improve in production, not just perform.
Why do web scraping solutions and proxies matter for LLM training?
When you’re fine-tuning a language model, reliable data is what keeps the AI up-to-date. Scraping the web lets you build high-quality, domain-specific datasets from real-world sources like blogs, product reviews, and forums, the exact language your model will need to understand and generate. But there's a catch – anti-bot mechanisms often block automated web scraping solutions from gathering the data.
That’s where proxies flex their muscle. Rotating IPs, like Decodo's residential proxies, bypass rate limits and geo-restrictions, so you keep collecting clean data at scale. With the best response time in the market and 115M+ IPs in 195+ locations, you can collect real-time data from any website online.
Alternatively, you can explore automated data collection solutions, like Web Scraping API, which helps you to gather information from SERP, various websites, eCommerce, or social media platforms with a single click. Users can also leverage pre-made scraping templates and collect real-time data even faster.
Collect data with Web Scraping API
Activate your 7-day free trial with 1K requests and train your LLMs with up-to-date data.
Best practices and tips
Even the cleanest training pipeline can break if you skip the fundamentals. Think of this as your AI operations checklist — the reliable structure behind every scalable, production-ready LLM. Nail these, and your model won’t just perform – it’ll hold up under pressure as your needs evolve.
- Data privacy and security. Encrypt data at rest, rotate credentials, and keep access logs tight. If it moves or stores data, it should be locked down.
- Bias and data quality. Curate balanced datasets, and run regular bias checks to catch unwanted patterns early.
- Iterative improvement. Remember that no AI model is final. Loop in user feedback, schedule retraining, and treat improvement as a built-in process, not a patch.
- Documentation and collaboration. The most important thing – README files aren’t optional. Outline your schema, training logic, and eval methods clearly enough for your future self (or teammate) to pick up and go.
- Compliance and ethics. If your data touches real people, check the legal boxes: GDPR, HIPAA, or whatever applies. Assume someone will ask — and make sure you’re ready.
Common pitfalls and how to avoid them
Even experienced teams hit roadblocks. These aren’t bugs — they’re recurring characters in the LLM development story. Spot them early, and you’ll save time and budget.
- Low-quality or insufficient data. Use synthetic samples, active learning, or targeted augmentation to bulk up quality where it counts.
- Overfitting or underfitting. Use regularization, early stopping, and smarter hyperparameters to stay in the zone.
- Performance won’t stay static. Monitor input changes and output quality continuously, and set clear retraining triggers when things slip.
- Compute adds up fast. Use cost dashboards, run non-critical jobs on spot instances, and tune batch sizes and precision settings to stretch your GPU time.
- What worked yesterday might break tomorrow. Version your data, track your configs, and document everything in a shared, structured format. If it’s not traceable, it’s technical debt.
Wrapping up
Training an LLM on your own data gives you leverage: sharper results, tighter control, and solutions that speak your language. This guide walks you through the full stack — from strategy to deployment. Use it to build AI systems that aren’t just functional, but fit-for-purpose and future-proof.
Explore solutions like rotating proxies or web scraping solutions to streamline your data collection process and follow the industry to update your LLMs with the most recent technologies for the best performance.
Train your LLMs with real-time data
Use our Web Scraping API with a 7-day free trial and 1K requests to get data from any website.
About the author

Mykolas Juodis
Head of Marketing
Mykolas is a seasoned digital marketing professional with over a decade of experience, currently leading Marketing department in the web data gathering industry. His extensive background in digital marketing, combined with his deep understanding of proxies and web scraping technologies, allows him to bridge the gap between technical solutions and practical business applications.
Connect with Mykolas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.

