AI Training Data: Definition, Sources & Best Practices
After years of progress, AI has gotten a lot better at acting like human thinking. Whether that’s in machine learning, robotics, natural language processing (NLP), or training AI agents. But one thing still holds true – AI is only as good as the data it learns from. In this post, we’ll look at why high-quality training data matters so much when building strong AI systems.
Mykolas Juodis
Last updated: May 30, 2025
6 min read

What is AI training data?
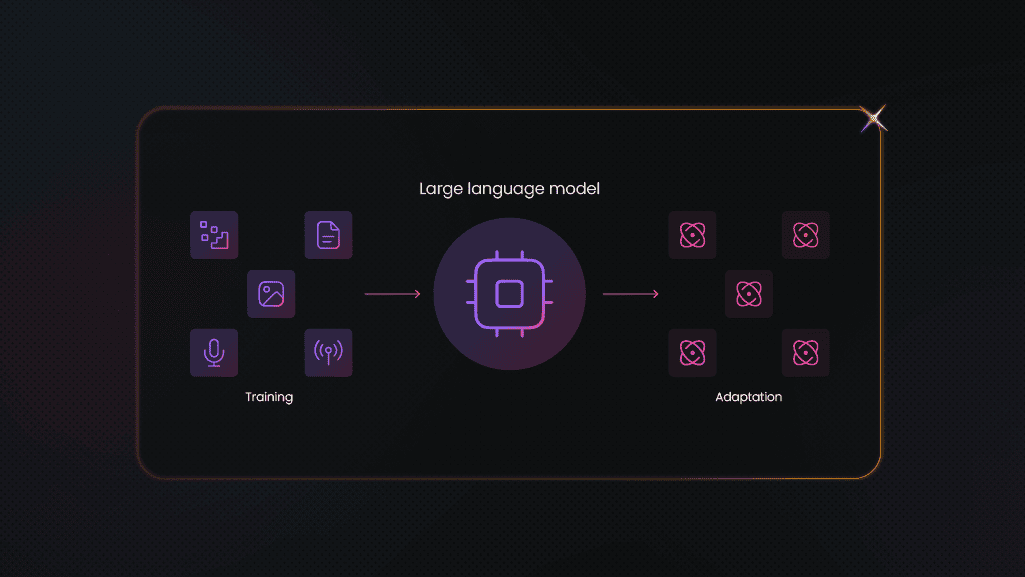
One of the main types of AI is machine learning, which focuses on the creation and use of models to make predictions. Models are essentially a product of an "a + b" formula, where "a" is the algorithm and "b" is the data. AI training data is the input used to train a model. Training data AI influences the type of machine learning technique used and the reliability of the model in solving problems.
Training a model to improve its efficiency and accuracy requires substantial amounts of high-quality data. With each interaction, the model becomes better at filtering through inconsistencies, surprises, and outliers to make more informed decisions. The result is a set of mathematical models that can produce reliable results within certain contexts.
The type of training data for AI depends on the model’s purpose. For example, if a model is trained to create cat images, the data for AI training will include pictures of cats and labels that include the name “cat” and various cat-related terms. This data helps the model identify cats and eventually create new images of cats based on the parts of a cat from as many images and labels as possible.
So, where does the data come from? Usually, users of the Internet create text, image, audio, video, and sensor data. However, some cases call for synthetic data, which is manufactured data that mimics the real world to create similar results.
AI training data is widely classified into two forms – labeled vs. unlabeled.
- Labeled data. This AI training data has useful tags to provide context for supervised learning. Data labeling is a manual process that uses human labor to manually classify raw data by identifying the content of an image, text, video, and so on. The labeled data is then fed into an algorithm to create a model. Ultimately, when the model is introduced to unlabeled data, it can accurately identify the data and produce accurate outcomes.
- Unlabeled data. This AI training data is in its raw form without tags for context. It’s useful for unsupervised learning that often requires anomaly and pattern identification. Unlabeled data is easier to collect because it doesn’t require labor-intensive preparations.
Does that mean that if you don’t label raw data, you can’t use it for unsupervised learning? Technically – yes.
- Supervised learning is the use of labelled AI data training sets to train machine models to classify data correctly or predict outcomes accurately. Human touch is required in each iteration to improve accuracy. Supervised learning techniques are useful for sentiment analysis, flagging spam, weather forecasting, and pricing projections.
- Unsupervised learning is the use of unlabeled data to train machine models to analyze and identify clusters and patterns previously unknown to humans. However, human intervention is still needed to ensure the outcome of the analysis makes sense for its application. Unsupervised learning is handy for detecting anomalies in medical imaging and financial transactions, building recommendations, and analyzing customer personas.
Types and formats of training data
Depending on the AI solution, training data can come in various shapes and forms:
- Text data is information stored in written form, like text messages, articles, academic papers, books, and any form of literature. AI models use text data to analyze themes, language, and patterns and generate human language.
- Audio data is speech data that AI models use to identify pronunciation and speech patterns for speech-to-text applications, including accents and regional vocabulary use. Audio data is also useful for identifying human emotion, animal sounds, car sounds, and music.
- Image data is data limited to visual formats such as images. It is useful for identifying and regenerating images, facial recognition, and quality control.
- Video data is data in a video format with moving images and audio, usually used to train computer vision AI, like surveillance systems.
- Sensor data is information about physical sensations, like temperature and humidity, or physical information like biometrics and object acceleration. Sensor data is useful for Internet of Things (IoT) devices, including the ones you can find even at your home, like temperature control units, humidity sensors, motion sensors, and security protocols.
The data is sorted into structured or unstructured AI training sets based on its format:
- Structured data has discrete forms, like numbers, dates, and short text. It fits neatly into tables such as Excel spreadsheets.
- Unstructured data doesn’t have a fixed format and occurs in more complex forms, like video and audio files. Because of its structure, you can't store unstructured data in a table.
The kind of data you're working with impacts a bunch of things, like:
- Storage. Structured data has a defined format and is stored in relational databases, while non-structured data is stored in its raw format in non-relational databases. Generally, structured data is easier to manipulate. Unstructured data requires more sophisticated manipulation skills and more data cleaning to ensure consistency.
- Use cases. Structured data is useful across machine learning algorithms in CRMs, business intelligence, inventory management, and SEO. Unstructured data is useful for natural language processing (NLP), generative AI, AI agent training, sentiment analysis, and predictive data analytics.
How AI training data is used in model development
AI models learn by processing training data to spot patterns and make predictions. Here’s a quick breakdown of how that works:
- Data collection. It all starts with gathering the right kind of data. This means figuring out where to get it, cleaning it up, and setting up ways to collect it efficiently. Since AI needs loads of examples to learn from, collecting a large and varied dataset is key. It’s also important to think about whether the data was collected ethically and where and how it’ll be stored and processed.
- Annotation and preprocessing. Most AI models need labeled data to learn properly. That’s where annotation comes in – adding tags to images, text, or video so the model knows what it’s looking at. This part often requires real people to do the work, since it involves catching errors and understanding the context. Preprocessing helps clean up any mistakes, irrelevant stuff, or inconsistencies that might mess with the training.
- AI model training. Once the data is ready, the model goes through training. There are two main types – supervised learning uses labeled data to teach the model exactly what to look for. Unsupervised learning works with unlabeled data to find patterns on its own.
- Validating the model. After training, the model is tested to see how well it performs. One common way is cross-validation. Users split the data into sets and running the model through each one to check consistency. Accuracy, precision, and recall are some of the go-to metrics to judge performance.
- Testing and launching. Finally, the model gets tested on real-world or live data. If it doesn’t perform well, it goes back for tweaks. But even after it’s up and running, training doesn’t stop. The model keeps learning and adapting over time, especially when it runs into new or unexpected situations.
Types of data used in AI training
AI models use different data types at various stages:
- Training set. The first batch of data used to teach the model. It’s fed in over and over until the model starts to get it.
- Validation set. A new set of data used to check how well the model performs after initial training.
- Test set. The final challenge – real-world data that checks if the model is accurate and ready to go without surprises.
Why high-quality training data matters
AI models need a ton of data to work well. But it’s not just about quantity — the quality of that data plays a big role in how accurate, fair, and adaptable the model ends up being.
Accuracy
Accuracy is all about how often the model gets things right. It measures how many correct predictions it makes out of the total number of tries. One of the best ways to boost accuracy is to clean up the data – remove errors, fill in missing info, and get rid of outliers. It also helps to use smart data collection and sampling methods from the start.
Generalization
This is the model’s ability to handle brand-new data it hasn’t seen before. Instead of memorizing everything, a good model learns the patterns so it can work with different inputs. The challenge is avoiding overfitting (when a model memorizes too much) and underfitting (when it hasn’t learned enough). Not enough data usually leads to underfitting, while too much of the same type can lead to overtraining without real improvement.
Fairness
Fairness means the model makes decisions without bias. That matters because AI can unintentionally reinforce stereotypes or inequalities if the training data is biased. This can lead to unfair outcomes like certain groups being denied jobs or services. For example, if a hiring algorithm is trained on biased data, it might favor one gender or race over another. To avoid this, the data needs to be diverse, and the development process should be transparent and regularly reviewed.
However, there are a few data issues that mess with AI solutions and can throw off how well they perform. For example:
Bias
Bias happens when data doesn’t reflect reality accurately. It can come from many places – how the data was collected, who labeled it, or even how the algorithm was built. Bias types include confirmation bias, exclusion bias, and automation bias, among others. Fixing bias means using more representative samples, diverse teams, clear processes, and regular audits.
Overfitting and underfitting
If a model is too good at learning from training data, it might not do well with new data – that’s overfitting. If it doesn’t learn enough, that’s underfitting. Both can be fixed by improving data quality, using varied examples, and watching for patterns in how the model performs.
Imbalanced datasets
This happens when one category dominates the data, like having way more photos of cats than dogs. The model then struggles with the underrepresented category. Fixing this includes better sampling, using balanced metrics, and applying cross-validation techniques.
Noisy or inaccurate labels
Sometimes data includes random, irrelevant stuff or has been labeled incorrectly, like a photo of a banana tagged as an apple. Fixing this takes some domain knowledge and data analysis tools like scatter plots or box plots to spot issues. Reducing noise and errors also means cleaning the data often and relying less on manual tagging when possible.
Sources of training data
AI models learn from all sorts of data, usually pulled from both inside and outside a business. Here are some common sources:
- Internal business data. This could be customer surveys, support tickets, or user behavior. For example, Spotify uses your playlists to power AI-generated DJs and music recommendations and some of the eCommerce brands uses your recently viewed and purchased products to create personalized deals or even introduce new items.
- Open datasets. Platforms like ImageNet, Common Crawl, and Kaggle offer free, publicly available data you can use to train AI models.
- Data providers and marketplaces. Some companies sell access to data, especially social media platforms or analytics firms. You pay to access their archives and then feed the data to the AI tools.
- Web scraping. This involves pulling data from various websites. It’s super useful for comparing competitor prices, collecting information on product details for SEO, or analyzing customer opinions on review sites. Platforms like Decodo offer all-in-one Web Scraping APIs that can automatically pull data, even from well-protected or JavaScript-heavy websites.
- Synthetic data. This is fake-but-useful data created by algorithms to mimic real-world info. It’s a cheaper, faster way to bulk up your datasets but it often lacks the complexity, unpredictability, and subtle patterns found in real-world data.
Before you start gathering data, it’s important to make sure everything’s above board. Here’s what to keep in mind:
- Licensing. A lot of content (like images, books, or songs) is protected by licenses. You often need permission to use it in your AI model.
- Copyright. Just having a license for a dataset doesn’t always mean you can use every part of it for AI. Contact the creators of the content you'll be feeding to your AI solution and sign up an agreement.
- Privacy and data protection. Laws like GDPR and CCPA are in place to protect user data. You’ll need to follow these rules closely and consult a legal professional to avoid breaching one of the most important laws.
Challenges in working with AI training data
Building effective AI models isn't just about smart algorithms; it's also about the quality and quantity of the data they learn from. Here are some challenges:
- Gathering enough data. AI models need large amounts of data to learn effectively. However, acquiring large datasets can be expensive and time-consuming. Licensing fees, copyright restrictions, and the costs associated with data scraping all add up. Moreover, for specialized applications, the required data might not even exist yet.
- Accurate and costly annotation. For AI to understand data, it often needs labeled examples. This labeling process, known as annotation, requires human expertise and can be both time-intensive and costly. Inaccurate annotations can lead to poor model performance, making quality control essential.
- Ensuring diverse and representative data. AI models can inadvertently learn biases present in their training data. If the data isn't diverse or representative of real-world scenarios, the AI's decisions might be skewed. Addressing this requires careful data selection and ongoing monitoring to ensure fairness.
- Navigating legal and ethical concerns. With data privacy laws like GDPR and CCPA, it's crucial to handle data responsibly. Ensuring compliance not only avoids legal issues but also builds trust with users. Ethical considerations, such as obtaining consent and protecting personal information, are a must.
- Managing large datasets. Storing and organizing massive datasets is no small feat. Efficient data management systems are needed to handle the volume, ensure data quality, and facilitate easy access for training purposes.
Best practices for preparing and managing training data
To build AI models that are accurate, up-to-date, and can complete even the most challenging tasks, consider:
- Data cleaning and normalization. Remove errors, duplicates, and inconsistencies to ensure the data is accurate and standardized.
- Utilize annotation tools and implement quality checks. Leveraging specialized tools can streamline the labeling process, and regular quality checks help maintain accuracy.
- Promote diversity to reduce bias. Assemble diverse teams and datasets to capture a wide range of perspectives and scenarios.
- Validate data consistency and completeness. Regularly assess datasets to ensure they are comprehensive and consistent across different sources.
- Implement data versioning and monitoring. Track changes in datasets over time and monitor for anomalies to maintain data integrity.
What’s next for AI training data
With the new AI solutions popping up daily, the demand for high-quality training data is growing rapidly. However, there are new innovative approaches emerging to tackle existing challenges:
- Synthetic and augmented data. Synthetic data, generated by algorithms, can mimic real-world data, helping to fill gaps where data is scarce or sensitive. Data augmentation techniques, like flipping or rotating images, can increase dataset diversity without additional data collection.
- Self-supervised learning. This approach allows models to learn from unlabeled data by identifying patterns and structures within the data itself. It reduces the reliance on annotated datasets and can lead to more generalized AI systems.
- Privacy-first data collection. Techniques like federated learning enable AI models to learn from data distributed across multiple devices without transferring the data to a central server. This approach enhances privacy and security, making it especially valuable in sensitive fields like healthcare.
- Regulation and responsible AI practices. There's a growing movement towards collaborative AI development, where countries and organizations contribute data to shared, open-source models. This collective approach aims to democratize AI and ensure that advancements benefit a broader spectrum of society.
Conclusion
AI models are built from the algorithms and data they’re trained on. If the data’s messy, missing info, errors, or bias, you’ll end up with an unreliable model that wastes time and resources. That’s why it’s so important to have a smart approach to collecting, storing, and analyzing training data. Putting the right systems and best practices in place helps make sure your data’s solid, and that leads to way more useful and trustworthy AI.
Collect real-time data for AI
Get accurate data from any website with our all-in-one Web Scraping API – 7-day free trial with 1K requests available.
About the author

Mykolas Juodis
Head of Marketing
Mykolas is a seasoned digital marketing professional with over a decade of experience, currently leading Marketing department in the web data gathering industry. His extensive background in digital marketing, combined with his deep understanding of proxies and web scraping technologies, allows him to bridge the gap between technical solutions and practical business applications.
Connect with Mykolas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.