How to Scrape Google Shopping: Extract Prices, Results & Product Data (2025)
Google Shopping is a product search engine that aggregates listings from thousands of online retailers. Businesses scrape it to track competitor pricing, spot trends, and gather valuable eCommerce insights. Using APIs, no-code tools, or custom scripts, you can extract data like product titles, prices, ratings, and more. In this guide, we’ll build a custom scraping script using Python and Playwright!
Dominykas Niaura
May 30, 2025
10 min read

Why scrape Google Shopping
Google Shopping is one of the richest sources of eCommerce data on the web. From product titles and prices to availability and seller information, it offers a centralized view of what the market looks like at any given moment.
Scraping this data allows businesses to monitor competitor pricing in near real time, helping them stay competitive and adjust their strategies on the fly. It’s also useful for gathering product intelligence: tracking how certain items perform across regions, retailers, and time.
For developers, the data can power comparison tools, price trackers, or product aggregators that help users find the best deals. Meanwhile, marketers can monitor sponsored listings and optimize their affiliate content by keeping tabs on what’s trending, in stock, or heavily promoted.
What you can scrape from Google Shopping
Google Shopping pages are packed with valuable product data, much of which can be extracted with the right tools.
You can scrape product names, prices, and sellers to understand how items are listed and marketed across different retailers. Many listings also include ratings and review counts, giving insight into customer sentiment and popularity.
Beyond individual items, you can target inline shopping results that appear directly on Google’s main search page, as well as related shopping blocks and even organic shopping results in some queries. Advanced setups can also extract filters (like brand, price range, or availability) and local shopping data, showing where a product is available nearby.
Ways to scrape Google Shopping
There are several ways to collect data from Google Shopping, depending on your goals and technical comfort level:
- Manual copy-pasting. Fine for quick, one-off checks but not practical for larger-scale or repeated tasks.
- Google Content API for Shopping. Ideal for merchants managing their own product feeds, but not suitable for scraping competitor or market-wide listings.
- No-code scrapers and scraping APIs. Good for simple use cases with limited customization. They save time but often lack flexibility or ways to extract specific, structured data.
- Custom scraping scripts. Best for full control. This approach lets you render JavaScript, handle dynamic content, rotate proxies, and fine-tune scraping logic to bypass blocks.
In this guide, we’ll show you how to build your own custom scraper using Python and Playwright.
What you need for Google Shopping scraping
For scraping Google Shopping with Python and Playwright, you’ll need to prepare a few things. Here’s how to get started:
- Install Python. Make sure you have Python 3.7+ installed on your computer. If not, download it from the official Python website.
- Get the required libraries. You’ll need Playwright, along with some built-in Python modules. To install Playwright, run the following command in your terminal:
3. Prepare proxies. Purchase a plan of reliable proxies and get your proxy credentials to integrate in your scraping code.
Why proxies are necessary for stable scraping
Google Shopping is heavily protected against automation. It frequently triggers CAPTCHAs, rate limits, and outright blocks when it detects bot-like behavior. Even with headless browsers and human-like interaction, your scraper can quickly get flagged if too many requests come from the same IP.
Proxies help you avoid these issues by rotating IP addresses, making your scraper appear more like real users. Residential proxies, in particular, are harder to detect and better at bypassing geo-restrictions. They also allow you to check product listings, availability, and prices as they appear in different regions, which is essential for accurate market tracking.
At Decodo, we offer residential proxies with a high success rate (99.86%), a rapid response time (<0.6s), and extensive geo-targeting options (195+ worldwide locations). Here's how easy it is to get a plan and your proxy credentials:
- Head over to the Decodo dashboard and create an account.
- On the left panel, click the Residential panel and select Residential.
- Choose a subscription, Pay As You Go plan, or opt for a 3-day free trial.
- In the Proxy setup tab, choose the location, session type, and protocol according to your needs.
- Copy your proxy address, port, username, and password for later use. Alternatively, you can click the download icon in the lower right corner of the table to download the proxy endpoints (10 by default).
How to scrape Google Shopping results step-by-step
Now that your environment is ready, let’s walk through the core parts of a simple scraper that grabs product descriptions from Google Shopping. The script is written in Python and powered by Playwright, with proxy support and basic anti-detection techniques.
1. Imports and setup
First, we’re going to indicate the core libraries. playwright.sync_api handles browser automation. time, random, and typing are used for delays, randomness (to avoid detection), and type hinting.
2. Human-like behavior function
The following function introduces small, random actions, such as moving the mouse and scrolling the page, to make the bot behave more like a real user. It’s not foolproof, but it can help reduce the chances of triggering Google’s anti-bot mechanisms.
3. Scraping function with retry logic
Here comes the main function, which takes a search query, proxy details, and scraping settings. It also includes retry logic – if the page isn’t loading correctly, it'll try again (in this example, up to 10 times).
This part of the code:
- Constructs the Google Shopping URL
- Launches a Chromium browser with Playwright
- Applies proxy settings if provided
- Loads the page
- Simulates human behavior
- Handles cookie/consent popups
- Simulates human behavior again and scrolls the page
- Waits for product blocks to appear
- Extracts their aria-label attributes.
The product blocks and their attributes can be found using the browser’s developer tools a.k.a. the Inspect Element feature.
4. Running the scraper
The last part sets the search query (in our case, "laptop"), provides proxy credentials, and prints the scraped results. You’ll want to replace the proxy placeholders with your actual proxy details.
In this example, we’re using Decodo’s residential proxies with a randomly assigned location and rotating session type, which means a different IP will be assigned for each request.
The complete Google Shopping scraping code
Below is the full Python script we've created throughout this step-by-step guide. You can copy, run, and adapt it to your own Google Shopping scraping projects.
After running the code in your coding environment, the result will look similar to this:
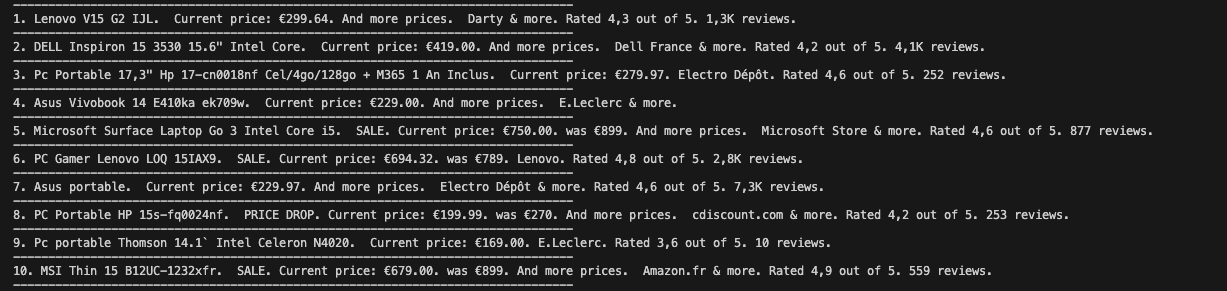
Keep in mind that even with high-quality proxies, scraping Google Shopping can occasionally trigger CAPTCHAs. This is often influenced by factors like the proxy’s location, how frequently it’s been used, the time of day, or the specific search patterns involved. Google’s anti-bot systems are aggressive and constantly evolving, so some blocks are simply unavoidable. That’s why it’s important to build retry logic into your scraper and avoid overly robotic behavior.
Tools and scrapers to extract Google Shopping data
There’s a wide range of tools and services available for scraping Google Shopping data, ranging from no-code APIs to fully custom-built scripts. Choosing the right approach depends on your technical skill level, budget, and how deeply you need to interact with the data.
DIY vs prebuilt scrapers
Prebuilt APIs work well when speed and ease are the priority. But if you need more control – for example, to extract custom fields, handle pagination, or scrape multiple regions – building your own scraper is the way to go. DIY scripts are especially useful for competitive analysis, bulk product tracking, and fine-tuned data extraction at scale.
Available Google Shopping scrapers
Tools like Decodo’s Web Scraping API or Oxylabs’ Web Scraper API offer ready-to-use Google Shopping scrapers. They handle things like proxy rotation, CAPTCHA solving, and JavaScript rendering out of the box, making them a solid choice for price monitoring, affiliate marketing, and quick prototyping. However, their flexibility is limited – you often can’t tweak scraping behavior beyond what’s built into the API.
Support for filters, related blocks, and inline shopping
Some scrapers only capture basic listings, while others can extract deeper elements like inline results, filters, and related product blocks. These are essential for use cases like ad tracking, trend analysis, or comparison tools. If your project relies on this richer data, make sure your scraper supports dynamic content and full-page interaction.
Decodo’s Web Scraping API can retrieve rich product data from Google Shopping, including titles, prices, ratings, delivery info, merchant names, thumbnails, and even result position within a grid. It’s well-suited for capturing inline shopping results and structured product listings – ideal for price monitoring, affiliate tools, and competitive analysis at scale.
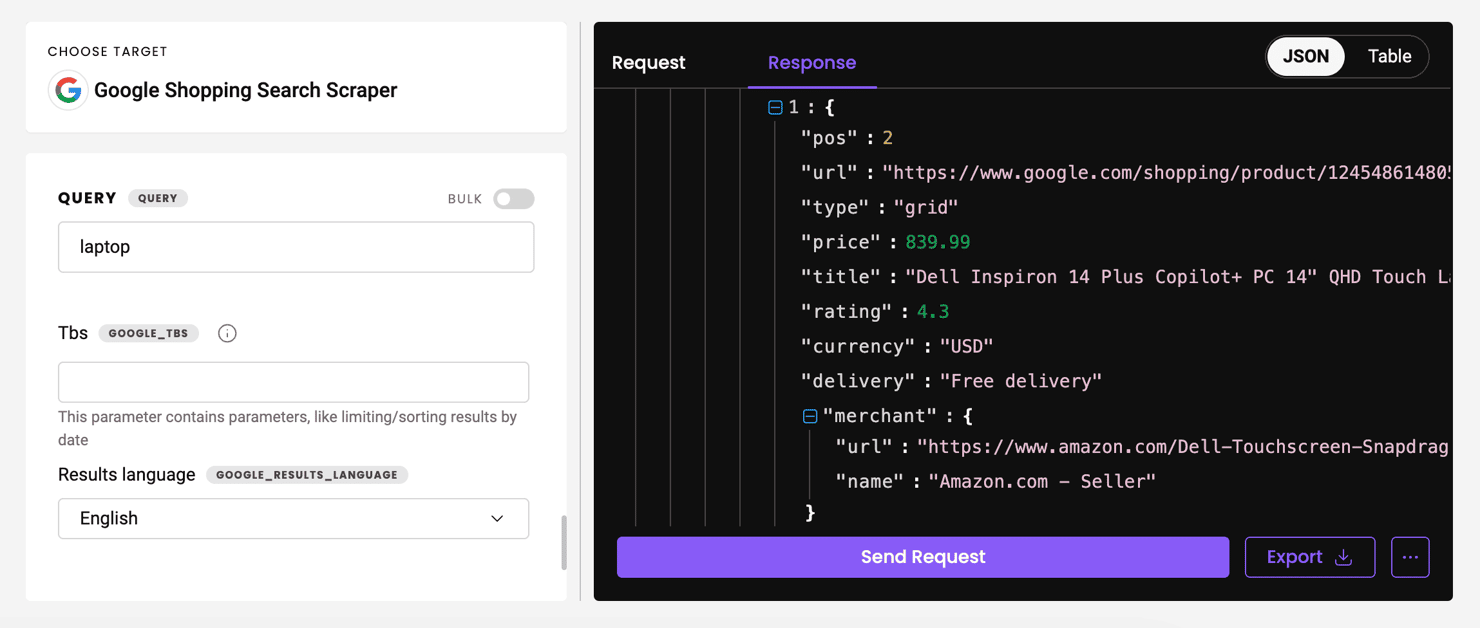
Start your free trial of Web Scraping API
Access structured data from Google Shopping and other platforms with our full-stack tool, complete with ready-made scraping templates.
Best practices and scraping tips
To keep your Google Shopping scraper running smoothly and sustainably, it's important to follow a few best practices that reduce the risk of being blocked or flagged.
Be respectful with request rates
Flooding Google with rapid-fire requests is a quick way to get blocked. Add randomized delays between page visits to mimic human browsing behavior, and avoid sending too many queries in a short time. A slower, more natural pattern is more effective in the long run.
Rotate user agents and proxies
Google actively monitors incoming traffic and can flag repeated requests from the same IP or browser fingerprint. To avoid detection, rotate both your proxy IPs and user agents regularly. Residential proxies are especially useful here, as they effectively simulate real users, unlike datacenter proxies.
Test and adapt regularly
Google frequently changes the structure of its pages, especially the DOM elements used in Shopping results. What works today might break tomorrow, so make sure to test your scraper often and be ready to tweak your selectors and logic as needed.
Avoid scraping while logged into a Google account
Logged-in sessions can behave differently, trigger more aggressive verification checks, or skew the results you're trying to capture. Always run your scraper in a clean, incognito-like environment to ensure consistency and reduce friction.
To sum up
Scraping Google Shopping can be done using prebuilt tools, scraping APIs, or custom code. Whatever method you choose, always respect site terms, avoid overloading servers, and handle data responsibly. If you're just starting out, try experimenting with a scraping API. Or, if you’d prefer to build your own Python scraper like the one covered here, be sure to include proxies for stability.
About the author

Dominykas Niaura
Technical Copywriter
Dominykas brings a unique blend of philosophical insight and technical expertise to his writing. Starting his career as a film critic and music industry copywriter, he's now an expert in making complex proxy and web scraping concepts accessible to everyone.
Connect with Dominykas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.