The Ultimate Guide to Training an AI Model: From Basics to Deployment
You don't need to be Google or work at a university to train your own AI model anymore. Small teams can build smart systems that actually work for what they need - you just need the right tools and know-how. This guide walks you through everything from figuring out what problem you're trying to solve all the way to getting your model up and running and keeping it working.
Mykolas Juodis
Last updated: Jul 14, 2025
6 min read
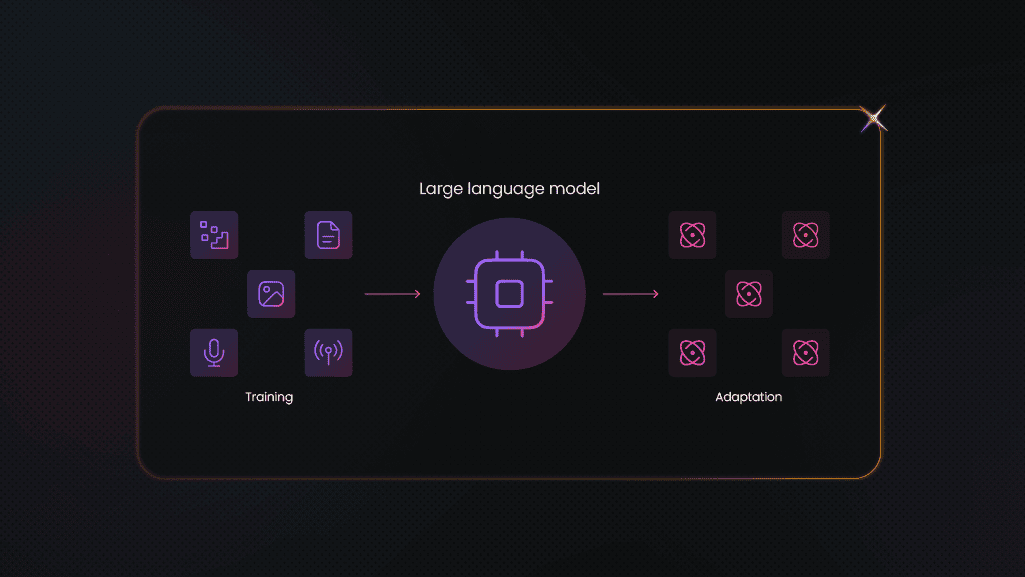
Understanding AI model training
Before going through the process, it's important to understand what AI model training really means. An AI model is a system designed to make decisions, predictions, or classifications based on input data. Training refers to feeding this model with labeled or unlabeled data so it can learn patterns, relationships, or representations.
Here's a short overview of all available models that we'll explore today:
- Regression models. Predict numerical values like house prices or stock prices.
- Classification models. Identify categories, such as spam vs. non-spam emails.
- Neural networks. Handle complex tasks like image recognition or language understanding.
Choosing between training your own model and using a pre-trained one depends on your needs:
- Use a pre-trained model. When your use case is general (like text summarization) or when you lack large-scale data.
- Train your own model. When you need control, custom features, or specialized performance.
Popular use cases for AI models
AI models are solving practical problems for businesses and individuals across many industries. And if you think ChatGPT saves you time on writing a few lines of code, you're barely scratching the surface of what's possible with the hundreds of specialized AI models available today.
- Image recognition helps companies automatically organize product catalogs and enables apps to identify objects in photos.
- Sentiment analysis allows businesses to understand customer feedback at scale, tracking how people feel about their products or services from reviews and social media.
- Fraud detection systems protect both companies and consumers by identifying suspicious transactions and activities in real-time.
- Recommendation systems drive significant business value by personalizing experiences - helping eCommerce sites increase sales, streaming platforms boost engagement, and content platforms keep users active.
- Voice assistants streamline daily tasks and customer service, allowing people to get information quickly and businesses to handle inquiries more efficiently.
Beyond these common use cases, AI models are creating value in many other ways:
- Customer service chatbots handle routine inquiries and free up human agents for complex issues.
- Predictive analytics help businesses forecast demand and optimize inventory levels.
- Automated content moderation keeps online communities safe by filtering harmful or spammy content.
- Personalization engines that tailor marketing messages to individual customer preferences.
The key is identifying specific problems where AI can either save time, reduce costs, or improve decision-making for your particular situation.
Step-by-step guide to training an AI model
Training your own AI model might seem overwhelming, but it's actually a structured process that becomes manageable when broken down into clear steps. Whether you're building a simple classifier or a more complex system, following a systematic approach will help you avoid common pitfalls and create a model that actually works for your specific needs. Here's how to get started from the ground up.
Step #1 – define the problem and objectives
Every successful AI model starts with a well-defined problem. Without knowing what you want to solve, it's easy to waste time or train the wrong model. Clear goals are key to successful model training:
- Clarify the problem and define what success looks like
- Split complex goals into manageable tasks and map out the full AI model training scope.
Step #2 – gather and prepare data
Your data is the fuel for your AI engine. The quality of what you put in directly impacts the quality of your results. Poor data leads to poor models, regardless of how sophisticated your algorithms are.
Start by determining how much data you actually need. For simple classification tasks, you might need thousands of examples per category, while complex models can require millions of data points. Consider these collection methods:
- Web scraping. Tools like Beautiful Soup or Scrapy can extract data from websites, but respect robots.txt files and rate limits. Useful for gathering product information, social media posts, or public records at scale. You can also explore automated data collection solutions, like Decodo's Web Scraping API. This tool automatically gathers data from various websites in your preferred format.
- Crowdsourcing. Platforms like Amazon Mechanical Turk or Labelbox help you get human-labeled data. Ideal for tasks requiring human judgment like image tagging or sentiment classification.
- Open datasets. Kaggle, UCI Machine Learning Repository, and Google Dataset Search offer pre-collected data. Great for learning and benchmarking, though may not fit your specific use case perfectly.
- Internal sources. Explore your existing databases, server logs, customer interactions, or transaction records. Often the most valuable data since it's directly relevant to your problem or use case.
- Synthetic data. Generate artificial data using tools like Faker for text or procedural generation for images. Useful when privacy concerns limit real data access or when you need to augment small datasets.
However, raw data is rarely ready for training. Plan to spend 60-80% of your time on this step:
- Remove duplicates. Use hash functions or fuzzy matching to identify similar records. Duplicates can cause your model to memorize rather than learn patterns.
- Fix missing values. For numerical data, try mean/median imputation or forward-fill methods. For categorical data, use mode imputation or create a "missing" category. Don't just delete rows unless missing data is minimal.
- Correct errors. Set up validation rules (e.g., ages between 0-120, valid email formats). Use spell-checkers for text data and range checks for numerical values.
- Handle outliers. Use statistical methods like IQR or Z-score to identify extreme values. Decide whether to remove them, cap them at reasonable thresholds, or transform them using log scaling.
Then it's time to pre-process your data into a format your model can understand:
- Normalize and scale. Use StandardScaler for features with different units (age vs. income) or MinMaxScaler to bound values between 0-1. This prevents features with larger scales from dominating the learning process.
- Encode categorical data. Convert text categories to numbers using one-hot encoding for nominal data (colors, countries) or label encoding for ordinal data (small, medium, large). For high-cardinality categories, consider target encoding.
- Feature engineering. Create meaningful variables from raw data. Extract day-of-week from timestamps, calculate ratios between related features, or use domain knowledge to combine existing features in useful ways.
If your model needs labeled examples to learn from, you've got two options:
- Manual labeling. Hire domain experts or use your team to label data accurately. Create clear labeling guidelines and use multiple annotators for subjective tasks. Expect to pay $15-50/hour for quality annotation.
- Automated annotation. Use existing models or rule-based systems to pre-label data, then have humans review and correct the results. This hybrid approach can reduce costs by 50-70% while maintaining quality.
Set aside 10-20% of your labeled data for testing and never let your model see it during training. This held-out data is your only reliable way to measure real-world performance.
Step #3 – choose the right model and training technique
Not every algorithm fits every task. You'll need to match your model to your goals and your data to get meaningful results. Making the wrong choice here can waste weeks of training time and computing resources.
First, figure out what you actually want your model to do:
- Regression models predict continuous numerical values like prices, temperatures, or sales figures. Use linear regression for simple relationships, polynomial regression for curved patterns, or random forests for complex non-linear relationships. For time-series data, consider ARIMA or LSTM networks.
- Classification models assign items to categories. For binary classification (yes/no, spam/not spam), try logistic regression or support vector machines. For multi-class problems, use random forests, gradient boosting, or neural networks. For image classification, convolutional neural networks (CNNs) are the standard.
- Natural language processing models require specialized architectures. Use transformer models like BERT for understanding text, GPT-style models for generation, or recurrent neural networks (RNNs) for sequence tasks like translation.
- Computer vision tasks need different approaches. CNNs work well for image classification, object detection models like YOLO for finding objects in images, and generative adversarial networks (GANs) for creating new images.
The size and quality of your dataset will determine which models actually work best with your use case:
- Small datasets (<1K samples). Stick to simple models like logistic regression, decision trees, or k-nearest neighbors. Complex models will overfit and perform poorly on new data.
- Medium datasets (1K-100K samples). Random forests, gradient boosting machines, or shallow neural networks work well. These models can capture complex patterns without needing massive amounts of data.
- Large datasets (>100K samples). Deep learning models like neural networks become viable. You can use architectures with multiple layers and millions of parameters.
Pick your learning approach based on what kind of data you have. Supervised learning works best when you have input-output pairs (features and correct answers):
- Batch learning. Train on your entire dataset at once. Works well for stable datasets that don't change frequently. Use algorithms like random forests or standard neural networks.
- Online learning: Update your model as new data arrives. Essential for streaming data or when your patterns change over time. Consider algorithms like stochastic gradient descent or online neural networks.
- Transfer learning. Start with a pre-trained model and fine-tune it for your specific task. Really effective for image recognition (use pre-trained ResNet or VGG models) or NLP (fine-tune BERT or GPT models). Can reduce training time by 80-90%.
If you're working with unlabeled data, unsupervised learning has several options:
- Clustering. Group similar items together using k-means for simple groupings or DBSCAN for complex shapes. Useful for customer segmentation or anomaly detection.
- Dimensionality reduction. Explore PCA or t-SNE to visualize high-dimensional data or reduce feature complexity before applying other algorithms.
- Anomaly detection. Identify unusual patterns using isolation forests or autoencoders. Critical for fraud detection or system monitoring.
Semi-supervised learning combines small amounts of labeled data with large amounts of unlabeled data:
- Self-training. Use your model's confident predictions on unlabeled data as additional training examples. Effective when labeling is expensive but you have lots of raw data.
- Co-training. Train multiple models on different feature sets and let them teach each other. Works well when you have different views of the same data.
Here's the thing about model complexity – start simple and work your way up. Begin with basic models like linear regression or logistic regression. They're fast to train, easy to interpret, and often surprisingly effective. Move to ensemble methods (random forests, gradient boosting) if simple models aren't cutting it. Only consider deep learning if you have enough data and computing resources.
Think about whether you need to explain your model's decisions. If you're working on credit scoring, regulatory compliance, or hiring decisions, choose interpretable models like decision trees or linear models over black-box neural networks. Also consider where your model will actually run – customer-facing apps need lightweight models for fast response times, while backend analytics systems can handle larger models.
Collect data faster with Web Scraping API
Train your AI model with publicly available data from any website. Start 7-day free trial with 1K requests and leave CAPTCHAs, IP bans, or geo-restrictions behind.
Step #4 – train the model
Now it's time to teach your model to recognize patterns and make predictions. This step is where your data turns into actionable insights that can drive business decisions like predicting customer churn, optimizing ad spend, or forecasting inventory demand.
Start by splitting your data strategically. Use 70% for training, 15% for validation, and 15% for final testing. For time-sensitive business data, like seasonal sales patterns or marketing campaigns, consider splitting the data chronologically. Train on older data and validate on more recent data to simulate real-world deployment.
Feed your training data to the model in batches. Start with a batch size of 32-128 samples for most business applications. Smaller batches work better for limited datasets like niche market segments, while larger batches are suitable when you have extensive customer data.
Monitor performance constantly to avoid common pitfalls. Overfitting happens when your model memorizes your training data instead of learning general patterns. This is particularly problematic for market research, where you need insights that apply to broader audiences. Signs include training accuracy improving while validation accuracy plateaus or decreases.
Underfitting occurs when your model is too simple to capture important business relationships. If both training and validation performance are poor, your model needs more complexity.
Hyperparameter tuning is crucial for business applications where small performance improvements translate to significant revenue:
- Learning rate. Start with 0.001 for most business problems. Higher rates (0.01) work for simpler patterns like customer segmentation, while lower rates (0.0001) are better for complex relationships like predicting individual purchase behavior.
- Epochs. Run 50-200 training cycles for most business models. Customer lifetime value prediction might need 100-300 epochs, while simple A/B test analysis could work with 20-50.
- Regularization. Use L1 or L2 regularization to prevent overfitting. This is especially important for marketing models where you have many potential features but limited sample sizes.
Use early stopping to prevent overfitting and save computational costs. Stop training when validation performance hasn't improved for 10-20 epochs. This saves time and prevents models from getting worse.
Model training is rarely perfect the first time. Plan for 3-5 iterations minimum. Common issues include poor feature selection, inadequate data preprocessing, or misaligned objectives (optimizing for clicks instead of conversions).
Step #5 – validate and test the model
Training alone isn't enough. You need to confirm that your model performs well on data it hasn't seen before, especially since business decisions based on inaccurate predictions can be costly.
Keep your test data completely isolated until the final evaluation. This held-out dataset should represent real-world conditions your model will face. For market research, use recent survey data or customer segments your model hasn't seen. eCommerce models should be tested on new product categories or customer cohorts.
Choose metrics that align with business objectives:
- Precision matters when false positives are costly. For email marketing, you don't want to incorrectly identify customers as likely to churn and send them retention offers unnecessarily.
- Recall is crucial when missing opportunities is expensive. Customer support chatbots should catch most relevant inquiries, even if they occasionally misclassify some messages.
- F1-score balances precision and recall, useful for balanced business decisions like lead scoring where you want to identify qualified prospects without overwhelming sales teams.
- ROC AUC measures how well your model distinguishes between classes across all threshold levels. Valuable for comparing different approaches to customer segmentation or ad targeting.
For business use cases, also track domain-specific metrics. Market research models should measure segment purity and business interpretability. eCommerce recommendation systems need click-through rates, conversion rates, and revenue per recommendation. SEO models should measure ranking correlation and traffic prediction accuracy.
Analyze errors systematically to understand business implications. Create confusion matrices to see which customer segments or product categories your model struggles with. Look for patterns in misclassified examples - are there seasonal effects your model missed? Do certain customer behaviors confuse your churn prediction model?
Test your model's performance across different business scenarios. A robust eCommerce model should maintain performance during Black Friday traffic spikes. Market research models should work across different survey methodologies and sample sizes.
Consider A/B testing your model against existing business processes. Deploy your model to a small segment of customers or products while keeping current methods for comparison. This approach reduces risk while providing real-world performance data that purely statistical metrics might miss.
Deployment and monitoring of the AI model
Once your model is ready, it's time to make it useful in the real world. But deployment is just the beginning - ongoing monitoring keeps it effective and relevant for your business needs.
Pick your deployment environment based on what your business actually needs:
- Cloud platforms like AWS, Google Cloud, or Azure offer scalable infrastructure that grows with your business. They're great for eCommerce recommendation engines that need to handle traffic spikes during sales events or market research tools that process survey data in batches. Most cloud providers have managed ML services that handle scaling automatically.
- On-premises deployment gives you more control over sensitive business data like customer information or proprietary market research. This works well for companies with strict data governance requirements or those in regulated industries where data must stay within specific geographic boundaries.
- Edge deployment puts your model closer to users for faster response times. This is crucial for real-time applications like dynamic pricing engines that need to adjust prices based on competitor analysis or personalized content recommendations that can't afford loading delays.
- API endpoints expose your model's functionality to other systems and teams. This is often the most flexible approach for business applications, letting your marketing team integrate churn prediction into their CRM system or your content team access SEO optimization suggestions directly from their workflow tools.
Getting your model production-ready means connecting it to your existing business systems. Link your model to frontends where users interact with predictions, data pipelines that feed fresh information, and business logic that makes decisions based on model outputs. For market research, this might mean integrating sentiment analysis into your survey platform. For eCommerce, it could involve connecting product recommendation models to your website's shopping cart system.
Track metrics that actually matter for your business operations. Set up dashboards that monitor not just technical performance but business impact. For SEO models, track how keyword ranking predictions correlate with actual traffic increases. For customer segmentation models, monitor how well predicted segments perform in marketing campaigns. Use tools like Grafana or your cloud provider's monitoring services to create real-time dashboards.
Data drift is a big concern for business applications where market conditions change constantly. Customer behavior evolves, new products launch, and economic conditions shift. Monitor your model's performance over time and set up automated alerts when accuracy drops below acceptable thresholds. For seasonal businesses, expect performance variations and plan model retraining schedules accordingly.
Set up smart alerts that notify the right teams when issues occur. Don't just alert on technical failures. Also, monitor for business-relevant problems like unusual prediction distributions or performance degradation in specific customer segments. Configure alerts to escalate appropriately, with immediate notifications for critical revenue-impacting issues and daily summaries for less urgent performance metrics.
Common challenges in AI model training
No AI project is free from roadblocks. The sooner you prepare for them, the better you can adapt your AI model and tweak the setup accordingly.
- Data issues are the most common challenge, especially for B2B applications. Customer data is often incomplete, inconsistent across systems, or biased toward certain segments. Market research data might be sparse for niche demographics, while eCommerce data could be skewed toward power users. Plan extra time for data cleaning and consider synthetic data generation for underrepresented segments.
- Privacy concerns get complex when dealing with customer data across multiple touchpoints. GDPR compliance requires careful handling of EU customer data, while CCPA affects California residents. Build privacy protection into your model development process from the start, using techniques like differential privacy or federated learning when appropriate.
- Infrastructure demands can drain budgets, especially for resource-intensive models like deep learning systems processing large product catalogs or analyzing extensive market research datasets. Cloud costs can escalate quickly during model training and inference. Consider using spot instances for training, implementing model compression techniques, and optimizing inference pipelines to reduce ongoing costs.
- Explainability becomes crucial when models influence business decisions that affect customers or require regulatory justification. Loan approval models need clear reasoning, while marketing personalization systems should be able to explain why certain recommendations were made. Choose interpretable models when transparency is more important than marginal performance gains.
Best practices for successful AI model training
What sets apart a reliable AI model from one that doesn't work? It's often not the algorithm, but how you approach the process. These habits can make or break your results and determine whether your model actually delivers business value.
- Start small with pilot projects that show value quickly. Test ideas with minimal data and simple models before investing in complex systems. A basic customer churn prediction model using just purchase history and support interactions can prove the concept before building comprehensive behavioral analysis systems.
- Focus on data quality over quantity. Clean, well-annotated, and diverse datasets produce better results than massive but messy collections. For market research, make sure your survey data represents your target demographics. For eCommerce, verify that product categorization is consistent and complete. For SEO, validate that keyword performance data includes all relevant ranking factors.
- Keep detailed records of everything you try. Document model versions, configuration settings, and experiment results. This becomes invaluable when you need to reproduce successful results or understand why certain approaches didn't work. Use tools like MLflow or Weights & Biases to track experiments systematically.
- Validate your models regularly against real-world performance. Statistical metrics are useful, but business impact is what matters. A/B test your recommendations against existing systems, monitor how predicted customer segments perform in marketing campaigns, and track whether SEO predictions actually correlate with traffic changes.
- Experiment with hyperparameters systematically rather than randomly. Use techniques like grid search or Bayesian optimization to find optimal settings efficiently. For business applications, focus on parameters that affect interpretability and inference speed, not just accuracy.
Here's a realistic example that shows the entire process for a common B2B use case:
The problem was improving product recommendations for an online retail platform to increase average order value and customer satisfaction. The company wanted to move beyond basic "customers who bought this also bought" recommendations to more sophisticated personalization.
Data collection involved customer purchase history, browsing behavior, product catalog information, and seasonal sales patterns. The team used collaborative filtering combined with content-based features like product categories, price ranges, and brand preferences. They also incorporated contextual factors like time of day, device type, and current cart contents.
The model architecture used a hybrid approach combining matrix factorization for collaborative filtering with neural networks for content-based recommendations. Training involved 80% of historical data with 20% held out for testing, stratified by customer segments to ensure representative evaluation.
Performance evaluation focused on business metrics like click-through rates, conversion rates, and revenue per recommendation, not just prediction accuracy. The team also measured recommendation diversity to avoid filter bubbles and novelty to help customers discover new products.
Deployment used a real-time API that integrated with the existing website infrastructure, providing recommendations within 100ms response times. The system handled A/B testing to gradually roll out the new recommendations while monitoring performance against the existing system.
Bottom line
The key to successful AI model training is starting with a clear business problem, focusing on data quality over complexity, and building systems that can adapt as your business evolves. Don't aim for perfection on your first try – aim for a working system that delivers measurable value and can be improved over time.
Remember that the most sophisticated algorithms won't help if your data doesn't reflect real customer behavior or if your model can't integrate with existing business processes. Success comes from understanding your domain, involving stakeholders throughout the process, and building systems that make your team more effective at serving customers.
Get real-time data for your AI models
Train your AI-powered tools with data from almost any website online. Activate your 7-day free trial of our Web Scraping API.
About the author

Mykolas Juodis
Head of Marketing
Mykolas is a seasoned digital marketing professional with over a decade of experience, currently leading Marketing department in the web data gathering industry. His extensive background in digital marketing, combined with his deep understanding of proxies and web scraping technologies, allows him to bridge the gap between technical solutions and practical business applications.
Connect with Mykolas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.