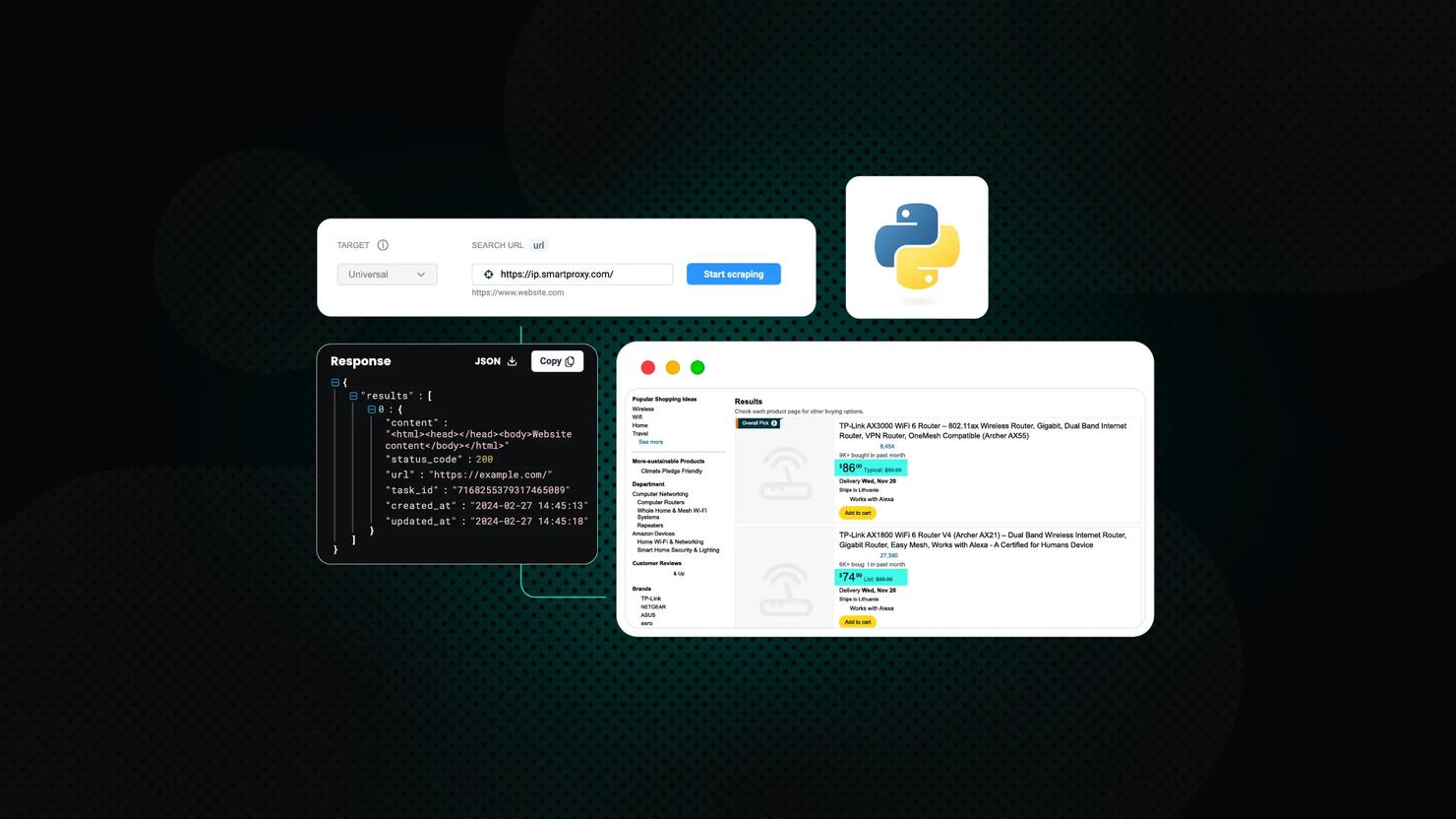
How to Scrape Target Product Data: A Complete Guide for Beginners and Pros
Target is one of the largest retailers in the US, offering a wide range of products, from electronics to groceries. Scraping product data can help you track prices, monitor trends, or build comparison tools to enhance your purchasing decisions. This guide outlines the process, provides suggestions, and provides instructions on how to extract data, such as prices and ratings, efficiently.
Justinas Tamasevicius
Last updated: Jul 07, 2025
6 min read

What is Target?
Target is one of the largest retail chains in the United States, offering a wide range of products – from electronics and home goods to groceries and apparel – both in-store and online. Its website provides rich, structured product data including names, prices, descriptions, reviews, availability, and promotions. With the right tools and a properly configured proxy setup, it’s a goldmine of real-time retail intelligence.
Understanding Target’s website
Target's website is built with a combination of static and dynamic elements. Product listing pages (search results) typically load multiple product tiles, each containing summary information such as the name, thumbnail image, sale price, and rating. These listings are often paginated or rendered incrementally as users scroll through them.
In contrast, product detail pages present comprehensive information about a single item. These pages generally include:
- The product title (usually in an <h1> tag)
- Pricing (regular and promotional, sometimes shown conditionally)
- Inventory availability by ZIP code or store location
- Customer ratings and number of reviews
- Category breadcrumbs and metadata
While some of this data is directly embedded in the HTML, others, especially price, stock level, and customer feedback, are rendered dynamically using JavaScript. In many cases, key content is stored in JSON files or fetched from background APIs. This means that a basic HTML fetch might not surface all the information unless you parse the script content or simulate a browser.
Target also uses various anti-scraping features to protect the content. These include:
- Bot detection. Unusual browsing behavior or missing headers can trigger blocks
- Rate limiting. Too many rapid requests from one IP can lead to 429 or CAPTCHA responses
- Geo-restrictions and headers. Certain features vary based on the user's location and accepted languages
- Cookie-dependent rendering. Some dynamic elements depend on session cookies or user context
Understanding this structure helps you design more resilient scraping strategies and know when to upgrade from simple request calls to browser automation tools like Selenium or automated solutions, like Web Scraping API that handle such challenges natively.
Choosing the right scraping approach
There are three main paths to scrape Target data:
- No-code tools. Easy for beginners, but limited in flexibility.
- Code-based scraping. Offers full control. Python, combined with requests and Beautiful Soup, is a solid choice.
- Third-party scraping APIs. Ideal for scale and reliability. APIs like Web Scraping API handle complex anti-bot logic so you don’t have to.
Step-by-step scraping of Target product data
In this guide, we’ll be using the code-based scraping method with Python and Selenium. This approach gives you full control over how requests are sent, data is parsed, and results are stored. It’s a great choice for developers or analysts who want reliable, repeatable results without depending on third-party tools. Below, we’ll walk through setting up your environment, inspecting the site, and writing your first Target scraper.
Step #1 – install Python
Ensure that you have Python installed on your system and that it's added to your system's PATH during installation.
Step #2 – install Google Chrome
Download and install the latest version of Google Chrome.
Step #3 – download ChromeDriver
Visit the ChromeDriver download page. Download the version of ChromeDriver that matches your installed version of Google Chrome. Extract the downloaded file and note the path to the chromedriver.exe file.
Step #4 – set up a virtual environment
Optional but recommended step. Get started by opening a terminal and navigate to the directory containing your project. Create a virtual environment:
Activate the virtual environment:
On Windows:
On macOS/Linux:
Step #5 – install the required Python packages
Install the necessary packages using pip:
Step #6 – inspecting the Target website
Use browser developer tools to inspect the page and find:
- The product title. It's often found in one of the <h1> elements.
- The price. Search for elements containing the $ symbol.
Step #7 – building the scraper
To get started with the scraper:
- Create a new file: scrape_target_selenium.py.
- Use the code below and save the file.
3. Replace the PRODUCT_URL with the address of your choice.
4. Run the scraper:
5. Check the results:
Overcoming anti-scraping measures
To reduce detection and avoid errors while collecting data from Target:
- Rotate IPs with residential or datacenter proxies. If you send too many requests from a single IP address, Target may flag and block it. IPs from trusted providers (we're talking about Decodo), especially residential ones that appear as typical users, as you distribute your traffic across multiple sources, making it harder for the site to detect automation.
- Change user-agent strings periodically. Sending all requests with the same browser fingerprint makes scraping predictable. Switching user-agent strings to mimic different devices and browsers (e.g., Chrome on Windows, Safari on iOS) helps you avoid detection by appearing more like organic traffic.
- Add delays or random sleeps between requests. Making rapid-fire requests is a telltale sign of a bot. Inserting short, random pauses (e.g., 1-5 seconds) between requests simulates human behavior and avoids tripping Target’s rate-limiting systems.
- Use sessions to persist cookies. Some pages on Target rely on cookies to serve content based on your browsing path or location. A requests.The Session() object maintains these cookies across requests, ensuring smoother navigation and helping to avoid access issues.
- Detect and handle CAPTCHAs. When you’re served a CAPTCHA or redirected to a verification page, it means your scraper has been flagged. You can either build logic to detect these responses and back off, or use services such as Decodo that provide reliable proxies that don't trigger CAPTCHAs frequently.
Exporting and using the data
Once the Target product data is extracted, you can:
- Export data to CSV, HTML, or JSON. These formats are ideal for lightweight analysis or sharing across tools. For example, you might export product data to a CSV file and open it in Excel to filter for specific price ranges or categories. JSON is especially useful if you plan to feed the scraped data into a web app or an API, while HTML is a great format for LLMs to parse through and find the information you require.
- Feed the data to AI tools and agents. Real-time data from eCommerce platforms like Target, Walmart, or Amazon can help your AI-powered tools to make informed decisions, personalize product recommendations, or dynamically adjust pricing strategies. For example, a chatbot could use up-to-date product listings to answer customer queries about availability or pricing, while a market intelligence agent might analyze competitor listings to detect trends or pricing shifts.
- Store in a database. For recurring scrapes or larger datasets, saving data into a relational database (such as PostgreSQL or MySQL) or a NoSQL option (like MongoDB) enables better querying, indexing, and version control. This makes it easier to track changes in pricing over time or compare different product categories.
- Use for dashboards, price tracking tools, or competitive analysis. You can feed the data into tools like Tableau, Power BI, or even a custom web dashboard to visualize trends and alerts. For instance, eCommerce businesses might track competitor pricing on a daily basis and receive automatic notifications when a Target item drops below a set threshold.
Scaling your scraping operations
If you're serious about your project and need to collect data from multiple Target pages:
- Loop through a list of URLs.
- Use asynchronous requests (aiohttp, httpx) or multithreading.
- Automate jobs with cron or task schedulers.
- Handle layout changes using robust selectors.
- Implement logging and error handling for resilience.
If your project is scaling rapidly or you’re managing high-frequency scraping, it may be time to move beyond local scripts. Deploying scrapers via cloud platforms offers better uptime, but maintaining proxies, solving CAPTCHAs, and adapting to layout changes can become a full-time task.
This is where scraping APIs are particularly valuable. They handle all the infrastructure, anti-bot protections, IP rotation, and data parsing for you. You simply send a request and get clean, structured output in return. Scraping APIs are ideal when:
- You need consistent access to data across thousands of products.
- You’re hitting rate limits or frequent blocks.
- You want to avoid rewriting selectors every time the layout changes.
- You lack the bandwidth or expertise to maintain a custom scraping setup.
If you’re looking for a fast, reliable, and scalable solution, Decodo’s Web Scraping API is designed for exactly this use case. It provides real-time access to Target product data without the need to manage code or infrastructure.
Common pitfalls and how to fix them
Even a well-built scraper can run into challenges. Below are some of the most common pitfalls developers face when scraping Target and how to overcome them:
- Data duplication and inconsistency. When scraping large sets of products or running your scraper on a schedule, duplicated entries can sneak into your dataset. For example, if a product is listed under multiple URLs or appears in multiple categories, you might unintentionally record it more than once. To prevent this, implement logic to compare product IDs, SKUs, or titles before writing to your storage system. Normalize fields (e.g., removing extra spaces or special characters) to avoid near-duplicates caused by formatting differences. Unchecked duplication can lead to inflated counts and skewed analytics.
- Website layout changes and broken scrapers. Target updates its frontend design from time to time. This could mean a class name changes or an element shifts to a new part of the page. These small changes can break your selectors and parsing logic, causing your scraper to miss or misinterpret data. Writing modular code that separates HTML parsing from the scraping logic makes updates easier. Monitor your scraping jobs and set up error logging or alerts to detect failures early. Regularly scheduled test scrapes are also helpful to ensure your code still works as expected.
- Handling unexpected errors and blocks. Even with headers, cookies, and delay strategies in place, scrapers can still get blocked or hit edge cases. For instance, if Target detects bot-like behavior, it might issue a CAPTCHA, serve a 403 Forbidden status, or redirect to an error page. To avoid silent failures, wrap your requests and parsing logic in try/except blocks and log all unexpected responses. Implement retry logic with exponential backoff for transient errors. If you skip this, your scraper may silently fail or flood your logs with misleading outputs, making it difficult to identify real issues. Planning for failure helps ensure continuity and reduces maintenance overhead.
Scraping is both a technical and strategic task. Whether you're a solo developer or a data team lead, getting the correct data starts with the right mindset, modular tooling, and a plan for handling edge cases.
Bottom line
Scraping Target product data is a valuable asset. You can gather real-time pricing, track promotions, and power smart tools. Start small, follow the law, and upgrade your methods as needed. Whether you code it yourself or use a scraping API, the goal is the same – clean, usable product data from one of America’s top retailers.
Collect Target data with just a few clicks
Get a 7-day free trial with 1K requests of the advanced Web Scraping API features.
About the author

Justinas Tamasevicius
Director of Engineering
Justinas Tamaševičius is Director of Engineering with over two decades of expertise in software development. What started as a self-taught passion during his school years has evolved into a distinguished career spanning backend engineering, system architecture, and infrastructure development.
Connect with Justinas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.