Target Scraper API
Collect real-time product data at scale with our Target scraper API* to get data points like pricing, inventory, reviews, minus IP blocks and CAPTCHAs.
* This scraper is now a part of the Web Scraping API.
125M+
IPs worldwide
99.99%
success rate
200
requests per second
100+
ready-made templates
Free
starter plan
Be ahead of the Target product scraping game
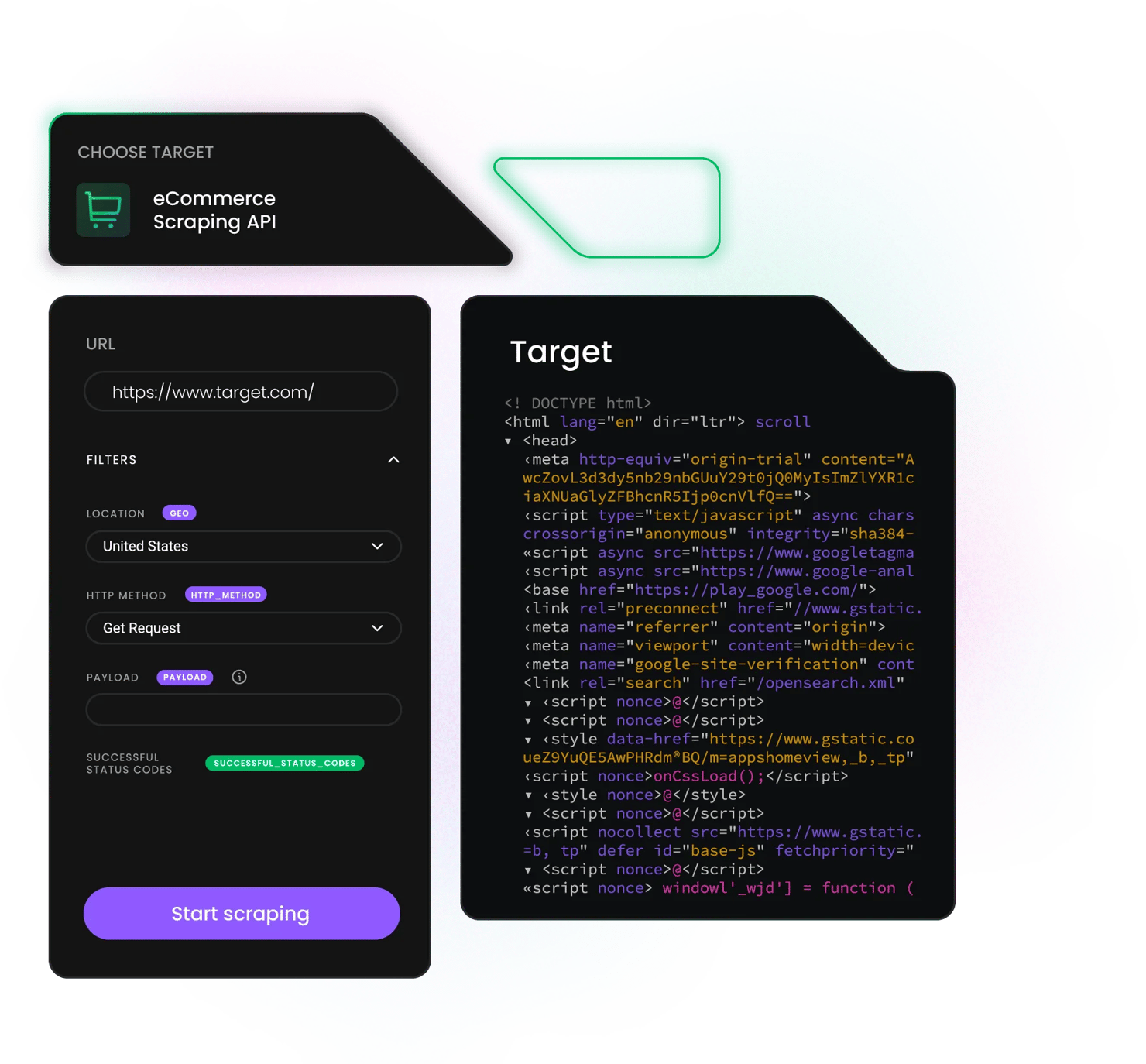
Extract data from Target
eCommerce Scraping API is a powerful data collector that combines a web scraper, a data parser, and a pool of 125M+ residential, mobile, ISP, and datacenter proxies. That’s why you can perform Target product data scraping in an instant. Here are some of the key data points you can extract with it:
- Product details
- Pricing data
- Inventory status
- Customer reviews
- Promotions and deals
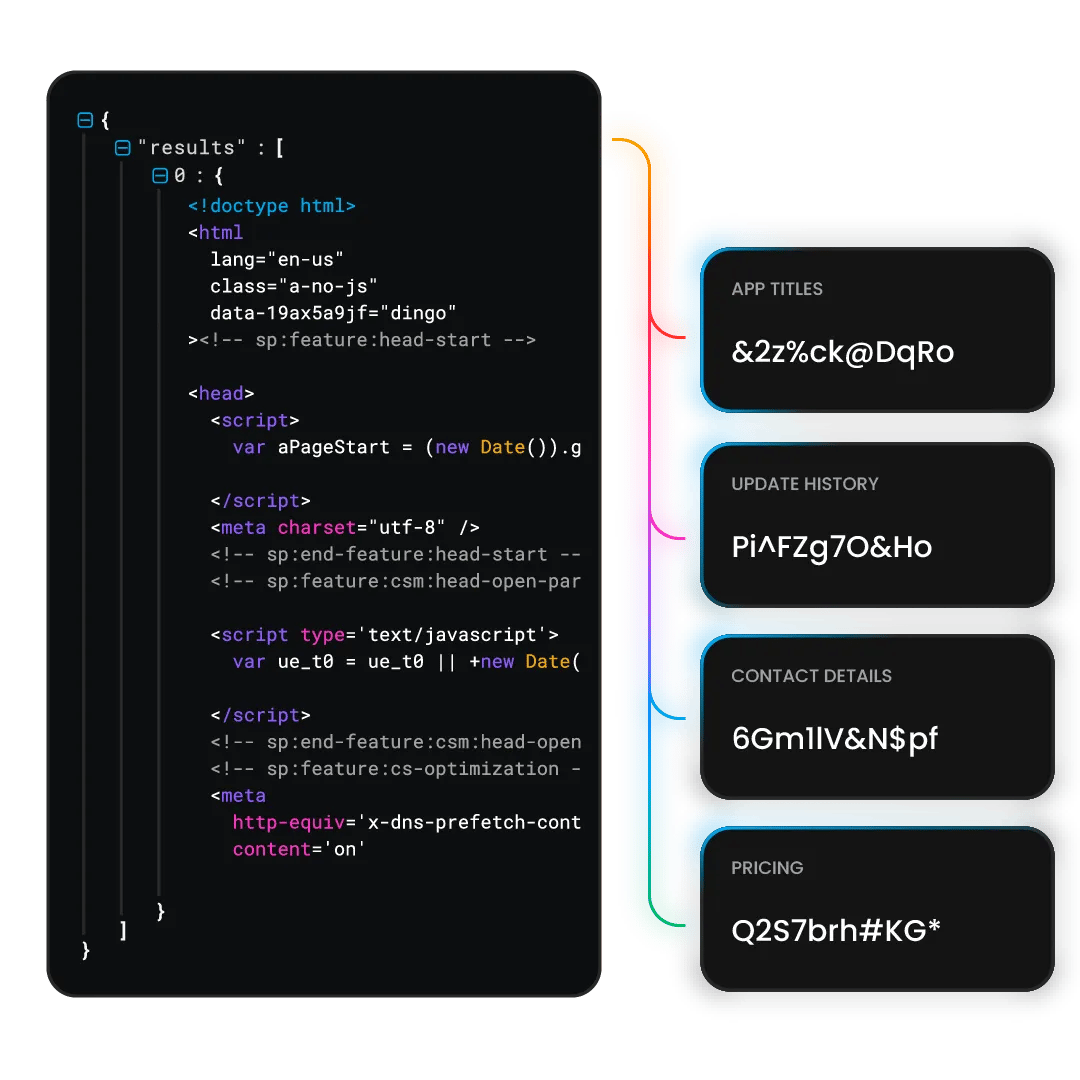
What is a Target scraper?
A Target scraper is a tool that extracts data from the Target website. With our Target scraper API, you can send a single API request and receive the data you need in HTML, JSON, or CSV format. Even if a request fails, we’ll automatically retry until the data is delivered. You'll only pay for successful requests.
Designed by our experienced developers, this tool offers you a range of handy features:
Built-in scraper and parser
JavaScript rendering
Easy API integration
195+ geo-locations, including country-, state-, and city-level targeting
No CAPTCHAs or IP blocks
Scrape Target product data with Python, Node.js, or cURL
Our Target scraper API supports all popular programming languages for hassle-free integration with your business tools.
Target scraper API is full of awesomeness
Scrape Target data with ease using our powerful API. From flexible output options to built-in proxy integration, we ensure seamless data collection without blocks or CAPTCHAs.
Flexible output options
Select from HTML, JSON, or parsed table results to suit your specific scraping needs.
100% success
Pay only for successfully retrieved results from your Target queries.
Real-time or on-demand results
Choose when you need the data – collect real-time results now or schedule scraping tasks for later.
Advanced anti-bot measures
Leverage integrated browser fingerprints to avoid detection and CAPTCHAs.
Easy integration
Integrate our APIs into your workflows with straightforward quick start guides and code examples.
Proxy integration
Leave CAPTCHAs, IP blocks, and geo-restrictions behind with 125M+ IPs under the scraping API hood.
API Playground
Send your first test request using our interactive API Playground in the dashboard.
What does Web Scraping API cost?
Choose a plan based on your scraping volume. All plans include the same powerful features – you only pay for what you use. Start with the free plan to test before committing.
Plan prices
+VAT / Billed monthly
Rate limit
All prices shown are per 1K req.
Plan price
$0
+VAT / Billed monthly
Request type
Price per 1k req.
2K req.
$0.50
1K req.
$0.75
1K req.
$1.00
667 req.
$1.50
Rate limit
10 req/s
Plan price
$19
+VAT / Billed monthly
Request type
Price per 1k req.
38K req.
$0.50
25K req.
$0.75
19K req.
$1.00
12K req.
$1.50
Rate limit
10 req/s
Plan price
$49
+VAT / Billed monthly
Request type
Price per 1k req.
163K req.
$0.30
75K req.
$0.65
54K req.
$0.90
39K req.
$1.25
Rate limit
25 req/s
Plan price
$99
+VAT / Billed monthly
Request type
Price per 1k req.
707K req.
$0.14
165K req.
$0.60
116K req.
$0.85
82K req.
$1.20
Rate limit
50 req/s
Need more?
Request type
Price per 1k req.
Custom
Custom
Custom
Custom
Rate limit
Custom
For low-security sites and simple access
For accessing guarded or sensitive pages
With each plan, you access:
99.99% success rate
Results in HTML, JSON, CSV, XHR or PNG
MCP server
JavaScript rendering
AI integrations
100+ pre-built templates
Supports search, pagination, and filtering
LLM-ready markdown format
24/7 tech support
14-day money-back
SSL Secure Payment
Your information is protected by 256-bit SSL

What people are saying about us
We're thrilled to have the support of our 135K+ clients and the industry's best
Attentive service
The professional expertise of the Decodo solution has significantly boosted our business growth while enhancing overall efficiency and effectiveness.
N
Novabeyond
Easy to get things done
Decodo provides great service with a simple setup and friendly support team.
R
RoiDynamic
A key to our work
Decodo enables us to develop and test applications in varied environments while supporting precise data collection for research and audience profiling.
C
Cybereg
Trusted by:
Decodo blog
Build knowledge on our solutions and improve your workflows with step-by-step guides, expert tips, and developer articles.
Most recent

Best US Proxies in 2026: Top Providers Compared
The best US proxies let you access US-only websites, scrape local web data, manage US-targeted accounts, and verify digital ads from different locations. They route your internet traffic through an IP address located in the United States, making websites recognize your requests as coming from an American user so you don’t get blocked. This guide compares the best US proxies using US-specific performance metrics.
Kotryna Ragaišytė
Last updated: Jul 31, 2026
16 min read
Most popular
Residential vs Datacenter Proxies: Which Should You Choose?
At first glance, residential and datacenter proxies may seem the same. Both types act as intermediaries that hide your IP address, allowing you to access restricted websites and geo-blocked content. However, there are some important differences between residential and datacenter proxies that you should know before making a decision. We’re happy to walk you through the differences so you can choose what's right for you.
Vilius Sakutis
Last updated: Apr 22, 2026
7 min read

Google Sheets Web Scraping: An Ultimate Guide for 2026
Google Sheets is a powerful data management tool, but few people know it can also pull data directly from the web without a single line of code. Using built-in import functions, you can scrape website content, parse tables, and pull live feeds straight into your spreadsheet. In this guide, you'll learn how to use IMPORTXML for XPath-based data extraction, IMPORTHTML for grabbing tables and lists, IMPORTFEED for RSS and Atom content, IMPORTDATA for CSV files, and IMPORTRANGE to link scraped data across spreadsheets. We'll also cover Google Apps Script for automation, common errors and how to fix them, and when to reach for a dedicated scraping tool instead.
Zilvinas Tamulis
Last updated: Mar 30, 2026
6 min read

Manage Your Business Reputation with SERP Scraping API
A widely available internet leaves the door open for people to find information about everything. For example, everyone can check a business's online presence before trusting it. So, everything that could be found online about your brand helps your potential audience evaluate if you’re legit.
Statistics only prove that – 9 out of 10 online shoppers admit that reviews influence their buying decisions. It stands to reason – checking unbiased opinions helps avoid low-value products and potential scams. And who wants that? So, for businesses analyzing their customers’ reviews becomes a not-to-miss-out factor.
However, reviews are just one part of the game. Brand reputation management consists of various elements that form the customers' perception of the company. If it’s still a gray area for you, this blog post could be your starting point.
Ella Moore
Last updated: Jun 20, 2022
7 min read

How to Scrape Google Without Getting Blocked
Nowadays, web scraping is essential for any business interested in gaining a competitive edge. It allows quick and efficient data extraction from a variety of sources and acts as an integral step toward advanced business and marketing strategies.
If done responsibly, web scraping rarely leads to any issues. But if you don’t follow data scraping best practices, you become more likely to get blocked. Thus, we’re here to share with you practical ways to avoid blocks while scraping Google.
James Keenan
Last updated: Feb 20, 2023
8 min read

What Is SERP Analysis And How To Do It?
SERP (Search Engine Results Page) analysis involves examining search engine results for specific keywords to understand website rankings. It helps identify the content, format, and optimization strategies used by top-ranking pages and uncovers opportunities for improving rankings. In this blog post, we’re exploring what SERP analysis is, how to conduct it, and how it can help you.
James Keenan
Last updated: Feb 20, 2023
7 min read
How to Scrape Amazon Prices
Amazon is the ultimate shopping platform, serving as a vast database of current, competitive pricing information. For anyone looking to track eCommerce prices, explore trends, or gain insights for competitive analysis, scraping Amazon prices is a powerful way to gather such data. In this guide on how to scrape Amazon prices, we’ll dive into the essential methods and tools available to help you gather pricing data and keep an eye on the latest deals and price changes.
Dominykas Niaura
Last updated: Nov 15, 2024
8 min read

America’s Top 5 eCommerce Platforms with Most Frequent Price Changes
Nowadays, the price of your favorite product could change at any moment – a few dollars more expensive or, if you're lucky, cheaper by the minute. For savvy shoppers and businesses alike, tracking these changes can offer a competitive edge. In the highly challenging landscape of American eCommerce, some platforms stand out for their dynamic pricing strategies, adjusting costs so frequently it feels like a game of cat and mouse.
This time, our experts explored the eCommerce Dynamic Pricing Index even further, and we’re about to uncover the top 5 eCommerce platforms in the United States and Canada, where prices never sit still. Also, we’re analyzing the purpose of dynamic pricing for eCommerce websites and how businesses and shoppers benefit from this practice.
Dominykas Niaura
Last updated: Oct 23, 2024
6 min read
How to Scrape Products from eCommerce Sites: The Ultimate Guide
Since there are over 2.14 billion online shoppers worldwide, understanding how to scrape products from eCommerce websites can give you a competitive edge and help you find relevant data to drive your business forward. In this article, we’ll discuss the 4 fundamental steps to scraping eCommerce sites and how to avoid some of the most common pitfalls.
Martin Ganchev
Last updated: Oct 02, 2024
4 min read
How to Scrape Amazon ASIN
Imagine you want to collect ASINs (Amazon Standard Identification Numbers) for all the products that appear on Amazon after searching for a specific item. This can be incredibly useful for tasks like market research, competitor analysis, or managing your own product listings. With our Amazon scraper, you can easily gather these ASINs directly from the search results, making the data collection process quick and efficient. In this guide, we’ll show you how to use our ready-made Amazon scraper to extract ASINs and explain how this information can benefit your business.
Dominykas Niaura
Last updated: Dec 03, 2024
7 min read
What Is Web Scraping? A Complete Guide to Its Uses and Best Practices
Web scraping is a powerful tool driving innovation across industries, and its full potential continues to unfold with each day. In this guide, we'll cover the fundamentals of web scraping – from basic concepts and techniques to practical applications and challenges. We’ll share best practices and explore emerging trends to help you stay ahead in this dynamic field.
Dominykas Niaura
Last updated: Jan 29, 2025
10 min read
Frequently asked questions
Do you provide dedicated support for Target scraping?
Yes, we offer dedicated support for Target scraping, including 24/7 tech support for fast troubleshooting of any potential issues you might face when collecting publicly available data. Users with bigger subscriptions also get a dedicated account manager who offers technical guidance, implementation support, and tips on scaling your scraping operations efficiently.
Do I need coding skills to use the Target scraper API?
No, you don’t necessarily need coding skills to use our Web Scraping API. You can conveniently collect data using our pre-made scraping templates for various Target queries. With a single request, you can get data from various Target product and search pages. For more advanced use cases, basic coding knowledge (e.g., Python or JavaScript) can help with customization and automation.
We also offer detailed documentation, quick start guides, and code examples, making it easy for non-developers to follow along. And if you face any challenges while scraping Target, our 24/7 tech support is available via LiveChat.
Is using a Target scraper legal?
Scraping publicly available data from Target is legal, especially when used responsibly and in compliance with applicable laws and website terms. We encourage consulting legal counsel for compliance in specific jurisdictions.
Can I customize what data fields I extract from Target?
Absolutely! The Target scraper API allows you to define exactly what data fields to extract, including product names, SKUs, prices, images, descriptions, availability, and ratings. This means you can tailor your extraction to your unique business needs without collecting unnecessary information.
How reliable is Decodo’s Target scraper API?
Decodo’s Target scraper API is built for enterprise-grade reliability, with a guaranteed 99.99% uptime and 100% success rate. Our platform offers built-in error handling, smart retries, and dynamic IP rotation, ensuring consistent and accurate data delivery.
What are the main use cases for Target data scraping?
Target data can be leveraged for price monitoring, competitive intelligence, inventory and stock analysis, brand and MAP compliance monitoring, market research, trend analysis, and eCommerce automation.
Target Scraper API for Your Data Needs
Gain access to real-time data at any scale without worrying about proxy setup or blocks.
14-day money-back option