Best Web Scraping Services: 2026 Comparison Guide
More and more industries now depend on data to make informed choices, which means having a fast, reliable way to collect structured web data is no longer optional. It’s a core need. In this overview, we’ll examine the top web scraping services of 2026, covering what they provide, their pricing models, the users they serve best, and their unique strengths. Whether you’re growing your data infrastructure or moving on from outdated tools, this guide is here to help you make a smart, well-matched choice.
Lukas Mikelionis
Last updated: Jan 06, 2026
5 min read
What is a web scraping service?
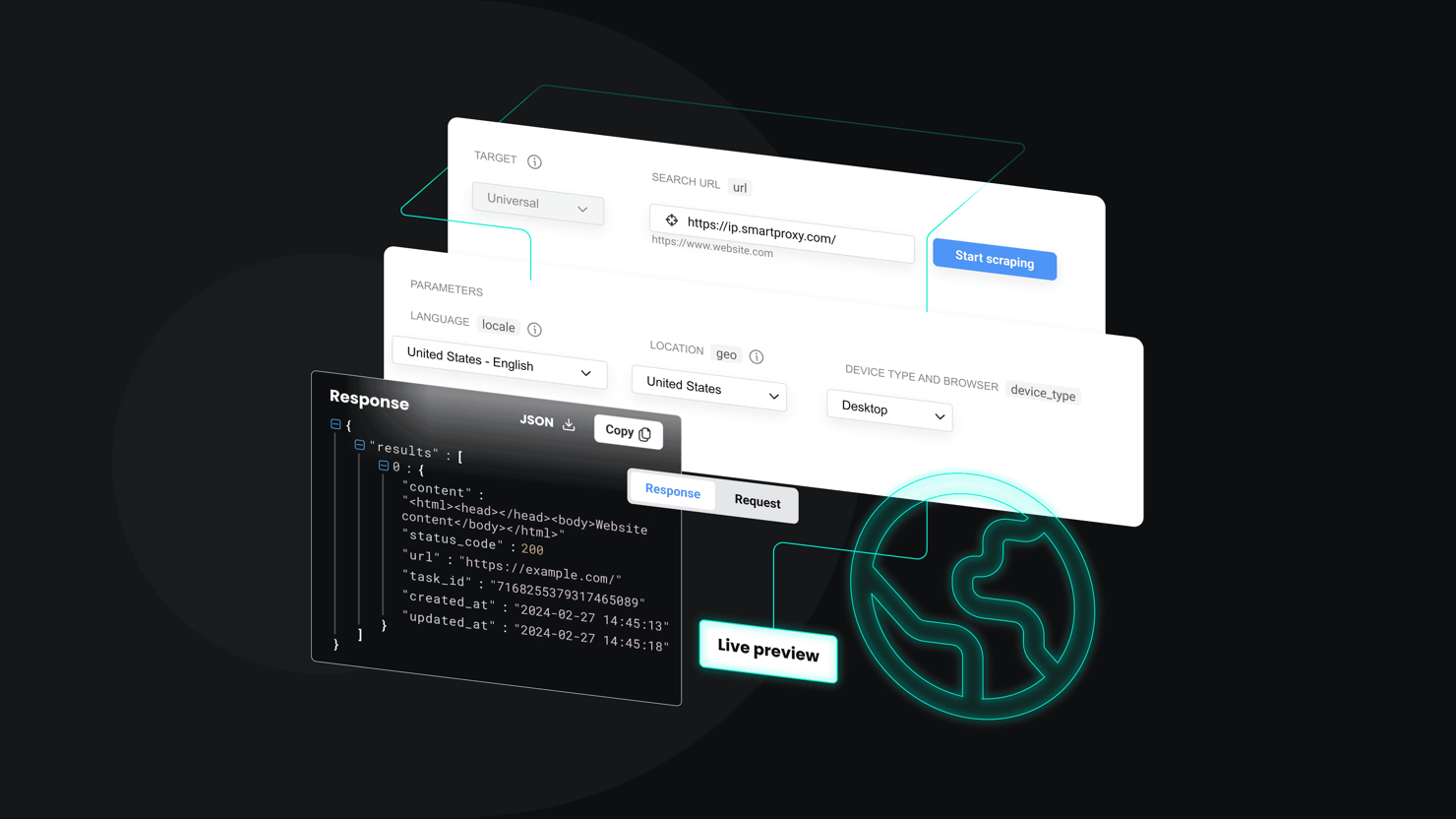
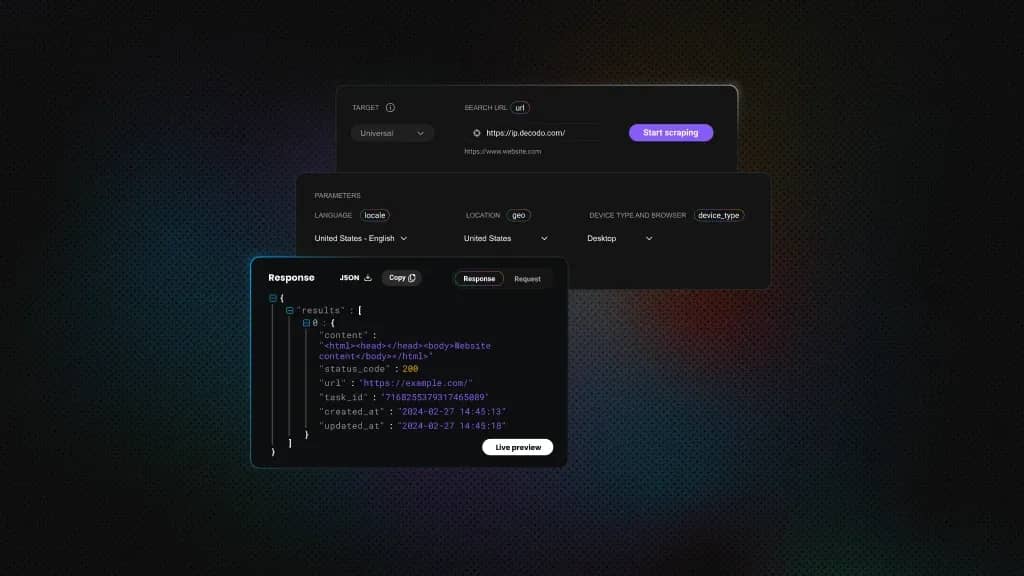
Web scraping services are platforms that help you automatically collect structured or semi-structured data from websites. Unlike do-it-yourself tools or open-source libraries, these services usually come ready with features like proxy handling, CAPTCHA bypassing, error management, and the ability to load dynamic web content, so you don’t have to build all that from scratch.
Common users include:
- Developers and data engineers working on automation and integration
- Product teams in need of competitive or pricing data
- AI/ML teams sourcing training data
- Enterprise teams managing compliance and scale
There are two main categories of scraping service providers:
- Managed web scraping services. Web scraping companies that provide such services offer fully outsourced data delivery, with minimal configuration and maintenance required from the user.
- Self-service APIs. These kinds of web scraping APIs provide flexible programmatic access for teams with in-house technical capabilities.
How to choose the best web scraping service
Choosing the right service starts with aligning technical requirements with business goals. Key selection criteria include:
- Data extraction capabilities. Can it extract accurate data? What about its validation process? Can the service handle JavaScript-heavy content, pagination, dynamic DOM elements, and complex selectors?
- Supported output formats and delivery. The data produced should be in a format that your business can use. Look for JSON, CSV, or XML support, and options for API, webhook, or cloud storage delivery.
- Interface and accessibility. Consider no-code web scraping or low-code interfaces if non-developers will use the service. However, developers may prefer raw API access or SDKs. Choose according to the technical capabilities of the end user.
- Scalability and performance. Your scraping solution should grow with you. Make sure it can handle changes in volume without sacrificing speed or accuracy. Check for things like concurrent request limits, average response time, and performance benchmarks.
- Pricing model. Transparent billing, whether per request, per GB, or monthly, is essential. Free trial access allows for low-risk evaluation. Choose one with a favorable pricing structure based on your business needs.
- Support and onboarding. Reliable onboarding, documentation, and technical support are non-negotiable in enterprise environments. Don’t just check if support is offered. Consider how fast, helpful, and knowledgeable the team is when you need them most.
Try Decodo's all-in-one Web Scraping API
Unlock 100+ ready-made scraping templates, advanced targeting, and other essential features with a free starter plan.
Detailed reviews of the best web scraping services
1. Decodo
Decodo delivers high-performance web scraping services through its Core and Advanced plans for Web Scraping API. Designed to manage challenges like proxy rotation, CAPTCHA bypassing, and anti-bot protection, Decodo removes the need for complex infrastructure so users can focus directly on data use.
Its emphasis on speed, scalability, and reliability makes it ideal for businesses needing clean, consistent public data from diverse online sources. The top features of this web scraping solution include:
- Handles complex websites that rely on JavaScript to load content
- You can automate scraping tasks to run at set intervals, saving manual effort
- Data is delivered in clean formats like JSON, HTML, or CSV, ready for immediate use
- The service manages proxy rotation and supports geo-targeting in 195+ locations
- Comes with built-in scraping templates and anti-bot tools for faster setup
Pros
- Robust infrastructure built for scalability
- Low-latency performance with 100% success rate
- Flexible targeting and rotating IPs
Cons
- Focused on technical users; not ideal for no-code users
Pricing
When it comes to pricing, Decodo’s pricing is designed to fit different needs, with Core and Advanced plans available. You only pay for what you use, thanks to a flexible, usage-based billing model. Decodo is best for developers, data teams, and enterprises requiring custom scraping logic at scale.
Differentiator
All-in-one Web Scraping API bundled with Decodo’s high-performance proxy network.
2. Scrapfly
Scrapfly is a developer-friendly scraping API that takes care of JavaScript, proxies, and bot detection for you. It speeds up data collection and ensures clean output, so your team can focus on what matters, which is using the data. With flexible tools and solid infrastructure, it’s built for teams that want full control without the hassle. Find the top features below.
- Can scrape websites that use JavaScript, manage user sessions, and target specific countries
- Allows you to add custom headers and cookies to control how requests are handled
- Offers detailed logging to help you debug issues and optimize scraping performance
Pros
- Highly flexible and transparent
- Competitive pricing for developers
Cons
- Support for non-technical users is minimal
Pricing
Scrapfly provides scalable pricing options and a generous free plan. It’s designed for developers and startups who prefer hands-on control.
Differentiator
Built around a dev-first experience with detailed control over every request.
3. Apify
Apify is a scalable scraping and automation platform built for flexibility. It works well with both custom scripts and pre-built actors, making it easy to manage a wide range of tasks.
With core features like cloud storage, scheduling, proxy support, and webhooks, it is ideal for teams that need strong, adaptable scraping workflows. Notable features include:
- A marketplace of pre-built scraping tools you can modify or use right away
- Full support for complex sites via headless browsers that simulate user interaction
- Includes built-in cloud storage and scheduling so your data is saved automatically and tasks run on a set timeline
Pros
- Flexible architecture and community-driven actors
- Strong no-code and low-code options
Cons
- Performance varies based on actor quality
Pricing
With a compute unit (CU)-based pricing model, Apify charges according to the resources your tasks use. With a free tier included, it’s easy to start testing or run smaller scraping jobs. The platform works best for small to mid-sized teams that want to use visual tools and also have the option to write custom code.
Differentiator
Merges an automation marketplace with a customizable, developer-friendly framework.
4. ScrapingBee
ScrapingBee is an API-based web scraping platform built to simplify data collection from JavaScript-heavy websites. It allows technical teams to focus on data processing rather than infrastructure maintenance by managing the technical side of things. While it positions itself as a developer-centric tool, ScrapingBee's API is a fairly accessible tool for smaller data projects.
Top features include:
- Headless browser and JavaScript rendering support
- Automatic datacenter and residential proxy rotation
- CAPTCHA handling and reCAPTCHA bypassing
- AI-powered scraping with plain prompts
- Structured JSON output and screenshot capture
Pros
- API integration using HTTP requests or SDKs available
- Success rates on moderately protected sites reach 99%
- Clear guides and an API Playground for real-time testing
Cons
- Complex credit-based pricing system
- Lacks features like scheduling or a centralized dashboard
Pricing
ScrapingBee uses a credit-based subscription model that starts from $49/month. A free trial is also available for new users.
The Differentiator
ScrapingBee’s main differentiator is its "no-maintenance" simplicity for developers.
5. Bright Data
Bright Data handles web data extraction through scraping tools, custom solutions, and dataset packages. Its proxy setup and unblocking tools handle CAPTCHAs and site blocks, reducing direct infrastructure work.
The platform claims to prioritize data analysis over backend maintenance. Key features include:
- Rotating IP addresses for geo-specific data retrieval
- No-code interface for simplified setup
- Compliance tracking dashboard for regulatory requirements
Pros
- Appropriate for regulated industries
- Wide range of features and integrations
Cons
- Higher cost than most competitors
- Can be unnecessarily complex for smaller operations
Pricing
Bright Data caters to enterprise budgets with usage-dependent or subscription-based plans. Given its feature depth and support infrastructure, the cost structure suits high-volume operations. Smaller projects may struggle to justify the expense.
Differentiator
Prioritizes robust compliance controls and dependable performance across high-volume tasks.
6. ScraperAPI
ScraperAPI makes it easier to get data from websites by handling the hard stuff for you – things like rotating proxies, CAPTCHAs, and JavaScript-heavy pages. You don’t need to set up anything complicated. Just plug into the API and start pulling data. It’s built for developers and small teams that want results without extra tech overhead. Here are ScraperAPI's features:
- Takes care of IP rotation, JavaScript, and CAPTCHAs, so your scrapes run with fewer errors
- Lets you pull data from different regions using a global IP network
Pros
- Simple to connect and use
- Good value for smaller projects or early testing
Cons
- Not ideal if you need advanced controls or large-scale scraping
Pricing
ScraperAPI charges a flat monthly rate, so costs are easy to plan for. You can also try it for free before signing up. It works well for solo developers or startups that need fast, reliable access to data without building everything from scratch.
Differentiator
Quick setup and dependable performance without a steep learning curve.
7. Zyte
Zyte offers an AI-powered scraping API that adapts on its own to dynamic and complex websites, and no custom code is required. Its system handles the hard parts in the background, helping speed up extraction, reduce errors, and scale across thousands of sites without a lot of hands-on work. It’s a solid option for teams that want to collect data at scale with minimal effort. Key features include:
- Manages proxies automatically, helping avoid blocks and IP bans
- Includes built-in data cleaning, so results are ready to use
- Supports cloud-based scraping with tools to schedule and monitor tasks
Pros
- Well-developed managed scraping tools
- Powerful automation and scheduling features
Cons
- Can feel a bit complex during initial setup
Pricing
Zyte’s pricing is tiered by product, with billing based on usage. This setup makes it easier to grow as your data needs expand. It’s best suited for enterprise teams that need a full-service pipeline without managing all the technical parts themselves.
Differentiator
Combines proxy handling, scraping logic, and data delivery into one streamlined system.
8. Octoparse
Octoparse is built for users who need to pull data from websites but don’t know how to code, and don’t want to learn. The platform uses a click-based setup, so building a scraper feels more like filling out a form than writing a script. It also handles technical stuff like proxies, CAPTCHA solving, and cloud automation, so you’re not stuck trying to figure all that out. The standout features here are:
- You can build scrapers just by clicking through steps. No coding and no syntax
- Comes with proxy support built in, so it helps you avoid getting blocked
- Tasks run in the cloud and follow whatever schedule you set
Pros
- Easy to use, even if you’ve never written code
- Automation works in the background, right from the cloud
Cons
- Doesn’t offer much flexibility if you’re dealing with tricky or custom scraping jobs
Pricing
Octoparse runs on a subscription model, and there's a free tier too, which is good for smaller jobs or just getting your feet wet. It’s best for business users who want reliable data, but don’t have a dev team on standby.
Differentiator
A scraping tool that skips the code and gives you a full visual setup instead.
9. WebHarvy
WebHarvy is a desktop scraper, plain and simple. You open a site, click on what you want, and it figures out the rest. No scripts and no code. You can pull text, images, emails, and whatever’s on the page. It even handles stuff like pagination or pages that load as you scroll. Below are the top features:
- It picks up on repeating patterns, so you don’t have to mark every single thing
- You get a real-time preview while you work, which is helpful before running anything
Pros
- Super beginner-friendly
- One-time payment – buy it once, and that’s it
Cons
- It’s desktop-only. No cloud features or remote control
Pricing
As for pricing, there’s no subscription here. You pay once, install it on your machine, and you're good. It’s a nice pick for solo users or teams that just want to scrape locally and skip anything cloud-based.
Differentiator
It’s not trying to be fancy. It is just a straightforward, offline tool that works without all the extras.
10. Mozenda
Mozenda is built for teams that don’t want to mess with code or infrastructure. You point, click, and the tool does the rest for you. It’s a fully managed data-as-a-service provider, so whether you need data once or regularly, they’ll set it up, run it, and deliver it to you cleaned and ready. No need to worry about what’s happening in the background, as it is all taken care of. The best features are listed below.
- You can create scraping tasks step by step and schedule them to run automatically
- Everything runs in the cloud. There is nothing to install or maintain on your side.
- You get dedicated support, so if something breaks, someone’s there to fix it
Pros
- Fully managed setup
- Strong focus on data quality
Cons
- Not much room for technical customization
Pricing
Pricing isn’t listed upfront. Mozenda gives you a custom quote based on what you need. It’s best for teams that want reliable data without having to build or maintain scrapers. If you’re looking to outsource the entire scraping process, this platform covers it all.
Differentiator
It’s a hands-off solution with real people behind it, support that feels more like a service than just software.
Top web scraping services compared
Provider
Type
No-code support
JS rendering
Free tier
Best for
Scrapfly
Developer API
No
Yes
Yes
Flexible, granular control
Apify
No-code + DevTool
Yes
Yes
Yes
Hybrid workflows
ScrapingBee
Developer API
Yes
Yes
No
Devs with small-to-mid-sized data projects
Bright Data
Managed/API
Yes
Yes
No
Regulated industries
ScraperAPI
Lightweight API
No
Yes
Yes
Quick-start scraping
Zyte
Managed/API
Limited
Yes
Limited
Enterprise pipelines
Octoparse
No-code tool
Yes
Partial
Yes
Non-technical business users
WebHarvy
Desktop tool
Yes
No
No
Local, one-time scraping tasks
Mozenda
Managed service
Limited
Yes
No
Research and full-service delivery
Common challenges in web scraping
Scraping the web can seem easy, until it’s not. Once you start doing it at scale or across modern websites, the issues pile up fast. Here are a few that challenge people all the time:
Pages that load after they load
You grab a site’s HTML, only to realize the data isn’t even there yet. Lots of modern sites load content with JavaScript after the page appears. If your scraper doesn’t wait or can’t process scripts, you have a problem. This is where tools that act like a user, such as headless browsers, come in.
CAPTCHAs and blocks
Sites are built to stop bots. You’ll hit CAPTCHAs, get flagged, or just see blank pages. If you’re not rotating sessions, switching user agents, or spoofing fingerprints, you’ll get blocked fast. Most basic scrapers don’t stand a chance.
Too many requests, not enough IPs
If one IP has hundreds of requests, that’s a red flag for any site. Before long, your IP gets throttled or outright banned. To avoid that, pros use rotating proxies, residential, mobile, and ISP.
Messy data
Let’s say you get through all that and still end up with data that’s messy. That is, duplicates, broken formats, or irrelevant data. You’ll need to clean it before it’s useful, and sometimes that’s the hardest part.
Legal gray areas
Scraping isn’t always clear-cut legally. Some sites forbid it in their terms, and others are subject to regional data laws. If you don’t know where the line is, you might cross it without realizing it, and that can come back to bite you.
Post-scraping: Data handling and integration
So, you’ve got the data. Now what? It’s not just about collecting it. The real value kicks in after. What you do next determines whether that data’s actually usable or just a pile of text.
Step 1: Clean it
Most scraped data looks rough. You’ll probably see duplicate rows, inconsistent formats, and maybe missing values. It needs cleaning, reformatting, trimming, and normalizing because you want it in shape before sending it anywhere.
Step 2: Send it somewhere
You’re not going to keep it in a spreadsheet forever. Ideally, your scraping tool sends it somewhere useful, via API, into a cloud bucket, maybe even through a webhook. That delivery piece is often overlooked, but it is super important.
Step 3: Connect it to something
Once it’s cleaned and delivered, it should plug into the tools you already use. It could be a CRM, a dashboard, or an internal system. If it can’t integrate seamlessly, you’ll be stuck doing manual work, which defeats the point.
Conclusion
The best web scraping service in 2026 depends entirely on your team’s technical resources, scale requirements, and data strategy. From developer-first APIs to full-service managed platforms, the market offers a solution for virtually every use case.
Decodo’s a good pick if you want something fast and don’t want to deal with setting up proxies yourself. It’s already handled. But if you’re more into drag-and-drop tools or just don’t have a dev team backing you, Apify or Octoparse might be the easier route. In the end, it depends on how technical your setup is and how much you want to customize things down the line.
Test Web Scraping API for free
Collect quality data to make informed decisions faster with a 7-day free trial and 1K requests.
About the author

Lukas Mikelionis
Senior Account Manager
Lukas is a seasoned enterprise sales professional with extensive experience in the SaaS industry. Throughout his career, he has built strong relationships with Fortune 500 technology companies, developing a deep understanding of complex enterprise needs and strategic account management.
Connect with Lukas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.