Lukas Mikelionis
Senior Account Manager

Lukas is a seasoned enterprise sales professional with extensive experience in the SaaS industry. Throughout his career, he has built strong relationships with Fortune 500 technology companies, developing a deep understanding of complex enterprise needs and strategic account management.
Lukas brings valuable insights to Decodo from his work with industry-leading organizations. His expertize in navigating large-scale business relationships and implementing effective sales strategies has been instrumental in driving success for both clients and organizations.
Outside of the business world, Lukas is a seasoned traveler and sports enthusiast. His passion for exploring different cultures extends to his love of international cuisine.
Connect with Lukas via LinkedIn.

Top AI Data Collection Tools: Features, Reviews, and How to Choose the Best One
Getting good data at scale is crucial when you're running AI-powered business operations. Sure, AI tools can help with data collection, but they're definitely not all created equal. We'll walk through the best AI data collection platforms out there, break down what works and what doesn't, and help you figure out which one makes sense for what you're trying to do, whether you're putting together a machine learning pipeline or just trying to automate all that tedious data entry work.
Lukas Mikelionis
Last updated: Jul 21, 2025
7 min read

How to Scrape Data from Google Play Store
Ever wondered how some app developers always seem one step ahead on Google Play? The secret often comes down to data – lots of it. Instead of waiting around for monthly “Top Charts” updates, the smartest teams use Google Play scrapers to track real-time metrics and stay ahead of the competition. In this article, you’ll learn how to do exactly that, gaining the tools to effortlessly scrape everything from download totals to one-star rant emojis.
Lukas Mikelionis
Last updated: Jul 07, 2025
6 min read
What is a Headless Browser: A Comprehensive Guide 2026
Do you want to unlock the power of invisible browsing? A headless browser works like a regular browser but without the visual interface. It runs invisibly, automatically visiting websites to test pages or collect data. Faster and lighter than regular browsers, it's perfect for developers. In this guide, we’ll explain how headless browsers work, their uses, pros/cons, and top tools to choose from.
Lukas Mikelionis
Last updated: Jan 06, 2026
5 min read
Unlock Market Insights: How Web Scraping Transforms Modern Market Research
Traditional market research is the business equivalent of using a flip phone in 2026. Sure, it technically works, but why limit yourself when superior technology exists? In this guide, we'll show you how web scraping for market research gives you a competitive advantage that makes conventional research look outdated.
Lukas Mikelionis
Last updated: Sep 29, 2025
7 min read
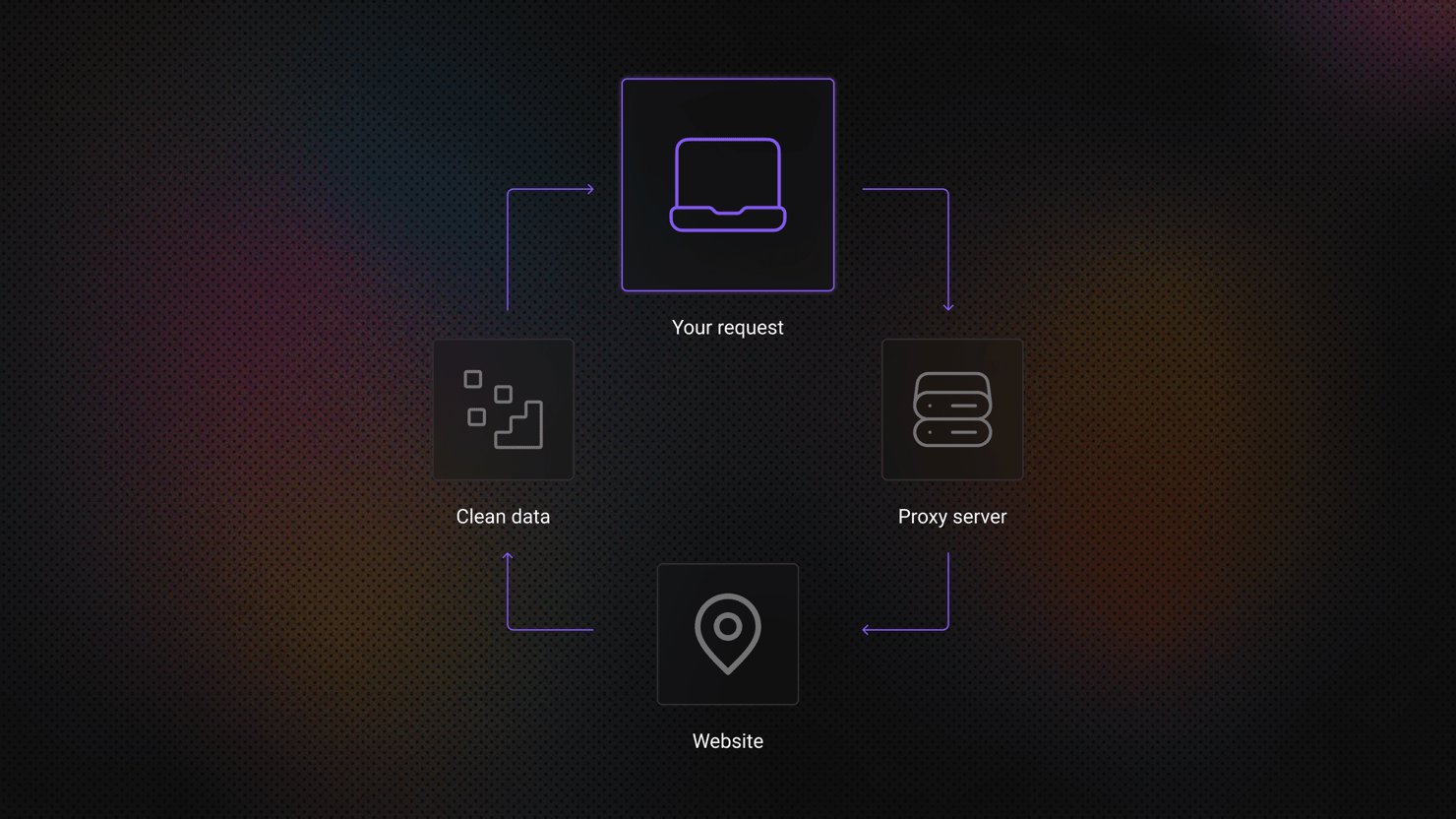
What Is an SSL/HTTPS Proxy: How It Works and When to Use It
An SSL proxy, often called an HTTPS proxy, is an intermediary server that forwards web requests between a user and a website through an encrypted HTTPS connection. Instead of connecting directly to the destination server, the client routes traffic through the proxy, which helps secure data transmission and manage outgoing requests.
Lukas Mikelionis
Last updated: Mar 18, 2026
4 min read

What Is a Proxy Hostname?
A proxy hostname is the domain you use to connect to a proxy service. Rather than entering a numeric IP address, the client connects through a readable host address that points to the provider’s proxy servers. Once configured in a browser, application, or script, this hostname ensures that outgoing requests pass through the proxy network before reaching the intended website.
Lukas Mikelionis
Last updated: Mar 27, 2026
3 min read
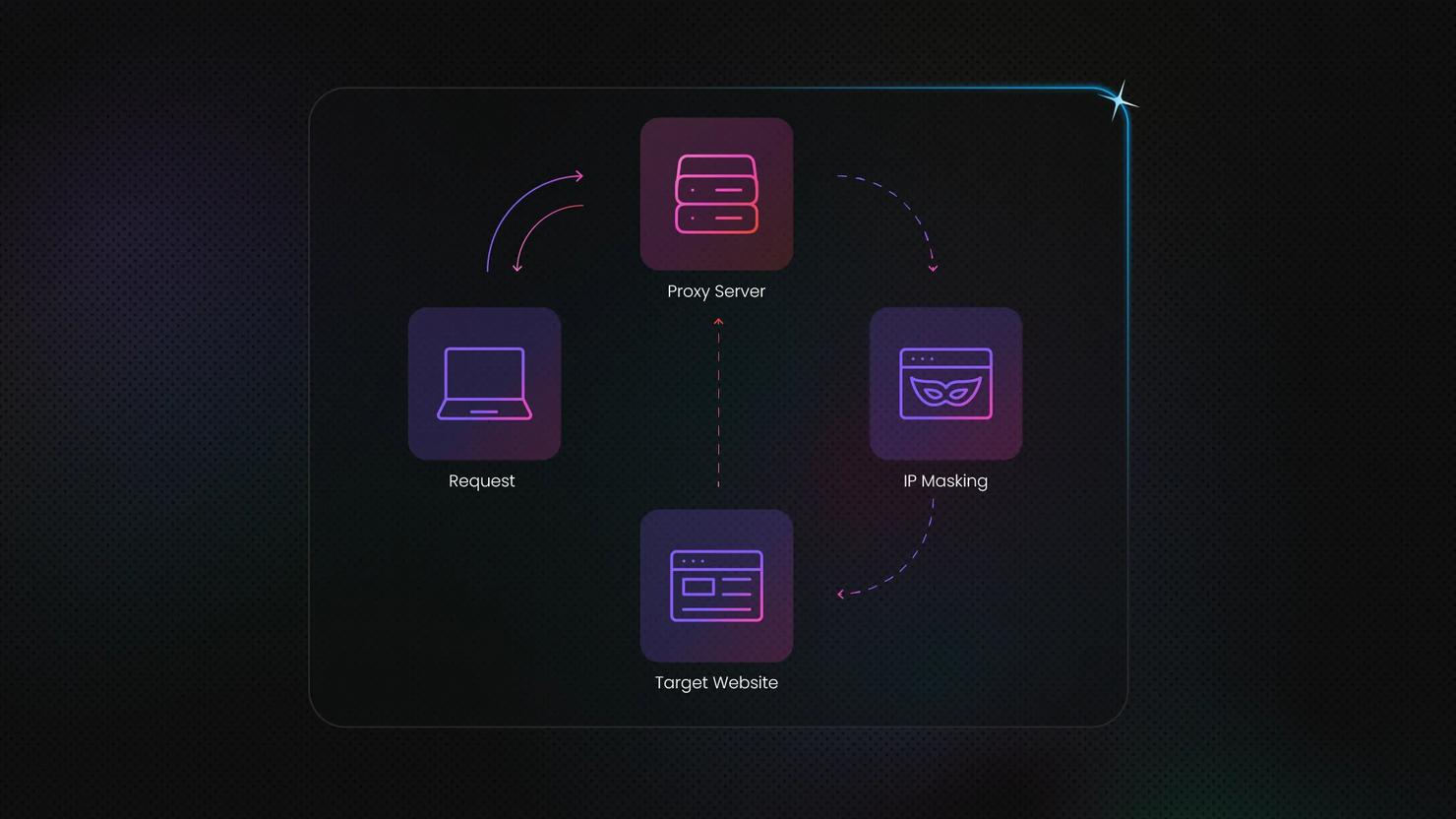
What Is a Dedicated Proxy? Key Types & Benefits
Ever feel like you're sharing a slow lane on the information highway? Standard proxies act as intermediaries, masking your IP address for privacy or accessing geo-specific web data. But when performance and a clean reputation matter most, dedicated proxies step in as a powerful solution offering exclusive access, speed, and stability tailored to your needs.
Lukas Mikelionis
Last updated: May 06, 2025
4 min read

How to Fix SSLError in Python Requests: Causes and Solutions
An SSL error means the TLS handshake failed: your application encountered an SSL certificate it couldn't verify, so the connection was rejected. This issue commonly shows up during web scraping or when integrating with external APIs. In this guide, we'll explain what this error means, its causes, and walk you through the right fix for each.
Lukas Mikelionis
Last updated: Apr 24, 2026
7 min read
Amazon Price Scraping with Google Sheets
Amazon’s massive product ecosystem makes it a goldmine for price tracking, competitive analysis, and market research. This guide covers methods for Amazon price scraping, from small-scale tracking to enterprise-grade solutions, plus how to import data into Google Sheets for real-time analysis. Whether you’re hunting deals or analyzing eCommerce trends, we’ve got you covered.
Lukas Mikelionis
Last updated: Mar 14, 2025
9 min read

The Best Python HTTP Clients for Web Scraping
Not all Python HTTP clients behave the same way on the wire. The one you choose affects how many requests you can run concurrently, how identifiable your traffic is to anti-bot systems, and how much code you need to manage. This guide breaks down six clients – urllib3, Requests, HTTPX, aiohttp, curl_cffi, and Niquests – covering where each fits and where it falls short.
Lukas Mikelionis
Last updated: Mar 26, 2026
12 min read
Wait for Page to Load in Beautiful Soup: Why It Fails and How to Fix It
Waiting for a page to load when using Beautiful Soup is a common challenge in web scraping, especially when your scraper returns empty results because the page renders content via JavaScript. This happens because Beautiful Soup is a parser, not a browser, so it can’t execute JavaScript or wait for dynamic content to load. To handle this, you can use browser automation tools like Selenium or Playwright, a lightweight option like requests-html, or a Web Scraping API for production-grade workflows.
Lukas Mikelionis
Last updated: Apr 30, 2026
9 min read
How to Use Wget With a Proxy: Configuration, Authentication, and Troubleshooting
Wget is a great tool for quickly downloading files or other web content, but you can also run into IP bans or geo-restrictions while using it. A simple way to bypass this limitation is to pair your setup with a proxy server. Instead of connecting directly to a website, wget then sends your requests through a proxy, which can help you stay under the radar and avoid getting blocked.
Lukas Mikelionis
Last updated: Mar 17, 2026
15 min read

How to Scrape Shopify Stores: Complete Developer Guide
Most Shopify stores have a built-in JSON endpoint for product data: prices, variants, inventory, images. Web scraping Shopify means requesting /products.json, paginating, and getting the catalog as JSON. But the endpoint is limited to 250 products per page, and some merchants disable it. This guide covers both: the JSON approach for stores that have it, and the fallback for stores that don't.
Lukas Mikelionis
Last updated: Apr 22, 2026
15 min read
Best Web Scraping Services: 2026 Comparison Guide
More and more industries now depend on data to make informed choices, which means having a fast, reliable way to collect structured web data is no longer optional. It’s a core need. In this overview, we’ll examine the top web scraping services of 2026, covering what they provide, their pricing models, the users they serve best, and their unique strengths. Whether you’re growing your data infrastructure or moving on from outdated tools, this guide is here to help you make a smart, well-matched choice.
Lukas Mikelionis
Last updated: Jan 06, 2026
5 min read
XPath Using Text: How to Select Elements by Text Value
HTML structure shifts constantly, but the visible text on a page tends to remain more stable. That stability is what makes text-based selectors useful in web scraping. This guide covers the core functions you need to work with text in XPath: text(), contains(), starts-with(), normalize-space(), and translate(), including where each one breaks and how to combine them to build selectors that survive page updates.
Lukas Mikelionis
Last updated: May 15, 2026
10 min read

Using Cursor AI To Build a Web Scraper: From Setup to Production With Decodo
Cursor AI is a code-aware IDE that generates, debugs, and refines scraper code through natural language, advancing AI-assisted scraping from concept to production. Building scrapers by hand means dealing with selector breakage, anti-bot walls, and proxy rotation logic that compounds every time a target site changes. This article covers setup, Cursor rules, scraper types, Decodo MCP integration, and project maintenance.
Lukas Mikelionis
Last updated: May 25, 2026
7 min read

Apache Nutch Tutorial: Install, Crawl, Index, and Automate
Scraping a page is simple. Crawling an entire website repeatedly, at scale, while also producing structured data that you can query, can be complex. Most scraping tools aren't designed for it, and that's what Apache Nutch is developed for. Nutch is an open source web crawler with built-in robots.txt compliance and native Apache Solr integration. By the end of this guide, you'll have a scoped crawl pipeline running and your data indexed into Solr.
Lukas Mikelionis
Last updated: Apr 24, 2026
15 min read
How to Buy Instagram Accounts Safely
Social media has turned the internet into a marketplace for digital assets. As buying fake followers faded out, demand shifted toward purchasing Instagram accounts with real audiences. In recent years, this market has grown rapidly. Buying an established account can give brands and marketers a head start, providing instant reach on one of today’s most powerful advertising platforms.
Lukas Mikelionis
Last updated: Mar 12, 2024
7 min read

Unblock Instagram With a Proxy
Instagram is everywhere – fueling opinions, creativity, and even income. With over 2 billion users worldwide, its influence is undeniable. But the platform isn’t always accessible: accounts can be blocked, features restricted, or the app unavailable in certain regions due to geo-restrictions. If Instagram suddenly stops working for you, there are ways to get around these limitations. Keep reading to learn how.
Lukas Mikelionis
Last updated: May 21, 2021
2 min read

Error 1005: What It Means and How to Fix It
You're trying to load a website, and instead of the page, you get a blank screen telling you access is denied. No explanation, no obvious reason. That's Error 1005, a Cloudflare security response that blocks your entire network rather than just your IP. This guide breaks down what triggers it, how to diagnose the cause, and what actually works to fix it.
Lukas Mikelionis
Last updated: Mar 16, 2026
6 min read

How To Use a Proxy With HttpClient in C#: From Setup to Production
If your C# application sends many requests from the same IP, the target will block it – 403 errors, CAPTCHAs, or rate limits. This is common in web scraping, price monitoring, and data collection. A proxy server routes requests through a different IP, so the target doesn't see yours. This guide covers HttpClient proxy setup from basics to production: authentication, SSL handling, IP rotation, and IHttpClientFactory patterns on .NET 8+.
Lukas Mikelionis
Last updated: Mar 04, 2026
8 min read
nodriver Explained: How Undetected Chromedriver's Successor Actually Works
nodriver is a Python package for browser automation and web scraping built as the successor to undetected-chromedriver. It skips the usual WebDriver layer, talks to Chrome more directly than Selenium, and uses an async-first design. In this guide, you'll learn what nodriver is, how it works in Python, and where it fits for scraping JavaScript-heavy pages when basic browser automation starts showing its limits.
Lukas Mikelionis
Last updated: Apr 01, 2026
8 min read

How To Scrape Emails From a Website: Python Tutorial
Scraping emails from a website is essential for lead generation, partner research, and CRM enrichment. However, to reliably scrape emails from a website, you need to handle multiple formats, including mailto links, plain-text addresses, obfuscated strings, and JavaScript-rendered content. This guide shows how to safely build a Python email scraper and scale it into a multi-page crawling workflow.
Lukas Mikelionis
Last updated: Apr 20, 2026
14 min read
YouTube Error 403: What It Means and How to Fix It
Do you scrape YouTube using YouTube-dl and yt-dlp packages? Or do you prefer writing a custom YouTube video downloader script? Either way, you might get caught off guard by YouTube error 403 due to issues with tokens, headers, cookies, or IP reputation. Read this insight to understand how disciplined session handling, browser-grade request emulation, and smarter quota-aware YouTube Data API strategies can help you tackle and fix YouTube error 403.
Lukas Mikelionis
Last updated: Oct 16, 2025
4 min read
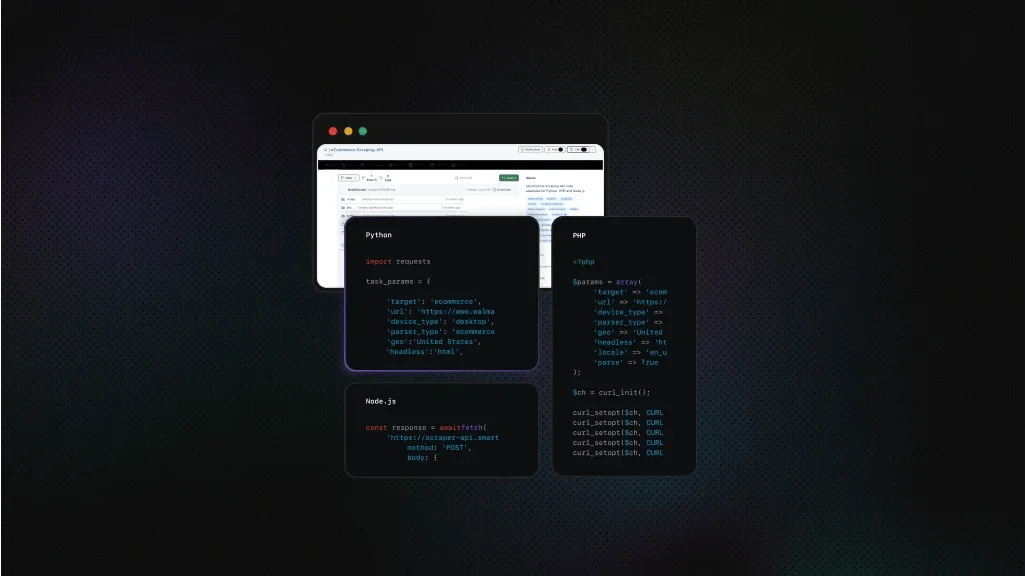
Error 1009 Guide: Solutions for Users and Web Scrapers
Have you ever tried visiting or scraping a website, only to be met with a cold signboard that reads "Error 1009, Access Denied"? Unlike transient HTTP error codes such as 4XX or 5XX, this error isn’t caused by origin instability or timeout. Instead, error 1009 is linked with Cloudflare’s security and access rules. This means that if you encounter error 1009, the site administrator has likely configured Cloudflare to block your access request due to location or policy restrictions. Read this article as we peel back the layers – what error 1009 is, why it appears, and how to effectively outwit it.
Lukas Mikelionis
Last updated: Sep 12, 2025
7 min read

Rust Web Scraping: Step-by-Step Tutorial With Code Examples
Python is usually the first choice for web scraping, but it can struggle in high-throughput scenarios where you’re fetching many pages concurrently or need stronger reliability. That’s where Rust comes in. In this tutorial, you’ll build a Hacker News scraper in Rust, covering setup, JSON output, and scaling, along with where Rust excels, where it adds friction, and when to offload to a managed scraping API.
Lukas Mikelionis
Last updated: Apr 15, 2026
10 min read

Web Scraping with Kotlin: A Complete Guide with Jsoup, OkHttp, and Coroutines
Kotlin developers don't need to reach for Python to scrape. The JVM ecosystem covers the full stack: Jsoup for HTML parsing, OkHttp for HTTP requests, and coroutines for concurrency. This guide is for JVM and Android developers, as well as Java teams evaluating a migration. By the end of this piece, you'll have a working scraper that handles pagination, runs concurrent requests, integrates proxies, and exports data to CSV.
Lukas Mikelionis
Last updated: Jun 16, 2026
8 min read

Price Scraping: How To Build a Scraper, Test It, and Scale With Confidence
Price data is important for monitoring competitors in eCommerce, enforcing MAP policies, and receiving deal alerts. Doing this manually isn't effective for scaling. A practical approach is price scraping, which helps automatically collect product pricing data from eCommerce websites. This guide will show you how to build a Python scraper using Playwright. It will help you gather real prices, deal with anti-bot measures, and create structured JSON data.
Lukas Mikelionis
Last updated: Jun 08, 2026
20 min read
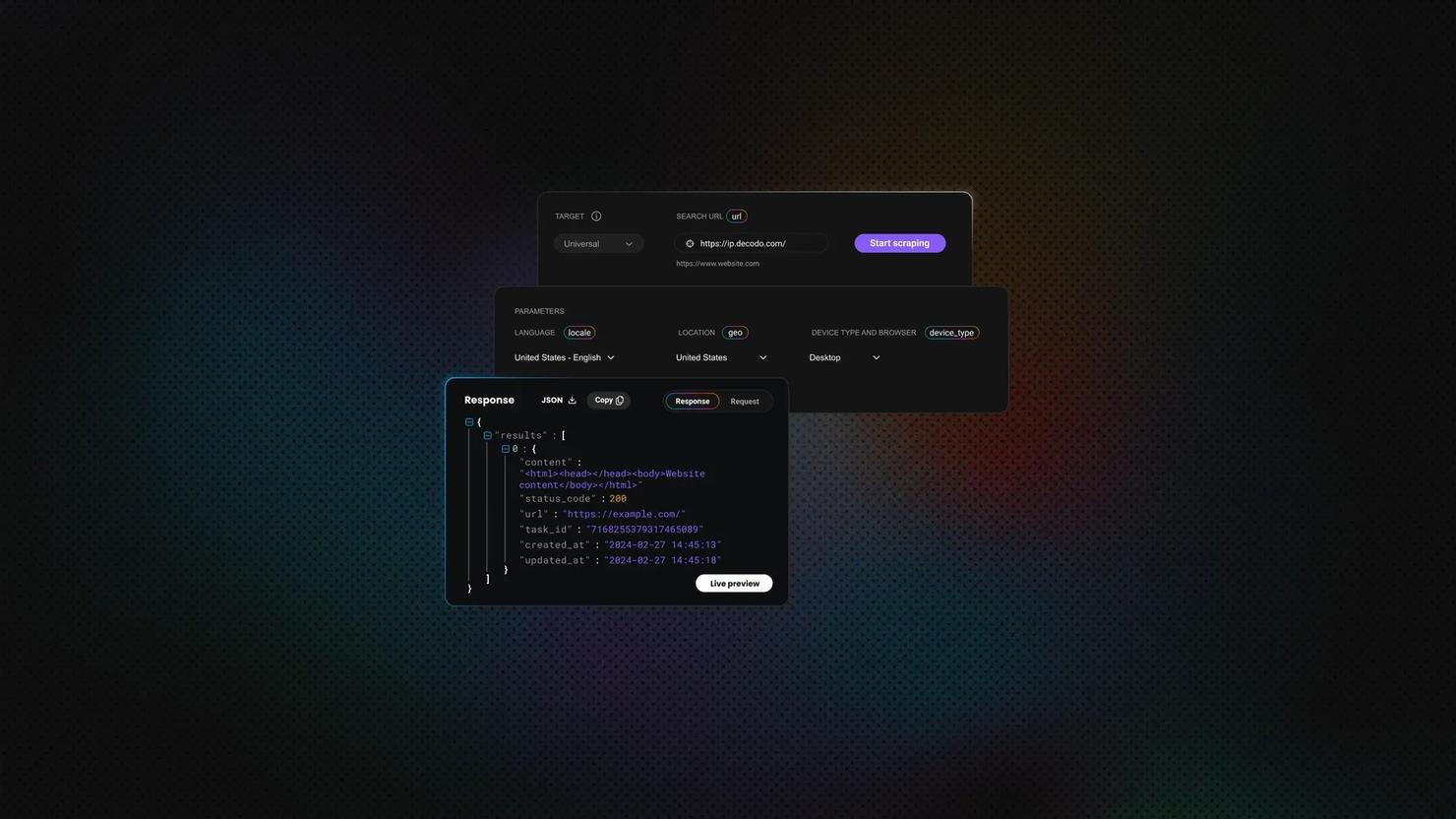
Web Scraping in Dify: A No-Code Guide
Dify is an open-source platform for building LLM apps and AI workflows visually. It gives teams a drag-and-drop canvas for chaining LLMs, tools, and APIs into complete AI workflows. Modern AI apps need fresh, structured web data, but most teams don't want to write and maintain Python scrapers. In this article, you'll learn how to build a no‑code Dify workflow and switch to a managed Web Scraping API when basic plugins aren't enough.
Lukas Mikelionis
Last updated: May 27, 2026
12 min read

C++ Web Scraping: A Practical Guide for Performance-Critical Projects
C++ web scraping is the process of sending HTTP requests from a C++ program, retrieving HTML or other structured responses, and parsing the data using libraries such as libcurl, CPR, libxml2, or pugixml. It's most useful in scraping workloads where CPU efficiency, memory control, predictable latency, or direct integration with an existing C++ system matter more than quick setup. That makes it a practical option for performance-critical pipelines, but a heavier one to build and maintain. The real question isn't whether C++ can scrape the web. It's whether that extra control is worth the extra engineering work.
Lukas Mikelionis
Last updated: Jun 04, 2026
14 min read
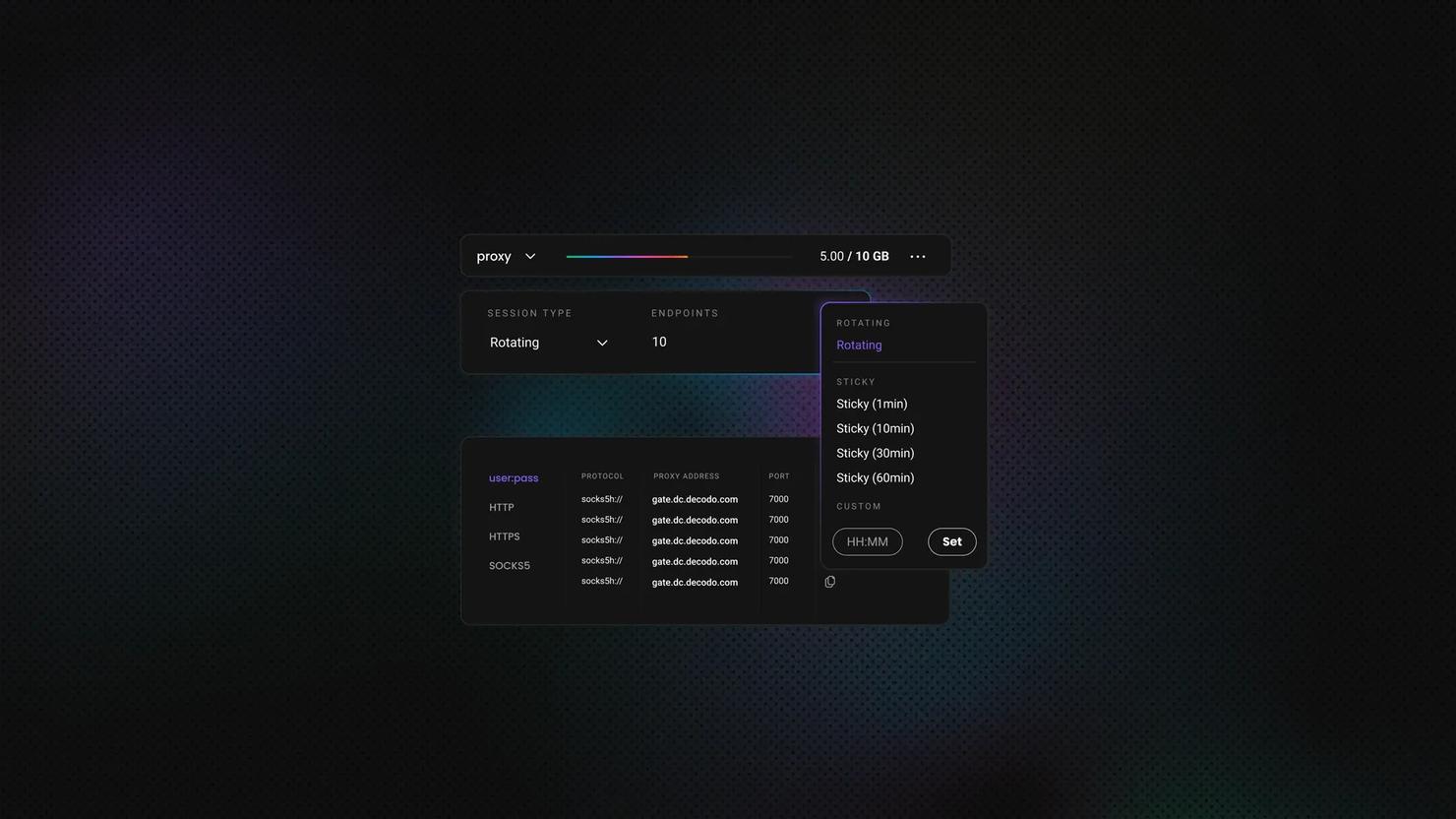
Puppeteer in Python With Pyppeteer: Setup, Scraping, and 2026 Alternatives
Pyppeteer is an unofficial Python port of Puppeteer, the Node.js library that drives headless Chromium through the DevTools Protocol. It brings the same async model to Python for clicking, filling forms, waiting, and scraping JavaScript-heavy sites. It works, but it's no longer the 2026 default. This guide covers using it and when to switch to Playwright or nodriver.
Lukas Mikelionis
Last updated: Jun 18, 2026
10 min read

Python Extract Text From HTML: A Step-by-Step Guide With Code Examples
Extracting text from HTML in Python is one of the most common tasks in web scraping, NLP pipelines, search indexing, and data preparation. The goal is to keep the visible content from a webpage while removing all the HTML markup, scripts, and styles that surround it. This guide walks you through the popular Python libraries for HTML text extraction and a full step-by-step workflow to go from raw HTML to clean, production-ready text.
Lukas Mikelionis
Last updated: May 28, 2026
14 min read

Web Scraping With Node Fetch: A Practical Guide
Web scraping with Node Fetch offers a lightweight way to collect data in Node.js. By fetching raw HTML or JSON responses and pairing them with parsers like Cheerio, developers can transform unstructured pages into structured datasets. This Node Fetch tutorial explains request handling, response parsing, data extraction, proxy integration, and when managed scraping APIs are necessary to effectively bypass advanced anti-bot protections.
Lukas Mikelionis
Last updated: Jun 11, 2026
17 min read