How to Scrape YouTube Search Results: Complete Guide
YouTube handles over 3B searches every month, making it the world’s second-largest search engine. Tapping into that web data uncovers trending topics, competitor strategies, and content gaps you can exploit. However, extracting that information requires navigating YouTube’s sophisticated CAPTCHAs and technical hurdles. In this guide, you’ll learn some proven approaches on how to scrape YouTube search results at scale and choose the right method for your specific needs.
Kipras Kalzanauskas
Last updated: Jun 25, 2025
9 min read
What data can you extract from YouTube search results?
Let’s explore the key data points you can extract from a YouTube search engine results page (SERP), which are invaluable for market research, SEO, and competitive analysis.
Here's a sample YouTube search engine results page for “what is mcp”, highlighting the key data points available for extraction:
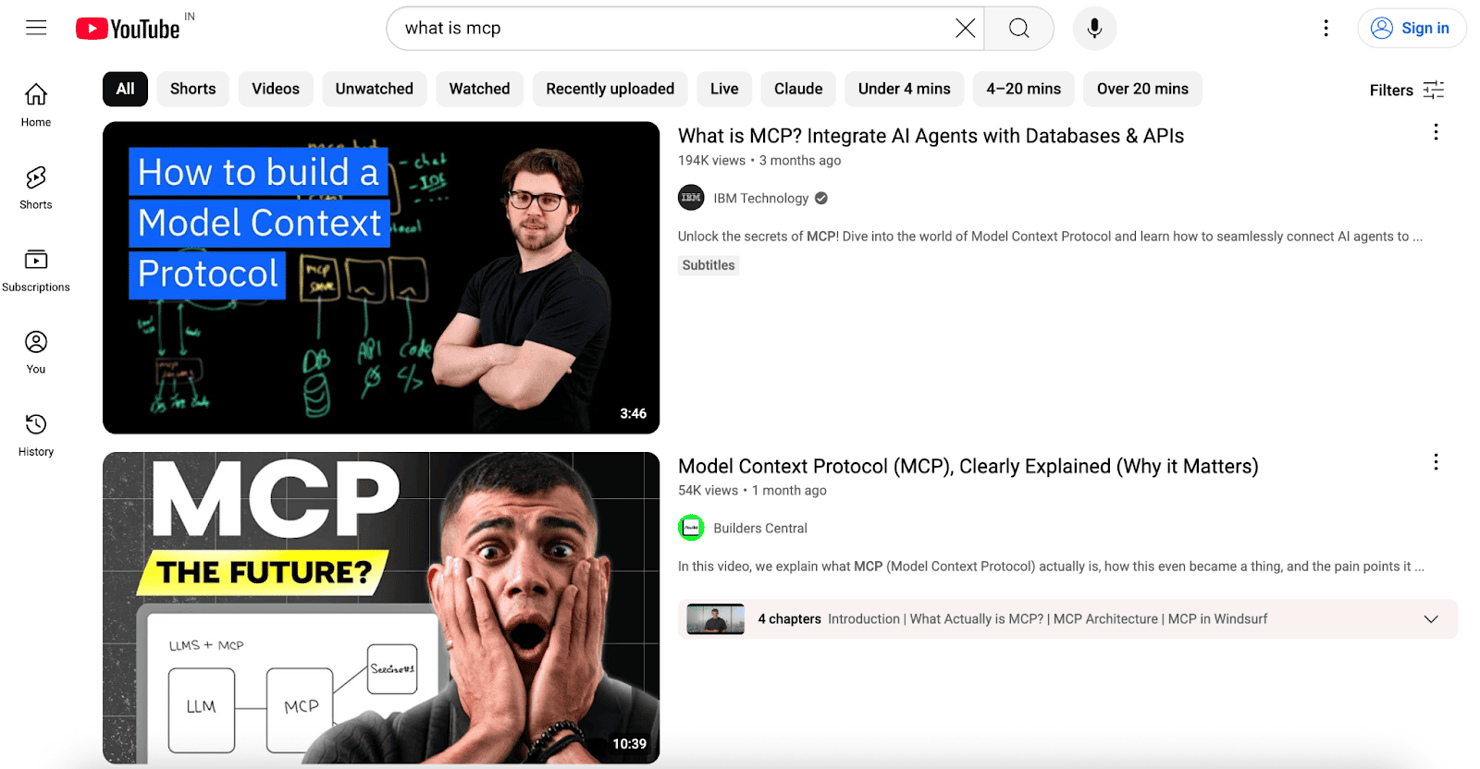
Here are the most valuable data points you can extract:
- Video title & URL. The primary text and link for the video. Essential for understanding topics and keywords.
- Channel name & URL. Identifies the publisher, which is key for competitor analysis and finding influencers.
- View count. A direct indicator of a video’s popularity and demand for the topic.
- Upload date. Reveals when the video was published, helping you distinguish between evergreen content and emerging trends.
- Video duration. The length of the video helps you understand the preferred content format within a niche.
- Description snippet. The short text preview under the title is often rich with keywords.
- Thumbnail URL. The link to the video’s preview image is useful for analyzing visual trends and branding.
By collecting this web data at scale, you can answer critical questions: which topics are trending right now? What keywords do top competitors use in their titles? What’s the average video length in my niche?
Methods for scraping YouTube search results
There are 3 main ways to approach YouTube data extraction. The best choice depends on your project’s scale, budget, and technical resources.
Method
Pros
Cons
Best for
YouTube Data API
Officially supported, reliable, and provides structured JSON data.
Extremely restrictive quotas – 100 searches/day on the free tier, doesn’t expose all public data.
Small‑scale projects, academic research, or tasks that don’t require frequent data collection.
Direct web scraping
Complete control over the data you collect, no API costs.
Complex to build and maintain – requires handling headless browsers, proxies, and frequent anti‑bot updates.
Technical users who need custom data fields and have time to manage the scraper infrastructure.
Fully managed service that handles proxies, CAPTCHAs, and JS rendering, highly reliable and scalable.
Subscription‑based costs, dependent on a third‑party service.
Businesses and developers who need reliable, scalable data without maintaining scrapers.
Step-by-step: scraping YouTube search results with Python
For a hands-on approach, building your scraper with Python is a powerful option. We’ll cover two libraries: yt-dlp for fast metadata extraction and Playwright for full browser automation that can handle tricky dynamic content.
If you're new to web scraping, check out our in-depth Python web scraping tutorial first.
Scraping with the yt-dlp library
yt-dlp is a command-line tool and Python library, forked from youtube-dl. It’s best known for downloading videos and can also get metadata as JSON. It’s fast, efficient, and avoids rendering a full browser.
Step #1 – install yt-dlp
Set up your environment by running the following commands in the terminal:
Step #2 – run the scraper script
Here’s the full Python script that searches YouTube videos by keyword and exports the metadata (title, views, likes, duration, etc.) to a structured JSON file.
The script is driven by 2 main configurations you can set at the top:
- SEARCH_QUERY – the search term to find relevant YouTube videos.
- SEARCH_RESULTS_LIMIT – the maximum number of search results to retrieve.
Now, let's deconstruct the yt-dlp options:
- "quiet": True tells yt-dlp to keep the terminal clean by not printing progress bars and status messages.
- "no_warnings": True tells the script to ignore minor, non-critical warnings.
- "dump_single_json": True tells yt-dlp not to download the video file but to gather all the metadata and package it into a single JSON object.
This script generates a youtube_search.json file with all the data you requested. Here's a peek at what the output looks like (we've shortened the description field for brevity).
The catch: why this method fails
While yt-dlp is great for quick jobs, it's not the most resilient approach for scraping at scale. Here's why:
- It's fragile. The tool can break whenever YouTube updates its internal code – your scraper will fail until a patch is released.
- You'll hit rate limits. After a burst of downloads, you'll start seeing HTTP 429 errors – unless you implement proper retry logic with delays.
- Your IP can get blocked. Scraping heavily from a single IP often triggers HTTP 403 "Video unavailable" errors. Using rotating proxies can help avoid this.
Scraping with internal API endpoint
YouTube’s web search sends a POST to https://www.youtube.com/youtubei/v1/search?prettyPrint=false. By replaying that request, you get structured JSON for every result: title, channel, views, duration, thumbnail, and more, without rendering any HTML.
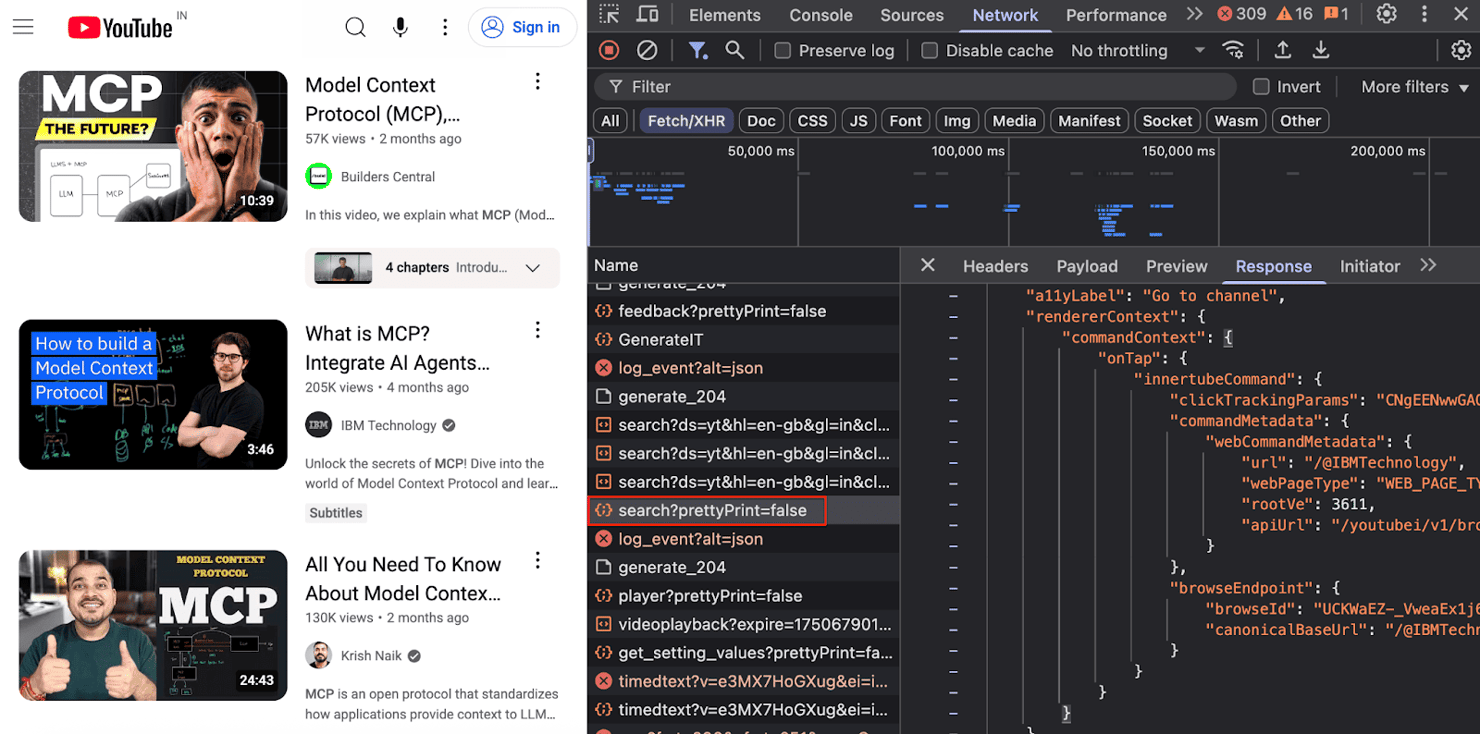
First, let's find the API request:
- Open DevTools – right-click anywhere on the page, select Inspect, and go to the Network tab.
- Filter XHR requests – click Fetch/XHR and refresh the page.
- Locate the search call – look for a request ending in search?prettyPrint=false.
- Inspect the payload – in the Payload panel, copy the clientVersion value.
The POST request requires a specific JSON payload. Here's the minimal structure:
Payload keys:
- clientName – must be “WEB”
- clientVersion – copy from DevTools (it changes often)
- query – your search term
- hl – interface language
- gl – two-letter country code
- userAgent – mirror your browser’s UA string
Step #1 – install requests if you haven’t already:
Step #2 – run the scraper script
To run the code, you simply pass your search term as the query parameter and, optionally, an integer max_videos to limit how many results you retrieve.
How it works
- YouTube returns a continuation token – the code loops until you've gathered enough videos or no more pages remain.
- A recursive search locates every VideoRenderer object, then extracts the videoId, title, views, duration, publishedTimeText, thumbnail, and a snippet of the description.
- Tracks seen IDs to avoid repeats across pages.
Running the script will produce a JSON file. Each video in the file will have a clean, structured format like this:
Scraping using Playwright
When the above-discussed approaches aren’t enough, you can simulate a real user by running a full browser. YouTube’s search results load dynamically with JavaScript, so you need a tool that can handle infinite scrolling and dynamic DOM updates.
Step #1 – Install Playwright
Step #2 – Scrape the search results
The logic here is to navigate to the search URL and then keep scrolling down the page. This repeated scrolling triggers the loading of more videos until we have all the results we need. For each video element (ytd-video-renderer), we'll extract the metadata by targeting specific CSS selectors.
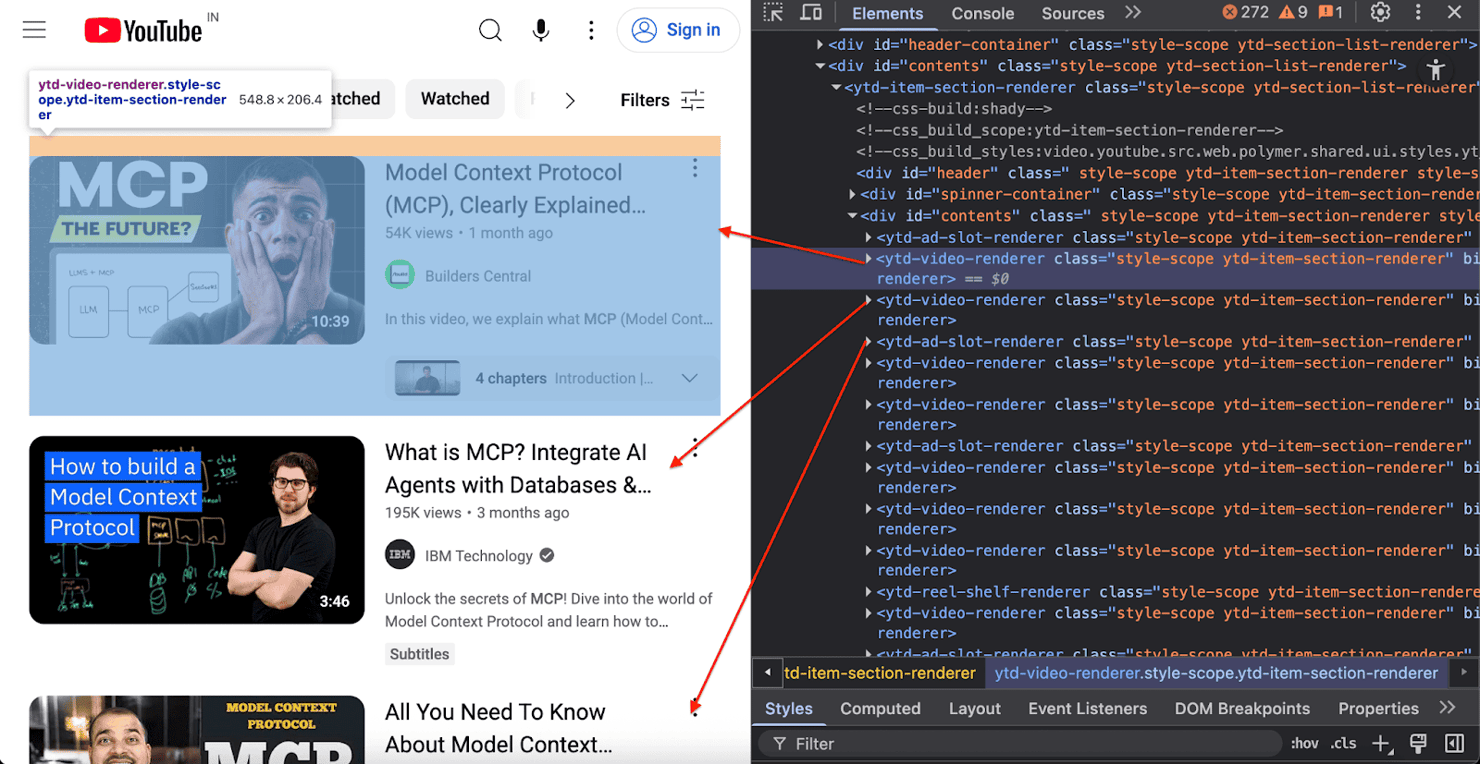
The following script automates the scraping process:
To configure the scraper, set the following constants at the top of your file:
- SEARCH_QUERY – the term to search for.
- OUTPUT_FILE – path to the JSON output file.
- MAX_RESULTS – number of videos to collect.
- HEADLESS, SCROLL_DELAY, MAX_IDLE_SCROLLS – control browser mode, scroll pacing, and when to stop.
For each video element, the script collects: title, url, views, upload time, duration (seconds), channel name & url, thumbnail, and verified badge.
When you run the script, you'll get a YT_search_results.json file similar to this example:
Handling challenges and anti-bot measures
No matter how robust your DIY scraper is, you’ll eventually hit YouTube’s anti-bot defenses. These include:
- IP rate limiting and bans. Making too many requests from one IP quickly triggers blocks, HTTP(S) errors, or CAPTCHAs.
- CAPTCHAs. Once you're flagged as a bot, you'll face Google's reCAPTCHA, which is notoriously difficult for automated tools to solve.
- Browser fingerprinting. YouTube can analyze subtle details about your browser environment, like installed fonts, plugins, and rendering nuances, to create a unique browser fingerprint. This helps it detect whether you're a real user or an automation tool like Playwright.
- Constant layout changes. YouTube is always updating its website. A simple change to a CSS class or HTML tag can break your scraper overnight, forcing you to constantly update your code and selectors just to keep up.
Managing these challenges requires a sophisticated infrastructure with rotating proxies, CAPTCHA-solving services, and ongoing maintenance. For any serious project, keeping a DIY scraper running becomes a full-time job.
Adding proxies to your DIY scraper
One of the most effective ways to handle IP rate limiting is to use rotating residential proxies. Here are the benefits of residential proxies for YouTube scraping:
- Avoid rate limits by distributing requests across multiple IPs
- Achieve geographic flexibility to access region-specific content
- Reduce blocking by lowering the chance of anti-bot detection
- Scale safely in large-scale scraping operations without IP bans
For robust, large-scale YouTube scraping, invest in high-quality YouTube proxies such as the Decodo proxy network.
To integrate Decodo’s residential proxies into your Python requests scraper code, follow these 2 simple steps:
Step #1 – configure proxies in your class initializer:
Step #2 – add the proxy to each request in your search method:
That’s it!
Similarly, if you’re using Playwright, add proxy settings when launching the browser:
Replace YOUR_USERNAME and YOUR_PASSWORD with your Decodo credentials.
The scalable solution – using Web Scraping API
When DIY methods become too brittle and time-consuming, a dedicated scraper API is the next logical step. Decodo offers a suite of tools designed to handle all the anti-bot complexity for you, so you can focus on getting data, not on scraper maintenance.
With Decodo, you don't need to manage headless browsers or proxy pools. You just make a simple API call, and we handle the rest.
- Large rotating proxy network to avoid IP bans.
- AI-powered anti-bot bypass to solve CAPTCHAs and defeat fingerprinting.
- Headless rendering for any JavaScript-heavy site.
- Enterprise-grade reliability with a pay-per-success model.
And the best part – every new user can claim a 7-day free trial, so you can test the automated YouTube scraping solution before committing.
Setup steps
To set up the Web Scraping API:
- Create an account or sign in to your Decodo dashboard.
- Select a plan under the Scraping APIs section – Core or Advanced.
- Start your trial – all plans come with a 7-day free trial.
- Select your tool (Web Core or Web Advanced) under the Scraping APIs section.
- Paste the YouTube video URL.
- Optionally, configure your API parameters (e.g., JS rendering, headers, geolocation). See the full list of web scraper API parameters.
- Hit Send Request and you’ll receive the clear HTML of the YouTube page in seconds.
Here’s what the Decodo dashboard looks like when using the Web Scraper API:
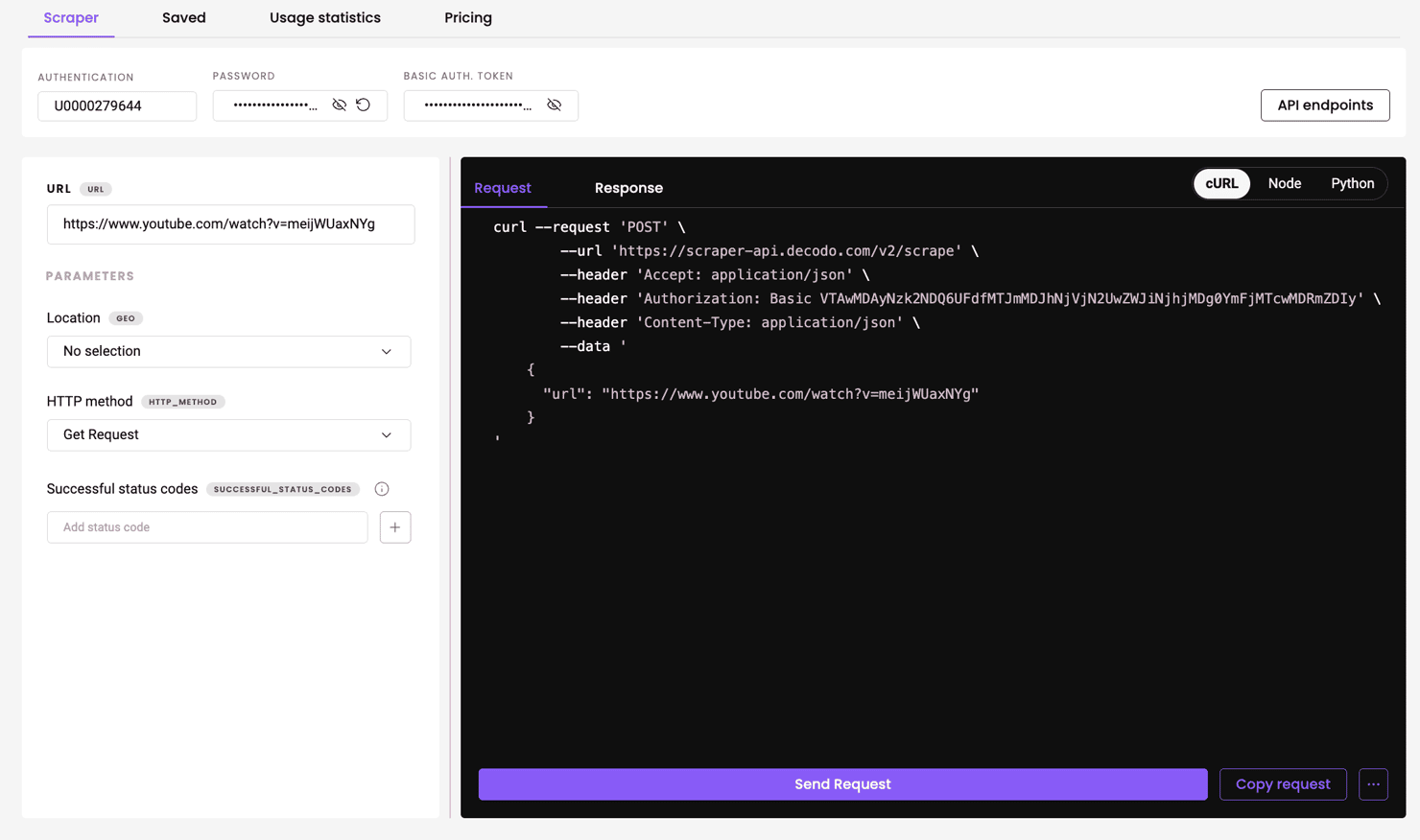
You can also grab a generated code sample in cURL, Node, or Python format. Here's an example:
Here’s how the code works:
- Define the scraping endpoint.
- Add the target YouTube URL to the payload.
- Set your headers with your API token.
- Send the request and save the HTML.
Don’t forget to replace DECODO_AUTH_TOKEN with your actual token from the Decodo dashboard.
Using dedicated YouTube scrapers
For an even better web scraping experience, Decodo offers dedicated YouTube scrapers that return structured JSON, no HTML parsing required.
YouTube metadata scraper
Get detailed video metadata by simply providing a video ID. In the dashboard, choose YouTube Metadata Scraper as the target, paste the video ID into the query field, and hit send.
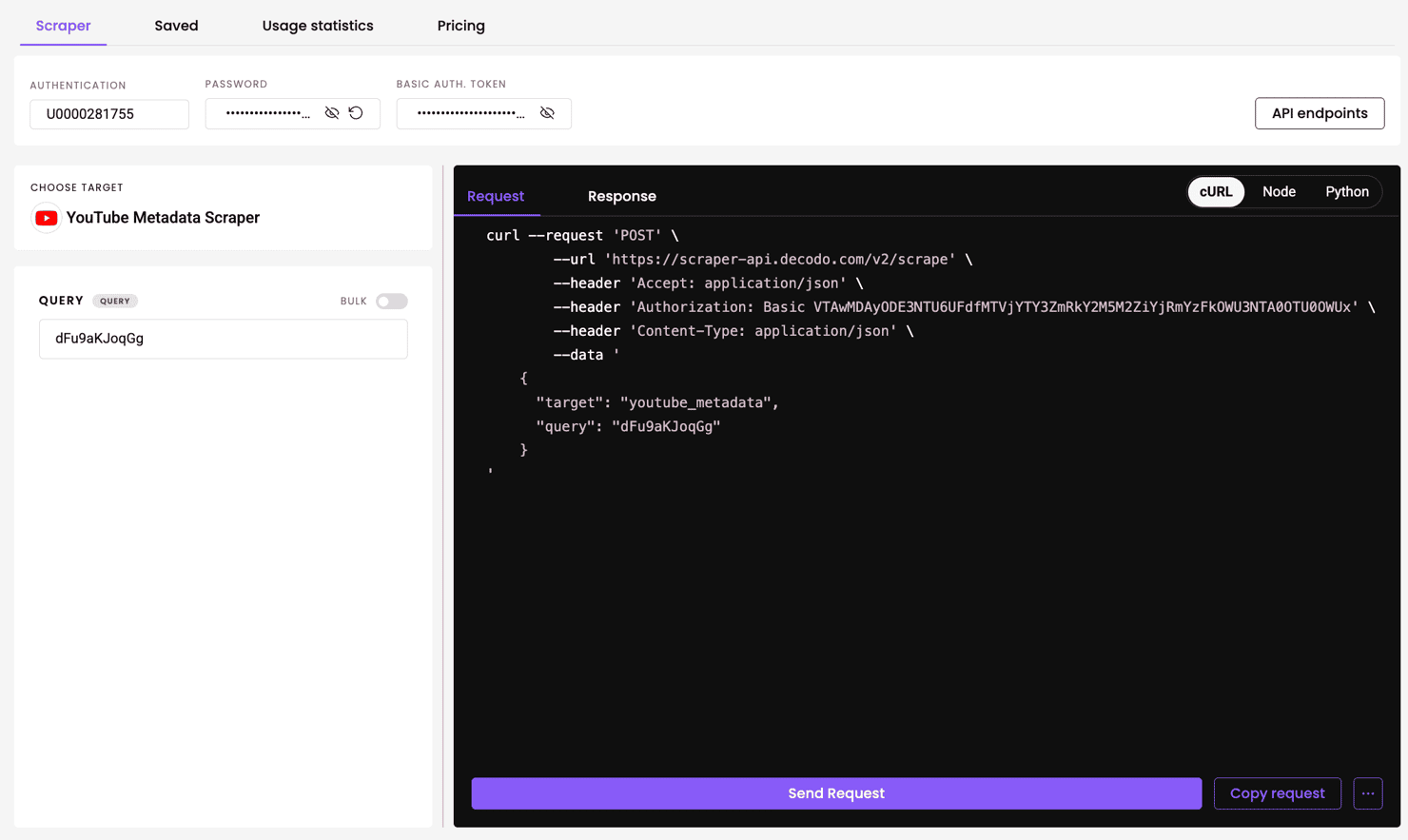
Here’s an example response (trimmed for brevity):
YouTube transcript scraper
Pull the full transcript for any video in any available language. Just set the target to YouTube Transcript scraper, provide the video ID as the query, and specify a language code.
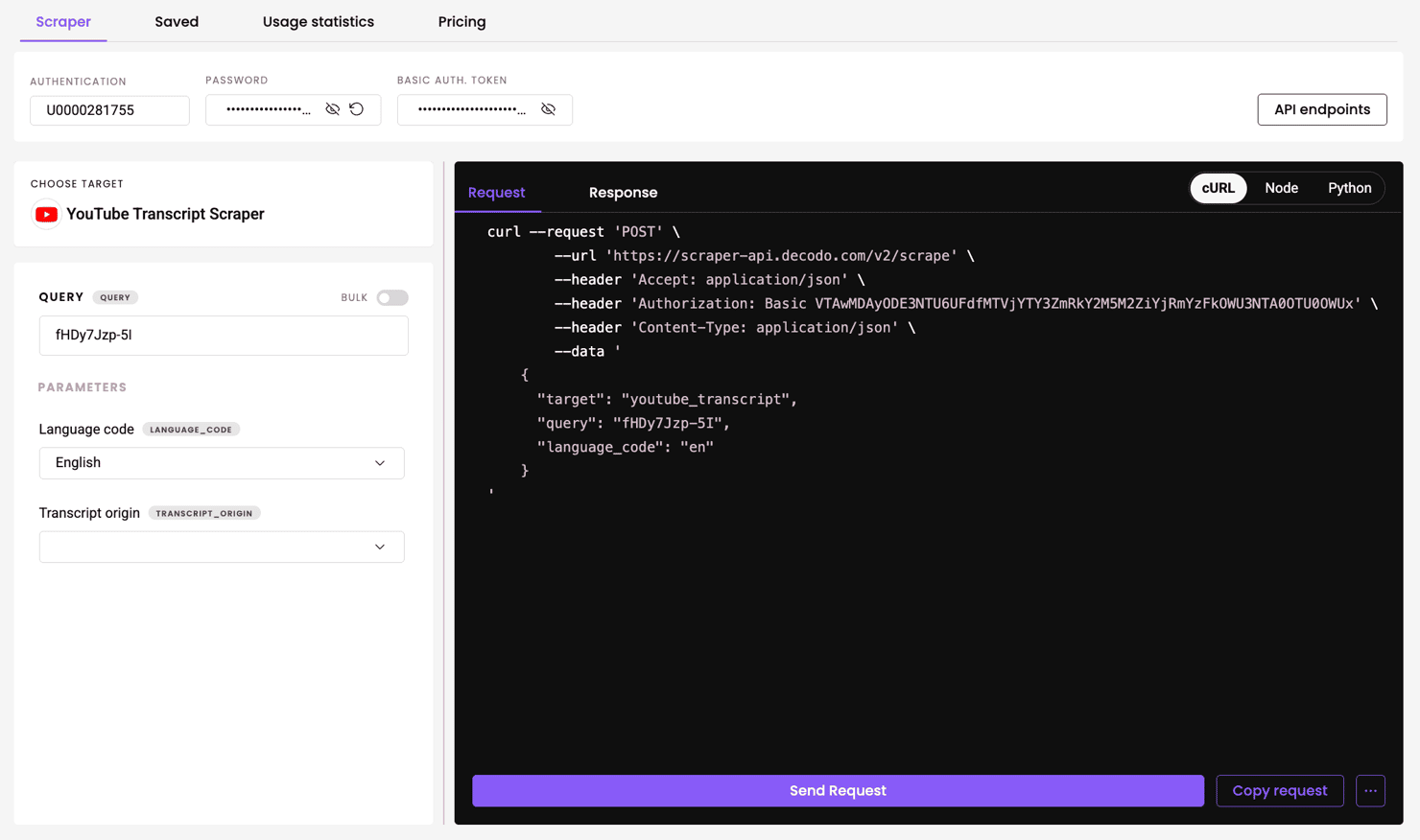
Here’s an example response (trimmed for brevity):
For advanced use cases and code samples, you can explore the Web Scraping API documentation.
Use cases and applications
Scraping YouTube search data unlocks valuable insights for content creators, marketers, analysts, and developers. Here are a few powerful ways you can use scraped YouTube data to get a competitive edge:
- AI model training. Build datasets for training language models, recommendation systems, or content analysis algorithms. Video titles, descriptions, and metadata provide rich training data for understanding content patterns, user preferences, and engagement prediction models.
- Content and SEO strategy. Analyze what makes top-ranking videos successful. By identifying the titles and keywords that get the most views, you can spot trending topics and optimize your content. For example, if most high-ranking videos for “what is MCP” include “for beginners”, you might adopt similar phrasing to improve visibility.
- Competitor analysis. Monitor competing channels by extracting titles, view counts, and channel names from search results. This helps reveal who’s dominating your niche – and where the content gaps are. A missing subtopic with low coverage could be your next high-opportunity video.
- Trend monitoring. Spot emerging trends before they blow up. By periodically scraping search results, you can watch for new keywords in video titles or see which topics are suddenly spiking in view counts.
- Market intelligence. Gauge audience sentiment on brands or products by collecting data on likes and comments. Analyzing the comment section of a popular review video can instantly tell you what consumers love or hate.
Bottom line
So, what’s the best way to scrape YouTube? The truth is, it depends on your project’s scale and complexity, as each method comes with its trade-offs. If you’re just getting started, you can begin with lightweight approaches. But as your needs grow, managing proxies, CAPTCHAs, and browser automation can become a burden. That’s where scalable solutions like Decodo’s Web Scraping API come in, allowing you to send a single request and receive data in seconds. With the right tools, you can reliably extract insights from YouTube to guide your strategy and gain a competitive edge.
Scrape YouTube in seconds
Collect data for AI training with a free 7-day trial and 1K requests.
About the author

Kipras Kalzanauskas
Senior Account Manager
Kipras is a strategic account expert with a strong background in sales, IT support, and data-driven solutions. Born and raised in Vilnius, he studied history at Vilnius University before spending time in the Lithuanian Military. For the past 3.5 years, he has been a key player at Decodo, working with Fortune 500 companies in eCommerce and Market Intelligence.
Connect with Kipras on LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.