How to Scrape YouTube Comments: A Complete Guide
Scraping YouTube comments is one of the most direct ways to tap into user sentiment, uncover insights for market research, and even build large datasets for machine learning models. In this blog, we’ll explore what YouTube comment scrapers are, the various methods to scrape comments (both official and unofficial), and how to choose the best approach for your needs.
Dominykas Niaura
Last updated: Sep 12, 2025
10 min read
What is a YouTube comment scraper?
A YouTube comment scraper is a tool or script that automates the extraction of comments from YouTube videos. In other words, instead of manually copying comments, a scraper program can round up and extract all user comments from any given YouTube video’s comments section.
These tools can also capture information such as each comment’s text, the author’s username, the posting date/time, number of likes, and even whether the comment has replies or was liked by the creator.
In essence, a YouTube comment scraper aims to capture all the discussions that have taken place in the comments section of a video you’re interested in. By scraping comments of several videos, you can create a dataset of your target audience talking about things that matter to you.
What are YouTube comments good for?
YouTube comments represent the voice of the customer straight from your target audience’s mouth (or keyboard). They can also offer immense value for creators, marketers, and researchers. Let's go over some of these benefits:
- Audience feedback. Comments give a bird’s-eye view of what viewers think about the video content. You can easily make out what they liked, disliked, or want more of. This helps creators and brands understand audience preferences and pain points.
- Sentiment analysis. The tone of the comments (positive, negative, neutral) can be analyzed at scale to gauge public opinion about a video, product, or topic. For instance, a larger number of negative comments might indicate an issue that needs addressing.
- Content ideas. Suggestions in comments usually tend to inspire great content when followed through, as they give the creators a priceless hint at what the viewers want to see.
- Trend and keyword tracking. By collecting comments across many videos in your niche, you can spot trending topics, slang, or keywords your audience resonates with. This information can then be used to update your SEO and content strategy to stay relevant.
Ways to scrape YouTube comments
There are several routes you can take to extract YouTube comments. You can write a custom script using Python, or rely on a whole range of APIs or automation tools.
YouTube proxies are also a powerful tool to have in your arsenal as they help ensure smoother scraping with fewer blocks, especially at scale.
Let's quickly go over some of the most popular methods:
1. YouTube Data API (official method)
Google provides the official YouTube Data API v3, which allows developers to retrieve comments and comment threads via HTTP requests. The API is great if you're working on a small project or testing an application; however, the API’s terms forbid using it explicitly for scraping or mass download of data.
Furthermore, this method requires an API key and is subject to strict quota limits and usage policies. By default, you get 10,000 units per day, with each comment list request costing 1 unit. This means you can only make a limited number of requests daily, and if you exceed the quota, you either have to request more quota or wait for the next day.
Nonetheless, for reasonable volumes, the Data API is a clean and ethical way to get comments, and it returns metadata like author channel IDs, like counts, and reply thread info. We’ll demonstrate using this API with Python in the next section.
2. Direct web scraping
Another approach is to scrape the YouTube website directly for comments. This can be done by using tools like Selenium or Playwright. The pros of direct scraping are that you bypass the official API’s quota limits and can retrieve all comments and including replies if you handle pagination properly.
It’s also free to use as there are no API keys needed or credit cards required. However, it's prone to break if YouTube changes its site structure or internal APIs. Also, YouTube may throttle or block your requests if you pull too much data too quickly.
YouTube’s anti-bot measures can detect rapid or repetitive requests from one IP, so to circumvent this, you’ll need to implement workarounds like rotating IP addresses or adding delays to avoid being flagged.
3. Using yt-dlp (YouTube-DL fork)
yt-dlp is a powerful Python library that is primarily used for downloading YouTube videos, but it also supports extracting video metadata, including comments. By setting the option getcomments=True, the library will fetch comments for any given YouTube video.
The advantage of yt-dlp is that it’s actively maintained to keep up with site changes, and it’s also very easy to use, as there are no API keys required and users don’t need to manually handle pagination or HTML parsing. Like any direct scraping method, it’s not immune to YouTube’s rate limiting or blocks. If you scrape too aggressively, YouTube might temporarily block your IP or pose CAPTCHA challenges.
4. No-code and third-party tools
If you prefer not to write code, there are automation tools and ready-made scrapers that can extract YouTube comments. They usually have a user-friendly interface and can integrate with other tools for analysis.
Note: Check out this simple n8n YouTube Comment Scraper and Analyzer workflow
The pro of these solutions is their ease of use. You can quickly get results with minimal technical effort as they often handle things like pagination or retries automatically.
However, many third-party services have usage limits or costs, and if they rely on the official API, they still face the API’s quota limits. Also, no-code tools may also be less flexible if you need custom logic, but for many business users, they are a convenient way to collect comments for analysis.
To help you picture things, here’s a quick comparison of the above methods:
Method
Difficulty
Speed
Rate Limits
Comments Quality
Cost
YouTube Data API
Low
Fast
High
High
Free tier + quota costs
Direct web Scraping
High
Slow
Moderate
Medium
Free
yt-dlp
Medium
Fast
Moderate
High
Free
No code tools
Low
Medium
Moderate
High
Free/Paid tiers
How to scrape YouTube comments with Python
Now, we’ll demonstrate how to programmatically fetch YouTube comments using Python. To build a YouTube comment scraper in Python, you’ll use the following tools and libraries:
- YouTube Data API. Provided by Google, it allows programmatic access to YouTube data.
- Python. Make sure you have Python 3.8+ installed on your system.
- Python libraries. Requests and json for handling HTTP requests and parsing responses.
- API key. A YouTube Data API key from the Google Cloud Console.
- A Decodo account. Create a new account on Decodo’s dashboard and choose a plan for residential proxies (free trial available).
Using Youtube Data API v3
The YouTube Data API is Google's official method for accessing YouTube data, including comments. It’s stable, well-documented, and returns clean JSON, so you don’t have to scrape HTML and worry about parsing.
The tradeoff with this method, however, is the daily quota, which can be frustrating if you’re looking to scrape hundreds of videos or build a large dataset. Still, if you want an ethical way to scrape YouTube comments, this is a great place to start.
Step 1: Getting your API key
To get started, you need to obtain an API key, so head over to Google Cloud Console, click on Go to my console and create a new project.
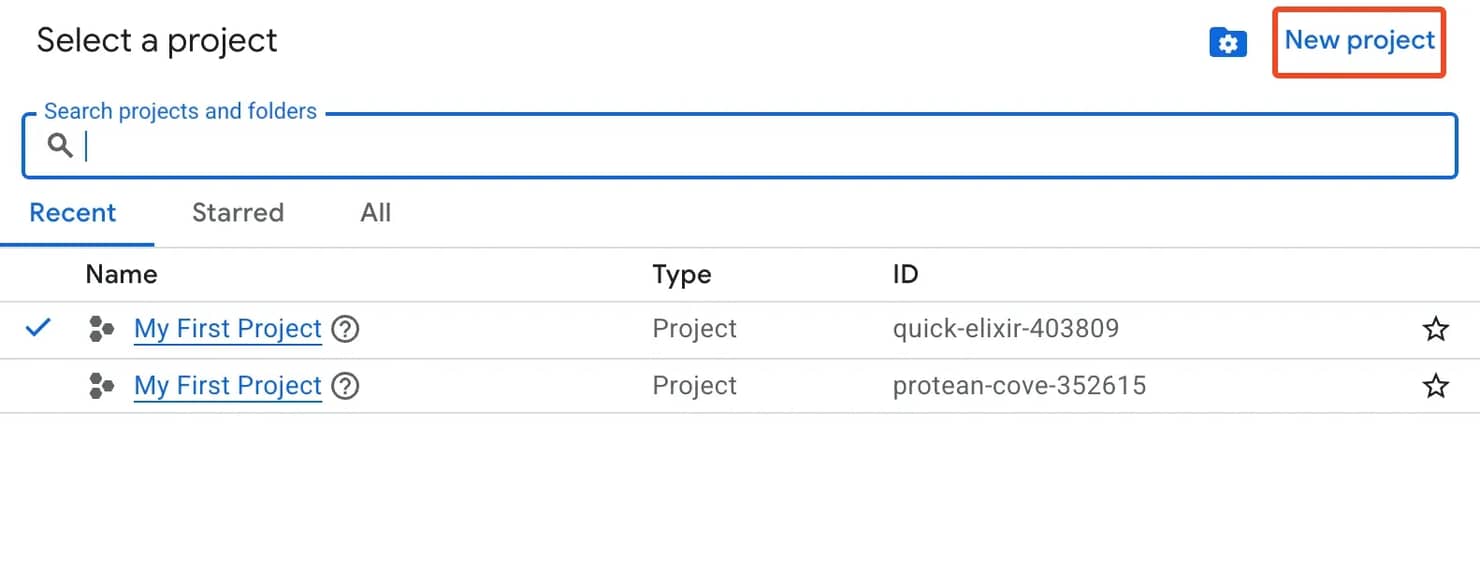
Once the project is created, open the navigation menu and head over to APIs & Services on the left panel.
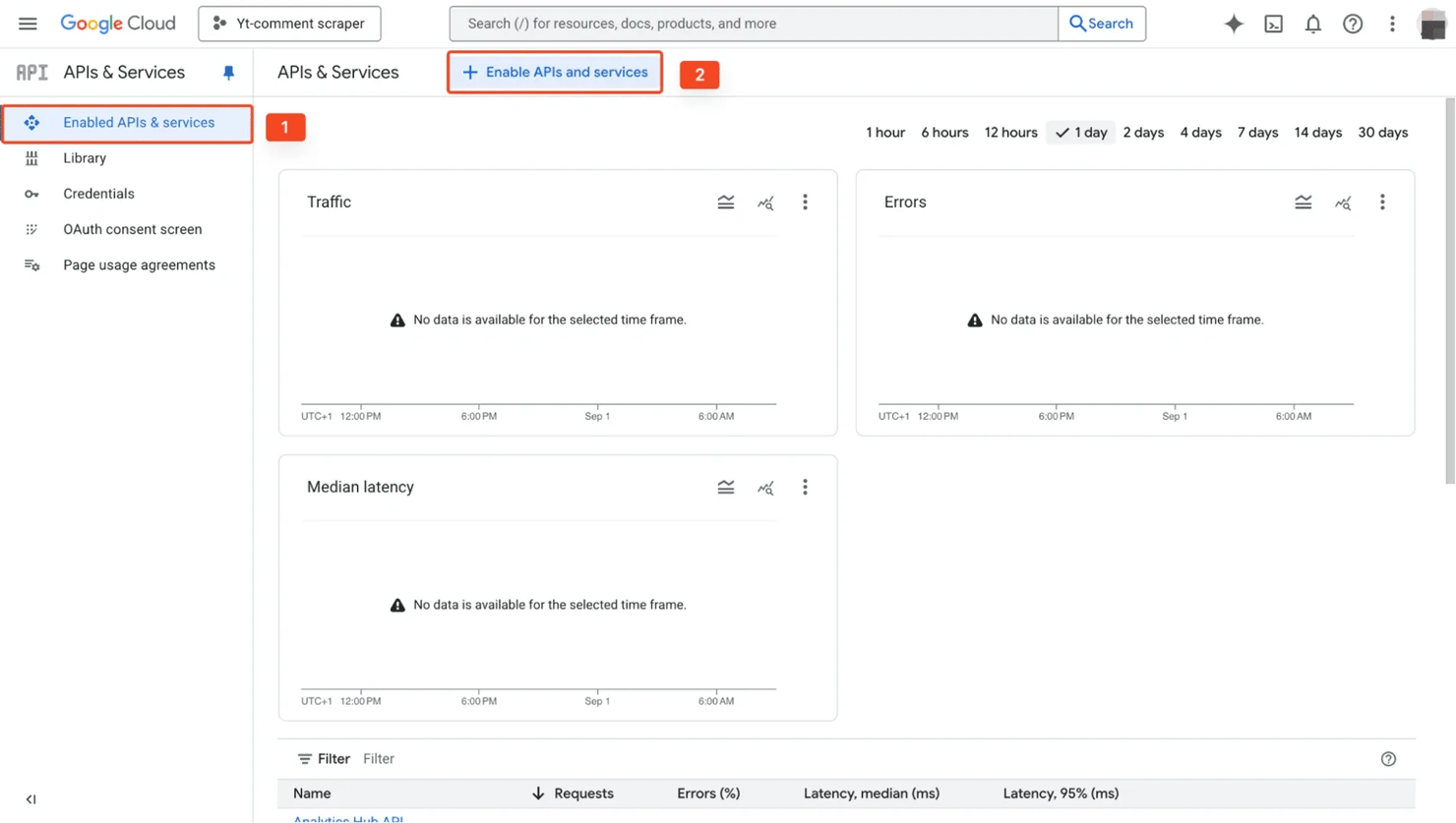
In the search bar, search for "YouTube Data API v3", open it and click Enable.
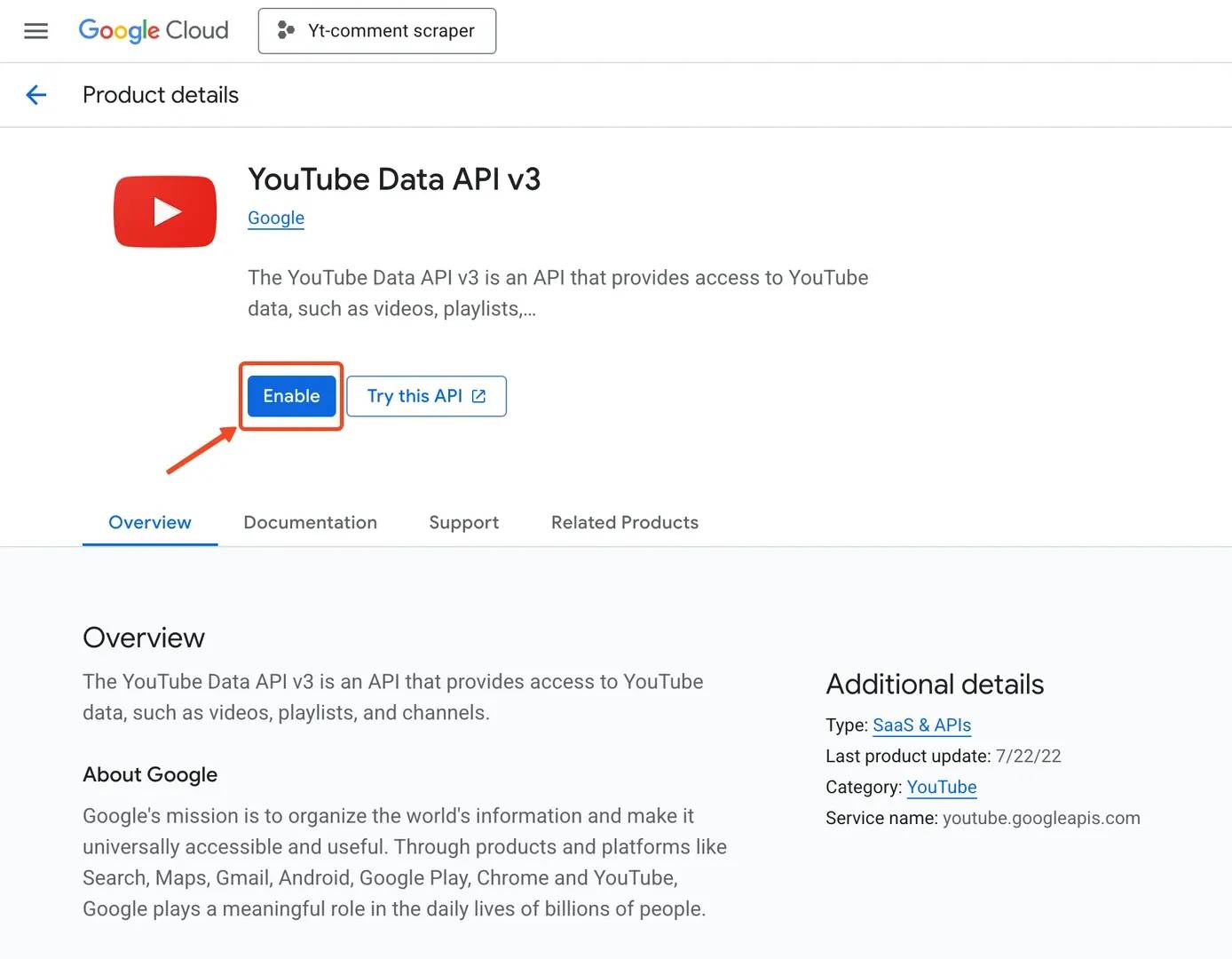
With the API enabled, go back to APIs & Services → Credentials, then select Create credentials → API key. Google will generate a new YouTube Data API key for you instantly.
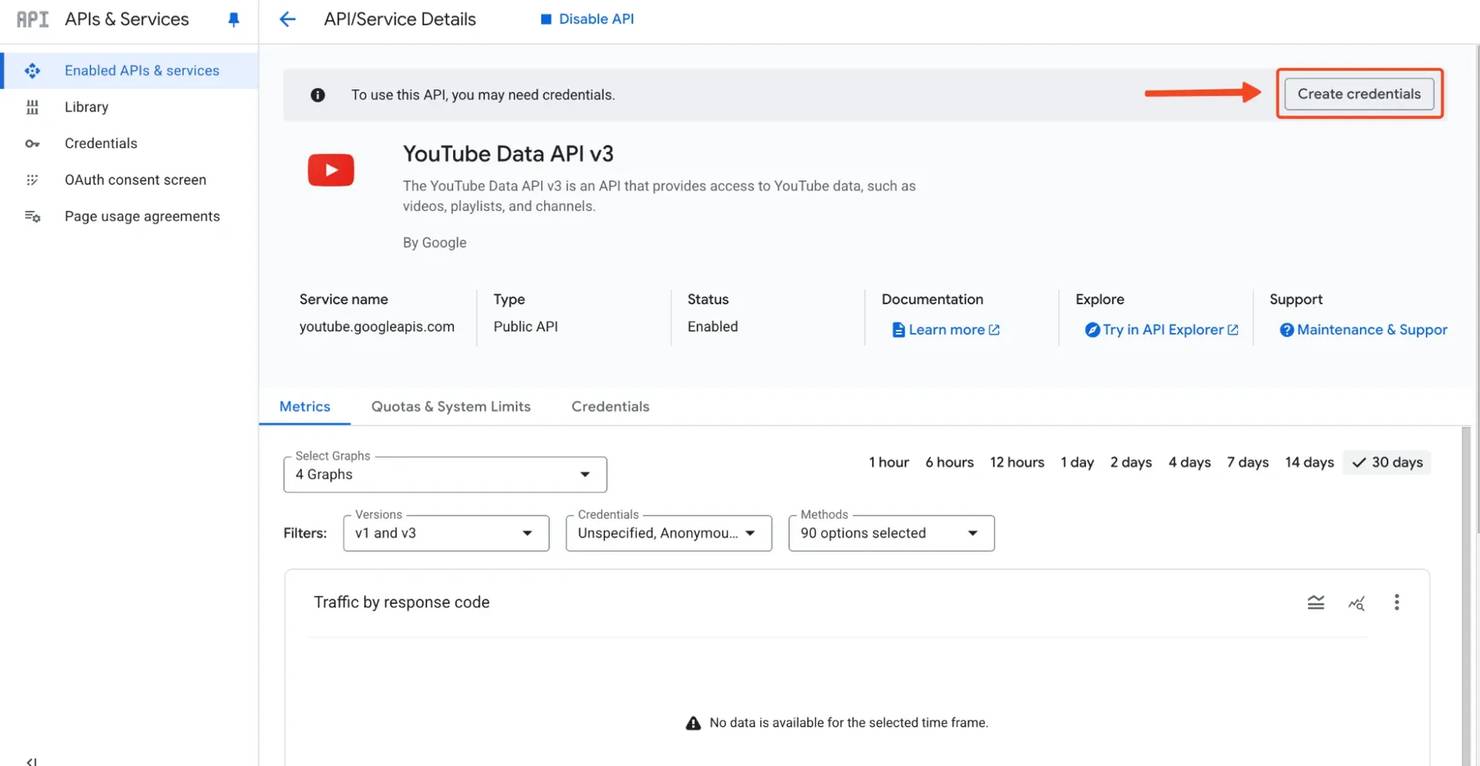
Copy this key and store it securely. You can optionally restrict it to specific domains or IP addresses for security purposes, but never share it publicly. Treat this API key like a password because anyone who has it can burn through your quota.
Step 2: Set up your project
For the Data API method, we’ll just use Python’s Requests library. You can install Requests with the following command:
Google also provides an official google-api-python-client, which is useful if you need OAuth authentication flows or more complex functionality. But, for the simple task of pulling comments, using Requests is more straightforward and gives you full control over the request structure.
At this point, your project folder is ready, and you have everything needed to start pulling data from the YouTube API.
Step 3: Fetch and save the raw API response
Now that the project is set up, we want to write a simple script that captures what the API returns. Start by importing the necessary libraries and defining constants.
The API takes in a videoId parameter as an argument, as it doesn’t automatically parse the full video URL. This is slightly tricky as some links use https://www.youtube.com/watch?v=..., while others use the short form https://youtu.be/...
To parse this URL, we have to first check if it is a short link and take the path part; otherwise, we look for the v= query parameter and return that value.
Now, the goal is to hit the commentThreads endpoint and capture exactly what Google returns. We do this by requesting a single page first, set maxResults to a small value (20) and write the raw payload to a JSON file. Run this script below:
Note: Remember to replace “YOUR_API_KEY” with the actual API key from your Google Cloud Console.
You should see something similar to the example below in your saved youtube_raw_response.json file. This is not the full object, but it’s just enough to show the shape of the JSON response:
As you can see from this response structure, the actual comment data is buried deep within multiple nested objects.
The comment text itself is located at items[0].snippet.topLevelComment.snippet.textDisplay, which is quite cumbersome to access repeatedly. This depth is normal for Google APIs, but it is awkward for analysis, so we would need to trim the response data.
Step 4: Make your scraper block-proof
Once you move beyond a couple of videos, a single IP won’t cut it. You’ll need to protect your scraper from being rate-limited or blocked, and one of the smartest ways is by integrating residential proxies into your requests.
Decodo is a premium proxy provider that offers global coverage with excellent reliability for YouTube scraping. Our residential proxies also behave like real user traffic, making it far less likely that Google will cut you off. Decodo also makes it easier to rotate proxies with its built-in rotating proxies feature.
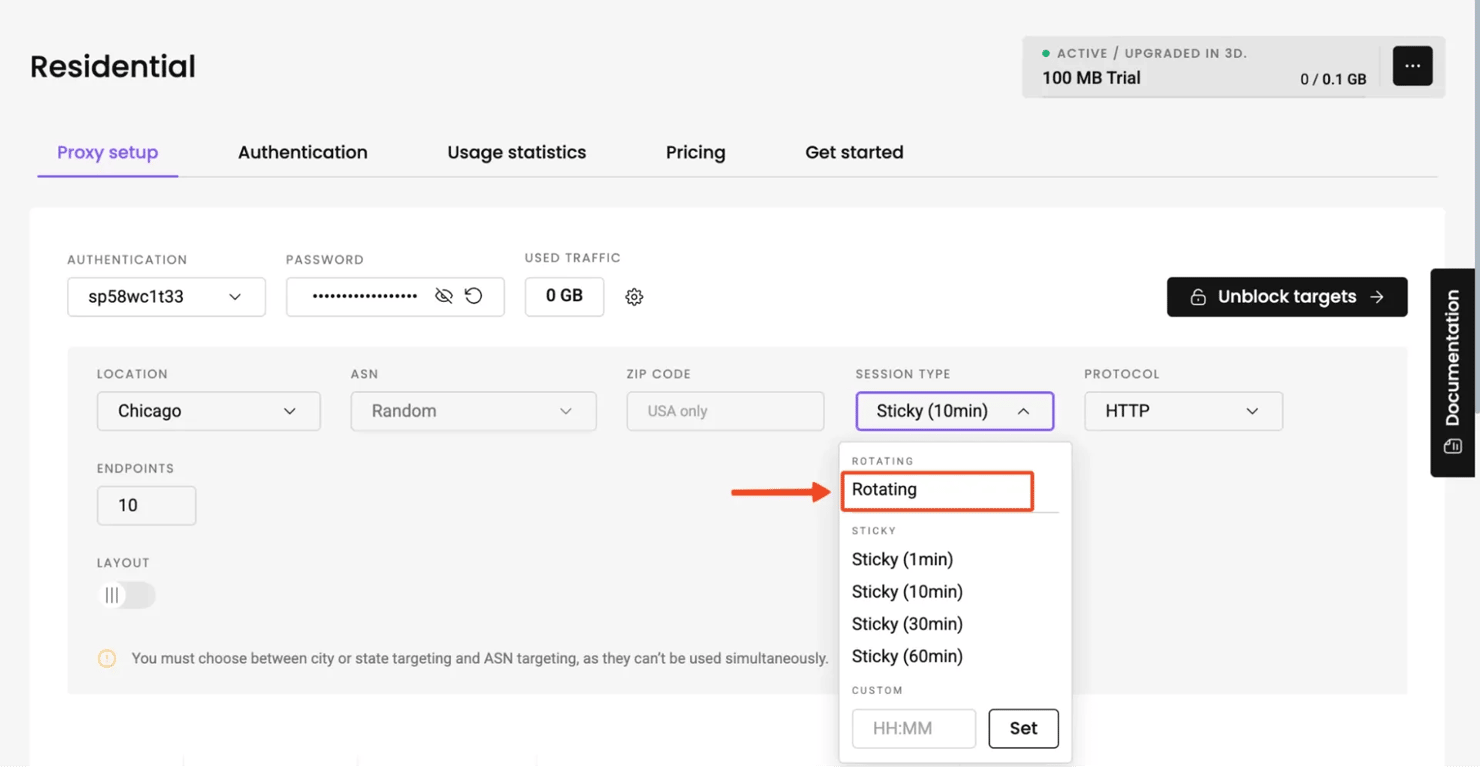
This means the IPs are rotated on every request to help keep our code lightweight while maintaining anonymity. If you haven’t already, sign up for Decodo and follow along with this tutorial:
Step 5: Normalize the API response
At this point, we’ve successfully pulled the raw comment data from the YouTube Data API. But if you opened youtube_raw_response.json, you’ll immediately notice how deeply nested and messy the structure is.
Each comment is wrapped inside multiple layers:
This nesting makes it hard to work with, especially if you plan to analyze the data in Excel or a database. So before you do anything meaningful, you need to normalize the API response. This means extracting only the fields you care about, which could include the comment ID, author, text, timestamp, like count, etc. and flattening the structure into a clean, manageable format.
Run the following script to normalize this data:
Note: Replace “YOUR_API_KEY” and proxy credentials with your actual credentials gotten from the respective providers.
The normalize_comment function extracts only the important fields from each comment, creating a dictionary with consistent field names that can be easily stored in a CSV file or database. By normalizing your data at this stage, you can easily remove the noise and set yourself up for analysis.
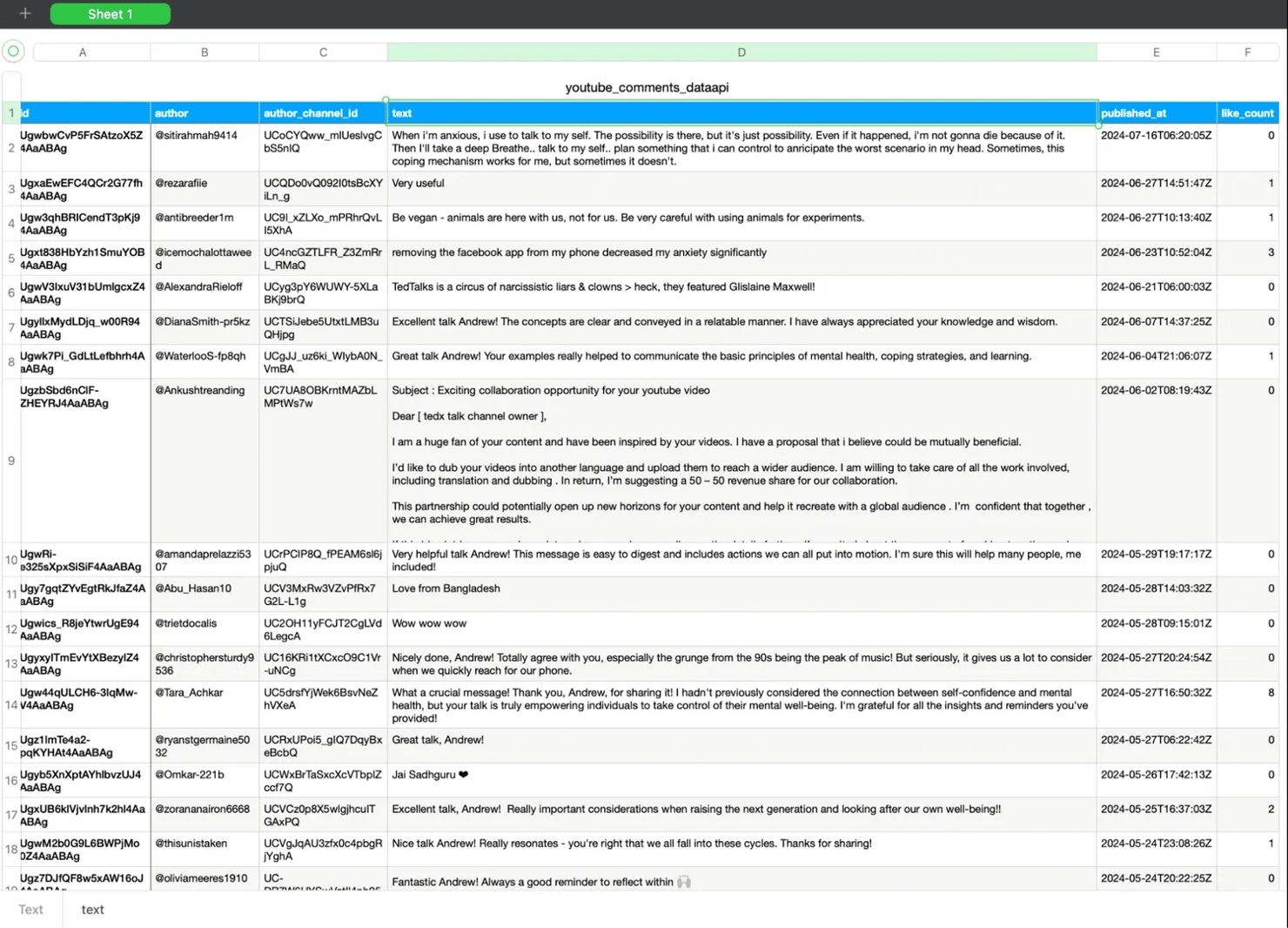
Step 6: Results
Run the script and you will get a youtube_comments_data_api.csv file in your project folder. Open it and verify the format matches your expectations before proceeding to cleaning the data or sentiment analysis.
Using yt-dlp
The yt-dlp library is one of the easiest ways to pull YouTube data without the Data API. It handles pagination and parsing internally, so you don't need to scrape HTML. If you’re just getting started or need a quick solution without API limits, it’s often simpler than browser automation.
Step 1: Set up your project
Similar to the previous method, start by creating a clean working directory for the project. Then install the yt-dlp library by running this command:
Step 2: Fetch YouTube comments with yt_dlp
We’ll configure yt-dlp to fetch only comments. Normally the tool downloads media, but with the right options we can skip video files and return metadata.
Make sure to replace the YouTube video URL with any video you want to scrape comments from:
This simple script is great for testing that yt-dlp works and seeing how it returns YouTube comment data. It quickly prints the raw output (a large dictionary containing each comment’s text, author, likes, and timestamps) which is useful for understanding the structure of the data.
However, since the output is verbose and not structured for analysis, let’s move on to a more advanced version that routes requests through proxies for safer large-scale scraping, saves comments to a clean CSV file, and includes extra options for smoother, more reliable performance.
Step 3: Scrape safely with proxies
Like with the Data API, scraping too many comments from a single IP address can get you blocked or restricted. So if you need large volumes of comments, you’ll likely hit rate limits or encounter throttling. To stay under the radar, we highly recommend using residential proxies from a premium provider like Decodo. We offer a free trial you can activate in under 2 minutes.
yt-dlp natively provides support for proxies, which only makes our lives easier. Let's define a proxy:
Step 4: Full script that normalizes comments to CSV
When you pull comments with yt-dlp, the raw output is a list of dictionaries, but the fields can be inconsistent and contain more information than you actually need. To make the data easier to work with, you should normalize it into a flat structure.
Below is the complete script. It fetches comments, flattens key fields, and saves them to youtube_comments.csv. Don't forget to replace:
- VIDEO_URL with your target video link.
- YOUR_PROXY_USERNAME and YOUR_PROXY_PASSWORD with your Decodo credentials.
Note: For huge threads, "max_comments": ["all"] pulls everything. For quicker runs, swap in a number – for example ["5000"].
Step 5: Viewing results
Once the script finishes, you’ll find a youtube_comments.csv file in your project directory. Open it in Excel or Google Sheets and you’ll see neatly structured rows with columns for ID, author, text, and timestamp, etc.
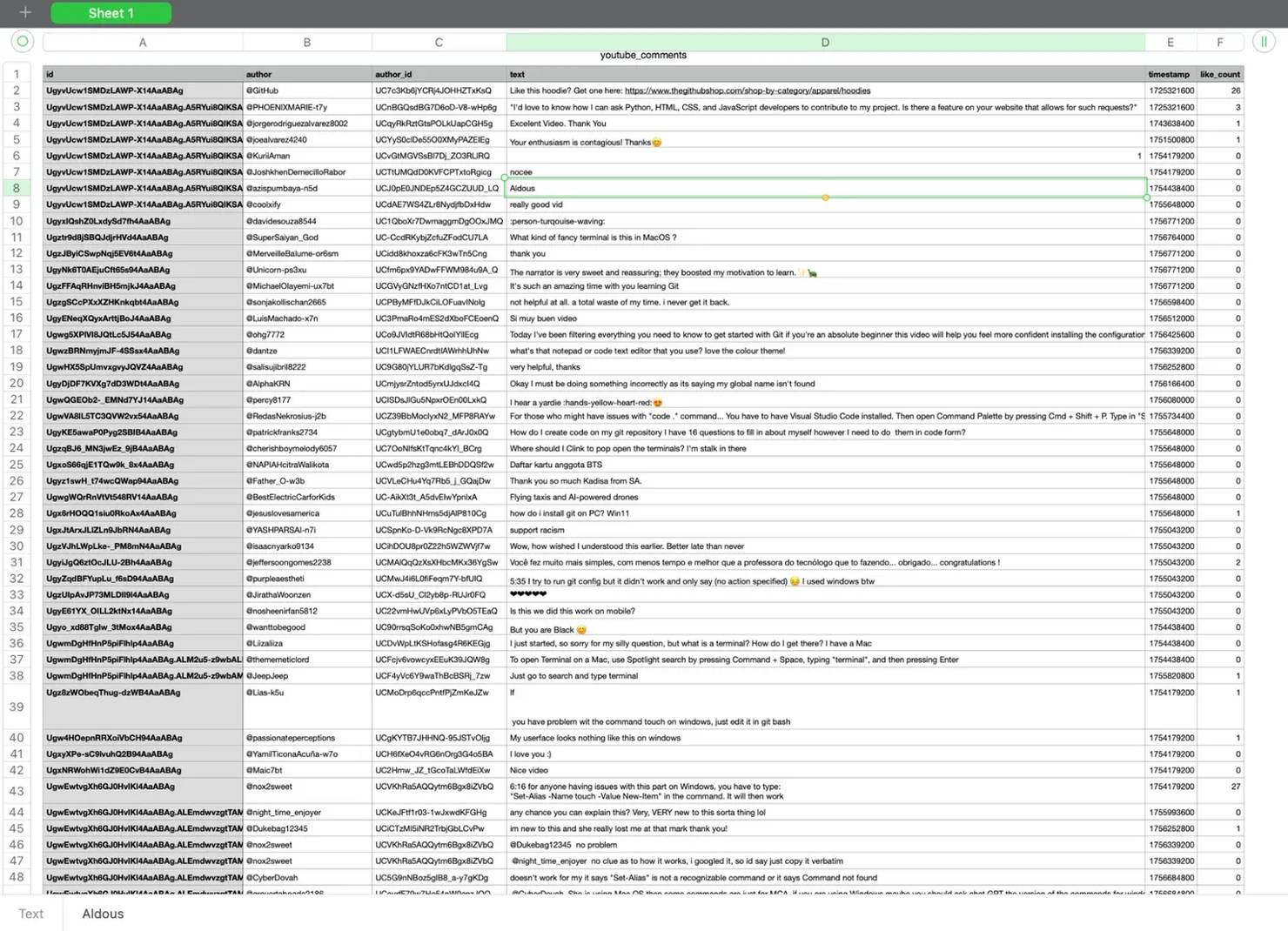
This makes it far easier to run analysis compared to dealing with the raw nested JSON. For more advanced workflows, you can import the CSV file into Pandas for data cleaning, visualization, or further analysis.
Choosing a scraping method
Now that we’ve seen multiple ways to scrape YouTube comments, the real question is: which method best suits your needs?
One of the most popular ways to download YouTube data is with the official YouTube Data API. This option is usually sufficient and kinder to use for most developers. The best thing about the YouTube Data API is that it’s free and stable with long-term support. However, it isn't as flexible as other solutions, enforces quota limits, and doesn’t allow large-scale scraping.
If you want something lightweight and straightforward, yt-dlp is the better choice. It doesn’t require API keys, handles pagination internally, and can pull all comments from a video. This makes it a solid option for quick experiments and even larger-scale operations. Its functionality even extends beyond YouTube comments; however, you’ll need proxies to go beyond a few requests.
For non-technical users, no-code and low-code solutions like n8n or Octoparse can be a better fit. These tools allow you to schedule scraping, monitor for new comments, and chain complex workflows without writing much or any code.
Regardless of the method, you’ll still want to consider post-processing steps like cleaning the raw comments, stripping emojis, handling duplicates, and performing sentiment analysis. Paying attention to these details will ensure your scraped dataset is not only complete but also ready for meaningful insights.
Wrapping up
Feel free to expand the source code with additional functionalities and adjust the target URLs for your YouTube data needs. If you want to save your scraped data or extend the scraper to pull YouTube Search Results, the techniques we covered in this guide give you a strong foundation to build on.
Now that you know how to scrape YouTube comments, you can apply these techniques to gather fresh insights for your channel or research project. YouTube’s comment section is full of real user opinions at your fingertips. And if you need premium YouTube proxies or any type of proxies, consider signing up for Decodo to enjoy smooth, uninterrupted scraping.
About the author

Dominykas Niaura
Technical Copywriter
Dominykas brings a unique blend of philosophical insight and technical expertise to his writing. Starting his career as a film critic and music industry copywriter, he's now an expert in making complex proxy and web scraping concepts accessible to everyone.
Connect with Dominykas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.