How to Scrape Zillow Data: Complete Guide for Real Estate Data
Zillow hosts millions of real estate listings across the U.S., but manually collecting that data is slow and error-prone. This guide walks you through how to scrape Zillow data effectively and ethically. You’ll learn what kind of data is accessible, which tools to use, and how to handle anti-scraping challenges to keep your pipeline running smoothly.
Justinas Tamasevicius
Last updated: Jun 23, 2025
6 min read

What Zillow data can be scraped?
Zillow doesn’t offer a public API for general use, but its front end reveals a wealth of information, if you know where to look. You can programmatically access listing data embedded in its HTML and network responses. This includes property metadata, pricing details, and agent info, all of which can be extracted using the right tools and parsing logic. Here are the key elements you can capture:
- Property addresses
- Prices and price histories
- Listing status (e.g., for sale, sold, pending)
- Beds, baths, and square footage
- Photos and virtual tours
- Agent or seller details
- Property descriptions and features
These data points are useful for real estate investment analysis, price monitoring, and lead generation.
Methods to scrape Zillow data
There’s more than one way to approach Zillow scraping. Each method comes with pros and cons:
- Manual scraping: Good for one-off tasks but not scalable.
- Browser automation (Selenium or Playwright): Can handle dynamic content but is resource-intensive.
- Direct requests to endpoints: Efficient but requires reverse-engineering Zillow’s frontend APIs.
- Third-party APIs: No-code and low-code solutions, such as Decodo's Zillow Scraper API, for hassle-free scraping, though usually paid.
Tools and libraries you’ll need
To build your own scraper, you'll need to use:
- A code editor of your choice (for example, Visual Studio Code)
- Python for scripting
- requests and httpx for HTTP calls
- BeautifulSoup or parsel for parsing HTML
- Browser Developer Tools to inspect endpoints
Optional:
- Selenium or Playwright for JavaScript-heavy pages
- Proxy services like Decodo to avoid IP bans
Step-by-step: scraping Zillow search results
Follow this step-by-step tutorial to scrape the Zillow page.
#1 Prerequisites
Before starting, check whether you have Python installed on your system.
#2 Install required packages
To scrape Zillow, you'll need:
- httpx for making HTTP requests
- parsel for parsing HTML content
Use the following commands in the terminal:
#3 Understanding bot detection on Zillow
Zillow employs advanced bot detection mechanisms, including:
- CAPTCHAs to verify human users
- Headers and cookies validation to ensure requests are legitimate
- Rate limiting to block excessive requests
To bypass these, you need to:
- Simulate human-like behavior
- Use valid headers and cookies from a logged-in session.
- Avoid making too many requests in a short time.
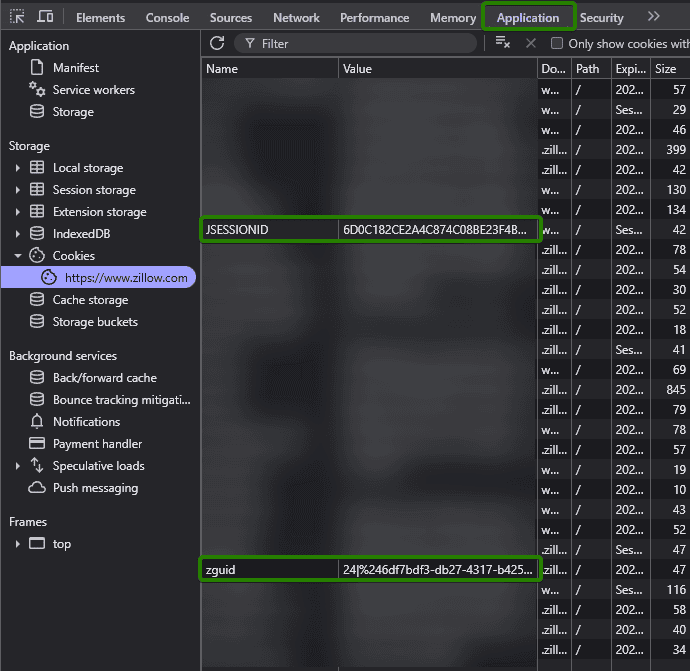
#4 Obtaining cookies and headers
Follow the steps below to get the required Zillow cookies:
- Open Zillow in your browser.
- Open the browser's developer tools (usually F12 or Ctrl+Shift+I).
- Go to the Application tab.
- Go to storage and find the Zillow cookies.
- Copy JSESSIONID and zguid.
#5 Prepare the script
Below is the Python script to scrape address data from Zillow:
Replace the below sections with copied IDs and paste the Zillow page to scrape:
#6 Explore the code
Getting off to a good start makes everything easier, so before you start building your scraper, make sure you understand all the key parameters in the code. These include:
- Headers and cookies – essential to mimic a real browser session.
- Fetch_page function – fetches the HTML content of the Zillow page.
- Parse_property_data function – extracts property details from the HTML using parsel and json.
- Display_property_data function – prints the extracted data in a readable format.
- Scrape_property function – orchestrates the scraping process.
#7 Run the script
Save the script as scrape_zillow.py and run it using:
#8 Check the results
Take this URL as an example:
And with a successfull scraping task, you should get this information back:
- Address: 1409 4th St, Key West, FL 33040
- Price: $1,200,000
- Beds: 3
- Baths: 2
- Area: 1,500
Handling anti-scraping measures
Zillow actively resists bots to protect its platform from abuse. To keep your scraper running smoothly and avoid detection, you’ll need to apply smart techniques and stay adaptable. Here’s how to avoid getting blocked:
- Rotate user agents and proxies
- Use headless browsers and cookie IDs to mimic real users
- Introduce delays between requests
- Monitor for CAPTCHAs or HTML changes
- Leverage third-party scraping APIs when needed
Scrape Zillow with Web Scraping API
Start your 7-day free trial with 1K requests.
Scrape Zillow with Web Scraping API
Our all-in-one web scraping API makes it easy to gather real-time data from Zillow. To get started:
- Sign up or log in to the Decodo dashboard.
- Go to the Scraping APIs tab in the right-side menu and select Pricing.
- Choose a subscription that fits your needs and start with a 7-day free trial.
- Once your subscription is active, navigate to the Web Scraping API interface and enter the URL you want to scrape.
- Adjust the settings like Location, HTTP method, and others as needed.
- Click Send Request and give the Web Scraping API a few moments to process.
After successful data extraction, you'll receive the results and can export them in your preferred format.
Scaling your scraping operations
If you plan to extract large volumes of Zillow data:
- Use cloud infrastructure for deployment
- Implement retry logic and backoff strategies
- Store data in scalable formats (CSV, JSON, or NoSQL)
- Use logging to monitor failures
Legal and ethical considerations
Many websites address data scraping in their Terms of Service. While scraping publicly available data is often legal, it may still violate a site's platform rules. To stay compliant and responsible, always:
- Scrape responsibly to minimize server load and avoid abusive behavior.
- Respect user privacy and don't collect personal or sensitive data.
- Respect robots.txt directives and follow the site's scraping permissions.
- Consult a legal expert to ensure your scraping projects are compliant with local laws and directives.
Common pitfalls and troubleshooting
Even when you've got decent tools, Zillow scraping can still go sideways and mess up your workflow or give you low quality data. Knowing what to expect helps you build something that actually works and saves you from pulling your hair out later trying to figure out what went wrong.
Getting your IPs blocked
Zillow's pretty trigger-happy about blocking IPs, sometimes after just a handful of requests, especially if you're scraping fast or using datacenter proxies. Your best bet is rotating residential proxies that make you look like a regular person browsing from home. This keeps you flying under the radar and dodges those annoying "Access Denied" errors and CAPTCHAs.
Layouts that keep changing
Zillow shows different layouts depending on whether a place is for sale, for rent, or off the market. That CSS selector that worked perfectly yesterday might be useless today. Build your scraper to check multiple spots for the same data and have backup selectors ready. Think of it as giving your scraper multiple ways to find what it's looking for.
JavaScript-heavy pages
A lot of Zillow's data loads after the initial page appears, thanks to JavaScript doing its thing in the background. If you're just grabbing the raw HTML, you're probably missing the good stuff. Use tools like Selenium or Playwright that can actually wait around for all the content to show up.
Inconsistent data
Not every property listing follows the same format. Some are missing key details, others have weird extra fields, and some might have typos or formatting quirks. Build your scraper to roll with these punches instead of crashing every time it hits something unexpected.
CAPTCHAs and bot detection
Zillow's getting smarter about spotting scrapers and will throw CAPTCHAs or other restrictions your way. Keep your scraping patterns looking human-like – add random delays, don't hit the same endpoints in perfect sequence, and maybe throw in some mouse movements if you're using a browser-based scraper.
Stale and duplicate data
Real estate moves fast, and that "just listed" property might have sold while you were scraping it. Plus, you might end up grabbing the same listing multiple times if you're not careful. Build in some duplicate detection and try to validate that your data is still fresh before you rely on it.
Bottom line
Scraping Zillow can be incredibly valuable if you're involved in real estate, whether you're analyzing housing markets, tracking pricing trends, or searching for investment opportunities. With the right strategy, you can automate the collection of high-volume, high-quality data, like property listings, price histories, neighborhood stats, and rental rates, giving you real-time insights that would be extremely time-consuming to gather manually.
However, Zillow actively protects its platform from automated scraping. To collect data without triggering CAPTCHAs or getting your IPs banned, you'll need to run several test scrapes to fine-tune your scraper. This might involve implementing rotating proxies, using randomized user agents, adding delays between requests, and carefully managing the frequency and scope of your data pulls to mimic human behavior and avoid detection.
Get rotating residential proxies
Start with a 3-day free trial and access 115M+ IPs from 195+ locations.
About the author

Justinas Tamasevicius
Director of Engineering
Justinas Tamaševičius is Director of Engineering with over two decades of expertise in software development. What started as a self-taught passion during his school years has evolved into a distinguished career spanning backend engineering, system architecture, and infrastructure development.
Connect with Justinas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.