Scrape TikTok Like a Pro: Step-by-Step Methods, Tools, and Tips
TikTok has become a goldmine of user-generated content and social media insights. With over 1 billion active users creating millions of videos daily, the platform offers unprecedented opportunities for data analysis, trend monitoring, and business intelligence. This comprehensive guide shows you how to scrape TikTok data effectively using Python.
Dominykas Niaura
Last updated: Jan 07, 2026
10 min read
Methods and tools for scraping TikTok
Several approaches exist for extracting TikTok data, each with distinct advantages and limitations. Choosing the right method depends on your technical requirements, scale needs, and budget constraints.
- Browser automation with Playwright/Selenium. The most reliable approach for handling TikTok's JavaScript-heavy interface. Tools like Playwright can fully render pages, handle infinite scroll, and mimic human behavior patterns. This method provides the highest success rate but requires more computational resources.
- Hidden API extraction. TikTok loads data through internal APIs that return JSON responses. By intercepting these API calls, you can extract structured data more efficiently than parsing HTML. However, these APIs change frequently and require reverse engineering.
- Unofficial TikTok APIs. Several open-source libraries like TikTok-API provide simplified interfaces for data extraction. While easier to implement, these tools often break when TikTok updates its systems and may not support all data types.
- Headless browser services. Cloud-based solutions offer managed browser infrastructure with built-in anti-detection features. These services handle proxy rotation, CAPTCHA solving, and infrastructure maintenance, but come with ongoing costs.
- Hybrid approaches. Combining multiple methods often yields the best results. For example, using Playwright for initial page rendering and then extracting data from hidden JSON objects provides both reliability and efficiency.
Why proxies are necessary for stable TikTok scraping
TikTok actively defends against scraping by tracking IP activity and limiting access based on region and behavior. Without proxies, your scraper will likely get blocked fast, especially at scale.
Proxies help by spreading requests across multiple IP addresses, making your activity appear more natural and avoiding rate limits. They also let you bypass regional restrictions and view content as if you're in a different location.
For best results, use residential proxies, which route traffic through real user devices and are harder for TikTok to detect compared to datacenter IPs. Pair this with smart rotation strategies (adjusting IPs based on request volume, error rates, and timing) to avoid triggering anti-bot systems.
At Decodo, we offer high-performance residential proxies with a 99.92% success rate, <0.5s response time, and geo-targeting across 195+ locations. Here’s how to integrate them into your TikTok scraper:
- Create your account. Sign up at the Decodo dashboard.
- Select a proxy plan. Choose a subscription that suits your needs or opt for a 3-day free trial.
- Configure proxy settings. Set up your proxies with rotating sessions for maximum effectiveness.
- Select locations. Target specific regions based on your data requirements or keep it at Random.
- Integrate into your scraper. Use the provided proxy endpoints in your scraping setup.
Get the Latest AI News, Features, and Deals First
Get updates that matter – product releases, special offers, great reads, and early access to new features delivered right to your inbox.
Why scrape TikTok?
TikTok scraping unlocks valuable insights that can transform your business strategy and research capabilities. The platform's vast ecosystem of content, creators, and user interactions provides rich data for multiple use cases:
- Trend analysis and market research. Monitor viral content patterns, emerging hashtags, and cultural movements in real time. Spot trends before they go mainstream and gain an edge in product development or content marketing.
- Influencer research and marketing. Evaluate creator performance, engagement metrics, and audience demographics to find the right brand partners. You can also monitor influencer campaigns and measure ROI more effectively.
- Sentiment analysis and brand monitoring. Use comments, video captions, and hashtags to gauge public sentiment toward your brand or competitors. Spot early signs of PR crises and respond proactively.
- Lead generation and sales intelligence. Uncover potential customers by analyzing content themes and user interests. B2B companies, in particular, can identify prospects discussing industry-specific pain points.
- Content strategy optimization. Analyze what formats, topics, and posting times drive engagement. Reverse-engineer successful accounts to sharpen your own content strategy and improve organic reach.
Understanding TikTok's structure and anti-scraping measures
TikTok presents unique challenges for web scraping due to its sophisticated architecture and robust anti-bot protections. Understanding these systems is crucial for building effective scrapers.
- Dynamic content loading. TikTok uses JavaScript rendering and infinite scroll mechanisms to load content dynamically. Unlike traditional websites with static HTML, TikTok constructs most of its data through server-side JavaScript, making simple HTTP requests insufficient.
- Anti-bot detection systems. The platform employs multiple layers of bot detection, including browser fingerprinting, behavioral analysis, and JavaScript challenges. These systems monitor request patterns, mouse movements, scroll behavior, and device characteristics to identify automated traffic.
- Rate limiting and IP blocking. TikTok implements aggressive rate limiting that can trigger temporary or permanent IP bans after relatively few requests. The platform also uses geographic restrictions and datacenter IP detection to block suspicious traffic patterns.
- CAPTCHAs and verification challenges. When suspicious activity is detected, TikTok displays various CAPTCHA types, including image recognition, puzzle solving, and phone verification requirements that can completely halt automated scraping attempts.
- Frequent structure changes. TikTok regularly updates its DOM structure, CSS selectors, and API endpoints to break existing scrapers. This means scrapers require constant maintenance and adaptation to remain functional.
Step-by-step guide: how to scrape TikTok data
In this section, we’ll walk you through how to use Python to scrape various types of TikTok data: profiles, videos/posts, comments, and search results. You'll learn how to extract structured information while handling TikTok’s anti-bot protections, all with practical, ready-to-run scripts.
Before running any of the scripts in this guide, make sure you have Python 3.8+ installed. Then, install the necessary libraries using the following commands:
After installing the packages, you’ll also need to install the Playwright browser binaries:
These libraries cover everything used in the scripts:
- Playwright – for browser automation when scraping profiles
- httpx – for making fast, async HTTP requests
- parsel – for parsing HTML content
- jmespath – for querying structured JSON data
Once these are set up, you’re ready to run any of the scraping scripts in this tutorial.
Scraping TikTok profiles
Profile scraping is a great entry point for influencer research, audience analysis, or competitive benchmarking. This Python script uses Playwright to automate a headless browser session and collect public profile data from TikTok.
The script works by launching a stealthy headless browser (Firefox in this case), routing traffic through a proxy for stability and geo-targeting. It visits the user’s profile page and tries to extract structured JSON data embedded in the page (__UNIVERSAL_DATA_FOR_REHYDRATION__). If that fails, it falls back to scraping visible HTML elements.
Here’s what it collects:
- Username and display name
- Bio/description
- Follower, following, and like counts
- Total number of videos
- Verification status
To reduce detection, the script uses a custom user-agent and disables navigator.webdriver, which helps mask automated behavior, as well as residential proxies.
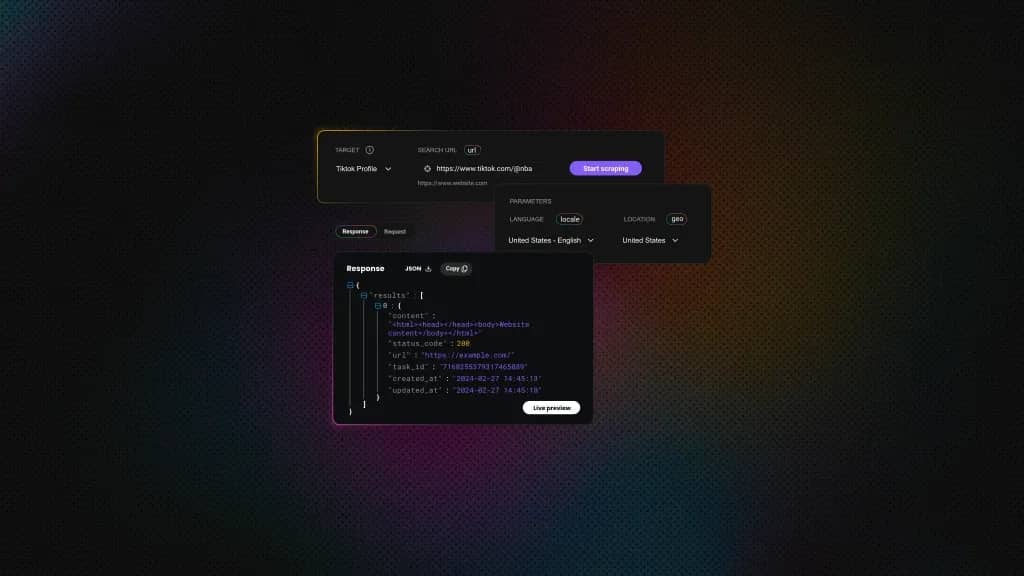
Once scraped, the data is returned in a structured JSON format that’s easy to store, analyze, or integrate into dashboards. Here's an example response for a real profile:
Scraping TikTok videos/posts
Scraping TikTok video pages allows you to extract rich metadata like post descriptions, hashtags, view counts, likes, shares, bookmarks, and more. This kind of data is especially useful for trend tracking, content analysis, and performance benchmarking.
All you need to do is plug your proxy credentials and a few TikTok post URLs into the script. The scraper sends asynchronous requests to TikTok video pages using httpx and parses the response HTML with parsel. It first attempts to extract structured data from TikTok’s embedded JSON (__UNIVERSAL_DATA_FOR_REHYDRATION__). If that fails, it falls back to scraping basic meta tags in the HTML.
The script is designed to:
- Return a clean summary of each video’s author, description, stats (likes, plays, comments, shares, bookmarks), and hashtags
- Handle HTTP errors gracefully and skip failed requests
- Add a small delay between requests to reduce the risk of triggering TikTok’s anti-bot defenses
- Use proxy routing to prevent IP bans and maintain reliable access
One key advantage is that it surfaces data not directly visible on the public TikTok post page, such as total play counts and bookmark numbers.
Below is the response you get with this script. This kind of output is especially helpful for researchers, marketers, or analysts who need quick, structured insights from multiple TikTok posts without manually inspecting each one:
Scraping TikTok comments
Comment scraping is essential if you're looking to understand audience sentiment, gather user feedback, or enrich content analysis with direct viewer reactions. This Python script uses httpx to fetch a TikTok video’s HTML, extract necessary tokens, and call TikTok’s internal comment API – all while routing requests through a proxy for stability and anonymity.
To use the scraper, simply replace the video URL, plug in your proxy credentials, and control how many comments to retrieve by changing the max_comments parameter. The script then:
- Parses the video ID from the URL
- Sends a request to the page to extract dynamic tokens like aid, msToken, and region required to query TikTok's comment API
- Builds the comment API URL and retrieves a list of comments
- Returns cleaned comment data including the author's handle, nickname, number of likes, replies, and the comment text itself
This kind of output that the script delivers is especially useful for identifying common reactions, capturing standout quotes, or spotting recurring audience themes. With a bit of additional logic, you could also perform basic sentiment analysis or track changes in engagement over time. Here’s a sample response from scraping the first 5 comments on a video:
Scraping TikTok search results
If you're tracking trends, monitoring a topic’s reach, or analyzing how people react to a breaking event, scraping TikTok search results can give you real-time insights into what’s being posted and how it’s performing.
The Python script below scrapes TikTok’s search results for a given keyword by simulating a browser visit, extracting internal API tokens, and querying TikTok’s backend search endpoint, all routed through a proxy for stability.
Here’s how it works:
- It creates a proxy-enabled HTTP client using httpx, with proper headers to mimic a real browser.
- It visits the public TikTok search page for the given query and extracts dynamic values like aid, msToken, region, and device_id – all of which are required to build a valid API call.
- It generates a random search_id to make the request appear unique and time-specific.
- It builds a search API URL with all the required query parameters, fetches the data, and parses relevant information from each video result.
The script collects and displays:
- Author username and nickname
- Video description (truncated if too long)
- Engagement stats: likes, plays, comments, shares
This scraper is especially helpful for quickly sampling content around a topic, measuring post engagement, and discovering emerging narratives or viral trends. You can easily modify it to paginate through more results or filter by engagement thresholds. Here’s a snippet of what the output looks like:
Handling and bypassing TikTok's scraping protections
TikTok employs sophisticated anti-scraping measures that require careful handling. Understanding these challenges and implementing proper countermeasures is essential for successful data extraction.
Common obstacles when scraping TikTok
- Rate limiting and IP bans. TikTok monitors request frequency and can impose temporary or permanent IP bans after detecting unusual traffic patterns. Signs include HTTP 429 errors, empty responses, or redirect loops to verification pages.
- CAPTCHAs and anti-bot mechanisms. The platform frequently displays image recognition puzzles, sliding puzzles, and behavioral verification challenges. These appear when TikTok's systems detect automated traffic patterns.
- Fingerprinting and behavioral detection. TikTok analyzes browser characteristics, mouse movements, scroll patterns, and timing to identify bot traffic. Consistent patterns or missing human-like behaviors trigger blocking mechanisms.
- Dynamic content loading issues. Since TikTok relies heavily on JavaScript, traditional HTTP scraping often returns empty or incomplete data. The content requires full browser rendering and proper timing.
Recognizing when you've been blocked
Watch for these warning signs that indicate your scraper has been detected:
- Empty or incomplete page content. Pages load but show minimal data or placeholder content.
- CAPTCHA challenges. Pop-up verification dialogs requiring human interaction.
- Redirect loops. Automatic redirects to verification or login pages.
- HTTP error codes. 429 (Too Many Requests), 403 (Forbidden), or 503 (Service Unavailable).
- Consistent timeouts. Pages that previously loaded quickly now time out frequently.
Solutions and workarounds
- Using rotating proxies and residential IPs. Implement a robust proxy rotation system to distribute requests across multiple IP addresses. Residential proxies are particularly effective as they appear more legitimate than datacenter IPs.
- Adjusting request headers and browser fingerprints. Rotate user agents and browser settings to avoid consistent fingerprinting.
- Implementing delays and randomization. Add human-like delays and random actions to avoid detection patterns.
- Leveraging JavaScript rendering and headless browsers. Use full browser automation with proper stealth settings.
Storing and analyzing scraped data
Proper data storage and analysis are crucial for extracting actionable insights from your TikTok scraping efforts. How you structure and analyze your data will shape the quality of your results. Here’s how to get started:
Output formats
- JSON storage. JSON is a great format for storing scraped TikTok data, especially when dealing with nested structures like user profiles, post metadata, and engagement stats. It’s lightweight, human-readable, and supported across most programming languages, making it ideal for smaller-scale projects, debugging, or exporting data to other tools.
- Database storage. For larger-scale scraping or long-term data collection, databases offer more structure and efficiency. PostgreSQL is a strong choice when you need relational integrity and powerful querying capabilities. On the other hand, MongoDB works well with semi-structured data and plays nicely with JSON-style documents, making it a natural fit for handling complex TikTok records like posts or profile snapshots.
Basic data cleaning tips
- Normalize number formats (e.g. convert "1.2M" to 1200000)
- Remove HTML artifacts from text fields like bios or captions
- Strip whitespace and emojis if you’re doing text-based analysis
- Handle missing or null values to prevent errors in your pipeline
- Convert timestamps to a consistent format (e.g. ISO 8601)
Example analyses
- Trend detection. Track hashtag frequency, sound usage, or caption keywords over time to detect emerging trends. Plot data weekly or daily to visualize spikes and cycles.
- Sentiment analysis. Run basic sentiment models on video captions or comment sections to understand public opinion. This can help with brand monitoring, campaign feedback, or competitor analysis.
- Influencer identification. Filter profiles by follower count, engagement rate, or niche-related hashtags to identify potential influencer partners. You can also build scoring systems to rank creators by relevance and reach.
Best practices and common pitfalls
Successful TikTok scraping requires careful attention to ethical considerations, technical implementation, and ongoing maintenance. Following these best practices will help you build sustainable and responsible scraping operations.
Respecting TikTok's terms of service and robots.txt
- Terms of service compliance. Review TikTok's Terms of Service regularly, as they may change. Generally, terms of service prohibit automated data collection, but enforcement varies. Understanding these restrictions helps you assess legal risks.
- Robots.txt guidelines. Check TikTok's robots.txt file at https://www.tiktok.com/robots.txt for crawler directives. While not legally binding, robots.txt provides guidance on the platform's preferences for automated access.
- Rate limiting. Implement conservative rate limiting to avoid triggering anti-abuse systems. Start with 1-2 requests per minute and adjust based on your success rates and blocking frequency.
Avoiding overloading TikTok servers
- Distributed request patterns. Spread your scraping activities across different time periods and IP addresses. Avoid burst patterns that could strain server resources or trigger security measures.
- Efficient data collection. Prioritize the most valuable data points and avoid collecting unnecessary information. This reduces server load and improves your scraping efficiency.
- Monitoring and alerting. Implement monitoring systems to track your scraper's performance and error rates. Set up alerts for unusual blocking patterns or system failures.
Keeping your scraper updated with TikTok changes
- Regular testing. Test your scrapers frequently to catch breaking changes early, as TikTok updates its interface and anti-bot measures regularly.
- Modular design. Structure your code with separate modules for different scraping tasks. This makes it easier to update specific functionality when changes occur.
- Selector management. Use flexible selectors that can adapt to minor DOM changes. Implement fallback extraction methods for critical data points.
Alternatives to scraping TikTok
If building and maintaining a custom scraper isn't the right fit for your project, there are a few alternative ways to access TikTok data. Some are official APIs provided by TikTok itself, while others come from third-party platforms. These options are more limited in scope but may work for specific, lower-volume use cases.
TikTok’s official APIs include:
- Research API. Designed for academic and non-commercial research, this API provides access to public, anonymized TikTok data such as video metadata, hashtag usage, and user profile information. However, access is currently limited to approved researchers affiliated with US-based institutions, and the program is managed through TikTok’s partnership with the University of Michigan's ICPSR platform. An institutional review board (IRB) approval is typically required.
- Marketing API. Intended for advertisers and TikTok partners, this API grants access to ad campaign performance data, audience demographics, and conversion metrics. It’s not suitable for general content scraping, influencer research, or competitor analysis.
- Login Kit and Developer Tools. TikTok offers SDKs that enable user authentication or content sharing through TikTok. These tools are useful for app integration but do not provide access to broader data or user activity beyond what’s explicitly authorized by the user.
Overall, official TikTok APIs come with strict access requirements, limited scope, usage quotas, and restrictions on commercial or large-scale data collection. They also don’t provide any access to public competitor content or trend-level data.
For more flexibility, third-party services are often the better choice. They provide access to TikTok data via scraping APIs or ready-made datasets, often with filters for hashtags, accounts, or engagement metrics. Decodo’s Web Scraping API, for example, includes a no-code template for scraping TikTok posts, letting you collect likes, comments, hashtags, and more without writing a single line of code.
Final thoughts
TikTok scraping presents unique challenges but offers tremendous value for businesses, researchers, and developers seeking to understand social media trends and user behavior. This comprehensive guide has covered the essential techniques, tools, and best practices needed to successfully extract TikTok data.
About the author

Dominykas Niaura
Technical Copywriter
Dominykas brings a unique blend of philosophical insight and technical expertise to his writing. Starting his career as a film critic and music industry copywriter, he's now an expert in making complex proxy and web scraping concepts accessible to everyone.
Connect with Dominykas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.

