Scrape Walmart Data: A Complete How-To Guide & Best Methods
Walmart’s digital marketplace is a vast platform, featuring over 420 million products and nearly 500 million monthly visits. That volume of web data is a valuable source for eCommerce teams, data analysts, and investment firms seeking pricing intelligence, inventory trends, and competitive insights. But scraping it isn’t easy – Walmart uses a complex, multi-layer anti-bot system that stops most common scraping tools. In this guide, you’ll learn the proven methods that work in 2026.
Vaidotas Juknys
Last updated: Jul 03, 2025
9 min read

Understanding Walmart data: what can you scrape?
Let’s look at the types of information you can scrape from Walmart’s site and why they matter:
Data type
Fields
Use cases
Product details
Name, brand, SKU, UPC, specifications, category path
Competitive intelligence, catalog enrichment
Pricing info
Current price, previous price, unit price, promo labels (rollback, clearance, best seller)
Dynamic pricing, margin analysis
Stock status
In stock / out of stock flag, low-stock alert, store-level availability
Supply-chain insights, promotion timing
Customer reviews
Review text, star rating, verified-purchase badge, images, review count over time
Sentiment analysis, product R&D
Media assets
High-resolution images, 360° views, spec videos (when available)
Content creation, visual merchandising
Seller details
Seller name & ID, seller rating, on-time shipping rate, return policy, and fulfillment type
Vendor assessment, partnership opportunities
Challenges in scraping Walmart
Walmart uses multi-layered detection systems to flag non-human traffic. As of 2026, they leverage Akamai Bot Manager and PerimeterX for advanced bot protection. Their detection methods include:
- Analyze TLS fingerprints, IP reputation, geolocation patterns, request frequency, and missing browser headers.
- Monitor JavaScript execution, device and browser fingerprinting, and other behavioral signals for bot score calculation.
- Enforce a progressive CAPTCHA flow – from simple “press and hold” checks to complex visual puzzles.
- Apply rate limiting, escalating from throttling to permanent IP bans.
- Build on a Next.js architecture (SSR, client hydration, lazy loading, obfuscated CSS classes) that further complicates scraping.
Here’s what you’ll see when your scraper gets detected:

Key point: Walmart invests heavily in blocking bots. Any vanilla HTTP-client script is redirected to a “Robot or human?” challenge within seconds. The following sections cover proven techniques to bypass these challenges.
Building a Walmart data scraper from scratch
The Python scraping landscape has evolved thanks to curl-cffi, the Python bindings for curl-impersonate. It mimics real browser TLS fingerprints, so your requests look indistinguishable from genuine browser traffic.
The strategy – finding the hidden JSON
Modern web apps, such as Walmart, fetch data via internal APIs and embed it in a <script> tag to speed up initial rendering.
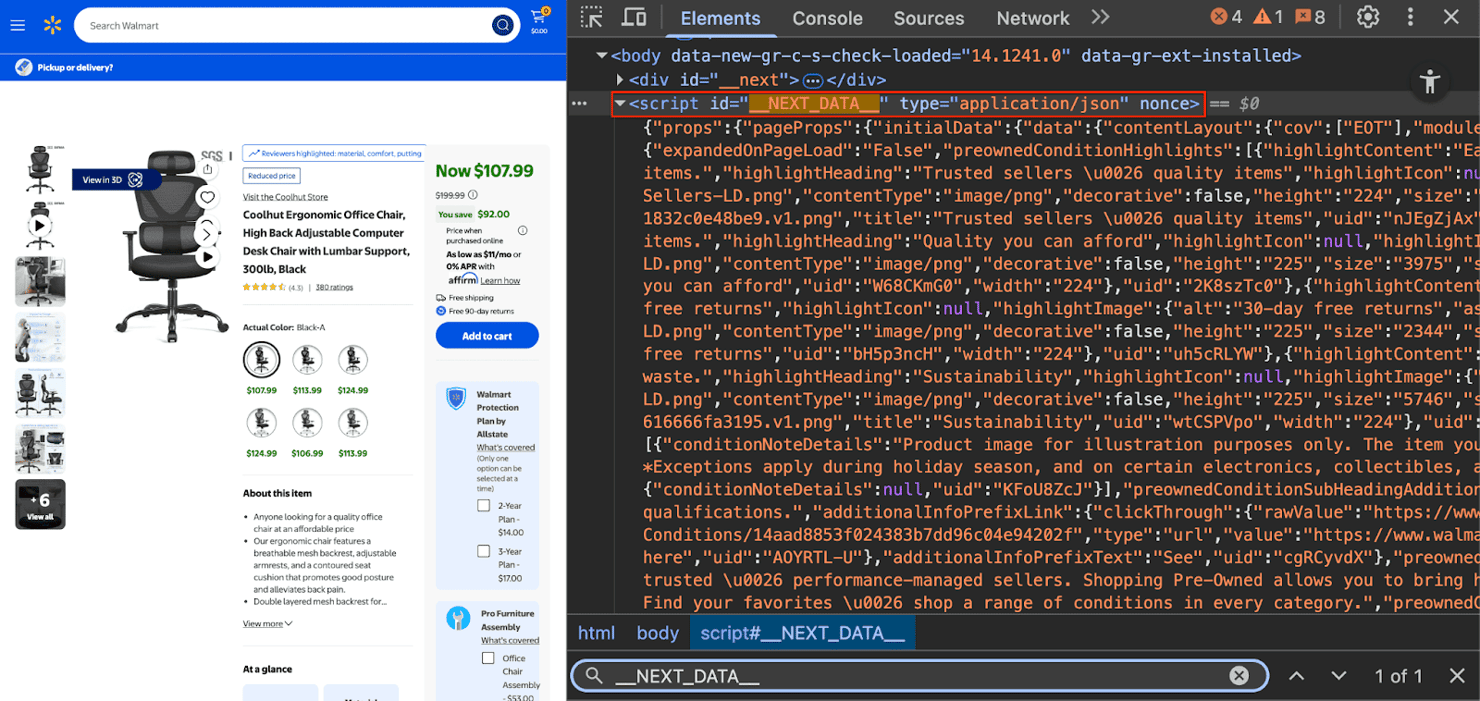
The goal is to locate and parse this data:
- Navigate to any Walmart search or product page.
- Open Developer Tools with a right-click and then Inspect.
- In the Elements tab, search for "__NEXT_DATA__".
- Look for: <script id="__NEXT_DATA__">…</script>.
So, rather than relying on brittle CSS selectors, we’ll target the structured JSON embedded in the page’s HTML – a far more robust approach.
Step #1 – setup and installation
Create and activate a Python virtual environment:
Install required libraries:
We use beautifulsoup4 to parse HTML and extract the <script> tag (a critical step in isolating the __NEXT_DATA__ payload). For detailed guidance on HTML parsing with Beautiful Soup, head to our complete web scraping guide with BeautifulSoup.
Step #2 – scraping Walmart search results
Let’s scrape Walmart’s search results for “office chair”.
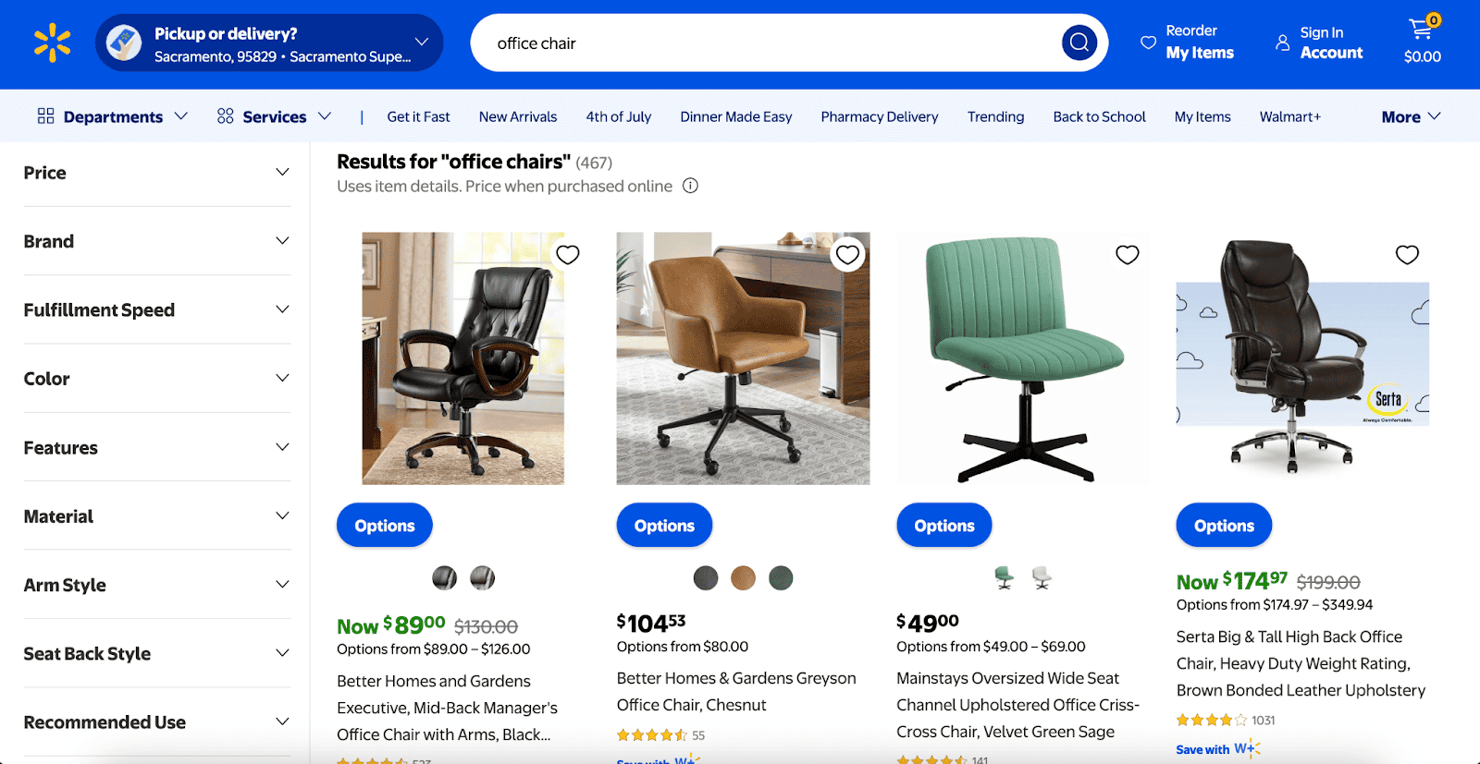
This script will query Walmart for a search term, paginate through the results, and extract product data from the __NEXT_DATA__ object on each page.
What this does:
- Uses curl-cffi with impersonate="chrome" to mimic Chrome’s TLS fingerprint
- Finds the __NEXT_DATA__ script tag and parses its JSON
- Extracts all product items from the nested JSON
- Loops through pages until no more items (or until max_items is reached)
- Saves results to a JSON file
Heads up – the sort parameter accepts best_match, price_low, price_high, and best_seller. You can also refine results with other filters (customer ratings, brand, fulfillment speed, etc.).
When you run the scraper, it loops through each page and outputs a walmart_office_chair.json file packed with clean product data.
Each item in the JSON file represents a product object with over 100 fields scraped directly from Walmart’s search results. The data is well-structured and ready for downstream analysis.
Here’s an example of what a product object might look like (trimmed for simplicity):
Heads up – the actual JSON includes many more fields and deeper nesting than the sample above.
Step #3 – scraping a Walmart product page
Scraping a single product page uses the same method – we target the <script id="__NEXT_DATA__"> tag and parse its JSON payload. However, the JSON path for accessing product details differs from the listing pages.
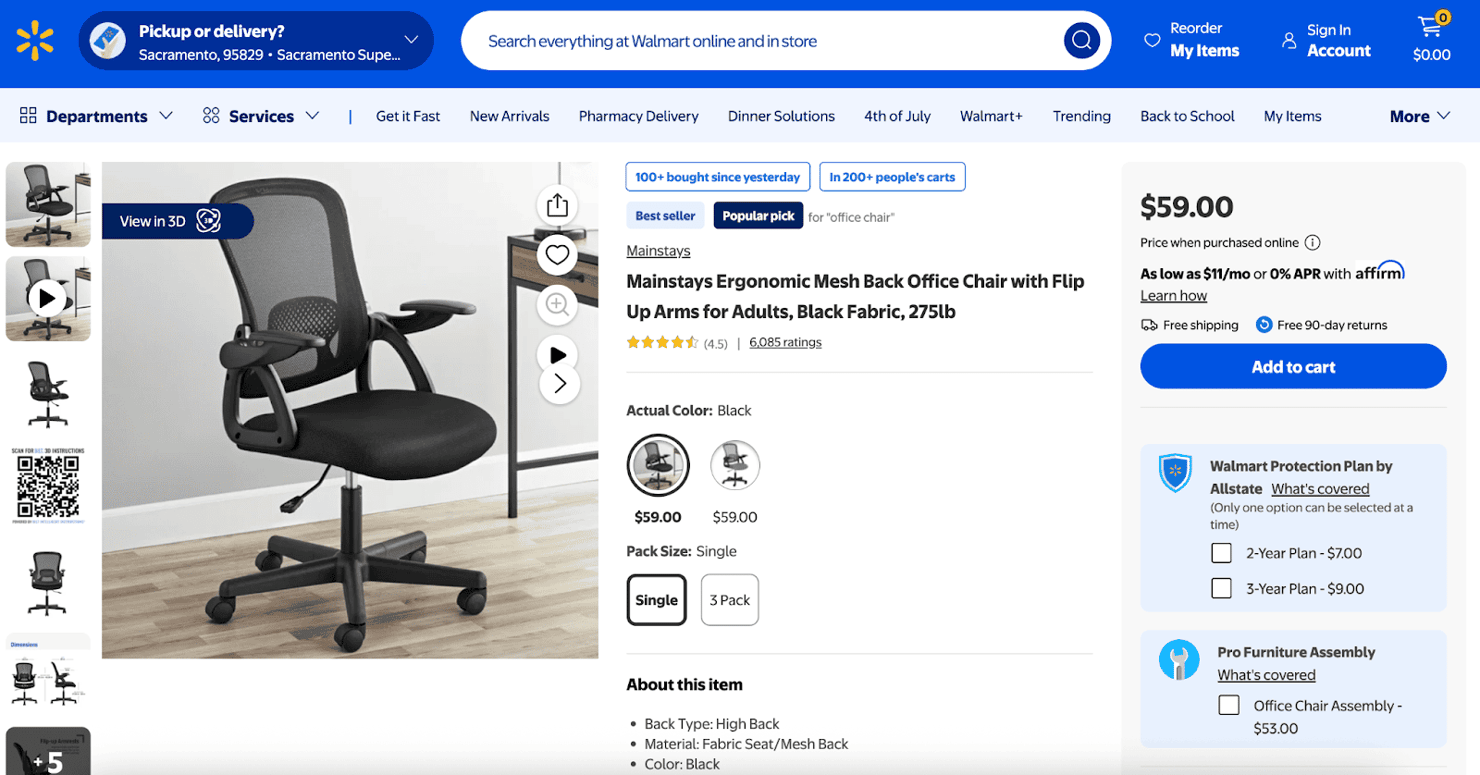
Here’s the complete code:
When you run this script, a walmart_product.json file appears in your directory, containing the complete product data model (usually under props.pageProps.initialData.data.product). Explore this JSON to find exactly the fields you need.
Step #4 – scraping Walmart product reviews
Walmart hosts reviews on pages like https://www.walmart.com/reviews/product/{PRODUCT_ID}?entryPoint=viewAllReviewsTop. Like other pages, the review data is embedded in the <script id="__NEXT_DATA__"> JSON object.
Here’s the complete code:
Run the scraper with your product ID and, optionally, the maximum number of reviews. It will loop through each review page until we’ve collected as many reviews as you need, then save everything to walmart_reviews_{PRODUCT_ID}.json.
Scaling up: how to avoid getting blocked
The basic script works fine for a few product pages. But once you send hundreds or thousands of requests from a single IP, Walmart will block you. Their bot protection system detects repeat traffic and responds with a challenge page:
To scrape at scale reliably, you’ll need rotating residential proxies. Residential IPs are assigned by real ISPs, making your traffic appear as if it’s coming from actual users, bypassing most bot detection systems.
Integrating Decodo residential proxies into your Python script is straightforward. First, head to the quick start guide to learn how to obtain your credentials. Decodo offers a free 3-day trial to help you test the setup at no cost.
Create an .env file in the same directory as your script to securely store your proxy credentials. Install the helper library using:
Now, add your credentials to .env:
Modify your scraper to use the proxy:
Decodo gives you access to 115M+ ethically-sourced residential proxy IPs across 195+ worldwide locations. With proxy rotation, each request is routed through a different real-user IP, allowing you to scrape at scale without triggering blocks.
The enterprise solution – web scraping API
Maintaining proxies and scrapers is a heavy engineering lift. Layout changes, evolving anti-bot measures, and parser breaks mean constant upkeep. For businesses that need reliable web data without the maintenance overhead, an all-in-one Web Scraping API is the most efficient solution.
A Web Scraping API abstracts away complexity – you make a single API call with a target URL, and the service handles proxy rotation, CAPTCHA solving, browser-fingerprint impersonation, and parsing, returning clean JSON.
Whether you’re scraping search pages, product listings, or any other site, Decodo’s Web Scraping API makes it fast, simple, and scalable, with zero manual work:
- Pay only for successful requests. You’re billed only for calls that return data.
- Flexible output options. Choose HTML, structured JSON, or parsed CSV.
- Real-time and on-demand results. Get data immediately or schedule tasks for later.
- Built-in anti-bot bypass. Browser fingerprinting, CAPTCHA evasion, and IP spoofing.
- Easy integration. Quick-start guides and code examples help you get up and running quickly.
- Ethically-sourced proxy pool. Leverage 125M+ residential, datacenter, mobile, and static residential (ISP) IPs across the world for geo-targeting and high success rates.
- Free trial. Test the API for 7 days with 1K requests at no cost.
Getting started
To set up the Walmart Scraping API:
- Create an account or sign in to your Decodo dashboard.
- Under Scraping APIs, select a plan – either Core or Advanced.
- Choose a subscription and select Start with free trial.
- Now, you can choose your target website. In this case, select Walmart – specifically the Walmart Search or Walmart Product endpoint.
Walmart Search Scraper
Here’s what the Decodo dashboard looks like when configuring the Web Scraping API for Walmart Search:
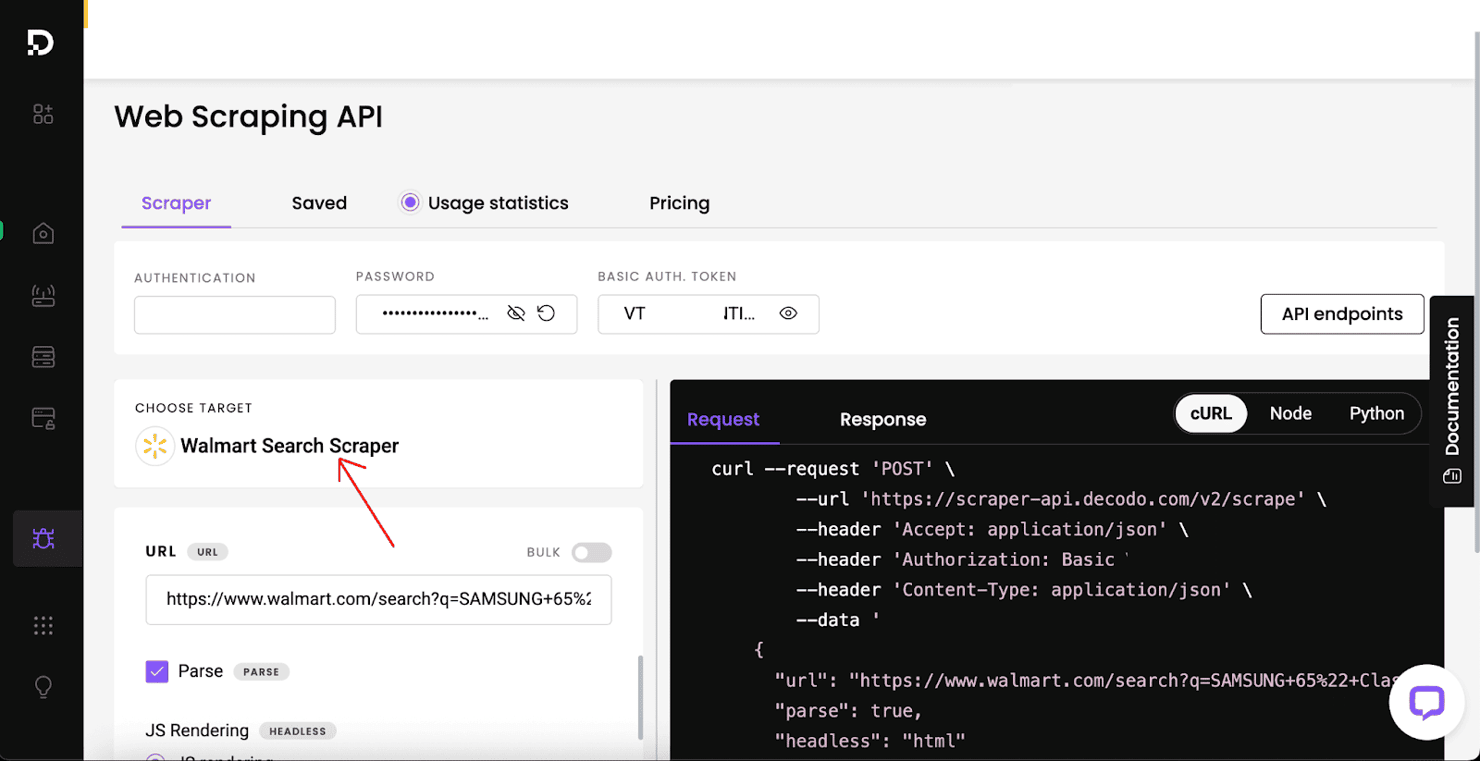
Simply paste the Walmart search URL into the input box on the Decodo dashboard.
You can optionally configure several API parameters, such as:
- JavaScript rendering
- Custom headers
- Geolocation
- Store zip code or store ID, and more.
To target a specific Walmart store:
- Use a ZIP code (e.g., 99950) to define the store location.
- Or specify a store ID to get localized search results.
Then click Send Request. Within seconds, you’ll receive the clean HTML of the Walmart search results page.
Your API response will appear in the Response tab, and you can export it in CSV or JSON format. Here's an example response (trimmed for brevity):
If you’re a developer, the dashboard can auto-generate code in cURL, Python, and Node.js. You can copy it with one click and plug it into your application instantly.
Walmart product scraper
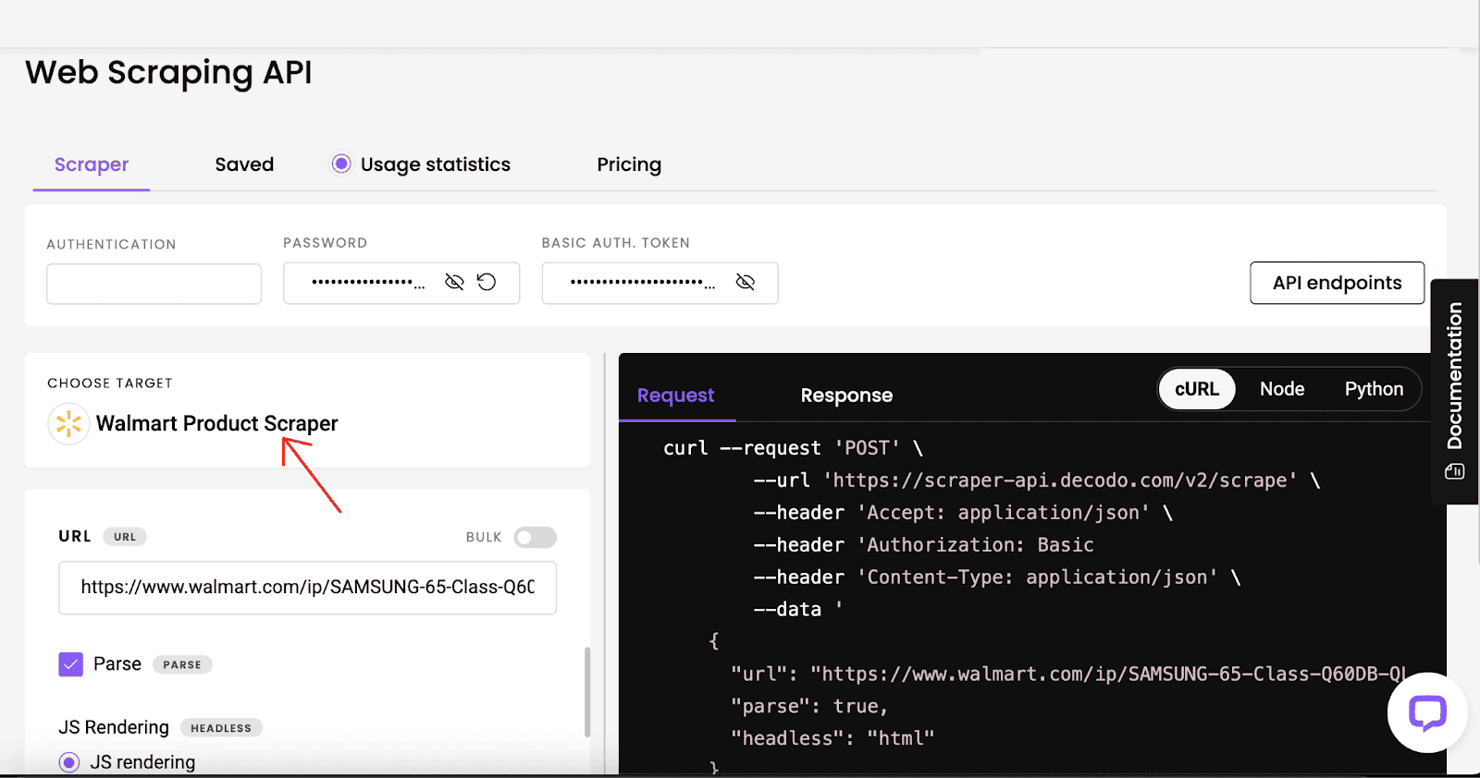
Just like the Search endpoint, you can switch the target to Walmart Product in the dashboard. The process is similar – paste the product URL, configure parameters if needed, and click Send Request. You'll receive structured JSON with detailed product data, which you can export just as before.
Ethical considerations
Scraping Walmart at scale is feasible, but only when done responsibly. Use the checklist below to ensure compliance with Walmart’s policies.
- Limit server load – throttle requests, respect robots.txt, and distribute traffic across regions with a geographically rotated proxy pool.
- Collect only public product data – prices, SKU IDs, and star ratings are non-copyrightable, strip any personal info (names, emails, addresses) that may appear in reviews.
- Simulate normal shopper traffic by rotating authentic User-Agent strings, maintaining TLS/device fingerprints coherence, and terminating the session after N consecutive CAPTCHA challenges.
Decodo’s Walmart scraper API includes built-in safeguards by default – adaptive rate limiting, advanced IP rotation, browser fingerprinting, and a controlled CAPTCHA handler, helping you to focus on insights instead of compliance overhead.
Conclusion
Scraping Walmart at scale is tough – their anti-bot stack flags most basic bots. You have 2 realistic options. The DIY approach gives you full control, but it requires building and maintaining your scraper and integrating a robust residential proxy network to avoid blocks and detection.
A more efficient alternative is to use a managed solution, like Decodo's Web Scraping API. It’s a faster, more reliable way to access structured Walmart data at scale. A single call returns parsed JSON or CSV while Decodo rotates proxies, solves CAPTCHAs, and adapts to layout changes.
For serious commercial projects, the API approach offers far better ROI by saving hundreds of hours in development and ongoing upkeep.
Collect Walmart data at scale
Start your 7-day free trial of Web Scraping API and gather pricing information without CAPTCHAs or IP bans.
About the author

Vaidotas Juknys
CEO
Vaidotas Juknys is a commercial leader with 10+ years across technology, telecommunications, and management consulting. His analytical mindset and drive to make public data more accessible have shaped a career that culminated in his role as Decodo's CEO.
In between business strategies, Vaidotas is a self-confessed sci-fi fan with a shelf full of novels and comic books to prove it.
Connect with Vaidotas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.