How to Scrape ZoomInfo: A Complete Step-by-Step Guide
ZoomInfo is a goldmine for B2B teams – over 100M company profiles and 260M contacts, all in one place. But getting that data isn’t easy. With strict defenses like CAPTCHAs, browser fingerprinting, and aggressive IP bans, most scrapers fail after just a few requests. That’s where this guide comes in. We’ll show you how to bypass ZoomInfo’s countermeasures and extract clean, actionable data at scale.
Justinas Tamasevicius
Last updated: Jun 10, 2025
10 min read
What data can you extract from ZoomInfo?
ZoomInfo delivers rich business intelligence across several key categories:
- Company intelligence (firmographics). Company name, headquarters location, website, SIC/NAICS codes, revenue, employee count, and parent-subsidiary structure.
- Contact information. Professional profiles, job titles, departments, seniority, verified emails, direct phone numbers, and LinkedIn URLs.
- Technology & operations (technographics). Insights into the company’s tech stack, cloud providers, and even org charts that map team structures and reporting lines.
- Business insights. Real-time updates, intent signals, executive moves, funding rounds, and data confidence scores to help you filter for quality.
ZoomInfo data architecture
Before writing any scraping logic, it’s important to understand how ZoomInfo structures its pages. Let’s take Anthropic’s company profile as an example:
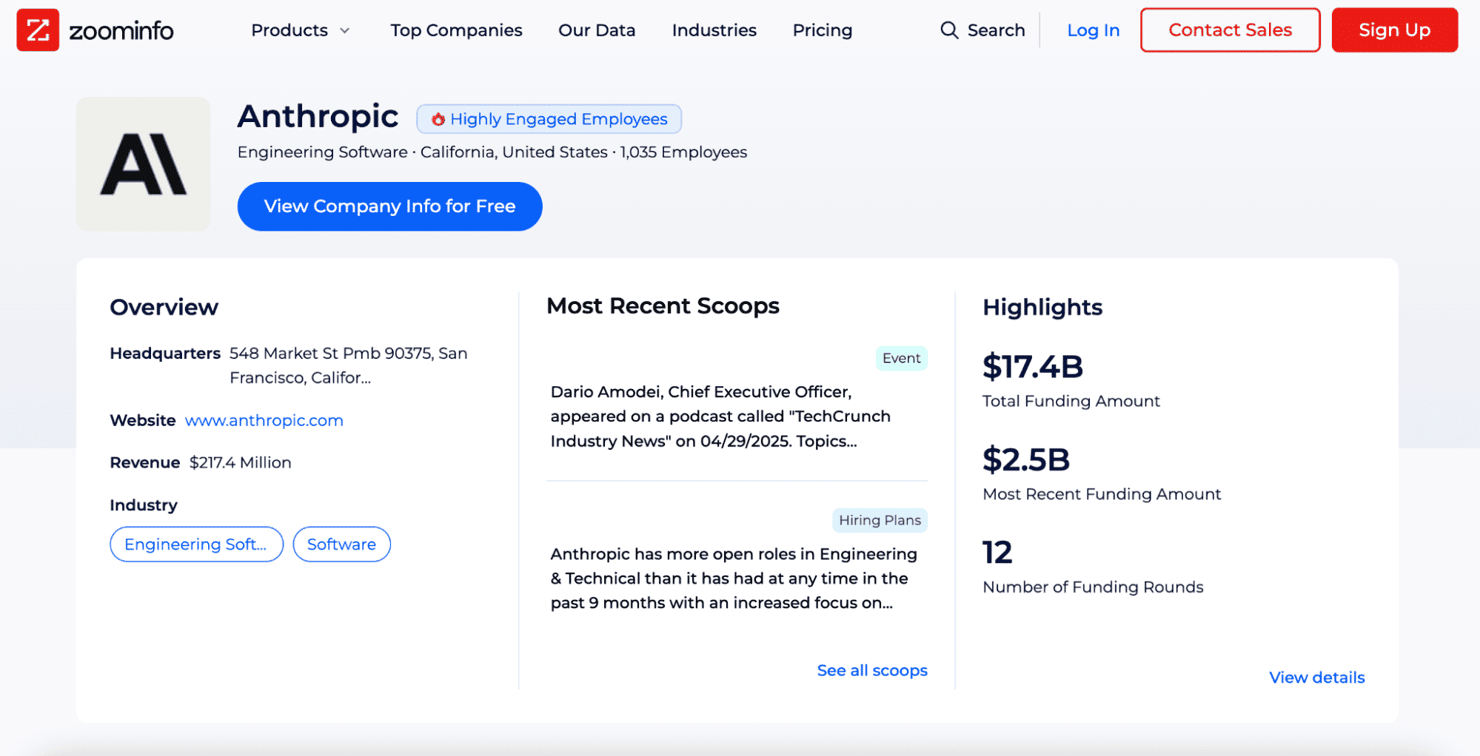
Most developers jump straight into parsing HTML when scraping, but ZoomInfo hides its best data elsewhere. Instead of cluttered DOM elements, it embeds a clean JSON object right inside a <script> tag.
Open DevTools, go to Network, filter by "Doc", and click the first entry to view the HTML. If you need a quick refresher on finding hidden data in your browser, check out How to Inspect Element.
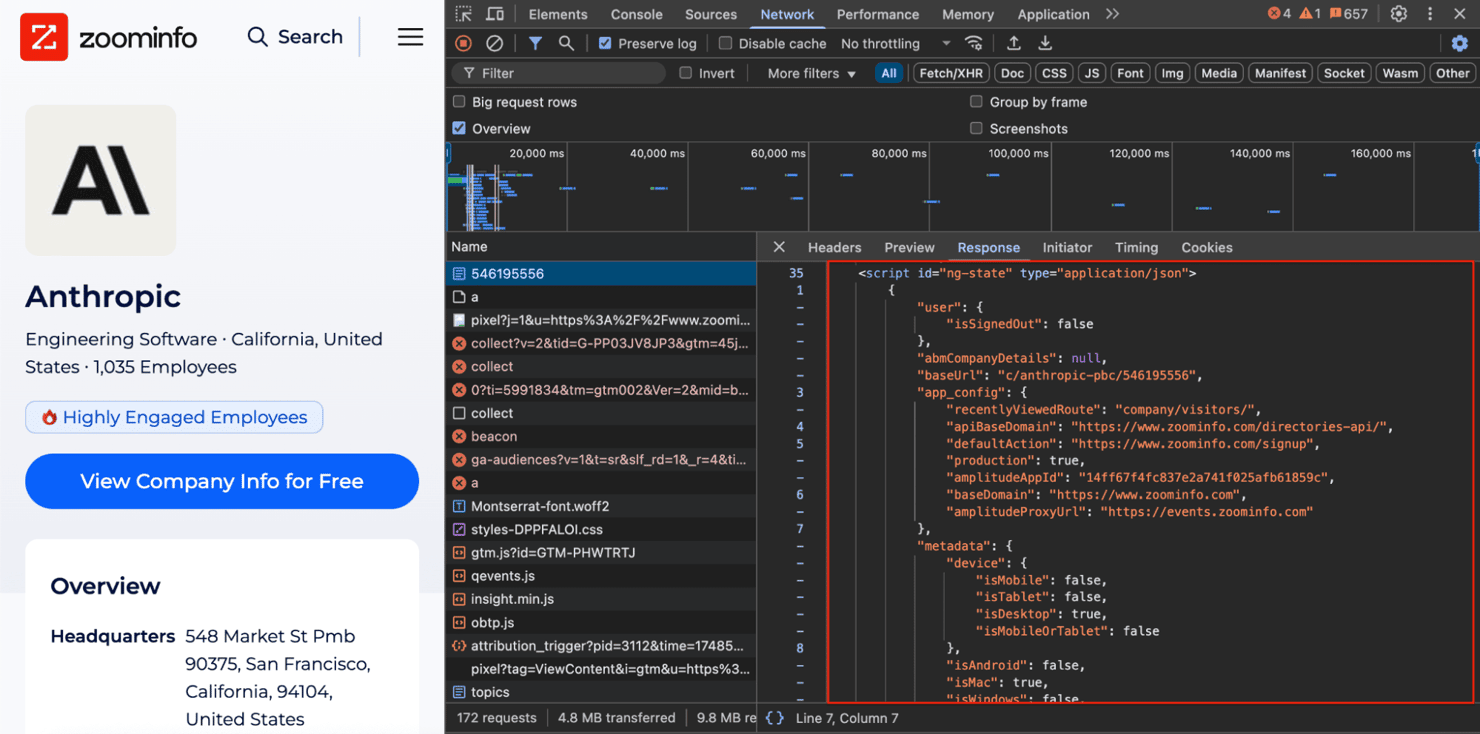
This JSON blob holds far more than what’s visible on the screen – from org charts and funding history to detailed contact info and company intent signals. Scraping this structured data directly is not only faster, it’s more reliable than chasing fragile DOM selectors.
Challenges of scraping ZoomInfo
Scraping ZoomInfo requires a clear understanding of how aggressive their anti-bot defenses are. Some sites are intentionally built to be hard to scrape – ZoomInfo is a prime example. You can learn more about these tactics in our article on navigating anti-bot systems.
Here are the key challenges you’ll face:
- Aggressive IP bans. ZoomInfo monitors request frequency closely. Too many requests in a short period can trigger a 429 Too Many Requests response, followed by a 403 Forbidden error and a temporary or permanent IP ban. For more on handling these, see our proxy error codes guide and, if you do get banned, follow the steps in how to fix an IP ban.
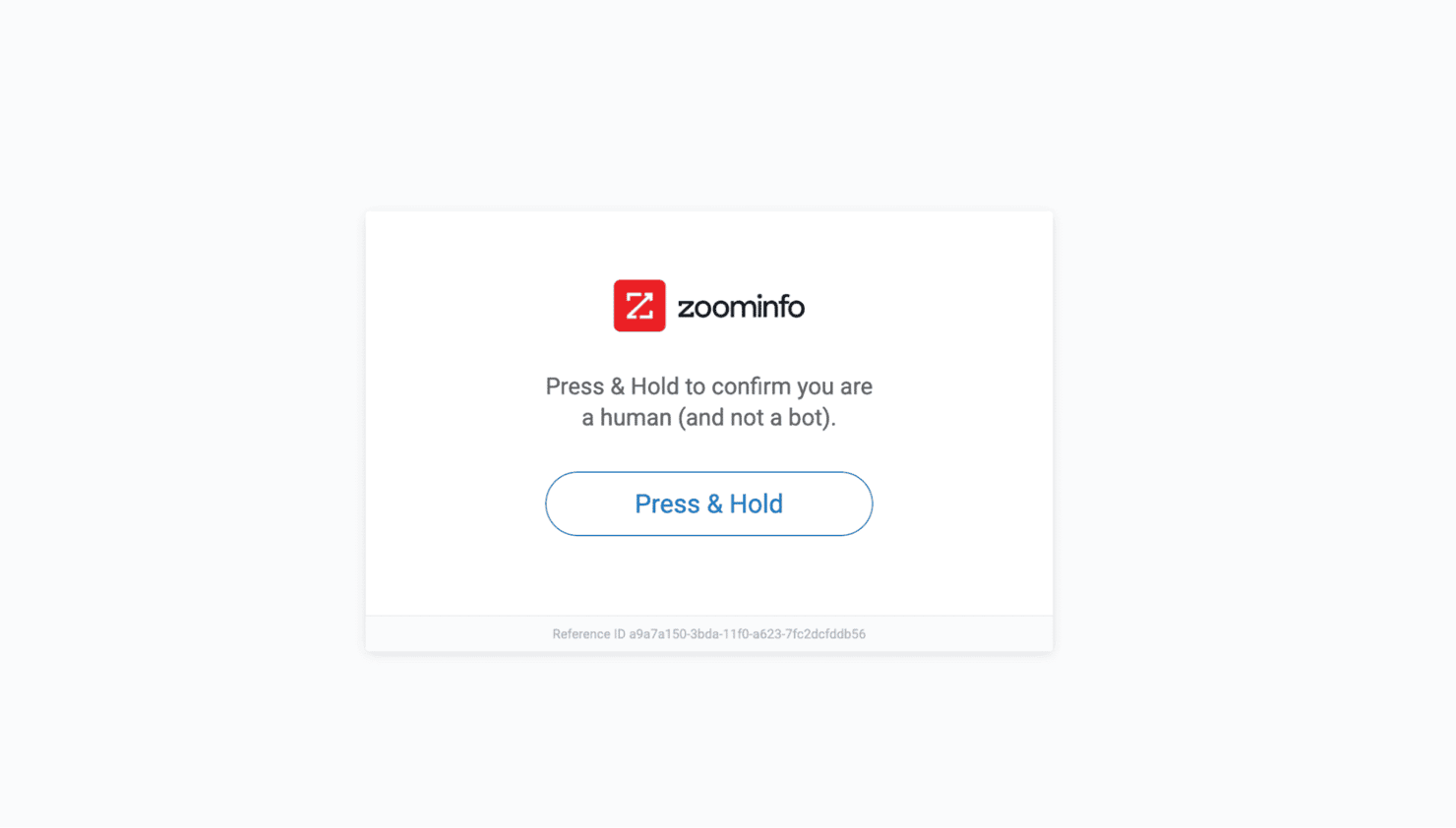
- CAPTCHAs and behavioral traps. After a few requests from the same IP, ZoomInfo will present a CAPTCHA (e.g., a "Press & Hold" slider puzzle) designed to block automated scripts.
- Advanced browser fingerprinting. ZoomInfo analyzes headers, JavaScript execution, Canvas/WebGL fingerprints, and other signals to distinguish real users from bots. A basic Requests script or a vanilla headless browser will usually be flagged almost immediately.
These defenses mean a "simple scraper" will fail outright. To succeed, you’ll need to upgrade your toolkit.
Handling anti-bot protection
Now that you understand how platforms like PerimeterX detect bots – and that ZoomInfo uses it – let’s walk through practical methods to bypass their defenses. To scrape ZoomInfo successfully, your scraper must behave like a real user by mimicking browser behavior, rotating IP addresses, and handling CAPTCHAs and fingerprinting.
Stealth (fortified) headless browsers
You’ll need a stealth browser – essentially a custom headless setup that hides automation signals and mimics real-user behavior:
- Selenium – Use Undetected ChromeDriver or SeleniumBase
- Puppeteer – Use the Puppeteer Stealth Plugin
- Playwright – Use Playwright Stealth
These tools patch navigator.webdriver, spoof Canvas/WebGL fingerprints, and eliminate the most obvious headless clues.
Note: Open-source stealth plugins are powerful, but they lag behind ever-evolving systems like PerimeterX. Also, running headless browsers at scale consumes significant CPU, RAM, and bandwidth.
CAPTCHA-solving services
When ZoomInfo presents a CAPTCHA, you’ll need a solver. The most popular options include 2Captcha and Anti-Captcha. They use human solvers or advanced AI models to bypass challenges automatically. Integration is straightforward, but these services add latency and increase your cost per request.
Rotating residential proxies
The most critical step: don’t send all requests from a single IP. ZoomInfo actively monitors IP behavior, and repeated access from one address is a quick path to a 403 Forbidden response.
Why residential proxies? Residential IPs route traffic through real consumer devices, making them far harder for ZoomInfo’s bot detection systems to flag compared to datacenter IPs.
Rotation is key. Use a proxy pool that assigns a fresh IP on each request to stay under ZoomInfo’s radar.
Our residential proxy pool provides access to over 115 million ethically-sourced IPs across 195+ locations, complete with automatic rotation and geo-targeting capabilities. You’ll see consistently high success rates – even when targeting advanced anti-bot platforms like ZoomInfo.
Get the Latest AI News, Features, and Deals First
Get updates that matter – product releases, special offers, great reads, and early access to new features delivered right to your inbox.
Step-by-step ZoomInfo scraping implementation
Now, let’s build the ZoomInfo scraper step by step. We’ll route all requests through a rotating residential proxy pool to avoid ZoomInfo’s anti-bot defenses.
1. Environment setup
First, create a virtual environment and install the necessary packages:
Here’s what each component does:
- Requests – Fetches the webpage HTML
- BeautifulSoup – Parses the HTML to extract data
- urllib3 – Handles proxy-related security warnings
👉 For a deeper dive, explore our hands-on guides to mastering Python Requests and web scraping with BeautifulSoup.
2. Basic company profile scraper
Let’s build a simple scraper that:
- Fetches the HTML. Makes a request to the ZoomInfo URL.
- Extracts the JSON data. Finds a hidden <script id="ng-state"> tag containing all profile data.
- Saves the output. Dumps the JSON to page_data.json.
Here's a scraper for individual company pages:
Running this script will create a page_data.json file. You’ll see something like this:
That JSON comes with everything you need for:
- Market analysis
- Lead generation
- Competitive research
- CRM enrichment
- Custom dashboards and reports
Scaling ZoomInfo data collection
Now that we have a scraper that works for individual company pages, let’s scale up and extract data from thousands of companies.
Method 1 – Scraping search results with pagination
ZoomInfo’s company search is a great starting point. You can apply filters like industry and location to narrow down results. For example, software companies in Germany:

To collect company profiles at scale, we’ll need to handle pagination. ZoomInfo paginates its search results using a "?pageNum=" query parameter. However, you’ll only get access to the first 5 pages before hitting a login wall.
Here’s our approach:
- Loop through pages 1 to 5.
- On each page, extract all company profile URLs using BeautifulSoup. The scraper uses the selector a.company-name.link[href] to find profile links and converts relative URLs into absolute ones using urljoin.
- Send each URL to the ZoomInfoScraper to extract and save JSON data from the HTML.
- Throttle requests and rotate headers to stay under ZoomInfo’s radar.
First, install the extra required dependencies:
- tenacity – Adds retry logic with exponential backoff to handle occasional request failures. Learn more about retrying failed requests.
- fake-useragent – Generates random User-Agent strings to simulate real browser behavior and avoid detection.
Here’s the full Python code:
Method 2 – Recursive crawling via competitor links
One powerful way to scale ZoomInfo scraping is by using competitor relationships to find more companies. Each company profile includes a competitors section, which you can use to dynamically expand your dataset.
Here’s a sample from the competitors array in the extracted JSON:
Using this, you can make full company URLs like:
Here’s how to turn a few seed companies into a large-scale dataset:
- Start with a seed company (e.g., Anthropic).
- Scrape its profile and extract all competitor info.
- For each competitor, build their URL and repeat the process.
- Continue crawling until you hit a max page limit or depth.
This strategy is called recursive crawling. For a deeper dive on how crawling differs from traditional scraping, read Web Crawling vs. Web Scraping.
Here’s a visual overview:
Bonus – People's data is also hidden in the HTML
Company pages aren’t the only target. ZoomInfo’s People Search results also embed rich, structured data in the same <script id="ng-state"> JSON and can be extracted using the same logic.
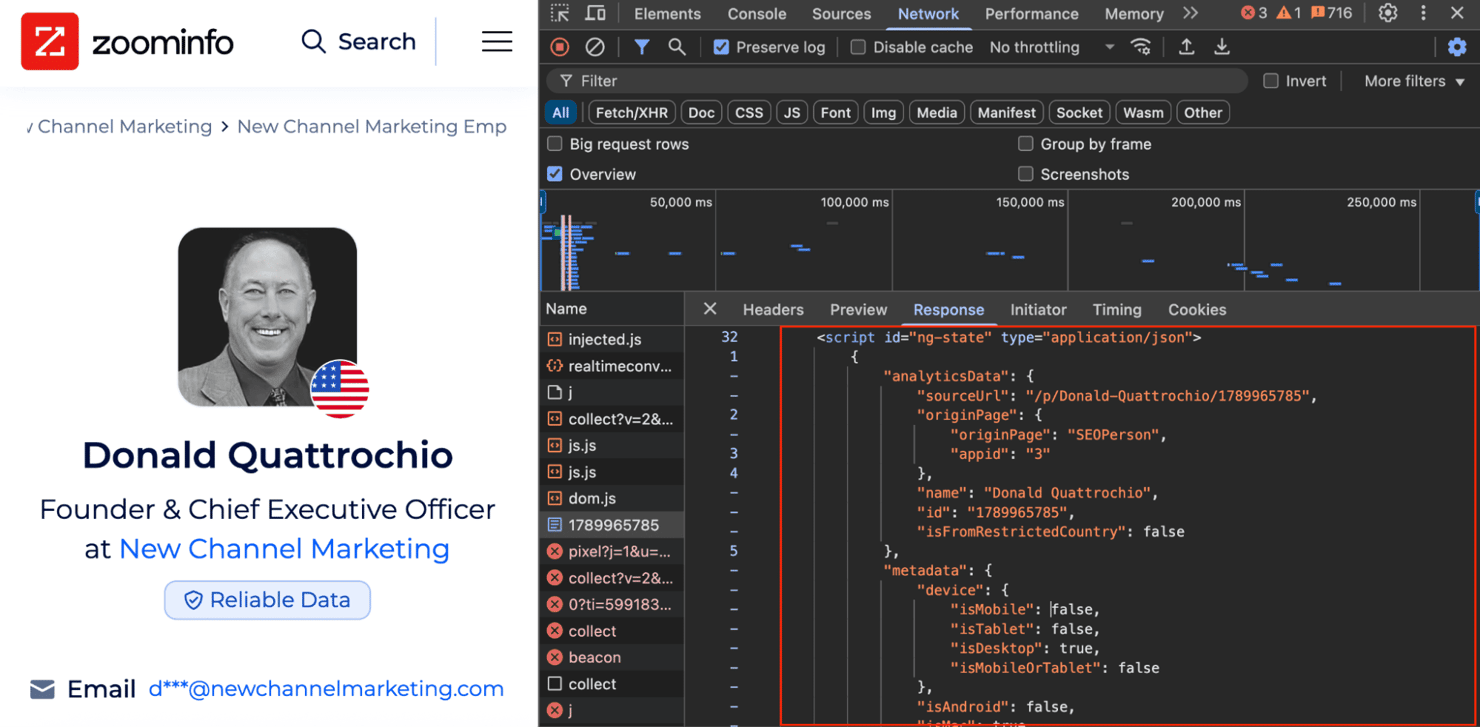
This includes job titles, tenure, verified contact information, social links, organizational chart relationships, and more.
The easier alternative – using scraper APIs
Building your scraper is powerful, but maintaining it at scale is a different story. You’ll need to juggle proxies, CAPTCHAs, fingerprinting, and breakage from even minor page structure changes.
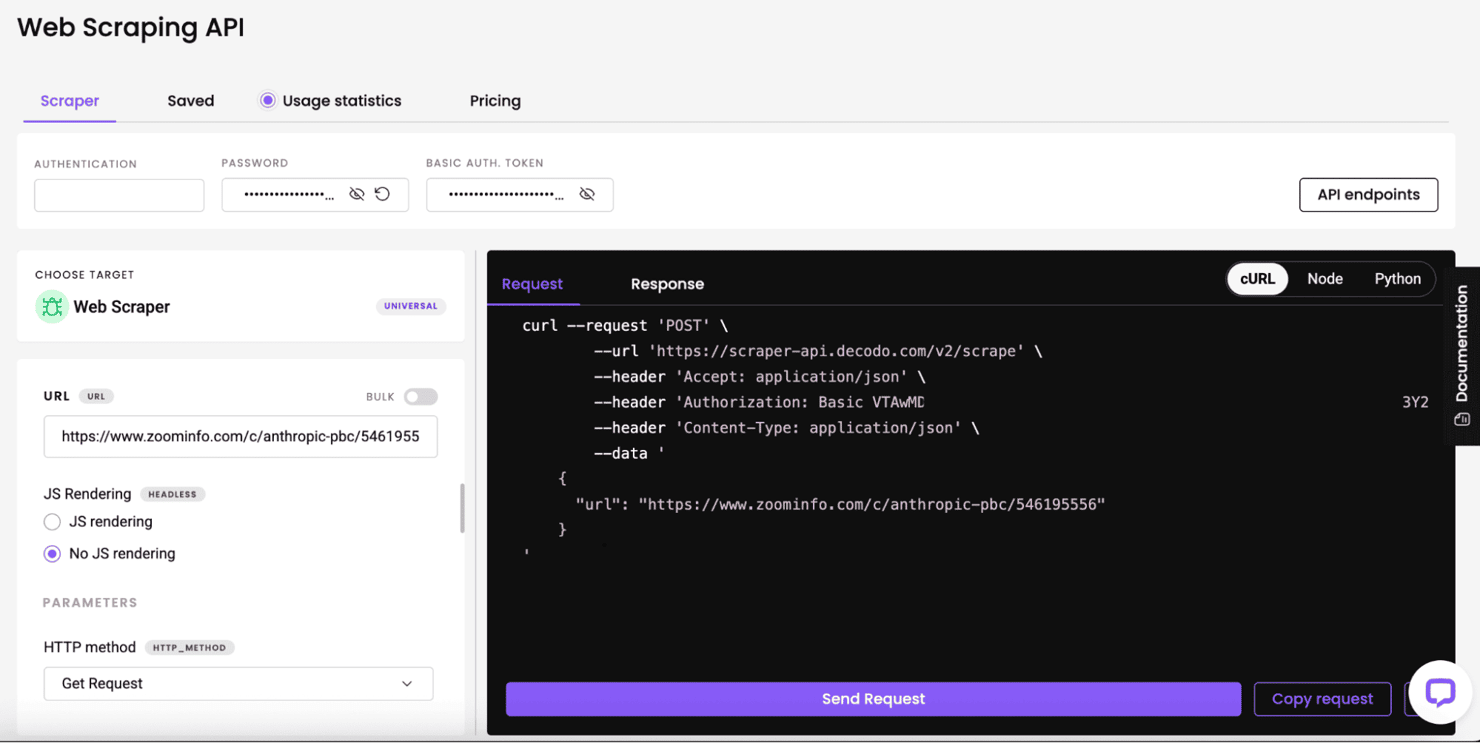
For reliable, low-maintenance ZoomInfo scraping, Web Scraping API is a smarter choice.
Decodo’s ZoomInfo Scraper API handles everything for you – proxy rotation, CAPTCHA-bypassing, JavaScript rendering, and fingerprint evasion – so you can focus on data, not infrastructure.
With Decodo, you send one POST request with your target URL, and the platform delivers the raw HTML or structured data. It’s that simple.
Key features:
- Automatic proxy rotation. 125M+ IPs to dodge bans and rotate locations.
- CAPTCHA-bypassing. No need to integrate third-party solvers.
- JavaScript rendering. Pages are rendered in a headless browser, so you get the final DOM.
- Pay-per-success. Only pay for successful requests.
- No infrastructure to manage. No proxies, browser farms, retries, or CAPTCHAs to deal with.
- Geo-targeting. Choose any country, state, or even city for precise results.
Every new user can claim a 7-day free trial, so you can test ZoomInfo scraping before committing.
Getting started with Decodo
Setting up takes just minutes:
- Create an account at dashboard.decodo.com.
- Select a plan under the Scraping APIs section – Core or Advanced.
- Start your trial – all plans come with a 7-day free trial.
- In the Scraper tab, select Web Scraper as the target.
- Paste your ZoomInfo company URLs.
- (Optional) Configure API parameters like JS rendering, headers, or geolocation.
- Hit Send Request, and you’ll get the HTML in seconds.
Here’s what the Decodo dashboard looks like when using the Web Scraping API:
View your raw HTML response in the Response tab. It’s that easy!
If you prefer coding, here’s how to use the API:
What’s happening:
- Define the scraping endpoint.
- Add the target URL to the payload.
- Set your headers with your API token.
- Send the request and save the HTML response.
Don’t forget to replace DECODO_AUTH_TOKEN with your actual token from the Decodo dashboard.
Optional – AI Parser
If you'd rather skip HTML parsing and selector implementation, try Decodo's AI Parser – extract structured data from any website without writing a single line of code.
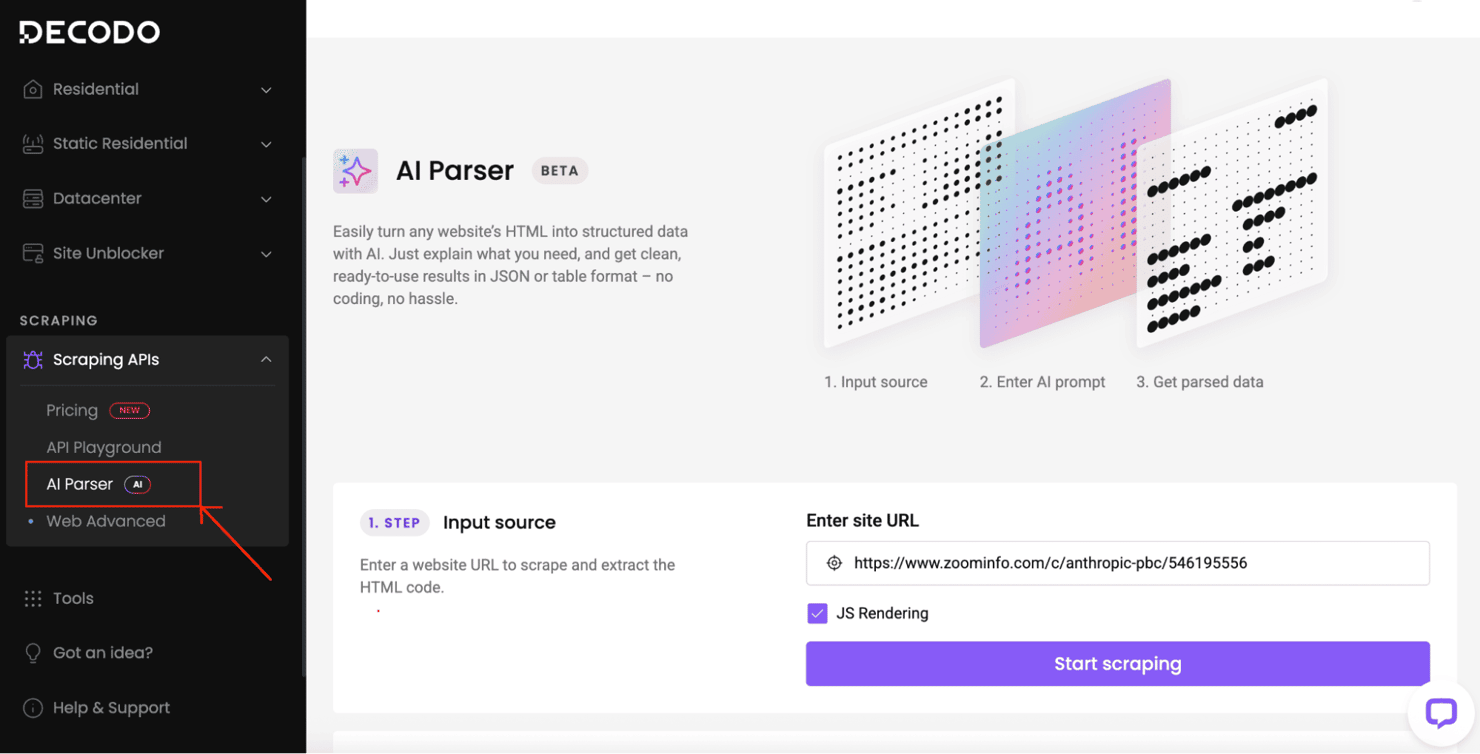
How to use the AI parser:
Step 1 – Input the source URL
Step 2 – Enter your AI prompt
Step 3 – Receive parsed data
That's it – no coding required. Just copy, paste, and get structured results in seconds.
For advanced use cases and code samples, see the web scraping API documentation. To learn how teams are cutting costs and scaling faster, watch our web scraping efficiency Webinar.
Conclusion
Scraping ZoomInfo can unlock powerful B2B insights, but it requires careful handling of its anti-bot protections. You’ll need rotating proxies, headless browsers, and smart handling of CAPTCHAs and rate limits just to keep your scraper alive.
Skip the maintenance headache with Decodo’s Zoominfo Scraper API. It auto-rotates proxies, solves CAPTCHAs, renders JavaScript, and retries failed requests – so you send a single request and get data back. Try it free for 7 days and see for yourself.
Start your free trial of Web Scraping API
Access structured data from ZoomInfo and other platforms with our full-stack tool, complete with ready-made scraping templates.
About the author

Justinas Tamasevicius
Director of Engineering
Justinas Tamaševičius is Director of Engineering with over two decades of expertise in software development. What started as a self-taught passion during his school years has evolved into a distinguished career spanning backend engineering, system architecture, and infrastructure development.
Connect with Justinas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.

