How to Scrape Google Finance
Google Finance is one of the most comprehensive financial data platforms, offering real-time stock prices, market analytics, and company insights. Scraping Google Finance provides access to valuable data streams that can transform your analysis capabilities. In this guide, we'll walk through building a robust Google Finance scraper using Python, handling anti-bot measures, and implementing best practices for reliable data extraction.
Dominykas Niaura
Last updated: Jun 25, 2025
10 min read
Why scrape Google Finance
Google Finance contains a wealth of financial information that's continuously updated throughout trading hours. By automating data collection from this platform, you can unlock insights that would be time-consuming or impossible to gather manually.
Market research and analysis
Scraping Google Finance allows you to track stock performance, analyze market trends, and gather comparative data across multiple securities. This data can power investment research, help identify emerging opportunities, or support academic studies on market behavior.
Portfolio management and tracking
Automated data collection enables real-time portfolio monitoring, performance tracking, and alert systems. You can build custom dashboards that aggregate data from multiple holdings and provide insights that aren't available through standard brokerage interfaces.
Financial application development
Developers can integrate Google Finance data into custom applications, trading algorithms, or financial tools. This includes everything from simple price trackers to sophisticated analytical platforms that require fresh, accurate market data.
Competitive intelligence
For businesses in the financial sector, monitoring competitor stock performance, analyst ratings, and market sentiment provides valuable competitive insights that can inform strategic decisions.
What data you can scrape from Google Finance
Google Finance pages contain rich financial information across multiple categories, making it a comprehensive source for market data extraction. Here are some of the most valuable data points you can scrape from this platform:
Real-time stock data
Current stock prices, percentage changes, trading volume, and market capitalization provide the foundation for most financial analysis. You can also extract 52-week high/low ranges, previous close prices, and intraday trading patterns.
Company fundamentals
Corporate information including company names, ticker symbols, primary exchanges, and basic metrics like P/E (price-to-earnings) ratios. Some listings also include employee counts, headquarters locations, and founding dates.
Financial statements and metrics
Revenue figures, operating expenses, net income, earnings per share, and EBITDA (Earnings Before Interest, Taxes, Depreciation and Amortization) data from recent financial reports. You can also access profit margins, tax rates, and other key performance indicators.
Market sentiment indicators
Price movement trends, analyst ratings where available, and related news articles that can provide context for stock performance and market sentiment.
Tools and libraries for Google Finance scraping
Now that you know the power behind Google Finance data, let’s talk about the process of gathering it with a custom scraping code. Building an effective Google Finance scraper requires the right combination of Python libraries and supporting tools.
Core Python libraries
The Requests library handles HTTP communication, while Beautiful Soup parses HTML content and extracts specific data elements. For faster and more accurate HTML parsing, it's recommended to use the lxml parser with Beautiful Soup. Together, these tools form the foundation of most web scraping projects and are sufficient for Google Finance’s primarily static content.
Data processing tools
Pandas provides powerful data manipulation capabilities for organizing and analyzing scraped results. The csv module enables easy export to spreadsheet formats, while the json module can handle structured data storage.
Advanced browser automation
For complex scenarios requiring JavaScript execution, Selenium or Playwright can simulate full browser environments. However, Google Finance's data is largely accessible through standard HTTP requests, making these tools optional for most use cases.
Proxy and session management
Reliable proxy services are essential for sustained scraping operations. Google Finance implements rate limiting and bot detection, making IP rotation and proper session management crucial for consistent data collection.
Setting up your environment
Before building your scraper, ensure you have the necessary tools and credentials configured properly.
Install required packages
Start by installing the essential Python libraries for web scraping and data handling in your terminal:
Configure proxy access
For reliable scraping, you'll need access to quality proxies. At Decodo, we offer residential proxies with a 99.92% success rate and response times under 0.6 seconds (the best in the market). Here's how to get started:
- Create an account on the Decodo dashboard.
- Navigate to Residential proxies and select a plan.
- In the Proxy setup tab, configure your location and session preferences.
- Copy your credentials for integration into your scraping script.
Prepare your development environment
Set up a Python development environment using your preferred IDE or text editor. Having browser developer tools available will help you inspect Google Finance pages and identify the correct elements to target.
Step-by-step Google Finance scraping tutorial
Let's build a comprehensive scraper that can extract detailed financial data from Google Finance pages. We’ll break this down into components, explaining each step and why it's necessary.
1. Import libraries and build the scraper class
The first block sets up all necessary imports and creates a scraper class. These libraries handle HTTP requests, HTML parsing, CSV export, and more. When initializing the GoogleFinanceScraper, you’ll need to input your proxy credentials (YOUR_USERNAME, YOUR_PASSWORD). This enables access through Decodo’s proxy gateway.
The session is configured with browser-like headers to reduce the chance of detection, and proxy setup is built-in for both HTTP and HTTPS requests.
2. Page fetching with error handling
Next, the get_page_content() method loads the target URL and includes error handling to raise alerts if the page fails to load. It also mimics human behavior by adding a small randomized delay between requests. This helps avoid getting flagged by Google’s anti-bot systems.
3. Data cleaning and standardization
The clean_number() method helps standardize various formats of numbers, dates, and symbols you might encounter on a Google Finance page. It ensures values like percentages, financial multipliers (M, B, T), and currencies are handled correctly for further processing or export.
4. CSS selector and contextual extraction
Two helper methods (extract_by_selector and find_p6k_value_by_context) offer flexibility when pulling data from the HTML:
- Use the CSS selector method when you know the structure.
- Use the context-based method when the page layout is dynamic – it looks for nearby keywords to locate the right value.
This dual approach is helpful because Google Finance’s layout isn’t always consistent.
5. Financial data extraction
extract_financial_data() zeroes in on core financial figures like revenue, net income, and EPS. It scans the table rows using keyword matching to locate the right cell, and then formats each value using the cleaner from earlier. This method handles different financial currencies and units as they appear on the site.
6. Main scraping function
The scrape_google_finance() method is where everything comes together. It:
- Fetches and parses the HTML
- Grabs the company name, price, market metrics, and other essentials
- Extracts info like CEO, HQ, and website
- Uses a fallback approach if some data isn’t found initially
- Merges in financial statement data
This is the method you’ll call when scraping a specific company. Be sure to replace the placeholder URL with your desired target.
7. Data display and export functions
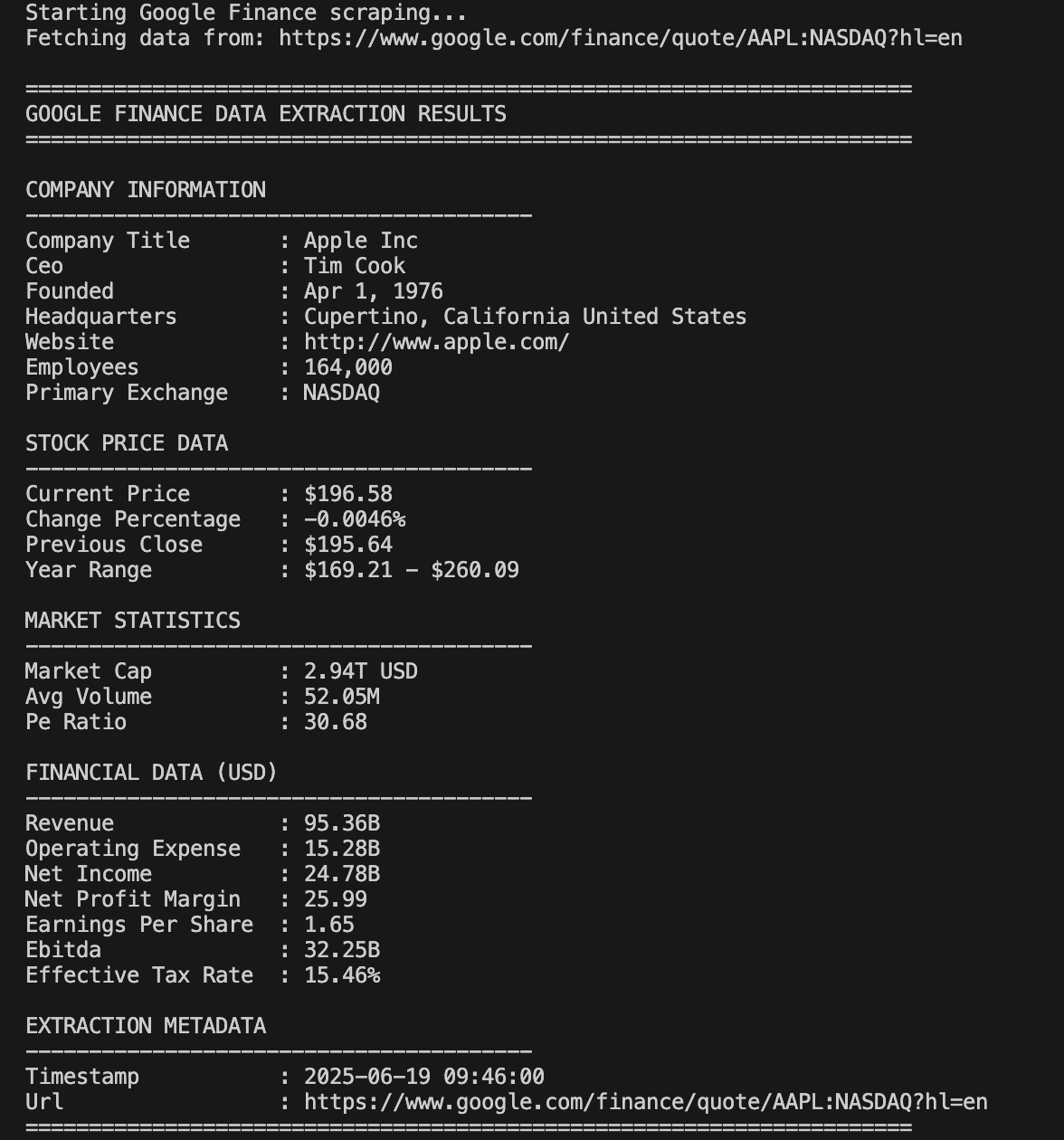
Once data is collected, the print_data method organizes it into logical sections for clarity. It’s a useful way to preview what was extracted.
The save_to_csv() method outputs the data to a CSV file. You can either save one company per file or extend it for batch mode.
8. Main execution function
In the main() function, you can either scrape a single company or loop through a list of company URLs. Rate limiting is included for batch mode to help avoid getting blocked.
The example here scrapes Apple’s Google Finance page. Swap in any other stock page by updating the URL. For multiple companies, just uncomment the list and loop sections.
The complete Google Finance scraping code
Here's the full implementation that brings together all the components we've discussed:
And here’s the response you’ll see in the terminal:
Handling challenges and anti-bot measures
Google Finance implements several protection mechanisms that scrapers must navigate carefully.
Rate limiting and request throttling
Google monitors request patterns and can temporarily block IPs that send too many requests in a short period. The scraper includes randomized delays between requests and exponential backoff for failed attempts to respect these limits.
Dynamic content loading
While most Google Finance data loads with the initial HTML, some elements may require JavaScript execution. For basic financial data, the static HTML approach works reliably, but more complex scenarios might benefit from browser automation tools.
IP-based blocking
Sustained scraping from a single IP address increases the likelihood of being blocked. Rotating through multiple proxy IPs helps distribute requests and maintain access over longer periods.
User agent and header detection
Google can detect non-browser requests through missing or inconsistent headers. The scraper includes comprehensive browser headers and uses common user agent strings to appear more like legitimate browser traffic.
Advanced scraping techniques
For more sophisticated data collection needs, several advanced techniques can improve scraper performance and reliability.
Session management and cookie handling
Maintaining consistent sessions across requests can improve success rates and reduce the likelihood of triggering anti-bot measures. The requests.Session object automatically handles cookies and connection pooling.
Multi-threaded data collection
When scraping large numbers of stocks, parallel processing can significantly reduce total execution time. However, this must be balanced against rate limiting requirements to avoid overwhelming the target server.
Error recovery and data validation
Robust scrapers include comprehensive error handling and data validation to ensure reliable operation even when encountering unexpected page structures or network issues.
Proxy rotation strategies
Advanced proxy management includes automatic rotation, health checking, and failover mechanisms to maintain consistent access even when individual proxy IPs become blocked.
Best practices for sustainable scraping
Following established best practices ensures your scraper operates reliably and respectfully over time.
Respect rate limits and implement delays
Always include appropriate delays between requests and avoid overwhelming target servers. Random delays help make request patterns appear more natural and reduce the likelihood of detection.
Monitor and adapt to page changes
Google occasionally updates its page structure, which can break scrapers that rely on specific CSS selectors or HTML patterns. Regular monitoring and testing help identify when updates are needed.
Handle errors gracefully
Network failures, rate limiting, and page structure changes are inevitable when scraping at scale. Building robust error handling and retry logic ensures your scraper can recover from temporary issues.
Store and rotate proxy credentials securely
Protect proxy credentials and API keys by storing them securely and rotating them regularly. This prevents unauthorized access and ensures continued service availability.
Alternatives to scraping Google Finance
Google no longer provides an official public API for Google Finance – the original one was deprecated years ago. While scraping remains a flexible way to access data, it's not always the most convenient or scalable option. Depending on your needs, third-party APIs might offer a more streamlined and reliable solution.
Official financial APIs
Services like Alpha Vantage, IEX Cloud, and Yahoo Finance offer structured APIs with reliable data access, though they often include usage limits and fees for comprehensive access.
Financial data providers
Professional services like Bloomberg Terminal, Refinitiv, and FactSet provide institutional-grade financial data with extensive historical records and real-time updates, though at significantly higher costs.
Broker APIs
Many online brokers offer APIs that provide account-specific data and limited market information, suitable for personal portfolio management but not broader market analysis.
To sum up
Scraping Google Finance can be a great way to unlock valuable insights for financial research, portfolio tracking, or just staying on top of the markets. With this Python-based scraper, you now have a flexible tool that can pull together over 20 key data points.
As long as you follow a few best practices (like rotating proxies, respecting rate limits, and handling errors gracefully), you’ll be well on your way to building scrapers that are both reliable and long-lasting. From automated reporting to custom dashboards, this setup offers a reliable starting point for working with financial data.
Access residential proxies now
Try residential proxies free for 3 days – full access, zero restrictions.
About the author

Dominykas Niaura
Technical Copywriter
Dominykas brings a unique blend of philosophical insight and technical expertise to his writing. Starting his career as a film critic and music industry copywriter, he's now an expert in making complex proxy and web scraping concepts accessible to everyone.
Connect with Dominykas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.