How to Bypass Google CAPTCHA: Expert Scraping Guide 2026
Scraping Google can quickly turn frustrating when you're repeatedly met with CAPTCHA challenges. Google's CAPTCHA system is notoriously advanced, but it’s not impossible to avoid. In this guide, we’ll explain how to bypass Google CAPTCHA verification reliably, why steering clear of Selenium is critical, and what tools and techniques actually work in 2026.
Dominykas Niaura
Last updated: Apr 08, 2026
10 min read
What are Google CAPTCHAs?
Google CAPTCHAs represent the evolution of Google's security infrastructure, designed to distinguish human users from automated bots. From the classic "I'm not a robot" checkbox to the more sophisticated image recognition tasks asking you to "select all traffic lights," these challenges have become ubiquitous across the site.
Google's CAPTCHA ecosystem includes several variants:
- reCAPTCHA v2. The familiar checkbox and image selection challenges.
- reCAPTCHA v3. Invisible behavioral analysis that scores user interactions.
- reCAPTCHA Enterprise. Advanced AI-powered risk analysis for high-security applications.
But here's what most people don't realize: Google CAPTCHAs aren't working as effectively as they used to. Advanced machine learning models now solve Google's image CAPTCHAs with up to 70% accuracy, and modern bypass techniques have evolved far beyond traditional solving methods.
Why does Google show CAPTCHAs?
Understanding what triggers Google CAPTCHAs is key to designing a more resilient bypass strategy. Most challenges are caused by one or more of the following:
1. IP reputation. Google tracks IP histories; therefore, shared datacenter IPs or reused proxy nodes with a history of scraping are frequently flagged.
2. Browser fingerprinting. Headless automation, missing plugins, or mismatched screen resolutions can mark your browser as suspicious.
3. Behavioral patterns. High-frequency requests, lack of interaction (e.g., scrolling/mouse movement), or cookie-less browsing are red flags.
4. Rate limiting. Sending too many requests in a short window will lead to CAPTCHAs or blocks, especially without session reuse.
5. Geographic factors. Requests from regions associated with bot traffic or proxies may trigger more frequent verification.
Why does a basic Python script trigger Google CAPTCHA?
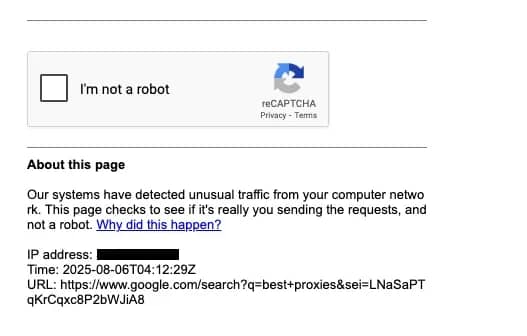
Before diving into advanced evasion strategies, let’s explore what happens when you don’t try to avoid detection at all. This naive Python script uses Selenium to perform a Google search. It doesn’t rotate proxy IPs, spoof fingerprints, or mimic user behavior. It’s designed to make one request and show you what happens.
To run the script, make sure you have Python 3.8+ installed. Then, install the required Selenium package by running the following command in your terminal:
Once the dependencies are installed, you can run the script below:
This approach lacks all the elements that make scraping resilient. Even a single request might trigger a CAPTCHA or a "Sorry, unusual traffic" message. The code above makes this obvious by printing:
- The page’s title
- A preview of the body contents
- Whether known CAPTCHA markers were detected
- A saved HTML dump and screenshot for manual inspection
Which Python library works best for each Google target?
At Decodo, we’ve worked with a wide range of Google scraping targets, and each one requires a slightly different approach. Here's a quick overview of what Python libraries have worked best for us across various Google websites:
- Google News – Playwright
- Google Scholar – Requests
- Google Reviews – Playwright
- Google Finance – Requests
As you can see, we didn’t rely on Selenium for any of these: either because it didn’t work reliably with Google, or because a lighter, more targeted approach got the job done more effectively.
Should you stop using Selenium?
Selenium is a widely-used browser automation tool for testing and scraping. Its popularity stems from ease of use, strong community support, and compatibility with major browsers like Chrome and Firefox. Many tutorials and scraping tools default to Selenium simply because it's so familiar.
However, Selenium is poorly suited for scraping Google’s targets. Google aggressively detects automation, and Selenium-controlled browsers are relatively easy to spot. Even with stealth plugins, these issues remain:
- WebDriver-specific properties like navigator.webdriver = true are visible to scripts
- Browser behavior lacks randomness and realism
- Fingerprints are not dynamically spoofed, making sessions predictable
Google Search, in particular, triggers CAPTCHAs after just a few Selenium-driven requests – even if you rotate IPs. That’s why it’s strongly advised to use alternatives like Playwright, which offers more advanced control over browser context and fingerprinting.
Playwright is a modern browser automation library developed by Microsoft. Unlike Selenium, it gives you low-level access to browser internals, making it easier to spoof fingerprints, control browser behavior, and emulate real user actions. It supports Chromium, Firefox, and WebKit, and is widely used for web scraping, testing, and automating complex browsing scenarios where stealth and reliability are key.
Is Chromium the right browser for bypassing Google CAPTCHAs?
While Chromium (used in Chrome and Edge) is heavily fingerprinted by Google, it’s not the wrong choice. In fact, using Chromium through Playwright often performs better than Firefox when configured properly. Therefore, we recommend this stack:
- Playwright + Chromium (with stealth fingerprint spoofing)
- Residential proxies (rotated regularly)
- Behavioral emulation (scrolling, mouse movement, delay timing)
Start with Playwright and Chromium, as it’s the most reliable setup for Google scraping. If you're still getting blocked despite solid stealth measures, that’s when experimenting with other browsers is a potential workaround.
Google CAPTCHA bypass methods for 2026
Google’s CAPTCHA challenges are getting smarter, so certain simple tricks (like switching away from Selenium) are far less effective on their own. Bypassing modern CAPTCHAs now requires a multi-layered approach. Below are the most effective avoidance methods currently used by professional scraping setups.
1. Advanced proxy rotation with residential IPs
Effective proxy management is the foundation of any CAPTCHA avoidance strategy. Leading scrapers rely on residential proxies that mimic real users’ IP behavior and rotate them intelligently to avoid detection. The most advanced systems integrate proxies from reliable providers. For best practices, consider these:
- Residential proxies. Employ residential proxies with clean reputations.
- IP rotation. Rotate IPs every 1-20 requests to prevent rate-limiting and detection.
- Geolocation adjustment. Match proxy locations with target content regions or user locales for legitimacy.
- Flagged IPs. Monitor for CAPTCHA triggers or failed responses and replace compromised addresses.
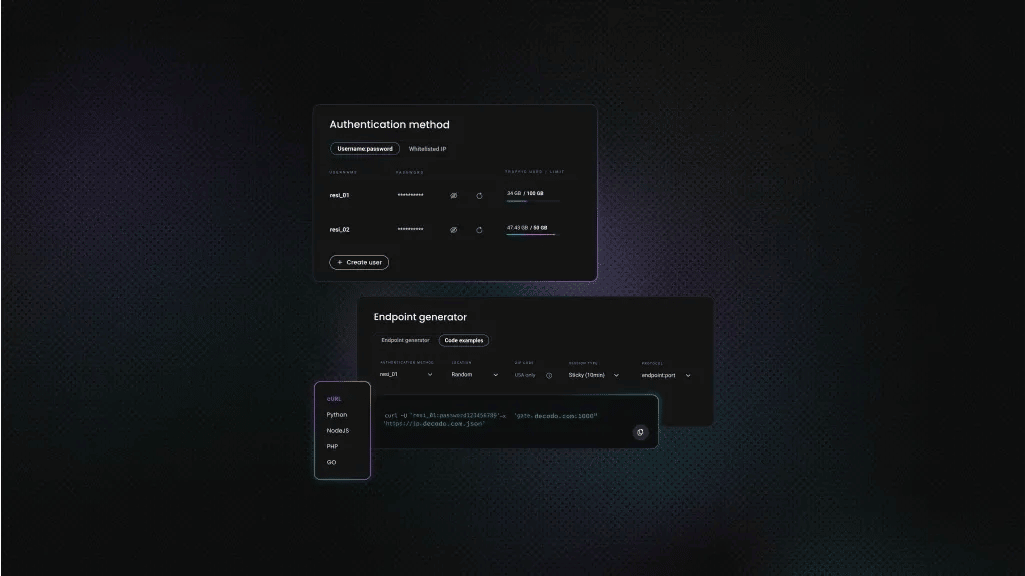
At Decodo, we offer residential proxies with a high success rate (99.92%), automatic rotation, a rapid response time (<0.5s), and extensive geo-targeting options (195+ worldwide locations). Here's how easy it is to get a plan and your proxy credentials:
- Head over to the Decodo dashboard and create an account.
- On the left panel, select Residential.
- Choose a subscription, Pay As You Go plan, or opt for a 3-day free trial.
- In the Proxy setup tab, choose the location, session type, and protocol according to your needs.
- Copy your proxy address, port, username, and password for later use. Alternatively, you can click the download icon in the lower right corner of the table to download the proxy endpoints (10 by default).
Get residential proxies for Google
Claim your 3-day free trial of residential proxies to collect Google data with full feature access.
2. Behavioral pattern mimicking
Modern bypass techniques focus more on analyzing user behavior and detecting environmental cues rather than relying on traditional cognitive tests. Your scraper should behave like a human user:
- Mouse movement simulation. Use curved, variable-speed movements rather than straight lines.
- Scroll patterns. Introduce natural scrolling with random speed and direction changes.
- Typing delays. Mimic human typing speeds, including occasional pauses and backspaces.
- Delays between requests. Implement a randomized waiting time of 2-8 seconds between interactions or navigation to avoid appearing robotic.
- Session persistence. Maintain cookies, headers, and local/session storage across requests to appear consistent.
3. JavaScript fingerprint manipulation
Many CAPTCHA triggers rely on JavaScript-based fingerprinting. Without mitigation, headless browsers and automation tools like Playwright or Puppeteer are easily detectable. Use fingerprint spoofing to reduce your browser’s uniqueness. Focus on:
- User agents & browser fingerprint rotation. Switch between user agent strings and spoof browser fingerprints to reduce traceability.
- Viewport randomization. Vary screen resolution and window sizes.
- Timezone spoofing. Align timezone data with proxy IP location.
- WebGL & canvas spoofing. Override or mask graphics fingerprinting outputs.
- Plugin & extension emulation. Simulate realistic browser plugin profiles.
4. CAPTCHA solving services
When avoidance fails, AI bots can solve CAPTCHA challenges with an accuracy ranging from 85% to 100%, compared to human success rates of 50% to 85%. Modern solving services integrate seamlessly with automation frameworks. Note these reCAPTCHA variants and bypass strategy:
- reCAPTCHA v2 (checkbox and image challenges). Can be solved using CAPTCHA-solving services, as it presents explicit challenges.
- reCAPTCHA v3 (score-based). Cannot be directly solved because it does not present a challenge. Instead, it assigns a risk score based on behavior, meaning the only viable strategy is avoidance – maintaining realistic browsing patterns, high-quality IPs, and session consistency to prevent low scores.
- reCAPTCHA Enterprise. Similar to v2 and v3 depending on implementation. Checkbox or challenge-based flows can be solved, while score-based implementations must be avoided rather than solved.
Here are some popular solving services:
- 2Captcha. Budget-friendly option that costs around $1.16 for 1,000 CAPTCHAs with support for reCAPTCHA v2, v3, and Enterprise.
- Anti-Captcha. Human-powered service with high accuracy rates and fast solving times.
- CapSolver. AI-powered service optimized for image-based and logic-based CAPTCHA types.
Complete Google CAPTCHA bypass Python script
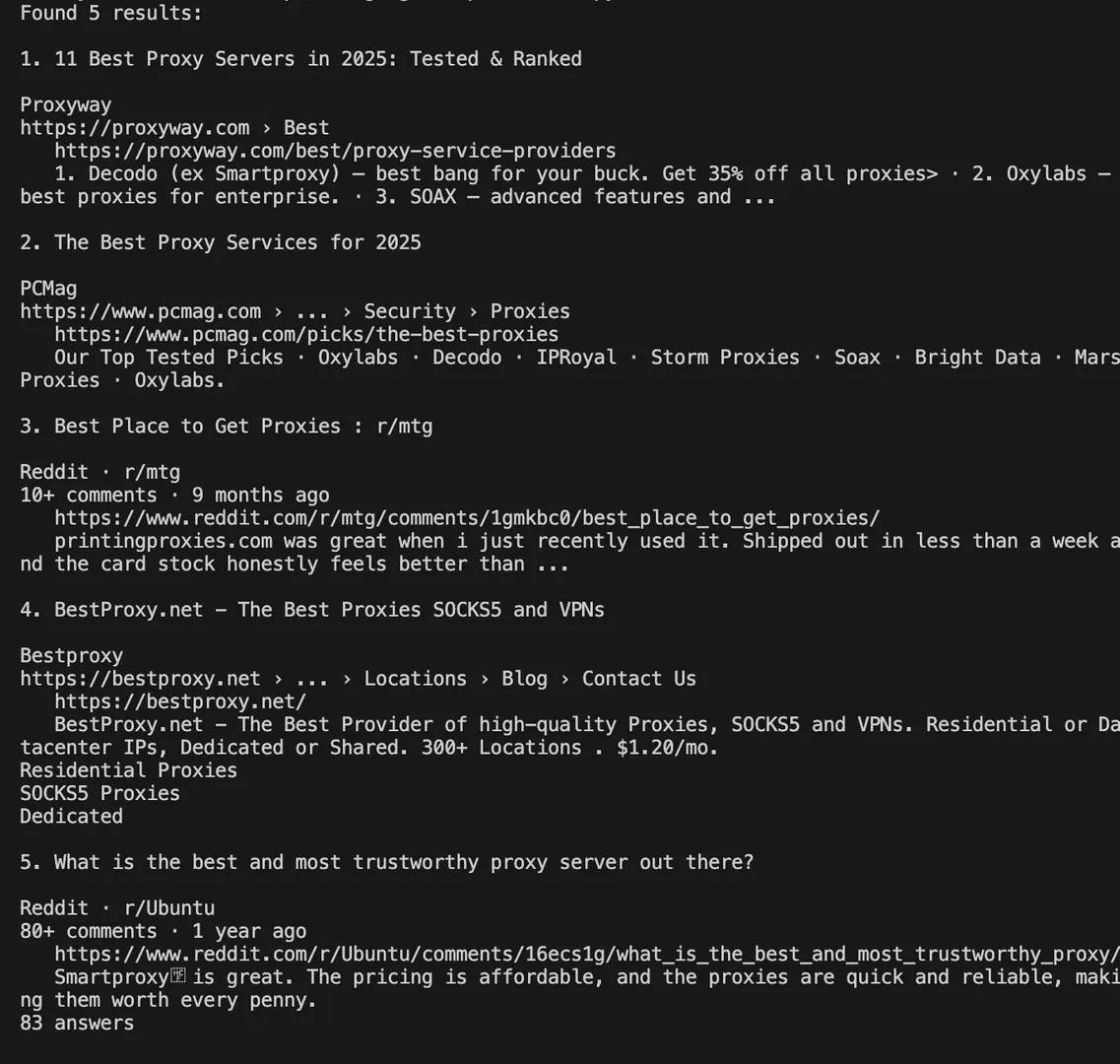
The following Playwright-based Python script demonstrates a scraping setup designed to minimize the risk of triggering Google CAPTCHAs. It uses Chromium via Playwright, simulates human-like behavior, rotates proxies, handles consent popups, and extracts structured results from Google Search. While still simplified, this setup outperforms basic scripts by reducing detectable bot traits and offering better compatibility with Google’s anti-bot systems.
If you already have Python installed, then install the required Playwright package by running the following commands in your terminal:
Next, enter your proxy credentials and target search URL in the code below. This script provides a reliable starting point for scraping Google with minimal CAPTCHA interruptions.
This script uses:
- Playwright with Chromium, not headless by default
- Residential proxies, configured with authentication
- Human-like typing, scrolling, and mouse movement
- Fingerprint spoofing techniques, like overriding navigator.webdriver
- Fallback logic for locating the search input and parsing result blocks
If you'd rather skip the setup entirely, Decodo's SERP Scraping API handles proxy rotation, fingerprint spoofing, and CAPTCHA avoidance automatically – returning structured Google Search data with a single API call.
In any case, for advanced use, you’d still want to add:
- Full session persistence (cookies, local storage)
- More granular fingerprint spoofing (canvas, WebGL, AudioContext)
- Retry and error logging mechanisms
How is Google replacing CAPTCHAs with invisible verification?
As Google continues evolving its bot protection systems, traditional challenge-response CAPTCHAs are being replaced with smarter, invisible defenses.
Over 50% of iOS device requests now rely on Private Access Tokens (PATs) – a cryptographic proof of legitimacy issued by the device, not the user. These tokens signal a shift toward hardware-level authentication, where behavioral patterns and device trustworthiness matter more than IP addresses or solving puzzles.
What this means for scrapers:
- Device fingerprinting and browser context spoofing are now critical.
- Session emulation must mimic real user flow – including cookies, local storage, and navigation timing.
- Invisible CAPTCHAs can still detect and respond to suspicious interaction patterns – even without a visual prompt.
While invisible verification is rising, many sites (especially older or custom implementations) still fall back on traditional reCAPTCHA v2/v3. In these cases, browser automation tools like Playwright remain highly useful.
Playwright supports advanced stealth techniques such as fingerprint injection, browser context isolation, and full session persistence – all essential for bypassing both visible and invisible verification layers in a modern scraping workflow.
When Google CAPTCHAs don’t work properly
In some cases, CAPTCHAs may fail to load or function entirely – and the problem may be on your side. Common causes include:
- JavaScript disabled. Google’s reCAPTCHA requires JS to render and verify.
- Outdated browser. Some automation tools use old browser versions that fail to display CAPTCHAs correctly.
- Proxy or VPN interference. Misconfigured proxies can block JavaScript or serve expired tokens.
- Server-side errors. Google’s CAPTCHA servers may occasionally fail to deliver challenges.
Always test suspicious cases with a normal browser and proxy. If it loads there but not via automation, the issue is likely your setup.
Get the Latest AI News, Features, and Deals First
Get updates that matter – product releases, special offers, great reads, and early access to new features delivered right to your inbox.
"Google CAPTCHA triggered. No bypass available": what it means
The dreaded "Google CAPTCHA triggered. No bypass available" message, particularly common in open-source tools like recon-ng, or after repeated failures from the same IP/browser combo. Here’s what triggers it:
- Repeated fingerprint failures. Your automation has been definitively identified as non-human behavior.
- Blacklisted IPs. Datacenter or abused proxy IPs end up on Google's restricted list.
- Strong detection signals. Too many concurrent or failed CAPTCHA attempts have been caught by Google’s sophisticated behavioral analysis.
Try these solution strategies to recover:
- Change infrastructure entirely. New IP, new browser context, cleared cookies.
- Space out requests. Implement longer delays (even hours apart) between batches.
- Use residential proxies. Clean IPs and diverse geolocations help you avoid detection.
- Use hybrid approaches. Combine manual and automated workflows where possible.
Best practices for bypassing a Google CAPTCHA
Avoiding CAPTCHAs isn’t just about technical workarounds – it also requires responsible scraping behavior and strategic implementation choices. Below are key best practices to help you maintain access and reduce friction when collecting data from Google and other protected services.
What are the compliance rules for scraping Google?
Maintaining ethical and respectful scraping practices helps reduce the risk of getting blocked or banned, and improves the long-term stability of your scraping setup.
- Respect robots.txt and terms of service. Before scraping any domain, check its robots.txt file and review its TOS. Some websites explicitly disallow automated access to specific routes, and ignoring these rules can result in IP bans or legal actions.
- Target only public data. Make sure the information you're collecting is publicly accessible without login or paywalls. Scraping behind authentication or protected endpoints raises both technical and ethical concerns.
- Avoid aggressive scraping of small or resource-limited sites. Frequent or concurrent requests can overload servers, especially for low-traffic websites. If you're scraping smaller properties, use conservative request patterns.
- Attribute content when required. If your use case involves republishing or reusing content (e.g. reviews, product data), ensure you provide proper attribution in accordance with copyright or licensing terms.
How do you implement Google scraping without triggering CAPTCHAs?
Beyond ethical compliance, solid technical design is critical for avoiding detection and maximizing success rates.
- Throttle your requests. Limiting your request rate to around 1 request per second (or slower for sensitive targets like Google) reduces the chance of triggering rate limits or behavioral flags.
- Use exponential backoff for failed requests. If a request fails due to a CAPTCHA or timeout, wait longer before retrying. Use strategies like exponential backoff to space out retries more naturally.
- Monitor HTTP status codes. Track responses for status codes like 403 (forbidden), 429 (too many requests), or redirects to CAPTCHA challenges. This helps you adapt your strategy in real time.
- Maintain detailed logs. Log key data points such as user agents, proxy IPs, session IDs, and timestamps. This makes it easier to troubleshoot issues and refine your anti-detection logic.
When to use paid CAPTCHA solving services
Despite best efforts, some scraping operations will inevitably encounter CAPTCHAs, especially at scale. In such cases, automated CAPTCHA-solving services offer a way to continue data collection without manual intervention. Consider professional solutions if:
- Your success rate drops below acceptable thresholds. If you're seeing consistent failures or incomplete sessions due to unsolved CAPTCHAs, it may be more efficient to solve than avoid them.
- You need large-scale, unattended automation. If your workflow needs to run continuously or across many threads, manual solving becomes impractical. Automation is essential for scaling.
- You need to solve difficult image or audio CAPTCHAs. Advanced CAPTCHA formats that can't be skipped with behavioral spoofing may require OCR or AI-powered solving.
- You need SLAs or performance guarantees. Paid providers typically offer uptime guarantees, API dashboards, and priority support, which is useful for production environments or client-facing tools.
How to bypass Google CAPTCHA – key takeaways
Bypassing Google CAPTCHAs in 2026 requires a multi-layered approach combining browser optimization, behavioral mimicking, and advanced proxy management. Avoiding Selenium when scraping Google targets can dramatically improve your success rate. While Selenium is a popular choice for automation, it exposes detectable traits that Google easily flags, especially when compared to more stealth-capable tools like Playwright.
Learning how to bypass Google CAPTCHA verification isn't about solving the puzzles – it's about avoiding them entirely through smart automation techniques. Don’t forget to strengthen your Google CAPTCHA avoidance implementations with Decodo’s high-performance residential proxies.
About the author

Dominykas Niaura
Technical Copywriter
Dominykas brings a unique blend of philosophical insight and technical expertise to his writing. Starting his career as a film critic and music industry copywriter, he's now an expert in making complex proxy and web scraping concepts accessible to everyone.
Connect with Dominykas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.