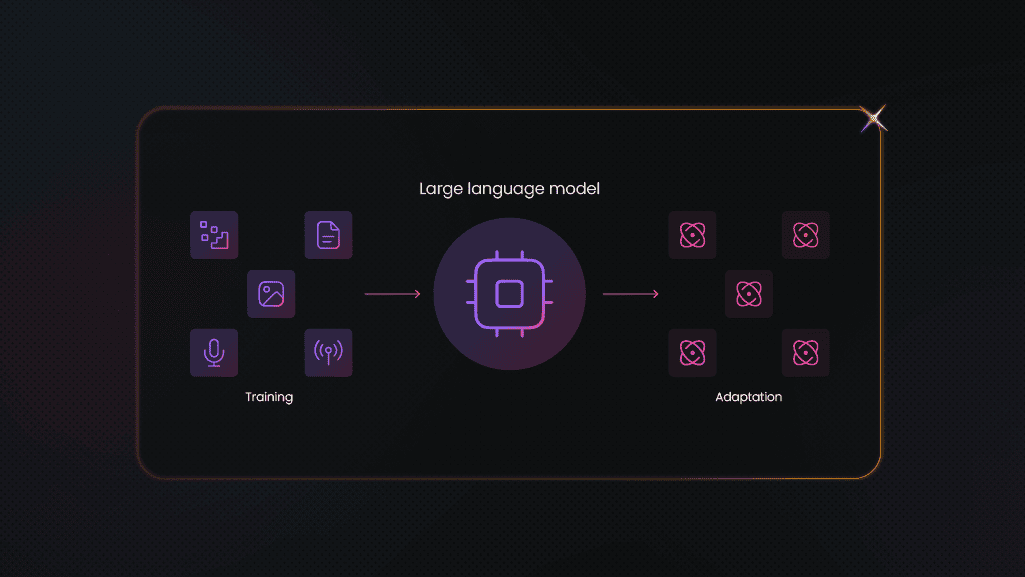
How to Build an LLM: Key Steps, Challenges, and Best Practices
Building an LLM from scratch in 2026? It's totally doable if you know what you're doing. This guide covers everything – from architecture, training, fine-tuning, and deployment to tips on how to handle the tricky parts. You'll walk away with a clear plan and best practices for building your own high-performing large language model.
Mykolas Juodis
Last updated: Sep 23, 2025
5 min read
Define your use case and objectives
Before you dive into the technical details of how to build an LLM, you need to start with the why.
The most successful LLM projects start with crystal-clear objectives that generic models can't address. Your specialized use case is exactly why you should be building your own model rather than settling for one-size-fits-all solutions.
Smart teams start with brutal honesty about what they're actually trying to accomplish:
- Is it a friendly support copilot that answers account questions in under a second?
- Is it a research assistant that can read long PDFs and reason across them?
- Is it a niche expert that understands medical shorthand or legal clauses?
Your specific use case then sets the size of everything else, because when you want to build your own LLM, bigger isn't always better – bigger is just heavier.
If you need deep reasoning, long context, or multilingual output, you'll likely need larger models, more training data, and beefier GPUs. For focused tasks like classifying tickets or summarizing documents with known formats, smaller models with clean, domain-specific datasets can be faster, cheaper, and easier to deploy.
In short, ambiguous goals mean more parameters, more data, more computing power. Tight, well-defined goals result in leaner models, simpler infrastructure, and ultimately lower costs.
A key point to consider when building your own LLM is whether you need to build it from scratch or adapt an existing LLM to meet your specific needs. Training from scratch gives you full control over data provenance, privacy, licensing, and architecture. That's useful if you have strict compliance needs, a very specific domain, or long-term IP goals, but most teams move faster by fine-tuning a strong base model and shaping it with their own examples. Ensure you pick the path that matches your constraints, not your curiosity.
Once you've determined your use case, the next step is to design your model architecture.
Designing the model architecture
Modern LLMs are built on the Transformer, a neural architecture that has ditched recurrence in favor of attention.
The transformer architecture provides the perfect foundation for building powerful domain-specific models, and recent innovations make custom development more efficient than ever.
The Transformer architecture is akin to a simple set of blocks that you can stack and tailor to your specific domain. Understanding each component helps you optimize for your specific use case:
- Embedding layers. Convert tokens into dense vector representations that capture semantic meaning. It can be specialized for your domain's vocabulary, enabling the model to understand industry-specific terminology and concepts that generic models may overlook.
- Positional encoding. This handles your typical input lengths and sequence structures. Modern implementations utilize Rotary Positional Encoding (RoPE), which enables better length generalization, allowing models to process longer documents than those for which they were trained.
- Self-attention mechanisms. This layer is designed to learn the relationships that matter most in your data. Multi-Head Attention performs parallel computations, focusing on different types of domain-specific patterns, such as syntactic structures in legal documents or diagnostic relationships in medical records.
- Feed-forward layers. Handles domain-specific reasoning patterns through position-wise neural networks. These layers provide the computational capacity for sophisticated pattern recognition specific to your problem space.
- Normalization layers. Ensure stable training on your specialized datasets by normalizing activations and preventing gradient problems that could derail training on domain-specific data distributions.
- Residual connections. Enable the training of deep networks by allowing gradients to flow directly through skip connections, which is essential for building sophisticated models that can capture complex domain relationships.
You can arrange these layers as you like to build either a decoder-only stack (used by most chat/coding models because it's simpler and great for next-token generation) or an encoder–decoder stack (great when you must read an input and produce a tightly aligned output, e.g., translation, structured summarization).
Framework choice accelerates development significantly. PyTorch dominates with over 1 million model implementations on Hugging Face, providing battle-tested code through the ecosystem (Transformers, Accelerate, DeepSpeed, PyTorch Lightning). TensorFlow and JAX are also strong alternatives, especially if you want XLA, TPU support, or specific compiler paths.
Your framework choice determines the implementation of distributed training, mixed precision, checkpointing, and export for efficient inference.
Once you're done designing the model, it's time to assemble it.
Assembling the model: encoder and decoder
Once you've determined your architectural components, you need to transform those building blocks into a functioning model that can actually learn something useful.
At build time, you create reusable layer blocks and stack copies of them. Transformers utilize encoder and decoder layers, which are nearly identical twins with crucial differences.
Encoder layers apply bidirectional self-attention (every token sees every other token) followed by feed-forward networks. Residual connections and normalization are applied at each step. Stack N layers to create a contextual understanding of your input.
Decoder layers, on the other hand, utilize masked self-attention (where tokens only see previous tokens) in conjunction with cross-attention to encoder outputs. This prevents "cheating" during training while accessing the relevant input context for generation.
Functionally, the encoder's job is to understand, while the decoder's job is to generate. Your architecture choice depends on your use case:
- Decoder-only (GPT): Best for text generation.
- Encoder-only (BERT): Better for understanding tasks.
- Encoder-decoder (T5): Handles translation and summarization.
For domain-specific applications, decoder-only architectures provide the best balance of generation quality and training efficiency. They're ideal for producing coherent, contextual outputs in specialized domains, such as legal contracts, medical diagnoses, or financial reports.
For strict input-to-output tasks, such as translation, structured summarization, and form-to-text, the classic encoder–decoder layout remains the better fit.
Data collection and curation
Great models come from great data. If the data used to build your own LLM is noisy, biased, or too narrow, your LLM will learn those flaws and amplify them.
To get good data for your LLMs, you can focus on three pillars:
- High quality
- High diversity
- High relevance
Remember, you want clean text, balanced sources and formats, and comprehensive coverage of the tasks your model will actually perform in production.
Your domain expertise data guides intelligent data curation, which maximizes model performance. Legal teams curate court documents and contracts, medical teams gather clinical notes and research papers, and financial teams collect market data and trading records. This specialized data creates competitive advantages that generic models can't replicate.
Building your data foundation requires three complementary sources:
- Public datasets that provide breadth and foundational knowledge, including encyclopedic text, books, forums, code repositories, and Q&A platforms that give your model a common understanding to build upon.
- Private datasets that inject your domain's unique voice and edge cases. This includes internal wikis, technical manuals, support tickets, chat transcripts, and knowledge bases that contain the specialized knowledge that distinguishes your model from generic alternatives.
- Web-sourced data fills coverage gaps and keeps your model current with evolving domain knowledge.
This is where most teams hit their first major roadblock. Effective web scraping requires handling proxy rotation, CAPTCHA solving, rate limiting, and JavaScript rendering, all while respecting robots.txt and terms of service. All of these present significant technical and compliance challenges that can derail many projects, but fortunately, you can simply use Decodo.
Instead of building fragile scrapers, you can use Decodo's Web Scraping API to pull clean, structured data at scale, complete with proxy rotation, anti-bot/CAPTCHA handling, and JavaScript rendering. Point it at your target sources, stream results to object storage, and plug them directly into a curation pipeline.
Decodo's workflow makes it straightforward to add PII redaction, toxicity filtering, and format normalization. This way, the data that you train your LLM with is high-signal, compliant text, not boilerplate and banners.
After getting the data, you need effective curation to transform raw content into training-ready datasets. This requires a systematic process that includes:
- Normalization and cleaning. Unicode fixes, consistent formatting, boilerplate removal, HTML stripping, and whitespace standardization create uniform input quality.
- Quality filtering. Language detection, safety screens, PII redaction, and domain-specific quality scoring using smaller models remove low-value content.
- Deduplication at multiple levels. Exact matching through content hashes, near-duplicate detection via MinHash/SimHash algorithms, and document-level canonicalization prevent training inefficiencies and phrase repetition, ensuring accurate results.
Evaluation planning must also happen from day one, so ensure you create clean train/validation/test splits that prevent data leakage through document-level boundaries. For time-sensitive domains, use chronological splits that train on historical data and test on recent examples.
For domain-specific LLMs, continuous data collection becomes an operational necessity as industry publications change, regulations update, and new research emerges. Decodo's ready-to-scale infrastructure provides reliable monitoring for content changes, automated collection from specialized sources, and seamless integration with your existing data pipelines.
Collect data faster with Web Scraping API
Build your LLMs faster with real-time data from any website online. Get started with a 7-day free trial and 1K requests.
Train your LLM
Training your custom LLM means turning a basic model into something that actually gets your specific domain. It's basically a cycle of guessing, checking, and fixing.
Here's how it works – your model takes some input, tries to predict what comes next, then sees how wrong it was and adjusts. This happens through forward and backward passes - first pushing data through the model, then flowing error signals back to tweak billions of parameters at once.
Common training challenges and how to fix them
Just like with any other AI-related process, training an LLM comes with its unique set of challenges:
- Underfitting. Underfitting indicates that your model lacks the capacity to learn the patterns in your domain. You'll notice that training loss plateaus at high values and exhibits poor performance on both the training and validation sets. You can fix this issue by scaling up your architecture, enhancing data quality, extending training duration, or increasing learning rates.
- Overfitting. Overfitting occurs when your model memorizes training examples rather than learning generalizable patterns. The telltale sign is diverging loss curves, where the training loss decreases while the validation loss increases. To combat this, utilize regularization techniques, dropout layers, early stopping when validation performance peaks, and ensure a diverse set of training examples.
- Training instability. Training instability can destroy weeks of progress through gradient explosions, loss spikes, or performance drops. Prevent instability through gradient clipping, learning rate schedules that reduce rates over time, mixed precision training for numerical stability, and frequent checkpointing so you can recover from failures.
Advanced training techniques and optimization
While the basic training techniques above are solid, more sophisticated optimization techniques can transform good domain-specific models into production-ready systems that deliver real business value.
- Parallelization methods, for example, distribute computational work across multiple GPUs to make larger models actually feasible.
- Data parallelism splits training examples across different devices, while tensor parallelism divides individual operations between GPUs. Pipeline parallelism processes different model stages sequentially across hardware, and model parallelism combines all these approaches for models that exceed 100B parameters.
Each method trades communication overhead for increased capacity, with the optimal choice really depending on your model size and what kind of hardware interconnects you have available.
- Hyperparameter tuning focuses on several key areas – batch size (larger batches provide more stability but may converge to suboptimal solutions), learning rate (domain-specific training typically benefits from warmup periods followed by cosine decay), and temperature (lower values like 0.1-0.7 produce more focused outputs for professional applications).
- Gradient checkpointing is a totally different technique that trades computation time for memory by recomputing activations during backward propagation, rather than storing them all in memory. This technique reduces memory requirements by 30-50% while increasing training time by 20-30%, allowing you to train larger models on the same hardware setup.
For domain-specific models that are really pushing hardware limits, this trade-off often favors model capacity over raw training speed.
Fine-tuning for specific tasks
If you don't want to train your LLM completely from scratch, you can fine-tune it to adapt to specific tasks and domains instead.
Fine-tuning is basically a form of transfer learning that takes a pre-trained model and continues training it on your specific dataset, adapting the existing knowledge for specialized tasks. Rather than starting from absolute zero, you leverage all the language understanding that was already learned during pre-training and refine it for your particular domain.
It's like hiring an experienced professional and training them on your company's specific procedures – way more efficient than educating someone from complete scratch.
There are two main approaches to fine-tuning:
- Full fine-tuning. This updates all model weights across the board. It usually delivers the highest possible ceiling on task performance, but it's compute-heavy, slower, and riskier if your dataset is small (you can easily overfit or "forget" general skills).
- Parameter-efficient fine-tuning (PEFT). Often called partial fine-tuning, this approach keeps the base model frozen and trains just a small number of additional advanced parameters (like LoRA/adapters or prompt/IA³ tuning ). PEFT is fast, cheap, and easy to iterate on, and you can maintain multiple task-specific adapters on a single base model without duplicating all the full weights.
Choosing when and how to fine-tune really depends on how far your domain is from the original pre-training data and what your resource constraints look like. You should fine-tune when you have specialized terminology, unique output formats, domain-specific reasoning patterns, or need to reduce inference costs for high-volume applications.
Evaluate and benchmark your LLM
Separate evaluation datasets are absolutely critical for understanding your model's real-world performance.
Your evaluation data must remain completely isolated from training – never seen during development, parameter tuning, or any part of the training process whatsoever. This separation prevents data leakage that would give you falsely optimistic performance metrics that don't reflect reality.
You need to make sure you create evaluation sets from different time periods, sources, or domains than your training data to ensure your model can handle genuine production scenarios rather than just memorized examples.
Use a mix of targeted benchmarks to cover different skills:
- ARC uses basically quiz questions that test whether AI can reason through basic scientific concepts and common knowledge.
- HellaSwag tests if AI has common sense by asking it to pick what would logically happen next in everyday situations that most people would understand.
- MMLU is a massive knowledge test covering 57 different subjects. Everything from basic math to advanced law and computer science topics.
- TruthfulQA checks if AI gives honest answers instead of just sounding confident while being totally wrong, especially on topics people commonly get confused about.
- GSM8K help with real-world math problems that require working through multiple steps to actually solve them correctly.
- HumanEval tests if AI can actually write working Python code by giving it function descriptions and seeing if the generated code passes automated tests.
- MT-Bench is a conversational AI benchmark that tests how well models handle multi-turn conversations across different categories like writing, reasoning, and coding.
Remember, benchmark scores are just a starting point, not the finish line. Interpreting results and iterating on improvements requires understanding both statistical significance and practical relevance to your use case. A 2% improvement on MMLU might be statistically significant but practically meaningless if it doesn't translate to better user experiences in your application. Focus on metrics that actually correlate with your real use case rather than chasing benchmark leaderboard positions for bragging rights.
Deployment risks
Getting an LLM ready for production is as much systems work as it is machine learning modeling.
Start by optimizing the artifact you'll actually serve. Export a stable checkpoint, lock down tokenizer and versioning, and profile inference performance thoroughly. Reduce latency and memory usage with quantization techniques (like 8-bit/4-bit), KV-cache reuse strategies, and (if needed) distillation into a smaller model that still meets your SLA requirements.
You should also wrap the model behind a predictable API, enforce strict request/response schemas, add sensible input/output size limits, and build in graceful timeouts and retry mechanisms. If your use case is knowledge-sensitive, definitely consider retrieval augmentation to keep answers fresh without requiring constant expensive retraining.
Finally, design for scale from day one. Scalability planning means anticipating varying demand patterns and growth in usage over time. Implement auto-scaling strategies based on request volume, load balancing across multiple model instances, and caching mechanisms for frequently requested outputs that don't change much.
Plan storage requirements carefully, including high-speed access for model weights, efficient prompt caching systems, and distributed systems architecture for handling lots of concurrent users without everything falling over.
To wrap up
Building an LLM breaks down into a pretty straightforward process. You figure out what you need it for, pick a Transformer architecture, get your tech stack together, and collect good training data. Then you train it with proper hardware, fine-tune for your specific stuff, test it honestly, and deploy it right. Keep tweaking until it works well enough for what you're doing.
Whether you build from scratch or just fine-tune depends on what data you have and what you're trying to do. Companies that actually succeed with custom LLMs have unique data that gives them an edge and solid systems to keep everything running smoothly.
Collect data from any website
Power up your LLMs with real-time data – get started today with 7-day free trial.
About the author

Mykolas Juodis
Head of Marketing
Mykolas is a seasoned digital marketing professional with over a decade of experience, currently leading Marketing department in the web data gathering industry. His extensive background in digital marketing, combined with his deep understanding of proxies and web scraping technologies, allows him to bridge the gap between technical solutions and practical business applications.
Connect with Mykolas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.