How to Scrape All Text From a Website: Methods, Tools, and Best Practices
Bulk text extraction has become an inseparable part of modern-day existence, with real-world cases including building datasets for LLM training, archiving, content analysis, and RAG systems. However, extracting all text is far more complex than scraping a single page, so we’ve prepared a step-by-step guide to discover pages, extract clean text, remove unnecessary elements, and export structured datasets into proper formats. The tools we use are Python, Beautiful Soup, Playwright, and Decodo proxies.
Mykolas Juodis
Last updated: Apr 15, 2026
8 min read

TL;DR
- Text scraping includes discovering URLs (crawling), extracting content (scraping), cleaning noise, and storing data in proper formats.
- We can use Requests and Beautiful Soup to scrape static pages and browser tools like Playwright for JavaScript-rendered pages.
- Clean text extraction includes identifying the main content and removing noise, including scripts, ads, and navigation elements.
- Use rotating residential proxies to scale scraping and avoid CAPTCHAs, bans, and request throttling.
- To ensure quality and usability of our scraped data, we utilize UTF-8, deduplication, text/whitespace normalization, and storing metadata.
Prepare your environment
First things first, we’ll prepare our development environment, and Python will be our best friend here, because it comes with libraries that will make getting all the content we want a breeze. While there are several popular libraries we can utilize, such as Scrapy, we’ll focus on Beautiful Soup, which makes the extracted data nicely structured and readable. We’ll want to put our proxies to use as well, particularly rotating IPs, like Decodo's residential proxies, in order to avoid rate limits and geo-restrictions that will seek to prevent us from collecting data at scale.
How to use Python
Python is simple, flexible, and versatile, which has made it the most popular programming language for web scraping. For our purposes, we’ll install Python 3.9 or later, then set up a virtual environment to separate different projects’ dependencies. We can create as many of these environments as we need. We’ll just run the venv module from Python’s library in a directory we want it to reside in, using the directory path: python -m venv decodo-env. This new decodo-env directory will contain the necessary Python files for our virtual environment. Then, we activate it in the terminal:
- Windows: decodo-env\Scripts\activate
- MacOS, Unix: source decodo-env/bin/activate
- Type deactivate to deactivate a virtual environment.
Next up, we’ll run pip install requests beautifulsoup4 lxml playwright python-dotenv. Let’s briefly overview why these tools are needed:
- requests: sends HTTP requests to grab web content
- beautifulsoup: a Python library that parses HTML and XML documents to extract data easily
- lxml: a fast parser that Beautiful Soup uses and a library with an extensive toolkit for processing XML and HTML documents, typically used with the requests library to first get the content and then parse it for extraction
- Playwright: an open-source library with a single API to automate Chromium, Firefox, and WebKit (Safari’s engine) browsers to scrape dynamic websites, JavaScript-rendered content, and single-page applications (SPAs)
- python-dotenv: a library that loads environment variables from a .env file.
Playwright needs browser binaries to be downloaded separately, so we’ll use playwright install.
Don’t forget your proxies
A proxy is the key that will open the doors to data that would otherwise be blocked. It hides our IP so that websites only see the proxy’s IP, which lets us access all the data we seek. This process appears organic and human, a key factor further strengthened by rotating proxies, which don’t allow a high volume of requests to come from the same source, instead sending multiple requests from different IPs.
A scraper rotates through numerous IPs, distributing the traffic load across them, increasing the data collection rate without triggering the rate limits. We can extract a ton of data as we bypass firewalls and geo-restrictions.
Decodo's residential proxies boast the best response time in the market, along with 115M+ IPs in 195+ locations, allowing you to collect real-time data from any website.
Here are simple steps to set up Decodo residential proxies with rotating IPs:
- Register or log in to the Decodo dashboard.
- Navigate to find residential proxies and choose a subscription that suits your needs or start with a 3-day free trial.
- Go to Proxy setup.
- Select a location or choose Random.
- Set the rotating session type and choose a protocol (HTTP(S) or SOCKS5).
- Choose the authentication type.
- Copy the generated endpoint and credentials into your scraper, browser, or software, or download them.
Watch our tutorial to learn how to set up residential proxies.
Get residential proxies for scraping text
Unlock superior scraping performance with a free 3-day trial of Decodo's residential proxy network.
To manage authentication for applications that use proxies, we commonly set proxy credentials in environment variables in order to prevent hardcoding sensitive information directly into our code or configuration files.
Residential vs. datacenter proxies
Now, you may wonder about the difference between residential and datacenter proxies. Both hide your IP and enable access to restricted websites and geo-blocked content.
Datacenter proxies are a great and cost-effective tool for large-scale extractions from less restrictive websites, while residential proxies use regular users’ devices across the globe, imitating a genuine user, thus being the best tool for scraping more restrictive sites.
Residential proxies
Datacenter proxies
Use
High-security websites with strong anti-bot systems
Simple targets with weak or no anti-bot measures
Trust score
High (real ISP IPs)
Low (easily identified)
Speed
Slower (home bandwidth)
Fast (server-grade)
Cost
Higher
Lower
Block risk
Low
High
Anonymity
High
Basic
Project structure suggestion
Here's an example of clean, modular file organization, with separate concerns, for a Python project:
How to extract clean text from HTML
In this section, we’ll cover a couple of ways to extract clean text from HTML pages. For starters, text scraping will be very different depending on the content type, whether it’s static or dynamic.
Static content includes all elements on a page embedded directly into the HTML document, so everything will be available in the first HTML response. This will include text, images, UI elements, and other content that changes only when the server-side source code gets updated. This is how to scrape static content:
- Retrieve the HTML document with a get request to the page’s URL using a simple HTTP client.
- Parse the response with an HTML parser.
- Extract whatever you need using CSS selectors or XPath.
A popular scraping stack for retrieving static content includes Requests and Beautiful Soup, while proxies are the best tool to avoid blocks.
On the other hand, dynamic content isn't included in the original HTML document that the server returns, as it’s added to the page only after JavaScript execution. And because browsers run JavaScript, we must use browser automation tools like Playwright or Selenium to scrape dynamic content.
- Open the target page in the browser.
- Wait for the wanted dynamic content to load.
- Select and extract that content with the provided node selection and data extraction APIs.
Basic text extraction with Beautiful Soup
Now it’s time to take a closer look at the above-mentioned Beautiful Soup. This is a hugely popular Python library that forms parse trees to extract text from HTML. We’ll follow these steps to extract our text:
- Use pip install requests beautifulsoup4 to download and install Requests and Beautiful Soup.
- Install libraries from the Python Package Index.
- Import the Beautiful Soup class from the bs4 module and the Requests library.
- Use an HTTP get request for the URL, load the HTML content.
- Pass the HTML content and the html.parser to create a Beautiful Soup object.
- Locate a specific element via the find method, use .select() or find_all() to target the HTML tag holding the main content.
- Use get_text() to extract the text content from that HTML element and separator=' ' to avoid words sticking together.
- Print the extracted text content.
The get_text() method allows us to eliminate whitespace and maintain document structure. We also want to remove unwanted elements (<script>, <style>, <nav>, <header>, <footer>, <aside>). A simple option is to use find_all() with a list of tags, then add decompose() to all elements. This will remove the tag and its content from the parsed tree.
Here’s an example of extracting an article text:
Note: Replace YOUR_PROXY_USERNAME and YOUR_PROXY_PASSWORD with Decodo credentials.
Targeted extraction with selectors
Instead of parsing the entire content, we can use targeted extraction to identify and extract specific data with CSS or XPath. CSS selectors focus on classes, tag types, IDs, and attributes, while XPath navigates the Document Object Model (DOM) in all directions to select elements. XPath is a perfect choice in complex and flexible cases when CSS is simply not enough.
Importantly, the DOM structure can be analyzed to find content-rich elements, allowing the core content to be separated from noise (ads, footers, navigational bars, etc.). The text density analysis, for example, calculates the ratio of text to HTML tags within DOM nodes to identify areas with high text density, i.e. core content, whereas the low-density areas contain noise.
Handling JavaScript-rendered content
When we handle JavaScript (JS)-rendered content, we want to make sure that browsers, search engines, and web scraping tools all properly process the dynamically generated content. Now, static extraction can fail, and we know it did when we see blank pages and empty data fields. A common culprit is dynamic content that static techniques can’t access.
To counteract this, we can use Playwright to render JavaScript before extraction. We’ll open the URL, wait for the page to render fully, and extract data with Playwright:
1. Install Playwright via npm:
- Use npm init playwright@latest to initialize a new project or add Playwright to an existing one
- Choose TypeScript or JavaScript, add tests folder name and a GitHub Actions workflow, and confirm to install Playwright browsers
2. Start a browser, chromium.launch()
3. Load the page, page.goto()
4. Wait for the dynamic content to render, page.waitForSelector()
5. Retrieve the rendered HTML, page.content()
6. browser.close()
If a site is built as a React SPA, the real content is rendered by JavaScript in the browser. The solution is to employ a browser automation tool to render the page and then extract the text. This example uses Playwright and Beautiful Soup:
1. Install dependencies
2. Copy this code, save as .py file, and run it in your terminal
Note: hn.algolia.com is the official, real-time search engine for Hacker News, a Rails 5 application with a React frontend.
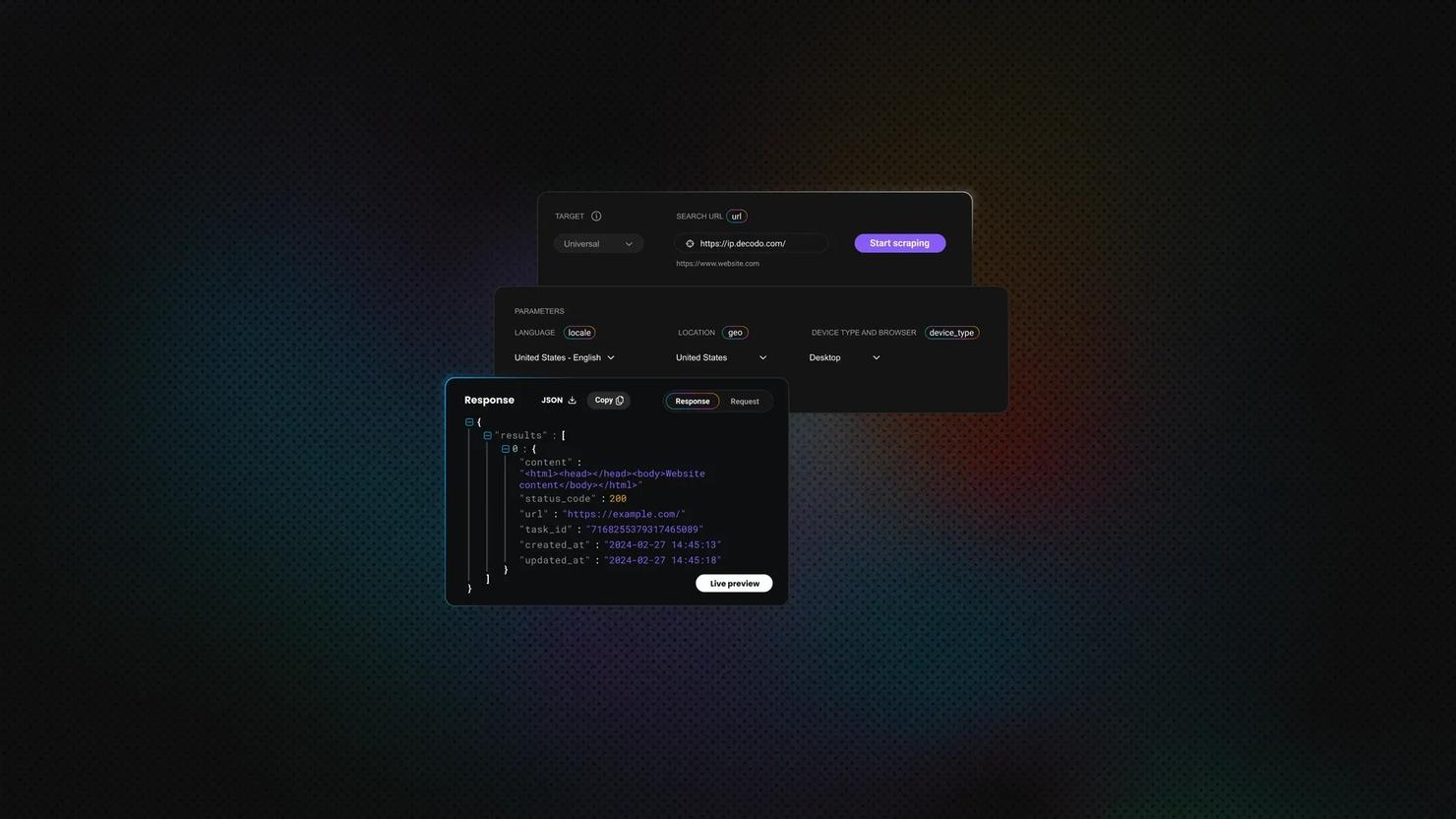
However, as an alternative for handling JavaScript rendering automatically, we highly recommend the Decodo Web Scraping API. There are five subscription types to choose from, including free and custom options, where each plan comes with proxies, 125M+ IPs globally, 200 requests per second, 99.99% success rate, 100+ prebuilt templates, and results in HTML, JSON, CSV, XHR or PNG.
Content cleaning and noise removal
This is the third essential step in the process, which follows crawling and scraping. Having the text cleaned is necessary for Large Language Model (LLM) training because noise leads to a massive drop in model performance. Here’s what we’ll do:
- use libraries like Beautiful Soup to remove HTML and tags, leaving only text;
- remove copyright notices, cookie banners, and social sharing widgets;
- normalize test, normalize whitespace, and standardize formatting;
- remove irrelevant elements (URLs, email addresses, special characters, and punctuation);
- remove low-information words and duplicate content, then fix typos.
Exporting and storing extracted text
We’ve reached the final step and now need to save our extracted text. We’ll choose between three formats, JSON, CSV, and specialized databases, depending on what our project requires to be the most efficient.
Plain text output (extracting the readable text content only) allows us to store or process high-volume, raw text data, when the textual content takes priority over style, producing lightweight and highly portable datasets. It’s typically used for large-scale language model training (LLM corpora) and simple, long-term archival purposes.
That said, the industry standard is saving scraped text to .txt files with UTF-8 encoding, because this allows maximum compatibility across platforms, operating systems, and international character sets. Importantly, UTF-8 is not prone to garbled text (aka "mojibake") thanks to its vast character support.
Structured JSON output
Structured JSON output in text scraping extracts data from unstructured text (e.g. raw HTML or document content) into a predefined JSON structure. This is crucial to enable cleaner data analysis and LLM training. We can also include metadata to provide more context and integrity, and keep the format consistent. For example, we can add the source URL, title, scrape timestamp, and word count. Let’s take a look at an example:
For large databases, JSONL (JSON Lines) is a good choice. Each line becomes an independent and valid JSON object.
CSV for spreadsheet analysis
CSV files are the standard format for storing scraped text and getting it nicely organized into rows and columns, enabling easy analysis in Excel or Google Sheets. Python’s pandas library converts data into a DataFrame, and we can export it to CSV (df.to_csv()). Also, Excel Power Query or Google Sheets' IMPORTXML function allows us to export text with metadata. We use XPath or CSS selectors to structure HTML into columns, which we can then export as CSV/XLSX.
Without a doubt, we’ll need to handle a text with newlines and special characters in CSV files, and we’ll have to do it properly. To accomplish this, we will use standardized UTF-8 encoding for all our CSV files, proper quoting, and built-in libraries such as Python's csv module.
Database storage for larger projects
Database solutions like PostgreSQL or MongoDB are ideal for large-scale text scraping. When it comes to production text scraping specifically, we can use MongoDB for unstructured scraped data, or data that changes often. However, PostgreSQL is a better solution for data that needs strong data integrity. Also, we can use SQLite for local projects and store all data in a single, portable file.
Avoiding frequent challenges
To round up the guide, we’ll take a look at common challenges specific to large-scale text extraction, including blocks and rate limits, as well as inconsistent page structures.
The first thing we’ll learn is to recognize block patterns by monitoring for 403 Forbidden responses, CAPTCHA challenges, and hidden honeypot traps. We’ll want to avoid these setups that are regularly used as anti-bot mechanisms by analyzing HTTP response codes, rendering JavaScript to detect dynamic challenges, and inspecting the DOM for invisible elements.
We can implement request throttling and backoff strategies via specialized techniques like setting rate limits (a token bucket or fixed window) and using parallel processing to handle HTTP 429/503 errors. An effective course of action when faced with rate limits is not to retry immediately. Instead, leverage exponential backoff with jitter to prevent sending requests at fixed intervals. This method will increase wait times exponentially and add random jitter.
All this said, the best strategy is to use rotating residential proxies. Because they rotate through hundreds of ISP-assigned IPs across the world, they appear like legitimate users, allowing proxies to maintain access, avoid blocks, and continue extractions. Avoid datacenter IPs, because they are often flagged instantly, and avoid free proxies as they tend to be unreliable, slow, and unsafe.
Dealing with inconsistent page structures
This is one of the most common challenges. We extracted data from different sources (e.g., websites, emails, articles, reports), but they’re now coming in all sorts of layouts and merged cells, and nothing is consistent. This can cost us our data. The DOM isn’t consistent, as names change, ads appear, and other elements appear, disappear, or shift. To solve this issue, we can build multiple candidate selectors, heuristics to isolate core information (by leveraging text density and structural features), and fallback layers with multiple selector fallbacks.
We’ll define a list of selectors ordered from most specific to least specific, so that if one fails, the scraper will try the next. The automated fallback strategies are essential to prevent data loss when primary selectors fail during large-scale text extraction. XPath with text-based matching is a strong option as well and can be used to locate elements based on text content rather than fixed DOM structures.
Character encoding and text quality
Other issues we can easily run into include encodings (UTF-8, ISO-8859-1, Windows-1252) and mojibake. We can’t detect all encodings, but heuristics are a good option for the most common ones. The best course of action is to prioritize UTF-8 and convert the data into it as soon as this is technically possible. This is also a key strategy to avoid mojibake.
Finally, we’ll validate output quality before downstream processing to reduce error propagation and prevent storing junk data by using a combination of confidence scoring, automated rules, and semantic checks to catch errors and formatting issues.
Once this is done, we’ll continue with monitoring and maintenance by establishing automated pipeline oversight and data quality control and implementing alerts for scraper failures to catch both total system outages and silent failures. We can also utilize version-controlling selectors to track site changes and deploy updates, and schedule periodic re-scrapes for fresh content.
It’s strongly recommended to maintain a diverse pool of proxies and rotate IPs to prevent blocking, as well as to set alerts for when the proxy success rate drops. Speaking of which, Decodo Site Unblocker is a concrete solution for accessing a range of targets while avoiding CAPTCHAs or IP bans. This is a proxy-like solution with a 100% success rate, which allows users to extract data from the most challenging targets without building a web scraper or using a headless browser.
Final thoughts
Scraping all text from a website isn’t just a technical task but also a process that builds a resilient system that can adapt to complex, often changing, and even hostile environments. However, combining the right tools with smart strategies will get you maximum value.
When done correctly, text scraping transforms from simple data collection into a basis for intelligent systems, automation, and much more. And when proxies are added into the mix, our web scraping projects become unstoppable.
Access residential proxies now
Try residential proxies free for 3 days – full access, zero restrictions.
About the author

Mykolas Juodis
Head of Marketing
Mykolas is a seasoned digital marketing professional with over a decade of experience, currently leading Marketing department in the web data gathering industry. His extensive background in digital marketing, combined with his deep understanding of proxies and web scraping technologies, allows him to bridge the gap between technical solutions and practical business applications.
Connect with Mykolas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.