Unlock Market Insights: How Web Scraping Transforms Modern Market Research
Traditional market research is the business equivalent of using a flip phone in 2026. Sure, it technically works, but why limit yourself when superior technology exists? In this guide, we'll show you how web scraping for market research gives you a competitive advantage that makes conventional research look outdated.
Lukas Mikelionis
Last updated: Sep 29, 2025
7 min read
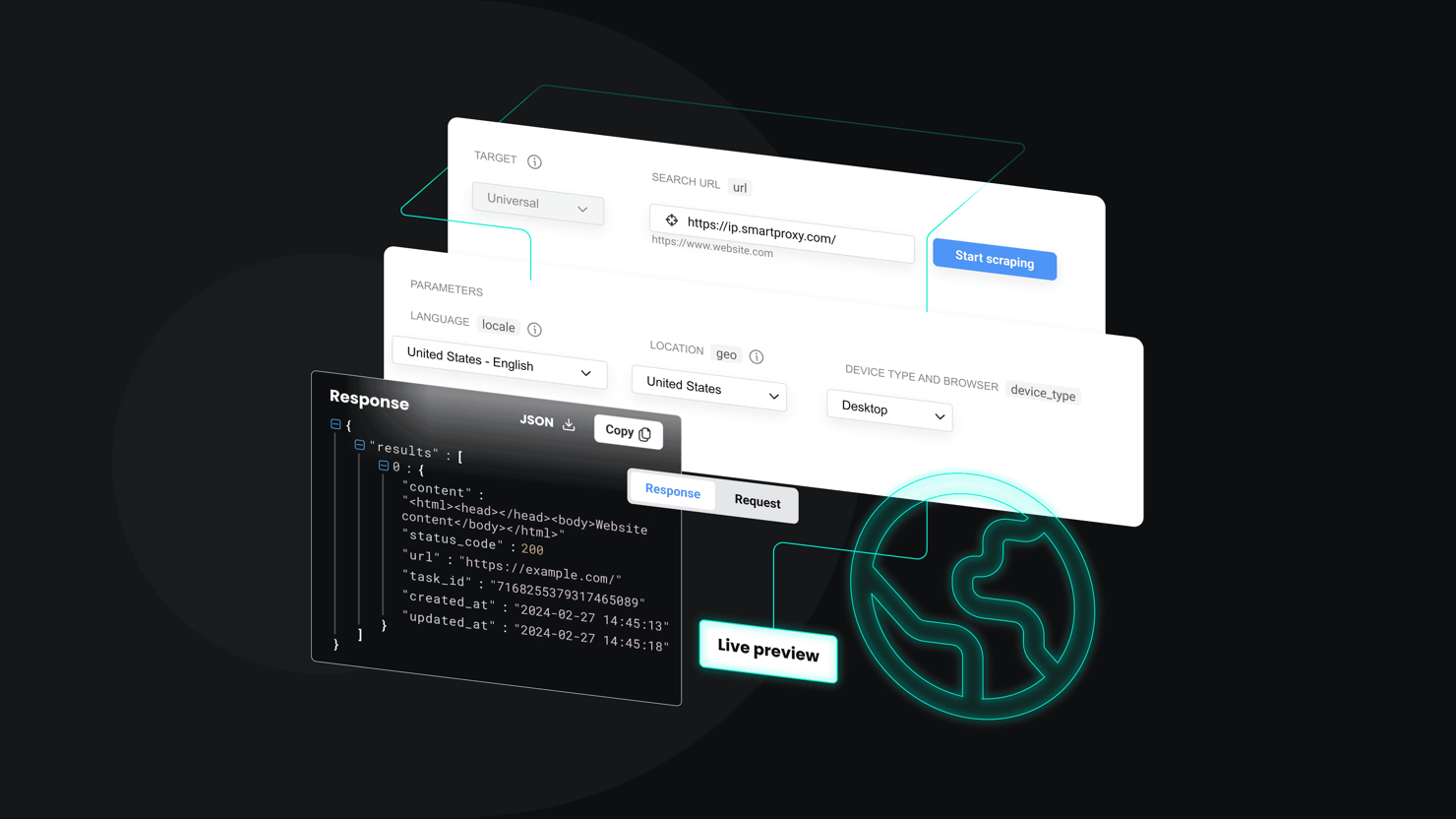
Understanding web scraping
Web scraping is the process of automatically extracting data from websites and online sources. Instead of manually checking dozens of sites one by one, think of web scraping as a high-speed scanner that can sweep across thousands of pages at once, pulling out the exact information you need. It turns hours of repetitive research into seconds of automated collection.
The web scraping process follows a systematic four-step approach:
- Target identification. Define the websites and data points that matter to your objectives. The focus is on gathering information that drives decisions, not just filling up spreadsheets.
- Data extraction. Automated bots handle the heavy lifting: crawling pages, applying CSS/XPath selectors, rendering JavaScript, and pulling the data you actually need fast and at scale.
- Data processing. Raw data is rarely ready out of the box. Cleaning, deduplication, and format standardization turn a messy feed into a structured dataset you can actually work with.
- Data analysis. With clean data in hand, the final step is putting it to work: spotting trends, benchmarking competitors, and uncovering insights that directly support smarter business moves.
APIs provide reliable data access when companies are willing to share, but let's be honest – the most valuable competitive intelligence rarely comes through public APIs. Browser automation tools like Selenium handle dynamic content, while parsing libraries such as BeautifulSoup (Python) and Cheerio (Node.js) extract specific data from HTML.
For more complex projects, advanced users often turn to frameworks like Scrapy, while no-code platforms let non-technical users build scrapers with ease. And for businesses that want to avoid technical overhead altogether, managed solutions like Decodo's Web Scraping API deliver clean, ready-to-use data without the hassle of proxies, CAPTCHAs, or ongoing maintenance.
Here's a comparison table that'll help you choose the best approach:
Approach
Best for
Pros
Cons
DIY scraping
Developers with time
Full control, customizable
High maintenance, breaks when sites change
Scraping tools
Teams with some technical knowledge
Faster setup, good for medium projects
Learning curve, requires updates
Managed APIs (Decodo)
Anyone who wants clean data fast
No setup, handles technical complexity
Costs money (but makes more money)
Why web scraping is a game-changer for market research
Traditional market research just can't keep up with how quickly markets move. By the time survey results are in or focus groups are analyzed, customer behavior may have shifted, and competitors may already be acting on new opportunities.
Web scraping flips that script by giving you data in real time. Instead of waiting weeks for reports, you can track competitors, monitor consumer sentiment, and analyze millions of data points as they change. That speed lets you spot opportunities and act on them before slower-moving rivals.
And the payoff is clear: faster insights mean faster decisions, quicker product launches, and a stronger position in the market.
With web scraping for market research, you can tap into insights like:
- Competitive intelligence. Real-time competitor pricing, product launches, marketing campaigns, and customer feedback analysis.
- Market trend analysis. Emerging product categories, consumer sentiment shifts, and demand pattern identification.
- Consumer behavior mapping. Purchase journey analysis, preference evolution tracking, and decision factor identification.
- Supply chain monitoring. Inventory levels, supplier relationships, and market availability tracking.
Types of data sources and data collected for market research
Web scraping democratizes access to competitive intelligence that once required corporate espionage-level budgets. The internet is an open book, and web scraping helps you read it quickly and at scale.
Market researchers can tap into a wide range of sources, but these are some of the most valuable:
- eCommerce platforms. Pricing, availability, customer ratings, and sales rankings provide a real-time view of market demand and competitor strategy.
- Social media and forums. Public discussions reveal unfiltered consumer opinions and authentic sentiment that surveys often miss.
- Review sites. Platforms like Trustpilot and G2 highlight customer experiences, competitive strengths, and feature gaps.
- News and industry reports. Tracking publications and press releases helps you identify emerging trends before they gain mainstream attention.
- Company directories. Business databases and professional networks offer structured information for sales targeting, partnerships, and competitive analysis.
Key use cases of web scraping in market research
Web scraping turns scattered online information into insights you can act on. Here are some of the ways it's being used today:
Market trend analysis
Trends rarely show up first in formal reports. They start in search queries, social chatter, new product pages, and news mentions. Scraping those sources gives you a running feed of what's bubbling up, so you can move while competitors are still waiting for confirmation.
Price monitoring
Pricing changes quickly, and missing a shift can cost market share. Daily scrapes of competitor sites reveal prices, discounts, and stock levels in near real time. That means no more surprises and a much clearer view of how rivals adjust strategies over weeks and months.
Competitor monitoring
Competitors don't always announce what they're doing, but they usually leave hints online. Scraping product pages, blogs, and press releases helps you catch quiet feature launches or shifts in positioning. Having that visibility gives you time to react before it becomes a bigger move.
Lead generation
Instead of relying on generic lead lists, scraping lets you pull prospects that actually match your target profile. From business directories to company sites, you can build contact lists with the details your sales team needs, without wasting hours digging manually.
R&D and product development
Market research isn't only for marketing and sales; it's also a rich input for research and development (R&D) and product teams. Thousands of customer reviews contain valuable feedback, but no one can read them all. Scraping makes it possible to analyze reviews at scale and pick out recurring frustrations or requests. For product teams, that's a direct line into what customers really want.
How to get started with web scraping for market research
Embarking on web scraping for the first time may seem daunting, but it's more accessible than ever:
- Define your objectives. What specific questions do you need answered? Competitor pricing? Customer sentiment? Market trends? Clear objectives determine which data sources and tools you'll need.
- Choose your approach. Technical teams should consider Python libraries like Scrapy or BeautifulSoup. And non-technical users can start with no-code tools. There's also a hands-off approach when you can use managed services that handle all technical complexity.
- Start small and scale. Begin with one competitor or data source. Validate your approach, then expand systematically. Most successful implementations start focused and grow over time.
- Automate analysis. Raw data isn't insights, so you need to set up dashboards, alerts, and reporting systems that turn your scraped data into actionable intelligence.
Regardless of the method you choose, the basic workflow of a web scraping operation is the same:
- Planning phase. The planning phase begins with defining research objectives, identifying target websites, and establishing success metrics alongside compliance requirements and data governance frameworks.
- Setup phase. During setup, you get to configure scraping tools, establish storage systems, and implement monitoring with tested extraction accuracy and robust error handling.
- Extraction phase. The extraction phase deploys automated collection systems while monitoring data quality, adjusting parameters for website changes, and maintaining respectful crawling practices with proper rate limiting.
- Transformation phase. Transformation involves cleaning extracted data, standardizing formats, enriching with context, validating accuracy, and eliminating duplicates.
- Analysis phase. Finally, the analysis phase integrates data with analytics platforms, creates visualization dashboards, establishes automated reporting, and generates actionable insights with strategic recommendations.
Collect data from any website
Unlock real-time data without a single line of code – activate your 7-day free trial.
Best practices for responsible web scraping
Web scraping is powerful, but it must be done responsibly and ethically. Mishandling scraping can lead to legal issues, broken websites, or unreliable data.
To ensure your web scraping is above board and effective, here are some key best practices to follow:
- Check the terms of service and robots.txt. Review website policies before scraping. Some sites explicitly forbid scraping or have specific usage requirements. While scraping publicly available data is generally legal, violating terms of service can lead to blocked access or legal complications.
- Respect data privacy. Focus on business intelligence, not personal surveillance. If data includes personal information, handle it carefully. Public data can still be protected by privacy laws, and ethical scraping means avoiding unnecessary personal data collection.
- Don't break websites. Your scraping shouldn't disrupt normal website operations. Hitting sites with thousands of rapid requests can appear like attacks and crash websites. Use reasonable request timing and respect server resources.
- Ensure data accuracy. Scraped data can be messy, especially when websites change structure. Implement validation checks to ensure your pricing data contains actual prices, not HTML fragments or error messages.
- Stay transparent. If you publish insights based on scraped data, disclose data sources appropriately. Use scraping to generate competitive intelligence, not to steal content or violate intellectual property rights.
Challenges and limitations
Web scraping is powerful, but it comes with challenges. Many sites use anti-bot protections such as CAPTCHAs, IP rate limits, login requirements, or obfuscated code that makes parsing more difficult.
Another issue is that websites often change their layouts, which can break scrapers without warning. The data itself can also be messy, full of inconsistencies, duplicates, and formatting errors that need careful cleaning. Timing is just as important: information like pricing or inventory can become outdated quickly if you are not scraping or refreshing regularly.
These hurdles are easier to manage with dedicated tools like Decodo, but they can be far more demanding with DIY solutions. It is always worth weighing the effort against the value of the data, especially if alternative sources are available.
The future of web scraping in market research
Web scraping and data extraction techniques continue to evolve rapidly. Looking ahead, several trends are shaping the future of web scraping as it applies to market research.
Automation and AI-driven scraping
Scrapers are getting smarter. Instead of breaking every time a website changes its layout, newer tools powered by AI can adjust on their own and keep collecting data. That means less time fixing broken code and more time using the information.
For researchers, this will make scraping feel easier and less technical. You might simply log into a dashboard or type a request in plain language, while the system handles the complicated parts behind the scenes.
Real-time analytics and predictive modeling
The gap between collecting data and analyzing it is shrinking. In the future, scraped data could flow straight into dashboards that update live with prices, reviews, or social mentions as they happen. Some companies already do this on a small scale, but it's likely to become standard.
Once that real-time stream is in place, predictive tools can go a step further. They'll help forecast when a competitor might cut prices, when demand is starting to shift, or when a new trend is about to break out.
Increasing regulatory scrutiny and data ethics
As web scraping becomes more prevalent, expect increased regulatory attention and more sophisticated website defenses. The arms race between scrapers and anti-scraping technology will continue escalating.
Ethics will become a competitive differentiator as companies adopt stricter data governance policies. Responsible scraping practices will separate professional operations from amateur data collectors.
Bottom line
Market leadership belongs to organizations that act on real-time intelligence while competitors debate quarterly reports. In fast-moving markets, the ability to collect and use competitive data quickly has become a basic requirement for survival.
Web scraping makes that possible. What once demanded enterprise budgets and specialized teams is now accessible to anyone who wants to compete. Whether you're a startup taking on bigger players or an established company trying to move faster, the data you need is already out there. The real decision is whether to use it or watch competitors use it against you.
Collect real-time data
Get real-time insights from any website with the Web Scraping API. Start your 7-day free trial with 1K requests.
About the author

Lukas Mikelionis
Senior Account Manager
Lukas is a seasoned enterprise sales professional with extensive experience in the SaaS industry. Throughout his career, he has built strong relationships with Fortune 500 technology companies, developing a deep understanding of complex enterprise needs and strategic account management.
Connect with Lukas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.