How to Scrape Craigslist with Python: Jobs, Housing, and For Sale Data
Craigslist is known as a valuable source of classified data across jobs, housing, and marketplace items for sale. However, scraping Craigslist presents challenges like CAPTCHAs, IP blocks, and anti-bot measures. This guide walks you through three Python scripts for extracting housing, job, and for sale item listings while handling these obstacles effectively with proxies or a scraper API.
Dominykas Niaura
Last updated: Oct 27, 2025
10 min read
Why scrape Craigslist?
Craigslist is a rich source of public data across countless categories – from real estate and vehicles to jobs and services. Scraping Craigslist data can help businesses uncover valuable insights and opportunities that would be hard to obtain manually. Here are some of the use cases of scraping Craigslist:
- Gathering sales leads. Businesses can identify potential customers by monitoring relevant categories, such as housing, services, or job postings. This data can be used to build outreach lists, discover local partners, or target new markets.
- Market research and competitor monitoring. Tracking listings and prices across different regions provides a real-time view of market trends. Companies can analyze competitor offerings, regional demand, and pricing dynamics to stay competitive.
- Reselling analysis. Resellers can track used item listings to identify undervalued deals, understand resale margins, and automate sourcing decisions based on predefined filters like condition, location, or price range.
- Trend prediction. Aggregating and analyzing Craigslist data over time helps researchers and businesses forecast emerging demand patterns – from popular vehicle models to shifts in rental prices or service demand.
Technical challenges of scraping Craigslist
While Craigslist data is publicly visible, extracting it at scale isn't straightforward. The platform employs several mechanisms to prevent automated scraping, which can quickly interrupt your data collection if not handled correctly. These technical challenges include:
- CAPTCHAs and anti-bot protections. Craigslist uses CAPTCHAs and behavioral checks to distinguish real users from automated scripts. Frequent requests from the same IP or unusual browsing patterns can trigger these protections, halting your scraper.
- IP rate limiting and bans. Sending too many requests in a short time may result in temporary or long-term IP bans. Using a rotating proxy pool with proper request throttling is essential to maintain stable access.
- User-agent and session tracking. Craigslist monitors browser headers, cookies, and session behavior to detect bots. Reusing the same user-agent or failing to handle cookies correctly can lead to blocked sessions.
- Lack of an official public API. Craigslist doesn't offer a public API for programmatic access to its listings. This makes it harder to maintain consistent scraping logic, as even small changes in Craigslist's layout can break your scripts.
What you need to scrape Craigslist
Let's scrape three of the arguably most popular listing categories: jobs, housing, and sales. The following scripts use Playwright for browser automation, which handles JavaScript rendering and makes the scraping process more reliable than simple HTTP requests. They also integrate residential proxies to keep requests successful.
Install Python
Python's flexibility and large ecosystem of libraries make it the go-to language for web scraping. Make sure you have Python 3.7 or later installed on your machine, which you can download from their official website. Most of the libraries used in this blog post come with Python by default.
Install Playwright
Before running any of the scripts, install Playwright and its Chromium browser driver using the following commands:
Configure proxy access
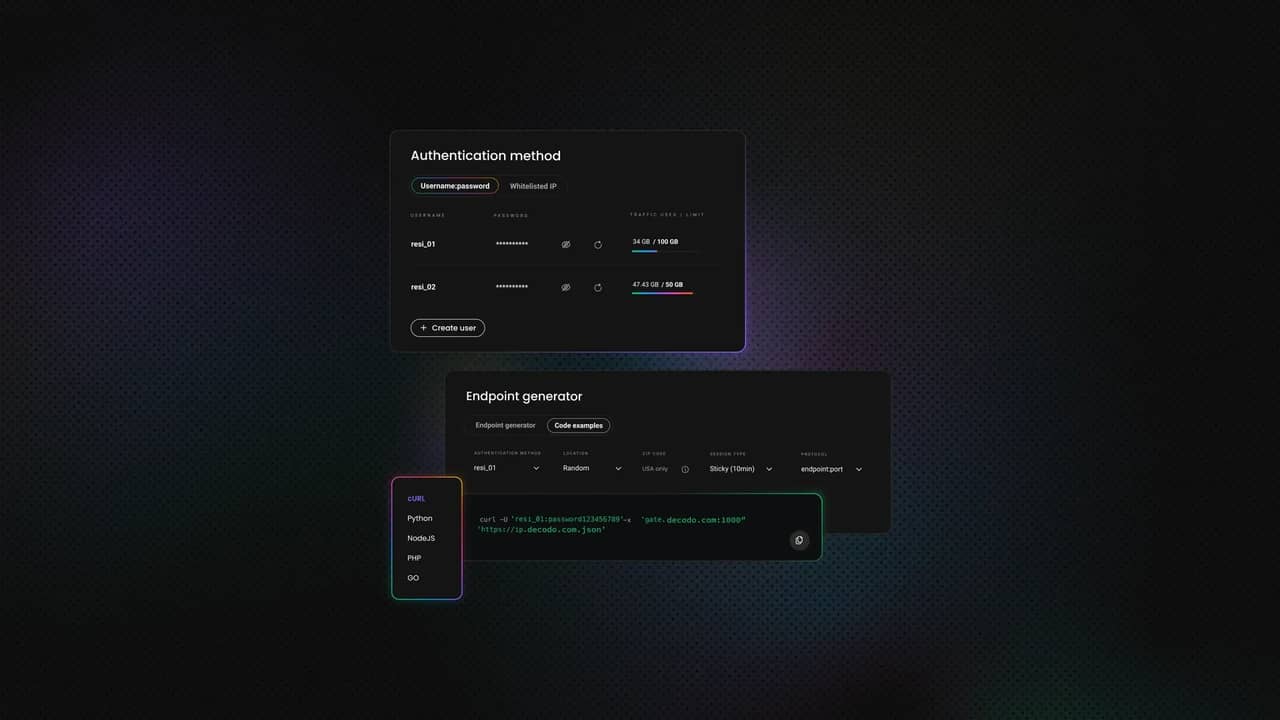
For reliable scraping, you'll need access to quality proxies. At Decodo, we offer residential proxies with a 99.92% success rate, average response times under 0.6 seconds, and a 3-day free trial. Here's how to get started:
- Create an account on the Decodo dashboard.
- On the left panel, select Residential proxies.
- Choose a subscription, Pay As You Go plan, or claim a 3-day free trial.
- In the Proxy setup tab, configure your location and session preferences.
- Copy your proxy credentials for integration into your scraping script.
Get residential proxies for Craigslist
Unlock superior scraping performance with a free 3-day trial of Decodo's residential proxy network.
Prepare your development environment
Set up a Python development environment using your preferred IDE or text editor. Having browser developer tools available will help you inspect Craigslist pages and identify the correct elements to target.
How to scrape Craigslist housing listings data
Let's start with Craigslist housing listings – one of the platform's most data-rich and consistently updated categories. Housing data reveals real-time rental prices, availability, and neighborhood trends, making it ideal for market analysis or investment research. Here's the full code followed with a quick breakdown of how this scraper is built:
The full scraper script
You can copy the code below, save it with a .py extension, and run it using your terminal or IDE:
Imports
- asyncio runs Playwright asynchronously, so page actions and waits do not block each other.
- playwright.async_api controls a real Chromium browser headlessly for reliable rendering and DOM access.
- csv writes structured results to a CSV file for easy analysis.
- urljoin from urllib.parse builds absolute listing URLs from relative links found on the page.
Proxies
Craigslist applies rate limits and anti-bot checks. Proxies help spread traffic across IPs to reduce blocks. The example uses a rotating residential proxy IP port (http://gate.decodo.com:7000) so each request can exit through different residential addresses.
The main function
This script launches headless Chromium, opens a fresh context with proxy authentication, and navigates to your target URL. It waits for initial results to render, then performs controlled infinite scrolling (repeatedly scrolling to the bottom and pausing) until it either reaches your requested listing count or detects no new results. It queries the DOM using resilient selector sets to extract fields even if Craigslist varies its markup.
Selectors
The script targets container blocks like div.result-info, then tries several possible selectors for each field. This multi-selector approach makes the scraper more tolerant to small layout changes. If the first selector is missing, the next candidate is tried.
Data points captured
For each listing, the scraper aims to collect:
- Title – The listing's headline.
- Location – A short area or neighborhood label.
- Date – The posting date shown in the grid.
- Price – The advertised price when available.
- Bedrooms – A quick housing meta snippet when present.
- URL – A fully qualified link to the listing detail page.
Save to CSV
save_to_csv() writes the extracted rows to craigslist_housing.csv file in the same directory where you run the script. It includes a header row and UTF-8 encoding. After saving, you see a short summary telling you how many listings were written.
Target URL
You can replace the url variable with any URL within Craigslist's housing category – filters are supported, and the script will respect them. The examples use the thumbnail view (notice …#search=2~thumb~… or URLs that end with thumb) because it conveniently surfaces the core fields – title, price, date, location – without extra navigation.
Listings to fetch
Set max_listings to the number you want. The infinite scroll loop tries to load at least that many cards, then processing is capped to your limit.
Results in the terminal
Besides writing a CSV file, the script prints a clean, enumerated summary of each listing – title, location, date, price, bedrooms, and URL – so you can quickly validate the output before opening the file.
Output
Here's a snippet of the response you'll see in the terminal:
How to scrape Craigslist jobs listings data
Job postings on Craigslist span categories including employment opportunities, gigs, and résumés across hundreds of cities. Recruiters and HR departments scrape these listings to source candidates, analyze salary expectations, and identify hiring trends across industries.
The setup and structure of this scraper are largely the same as in the housing scraper. It uses the same imports, proxy rotation, and the same Playwright flow for launching Chromium, scrolling, and saving results.
Target URL
The url variable in this script points to a Craigslist jobs category, typically something like:
As with housing, you can replace this with any regional or filtered jobs page URL (for example, specific job types). The script again works best with the thumbnail view, since it exposes most relevant data points directly on the page.
Data points extracted
This scraper focuses on job-specific attributes:
- Title – The listing's headline, usually containing the job title.
- Location – Area or neighborhood label.
- Date posted – The posting date shown in the grid.
- Compensation & company/poster name – Captured from the meta section when listed, such as hourly rate, salary, or company name.
- Listing URL – A full link to the job detail page.
Some jobs omit company or precise location data, so the script includes fallback selectors to handle inconsistent structures gracefully.
Scrolling logic and selectors
The infinite scroll loop remains the same, but the primary selector targets div.result-info elements within the jobs section. The list of alternative selectors for title, date, and location differs slightly to match the markup used on Craigslist job pages. This adaptive approach keeps the scraper resilient to layout variations across subcategories.
The full scraper script
Place the following script in a new .py file and execute it through your terminal or code editor:
Output
Here's a sample of the results that appear in the terminal once the script runs:
How to scrape Craigslist for sale listings data
Craigslist's for sale section contains millions of listings for vehicles, electronics, furniture, and appliances. Resellers and eCommerce businesses scrape this data to monitor competitor pricing, identify arbitrage opportunities, and track product availability. These structured listings are ideal for price comparison analysis and inventory trend monitoring.
Just like the housing and jobs scripts, this script uses Playwright, asyncio, csv, and urljoin, along with the same proxy setup, save_to_csv() logic, CSV writing format, and on-screen printout as before.
Targeting the "cars + trucks" category
For this example, the script focuses on the for sale category, specifically the cars and trucks section. Craigslist's for sale listings span dozens of product types, but vehicles are among the most scraped because they offer consistent, structured data like price, mileage, and location.
The url variable points to a filtered "cars+trucks" search, such as:
As before, users can replace this with any other subcategory or apply additional filters (brand, year range, price limits, etc.), and the script will still function. Using the thumbnail view ensures the scraper can easily access all key details without extra navigation.
Data points scraped
This version collects slightly different fields tailored to for sale listings:
- Title – The listing headline, such as product type, model, or short description.
- Location – The city, area, or neighborhood tag.
- Date – When the listing was posted or updated.
- Price – The listed selling price, typically marked with a currency symbol.
- URL – The full link to the individual listing page.
Because the for sale category includes diverse item types, the script uses several possible selectors for each field to handle layout differences across subcategories.
The full scraper script
Save the code below as a .py file, then run it from your terminal or preferred IDE:
Output
Below is an example of what the output will look like in your terminal:
Advanced techniques for scraping Craigslist
Once you're comfortable running the basic scripts, you can extend them to handle larger data sets and produce more structured, scalable outputs. Here are some ideas on how to expand your scraper next:
Handling filters
Craigslist supports extensive built-in filters, such as price ranges, keywords, listing types, or date. You can adjust these filters directly on the Craigslist search page and then simply copy the resulting URL into your scraper.
Alternatively, you can append parameters manually, such as "&min_price=500&max_price=2000", to limit listings to a specific price range. A filtered housing URL in New York might look like this:
Exporting data to different formats
While the examples in this guide save results to CSV, you can easily adjust the export logic. These methods are particularly useful when you need to aggregate listings over time or compare data between multiple regions:
- Excel. Use Python's Pandas or openpyxl library to write .xlsx files for cleaner formatting and easier sharing.
- Databases. Insert scraped data into SQLite, PostgreSQL, or MongoDB to store and query large volumes efficiently.
- APIs or dashboards. For automated systems, send the data directly to internal APIs or visualization tools for live analysis.
Using extraction rules and templates
Craigslist pages share similar structures across categories, but minor variations can break hardcoded selectors. Defining extraction templates helps maintain flexibility. You can store selector sets for each data field (title, price, date, etc.) in a separate configuration file or dictionary and load them dynamically depending on the category.
For highly structured output, you can also introduce extraction rules – logic that standardizes inconsistent values (for example, converting "2br," which stands for "two bedrooms," into a numeric bedroom count, or removing currency symbols). This improves data quality and makes analysis or integration with other systems much easier.
How to avoid getting blocked
Craigslist uses various anti-bot measures to protect its platform, so responsible scraping practices are essential for stable and sustainable data collection. Here are some key steps to help keep your scrapers running smoothly.
Proxy rotation and request throttling
Avoid sending too many requests from the same IP address. Use a rotating proxy pool to distribute traffic across different IPs, reducing the risk of bans. Combine this with request throttling (short, random delays between page loads) to mimic normal user behavior and stay under Craigslist's rate limits.
Rotating user-agents
Craigslist often checks browser headers to detect automation. Rotate user-agent strings (the identifiers that tell websites which browser and device you're using) for each session or request. Libraries like fake-useragent or custom user-agent lists help make your requests appear more organic.
Avoid scraping sensitive or prohibited data
Only collect public, non-personal information. Avoid scraping user emails, phone numbers, or any data that violates Craigslist's terms of use. Focus on general listing attributes like titles, prices, and locations – fields that are publicly visible and safe to process.
General etiquette
Respectful scraping frequency matters. Keep your request rate low enough that it doesn't affect Craigslist's servers. A delay of a few seconds between page loads is usually enough to stay off the radar. Responsible data collection ensures your scripts run reliably over time.
A simpler alternative: use Web Scraping API
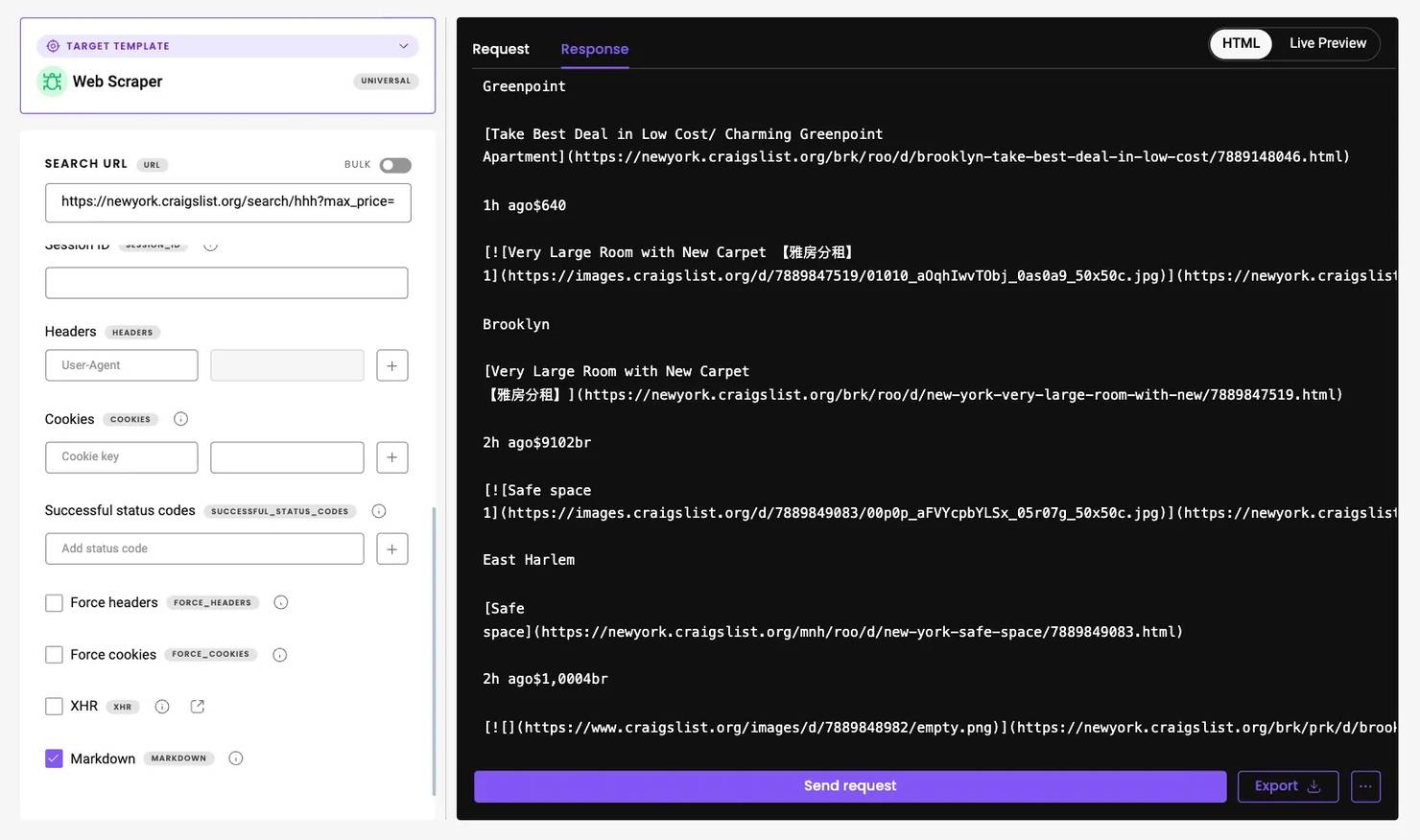
If you'd rather skip proxy management and anti-bot challenges altogether, you can use Web Scraping API. It handles IP rotation, CAPTCHA bypassing, and JavaScript rendering automatically while offering advanced geo-targeting options and a 100% success rate.
The API includes 100+ ready-made templates for popular websites. Craigslist isn't one of them yet, so you'll need to use the Web (universal) target, which returns the HTML of any page. You can then parse this output using the same logic as in your Playwright scripts.
If you prefer a more readable format right out of the box, enable the Markdown option – Craigslist pages work especially well with it, since they contain little unnecessary markup and present data in a clear, text-oriented structure.
Get Web Scraping API for Craigslist
Claim your 7-day free trial of our scraper API and explore full features with unrestricted access.
Final thoughts
The wealth of publicly available data offered on Craigslist is excellent for research, price tracking, and market analysis. And with tools like Playwright, residential proxies, and structured extraction logic, building a reliable custom scraper is entirely achievable. You can further enhance it by applying filters, exporting to richer formats, or scaling collection through automation.
For those who value simplicity and reliability over maintaining their own scraping infrastructure, our Web Scraping API could be a more attractive choice. It removes the need to manage proxies, browsers, and anti-bot handling while still giving full access to Craigslist data in raw HTML or clean Markdown format.
About the author

Dominykas Niaura
Technical Copywriter
Dominykas brings a unique blend of philosophical insight and technical expertise to his writing. Starting his career as a film critic and music industry copywriter, he's now an expert in making complex proxy and web scraping concepts accessible to everyone.
Connect with Dominykas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.