Web Scraping With Java: The Complete Guide
Web scraping is the process of automating page requests, parsing the HTML, and extracting structured data from public websites. While Python often gets all the attention, Java is a serious contender for professional web scraping because it's reliable, fast, and built for scale. Its mature ecosystem with libraries like Jsoup, Selenium, Playwright, and HttpClient gives you the control and performance you need for large-scale web scraping projects.
Justinas Tamasevicius
Last updated: Nov 26, 2025
10 min read

Prerequisites for scraping with Java
Before you can create a simple web scraper with Java, make sure your setup is ready for the job:
- Use a current Java LTS release – download Java 17, 21, or newer, and install it.
- Use an IDE like IntelliJ IDEA (Community Edition is free) – it simplifies development and integrates with build tools.
- Use automated build tools like Maven to manage dependencies like Jsoup or Selenium. Use the installation guide for getting Maven on your system.
- Understand the basics of HTML so you can locate elements to scrape.
- Understand CSS selectors and XPath – essential for targeting specific elements on a page.
For more in-depth setup instructions and some of the Java scripts discussed in this blog post, visit this GitHub repository.
Overview of Java web scraping libraries
Java gives you more than one way to scrape data from the web, and the right tool depends on what kind of content you're dealing with. Some pages serve static HTML, while others rely on JavaScript to dynamically load data. Let's take a brief look at when to use each library.
Before you try any of the examples in this guide, make sure your dependencies are set up. You don't download these libraries manually. If you're using Maven, you just add the dependency blocks to your pom.xml, and Maven pulls everything from Maven Central Repository into your project for you. Gradle works the same way. Once the dependencies are declared, your IDE handles the imports automatically, and the snippets below compile without extra configuration. This setup also makes it easy to update versions or check the official documentation when an API changes.
Jsoup
Jsoup is lightweight and reads HTML almost like a browser would. You can fetch a page with just a few lines of code and then use familiar CSS selectors to extract what you need.
Use Jsoup when your target pages render all their data in the initial HTML response. On the other hand, it can't scrape dynamically created pages that heavily rely on JavaScript to generate the content.
HtmlUnit
HtmlUnit is a headless browser written in Java that simulates user interactions like clicking. It's slower than Jsoup but can handle dynamic JavaScript content without running a full browser window.
It's handy for testing and simple scraping tasks where you need to wait for JavaScript to run.
Selenium
If you need even more control over dynamic websites, Selenium is the next step. It controls a real browser (Chrome, Firefox, or Edge) through WebDriver. This allows you to scrape content that appears only after user-like actions. You can click buttons, log in, or scroll through infinite pages.
The trade-off is speed. Selenium is powerful but pretty resource-intensive.
Apache HttpClient/HttpComponents
For projects focused on HTTP performance, you might prefer Apache HttpClient (HttpComponents). It's a tool for sending requests, managing headers, handling cookies, and controlling sessions.
In production-grade systems, developers often pair HttpClient with Jsoup for clean separation between fetching and parsing.
Playwright
Playwright for Java brings a high-level API for scraping JavaScript-heavy websites faster and more reliably than Selenium in some cases. Microsoft maintains it, and it's becoming a strong contender for automation and scraping alike.
Step-by-step guide: basic web scraping with Java
Let's walk through the process of building a simple web scraper in Java, with each step explained so you can drop it straight into your project.
We'll assume you've already met all the prerequisites and created a Java project in IntelliJ IDEA using Maven as the build tool.
Add dependencies
Before you start building the scraper, add the libraries you'll use. For parsing HTML, you'll use Jsoup. For exporting results to JSON, you'll use Gson. And for exporting to CSV, you'll use OpenCSV. Add the following to your pom.xml file:
Fetch the page
You'll fetch data from a simple placeholder site with quotes: https://quotes.toscrape.com.
First, create a reusable client with a sensible connection timeout. Next, build a GET request that targets the website you want to scrape, sets a clear User-Agent (and any other headers you need), and defines the request method. Finally, send the request and capture the response body as a string. That HTML lands in the html variable you'll parse in the next step.
Parse results with Jsoup
Inspect the page in the browser. Each quote lives inside a div with class quote, with two spans inside: span.text holds the quote text, and span.author holds the author.
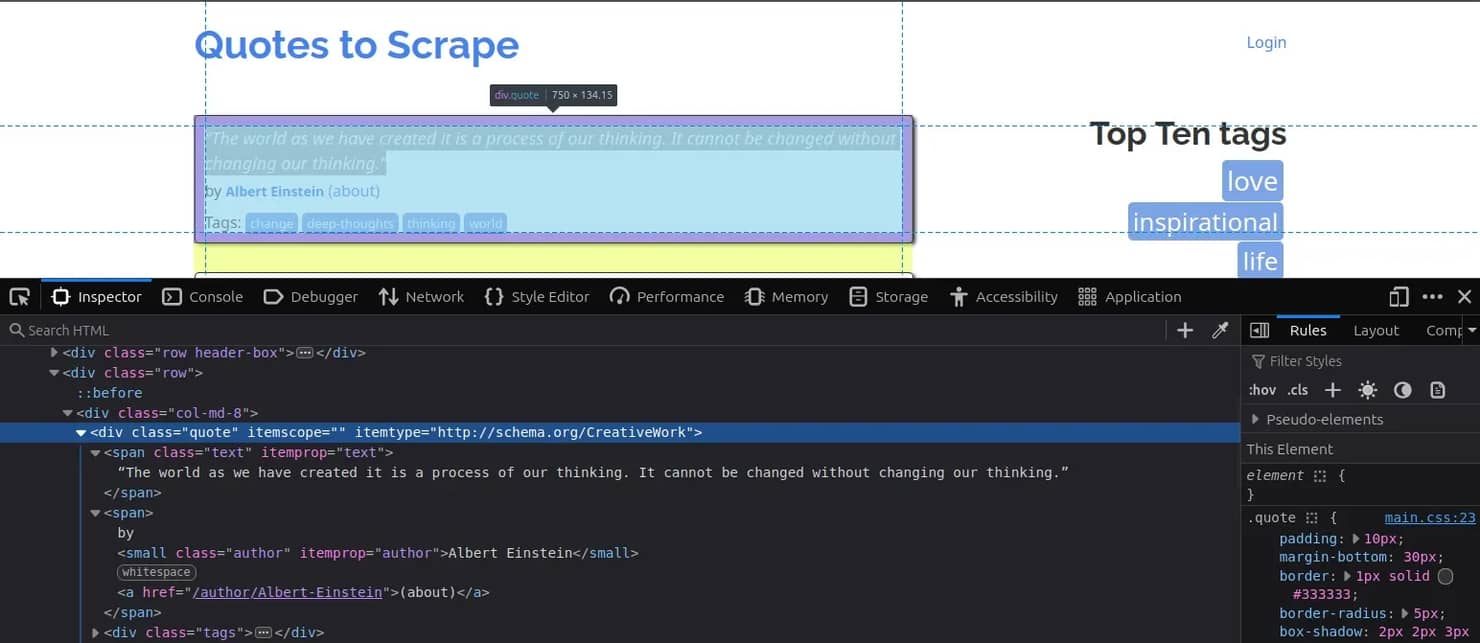
Based on that structure, the code parses the fetched HTML into a Jsoup Document, selects all quote blocks with the CSS selector .quote, and then, for each one, reads the .text and .author elements:
To keep the example transparent, this code prints the quote and author to standard output so you can verify the selectors and see exactly what the program is pulling.
In the next section, you'll learn how to do this properly – define a Quote class with text and author fields, and build a list of Quote objects as you iterate through the page.
Extract fields and map to objects
Create a small Quote class to hold the two fields you scrape (quoteText and quoteAuthor) with the usual constructor, getters, and setters:
Then, instead of printing inside the loop, you'll instantiate a Quote for each matched element and add it to a List<Quote>:
This gives you a collection you can test and export to JSON or XML later in the pipeline.
Export to JSON
Here's how to export the collected List<Quote> to JSON using Gson. This version pretty-prints the output and writes it to quotes.json:
This writes a new quotes.json file with your scraped data, stored in a JSON structure. You'll also see a console message confirming that the export worked and showing how many items were saved.
Export to CSV
Here's how to export your List<Quote> to CSV with OpenCSV. This writes a header row, then one line per quote:
This writes a quotes.csv file containing scraped quotes in a CSV structure. You'll also see a console message showing how many items were saved.
Handling dynamic content
When data on a website loads only after JavaScript runs, you can't just use HttpClient and Jsoup to scrape the content. You'll end up with empty sections or missing values, because the HTML you get isn't what the user sees in the browser.
Dynamic pages use JavaScript to request data asynchronously, often through XHR or fetch() calls. To handle this, you have two main strategies in Java: render the page like a browser would or intercept the underlying network requests.
For full rendering, use Selenium. It controls a real browser and waits for the page to load completely before scraping. Here's a minimal example:
For production use, replace the sleep call with WebDriverWait or explicit waits to ensure elements are loaded properly:
If you'd rather stay fully headless, HtmlUnit simulates browser behavior without launching a real one. It's lighter and faster, though less accurate with modern JavaScript frameworks.
In some cases, you don't need a browser at all. Open your browser's DevTools and check the Network tab. You might find that the site fetches data from a public JSON endpoint. If that's the case, you can hit that endpoint directly with HttpClient, bypassing rendering entirely. It's an elegant way to scrape faster while using less resources.
Pagination and web crawling
Pagination is how websites spread large datasets across multiple pages. Most sites implement pagination through a Next button or a predictable URL structure, like ?page=2 or /page/3.
You can confirm this by navigating through the site and watching the URL bar. Once you spot the pattern, you can automate it. In the case of the "Quotes to Scrape" website, it uses the page/3 structure.
Here's a simple example using Jsoup to crawl multiple pages until no more results appear:
This approach works for static or predictable URLs. For dynamic pagination-like infinite scroll or Load more buttons, you'll need Selenium or Playwright to click and wait for new content, as shown in the previous section.
Note: When building a scraper, avoid duplicate data. Keep a simple in-memory Set<String> of visited URLs or product IDs. If your crawler scales, move that check to a database or key-value store like Redis. Duplicates can waste bandwidth and storage.
Parallelization and efficient scraping
Fetching pages one by one is fine for testing, but when you're dealing with hundreds or thousands of URLs, you'll want to parallelize your requests. Java gives you excellent tools for that!
ExecutorService is Java's built-in thread pool manager. It lets you run multiple scraping tasks in parallel, each fetching and parsing a separate page. A fixed-size thread pool (say, 5 or 10 threads) balances speed and system stability. Here's a basic example:
This pattern alone can cut your scraping time drastically. But you don't have to stop there.
Starting from Java 19, virtual threads (part of Project Loom) make concurrency even lighter. Each task runs almost like a coroutine, which allows you to spawn thousands of threads without hitting memory limits. The official JEP 425 documentation explains how virtual threads can simplify I/O-bound workloads like scraping.
Why proxies matter in web scraping
Proxies help your scraper behave like a normal user instead of a single, repeatable pattern. They spread your traffic across multiple IPs, which lowers the pressure on any one endpoint and reduces the chance of temporary blocks.
They also unlock regional content differences, which is common in pricing, product availability, and ranking data.
If your workflow depends on multi-step flows (filtering, paginating, adding parameters) session-sticky proxies give you stable behavior. With a consistent IP behind each session, your scraper avoids broken sequences and mismatched results.
Decodo offers 115M+ residential proxies with a 99.92% success rate, average response times under 0.6 seconds, and a 3-day free trial. Here's how to get started:
- Create an account on the Decodo dashboard.
- On the left panel, select Residential proxies.
- Choose a subscription, Pay As You Go plan, or claim a 3-day free trial.
- In the Proxy setup tab, configure your location and session preferences.
- Copy your proxy credentials for integration into your scraping script.
Integrate proxies into your Java scraper
Unlock superior scraping performance with a free 3-day trial of Decodo's residential proxy network.
Using proxies in Java web scraping
As your Java scraper grows, you eventually reach a point where traffic patterns start to matter more than the code you write. Sending every request from a single IP works for small tests, but it quickly becomes a bottleneck at scale. Proxies solve that by routing your traffic through different IPs, making your scraper more stable.
Java cleanly integrates with proxies across its standard HTTP(S) stack and higher-level libraries. You don't have to rewrite your scraper to use them. You only define the proxy once and let the HTTP client or browser automation library handle the rest.
Selenium WebDriver with proxies
Selenium lets you route an entire browser session through a proxy, which is helpful for pages that depend on JavaScript or user-like interactions. Don’t forget to replace the placeholder values with your own authentication credentials:
The browser loads the site through the proxy, and the printed HTML matches what the page looks like from the proxy's perspective.
Playwright for Java with proxies
Playwright exposes proxy routing at browser launch. Insert your proxy username and password in place of the placeholder values:
This routes the whole browser session through the proxy. The HTML printed in the console reflects the content rendered from that proxy's location.
Anti-scraping measures and how to handle them
The moment your scraper scales, you'll likely encounter website defense mechanisms trying to block you. Treat them as signals that you're probably doing something wrong. Start with the lightest fix that works and escalate only if needed.
Rotate the User-Agent and set realistic headers
Many basic filters key off identical headers. Rotate a small pool of modern User-Agents, and add Accept-Language, Referer, and Accept to mimic real traffic. Keep the pool short and plausible, random strings look fake.
Manage cookies and sessions
Some sites expect stateful clients. Persist cookies across requests and reuse the same client so your session looks consistent. Add backoff when you see sudden redirects to login or consent pages.
Respect robots.txt and site terms
Let robots.txt and rate-limit rules guide you. Crawl only the paths you need, cache responses where possible, and cap per-host concurrency. Send requests at a steady pace. Aim for 1-3 requests per second per site, add a small random delay (about 500-1500 ms), and keep an eye on errors rates.
Handle CAPTCHAs with clear escalation paths
A spike in 403 response codes or pages titled "Just a moment…" usually signals a bot check.
First, slow down and improve header realism. If challenges persist, switch to a real browser (Selenium or Playwright for Java) and use explicit waits. Only after that consider third-party CAPTCHA solving services.
Use proxies and IP rotation
Rotate IPs when blocks are IP-based or when you fan out across regions. Pair rotation with session stickiness to keep carts, filters, or pagination stable. However, if your behavior or fingerprint looks automated, proxy rotation alone won't help.
Storing and processing scraped data
The real web scraping value comes from how you store and process the results:
- Save to files. For small jobs, write CSV for tabular reviews and JSON when records vary or will feed APIs/NoSQL.
- Use a database when size grows. Move to MySQL/PostgreSQL if your schema is clear. Pick MongoDB/Elasticsearch when structure varies or search matters. Insert with JDBC batches, and design a unique key so upserts avoid duplicates.
- Clean and normalize. Trim whitespace, standardize units and currencies, and validate required fields before storage. Drop obviously broken rows.
- Process and analyze. Start with Java Streams for quick aggregates. For larger pipelines, schedule batch jobs and consider Spark or Kafka Streams when volumes jump.
Troubleshooting and debugging
Even the cleanest scraper will eventually break – websites change layouts, add new anti-bot mechanisms, or throttle requests. Below are common problem areas and practical tips for how to overcome them.
Check the HTTP response
Inspect the response your scraper receives before assuming your parsing code is wrong. If you suddenly get empty data, log the HTTP status code and the first few hundred characters of the response body:
- 403 or 429. You're likely blocked or rate-limited. Try adding headers, rotating IPs, or adding delays.
- 301 or 302. The site has added redirects. Check for login pages or new URLs.
- 200 but empty content. The page might be rendered dynamically. Use Selenium or Playwright.
Log important events
Add structured logs for key events – request URLs, response times, and the number of items parsed. Use a lightweight logging library such as SLF4J with Logback. Avoid logging full HTML unless debugging a specific issue (it can slow your scraper and clutter logs).
Check selectors and page structure
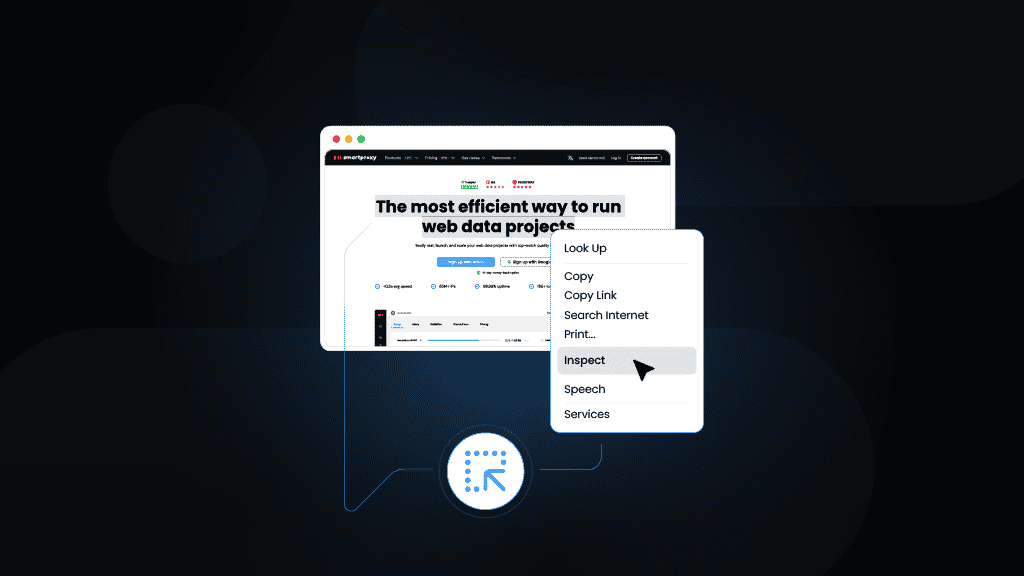
When parsing suddenly fails, verify that the page's HTML structure hasn't changed. Load the target page in your browser, right-click Inspect, and confirm your CSS selectors or XPath expressions still match.
Simulate a real browser
If you're consistently receiving blank or partial pages, the site might require JavaScript rendering. Run the same URL in a headless browser to confirm:
If Selenium returns the full HTML while Jsoup doesn't, the problem isn't your code – it's the rendering method.
Handle exceptions
Unexpected errors shouldn't crash your scraper. Wrap parsing logic and network calls in try/catch blocks and log failures with context:
You can retry failed requests with exponential backoff, or store them for later reprocessing.
Set up alerts and health checks
For production scrapers, add a basic alert system:
- Track success rate and average scrape time.
- If the number of extracted items drops sharply, send a notification.
- Keep historical logs to identify when and why something started failing.
Best practices for Java web scraping
Professional scraping means building systems that respect the web while staying reliable. Here are some things to keep in mind when web scraping.
Stay within ethical boundaries
Scrape only publicly available data that's clearly visible to regular users, and always check a site's robots.txt for guidance on what not to scrape. If there's an official public API for your target, give it a try. Additionally, avoid bypassing logins, paywalls, or any other access control mechanism.
Minimize server load and be a responsible scraper
Don't flood websites with requests:
- Keep a steady pace of 1-3 requests per second per host.
- Add small random delays and reuse connections with a persistent HttpClient to stay efficient without overwhelming the server.
- Cache results where possible, retry intelligently, and identify your scraper with a descriptive User-Agent that includes a contact.
Think longevity, not volume
Your goal should be to collect consistent, high-quality data over time. That way, you'll get fewer blocks, cleaner data, and stronger infrastructure that can scale safely.
Advanced tips and resources
Once your scraper is stable, you can start optimizing it for performance and flexibility. These are the same strategies professional data teams use to keep pipelines efficient and resilient.
Use headless browsers
When pages rely heavily on JavaScript, use Selenium or Playwright for Java to render and extract data. Both can run in headless mode, meaning the browser operates without a visible window (faster and more efficient for automation).
Playwright's async API and built-in waiting mechanisms often make it smoother for large-scale projects.
See the Playwright for Java documentation and Selenium WebDriver guide for setup and performance tuning.
Integrate third-party APIs or services
For high-volume or complex scraping, APIs that handle IP rotation, CAPTCHA solving, and JavaScript rendering can save you a lot of engineering time. They simplify scaling – you call a single endpoint and get cleaned, structured data back. This approach lets your team focus on business logic rather than infrastructure.
With Decodo's Web Scraping API, you don't need to worry about proxy integration, JavaScript rendering, or rate limiting. It allows you to specify a target URL and return data in formats like HTML, JSON, CSV, or Markdown.
Get Web Scraping API
Claim your 7-day free trial of our scraper API and explore full features with unrestricted access.
Further reading
Bookmark the official docs for your main tools:
- Jsoup documentation – parsing and selectors
- Java HttpClient API docs – advanced networking options
- Gson documentation – JSON serialization
- OpenCSV documentation – CSV exports
For deeper insights, explore GitHub repositories of open-source scrapers, or join developer forums like Stack Overflow and Reddit's r/webscraping. The more real-world examples you see, the better your sense of what scales and what breaks in production.
Final thoughts
With Java, you now have a full toolkit for scraping: HttpClient for fetching, Jsoup for parsing, Selenium and Playwright for dynamic pages, plus Gson/OpenCSV for clean exports. This combination covers static sites, complex interactions, proxies, and structured data output.
What comes next is refinement. You can scale with parallel scraping, add pagination, reuse extractors across similar sites, or automate scheduled runs. Tailoring these building blocks to each project is what turns a basic scraper into a fast, reliable Java pipeline.
About the author

Justinas Tamasevicius
Director of Engineering
Justinas Tamaševičius is Director of Engineering with over two decades of expertise in software development. What started as a self-taught passion during his school years has evolved into a distinguished career spanning backend engineering, system architecture, and infrastructure development.
Connect with Justinas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.