How To Build a News Crawler in Python: Step-by-Step Guide
A news crawler is a tool that automatically pulls content from news websites. A web news crawler helps with tracking competitors, feeding LLM pipelines, or watching topic coverage across publishers. This guide walks you through building a configurable proxy-integrated Python news crawler that’ll target multiple news sources, handles proxy rotation, and saves structured results on a schedule.
Kipras Kalzanauskas
Last updated: Jun 03, 2026
12 min read
TL;DR
- We'll build a Python news crawler using Requests and Beautiful Soup. It will target 3 real news sites: TechCrunch, Ars Technica, and Reuters Technology.
- The architecture will be config-driven. Adding a new source will be a config change, not a code one.
- We'll cover proxy rotation with Decodo residential proxies for sites that rate-limit aggressively.
- Scheduling will use the lightweight schedule library, whereas output will be timestamped JSON for easy archiving.
- Async upgrade via httpx + asyncio will be shown as an optional next step for larger source lists.
Why build a news crawler?
News data is one of the most useful raw materials in modern dev work. Some common reasons to crawl include:
- Feeding content pipelines that summarize or rewrite stories for newsletters.
- Building topic monitors that alert when a keyword surfaces across news publishers.
- Pulling fresh training inputs for LLMs or retrieval-augmented generation systems.
- Tracking competitor coverage or PR mentions.
The catch is that scraping news websites are one of the trickier scraping jobs out there. Every outlet has its own HTML structure. Some have rotating CSS classes, while most have at least light bot detection, and a few use heavy systems like Akamai or Cloudflare.
That's why we're not just hardcoding selectors for one site. We'll build a config-driven crawler that scales to many sources. If you're wondering how crawling differs from scraping, our web crawling vs. web scraping post covers the distinction.
Prerequisites and environment setup
You'll need Python 3.10 or newer, plus a few libraries. Here's the setup.
Create a virtual environment
Install dependencies
What each library does:
- Requests – the standard Python HTTP client, synchronous, simple, and well-documented.
- Beautiful Soup – parses HTML and lets you query it with CSS selectors.
- httpx – an async-capable HTTP client that uses the same API shape as Requests. Optional, but useful when you outgrow synchronous crawls.
- python-dotenv – loads environment variables from a .env file. It keeps your proxy credentials out of the source code.
- schedule – a tiny cron-like library for running functions on an interval, no framework needed.
Project structure
How to get your Decodo credentials
To get your credentials, sign up or log in at decodo.com.
Residential proxy credentials
- Go to the Dashboard and select Residential from the left sidebar.
- You should land in the Proxy Setup tab. Your proxy endpoint, port, username, and password are listed here.
- Copy the Username and Password and paste them into your .env file:
Note that you have to create the .env file yourself.
Web Scraping API token
- From the left sidebar, go to Scraping APIs → Web Scraping API.
- Your Basic authentication token should be automatically generated. You can also find your username and password in the Authentication settings next to the copy icon.
- Copy the generated Base64 token.
Never commit your .env file to version control. Add it to .gitignore to keep your credentials safe.
Selecting target news websites
Before writing scraper code, you should evaluate each target site. Different sites have different HTML structures, anti-bot protections, crawl limits, and content quality. Picking stable, scrape-friendly sources improves your crawler’s reliability.
Check robots.txt first
Every site exposes a robots.txt file at its root. It tells crawlers which paths are off-limits. Always check it before you write a single line of scraping code. Look for Disallow rules covering the paths you want. Crawling against a published Disallow rule is both unethical and legally risky.
The robots.txt tells you a lot about how aggressively a site will fight back. Compare TechCrunch and Reuters side by side:
TechCrunch and Ars Technica – scraping-friendly
TechCrunch’s wildcard rule blocks only wp-admin and search paths. Everything else, including /latest/, is open. A plain requests call with a browser User-Agent is enough without involving any proxies. Just like TechCrunch, Ars Technica does not need a proxy either.
Reuters – heavily protected
Reuters takes the opposite approach: the Disallow: / rule under the wildcard user agent blocks all unrecognized bots. In addition, Reuters explicitly lists more than 80 individual bots and uses Akamai’s server-side bot detection. As a result, a standard requests call returns a 401 response regardless of the User-Agent header. This is why we use Decodo’s Web Scraping API for Reuters. It handles JS rendering and anti-bot bypass server-side, while a simple residential proxy is enough for scraping-friendly sites like TechCrunch.
Look for an RSS feed
Many publishers expose RSS at a known path:
- TechCrunch –
https://techcrunch.com/feed/ - Ars Technica –
https://feeds.arstechnica.com/arstechnica/index - Reuters –
https://feeds.reuters.com/reuters/technologyNews
If your use case only needs headlines and summaries, RSS is simpler and more stable than HTML scraping. The trade-off is that feeds rarely include the full article body, author details, or category tags. If you need that data, HTML scraping is the way.
Check the HTML structure
There are several things to check in the HTML structure before continuing with the crawler. Open DevTools on each target site, find a headline, and inspect it for:
- Is the headline in a semantic tag like h2 or h3?
- Is the parent an article element with a stable class or data- attribute?
- Do the CSS classes look human-readable (post-block__title) or is it auto-generated (sc-3xy21z)?
Auto-generated classes are a red flag because they change. Instead, pick selectors that hang off semantic structure whenever you can. Our guide on how to inspect elements walks through DevTools in more detail. If you're choosing between CSS selectors and XPath, our CSS selectors vs. XPath post covers the trade-offs.
Test rate-limit tolerance
Try hitting the same page 5-10 times in quick succession with curl and watch what comes back. If you see 429 responses or CAPTCHA challenges after just a few hits, that site needs a proxy. Reuters falls into this category, while TechCrunch and Ars Technica are usually more permissive, but still deserve crawl delays.
If you're scraping a news aggregator like Google News instead of individual publishers, that's a different beast. Our how to scrape Google News with Python guide covers that approach.
Scraping specific news sources
Now we build the architectural core, which includes a config dictionary, plus a generic parsing function. Adding or updating a publisher only requires editing the configuration, not rewriting crawler code. The selectors below were accurate at the time of writing. If your crawler suddenly returns zero results from one source, that's the first thing to check. We'll add monitoring for this later.
The SOURCES config
Create a config.py file with the following contents:
A few notes on this structure:
- crawl_delay_seconds lets each site set its own pace. Reuters gets 5 seconds between requests because it's stricter. TechCrunch and Ars Technica are fine with 2.
- use_proxy is a per-site flag. We'll wire up proxy routing in a later section. For now, all 3 sources stay direct.
- We picked data-testid selectors for Reuters because data- attributes are more stable than CSS classes. Class names get renamed across redesigns, but test IDs rarely do.
Imports and logging setup
Now create a scraper.py file, import the required libraries, and enable logging so you can track crawl progress and failures.
Safe text extraction helper
Some selectors will fail occasionally because optional fields like author, names, or dates may not exist. Returning None avoids unnecessary crashes.
Fetch pages safely
Now create a helper that downloads HTML safely:
Using a shared requests.Session() improves performance by reusing connections across requests.
Extract structured object
Build a structured article object from a matched HTML element.
Parsing article data
The parser uses selectors from config.py to extract titles, URLs, authors, dates, and categories from each article card. Beautiful Soup parsing patterns can load content dynamically with JavaScript rather than returning full HTML from the server. For those cases, you’ll need a headless browser or JS rendering.
Wrap everything into a reusable NewsCrawler class
What's worth noting:
- requests.Session() reuses the underlying TCP connection across requests to the same domain. Without it, you'd be opening a fresh connection for every request, which is an unoptimized process.
- The User-Agent header makes us look like a regular Chrome browser, which is a sign of genuine human traffic. The default Python User-Agent (python-requests/2.x) would be a giveaway and most sites would flag it immediately.
- The try/except in crawl_all() wraps each source independently. If Reuters fails, TechCrunch and Ars Technica still run. In turn, one broken source doesn't kill the whole crawl.
- The seen_urls set prevents duplicates when stories get syndicated. Reuters might publish a story that TechCrunch picks up. We only want it once.
- crawl_all() returns a payload envelope with a timestamp, source order, run stats, and the article list. This makes it easy to track crawl health over time.
Run the script:
You should see output like this:
The Reuters failure in the output above isn't a bug. It's expected because Reuters blocks standard requests. Next, we'll add proxy-based fetching to handle protected sites.
Async upgrade path
For 3 sources, sequential crawling is fine. But if you’re going with 30 sources, you'll want async. The change is small – just swap Requests for httpx and use asyncio.gather():
The trade-off is that you lose per-source crawl delays, unless you sleep inside each task. For most news crawling at moderate scale, synchronization is enough.
Bypassing rate limits with rotating proxies
As shown above, some news sites blocks standard scraping requests. You'll encounter the same challenge on many heavily protected sites, especially when sending repeated requests from a single IP.
Why residential proxies work
Datacenter IPs (AWS, GCP, DigitalOcean) are easy to flag because their IP ranges are public and known, and bot-protection services pre-score them as high risk.
Residential proxies, on the other hand, use IPs assigned to real home internet connections. Using these IPs, Akamai or Cloudflare see your requests as those from regular visitors browsing from home. That's a much harder pattern to block.
For more on how rotation works, our what are rotating proxies post explains the basics. For a bigger picture on bot detection, read our anti-scraping techniques and how to outsmart them post.
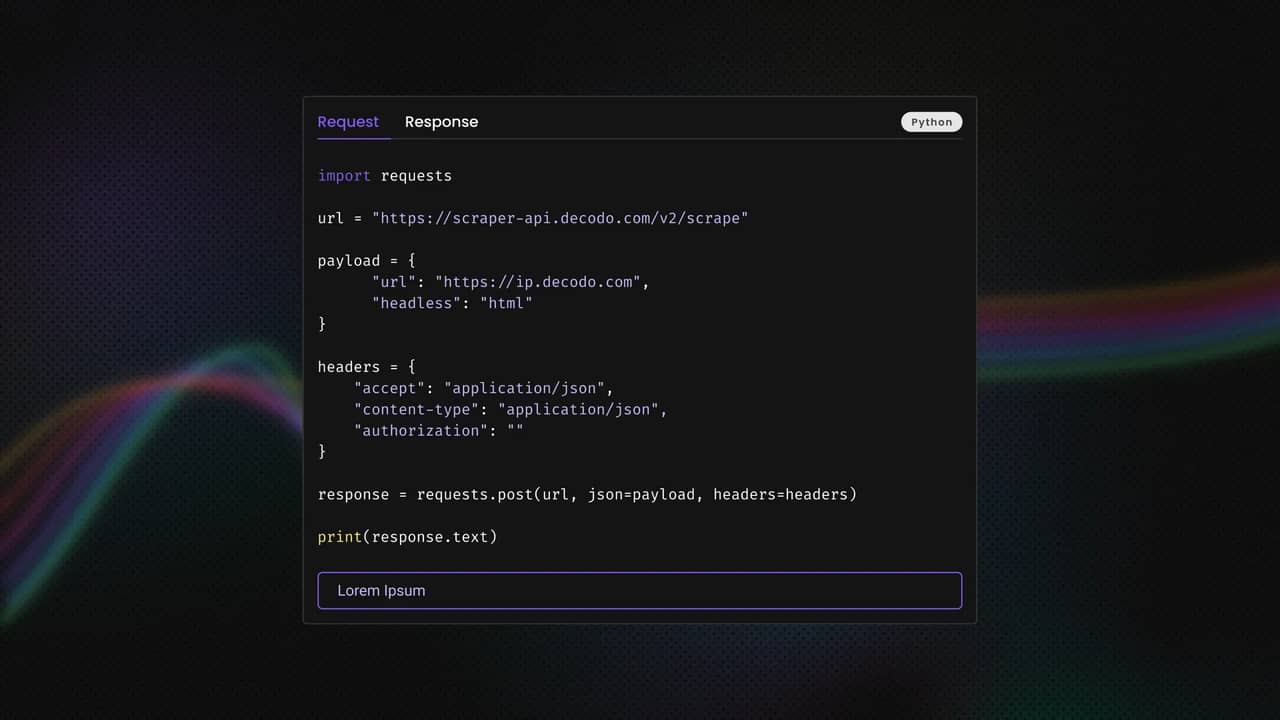
Wiring up Decodo proxies
Open .env and fill in your real Decodo credentials.
Get your web data project off the ground
Set up residential proxies or plug into our Web Scraping API in minutes
Update scraper.py to add 3 fetch paths
It follows these patterns:
- Plain Requests for permissive sites.
- Residential proxy for moderate targets.
- Decodo Web Scraping API for hard ones like Reuters
Add these imports to scraper.py
Without these imports, proxy and API authentication would fail
Add proxy helper functions
Place these below safe_text(): It centralizes authentication logic so that credentials are handled in one place instead of scattered across the crawler.
Replace fetch_page() with 3 fetch methods
Delete the old:
Replace it with the following functions:
Different sites need different levels of anti-bot handling. Splitting fetch logic into dedicated functions keeps the crawler flexible without complicating the parser.
Update parse_source() Logic
The crawler now decides how to fetch a page per source instead of using one global strategy for every site.
Replace the fetch logic inside parse_source() with:
Update the crawler constructor
The proxy URL gets built once during startup instead of on every request, which keeps request handling simpler and slightly more efficient.
Inside NewsCrawler .__init__() class add:
Update crawl_all() method of the NewsCrawler class
Replace only this line
with
Enable the Decodo scraper for Reuters
Update the Reuters config:
The full scraper.py code
Storing and exporting crawled news data
In-memory results are gone the moment your script crashes. We need durable storage.
Timestamped JSON files
Create storage.py:
The full payload gets written, not just the article list. So, the saved file includes the crawled_at timestamp, sources_crawled list, and stats block. Useful when you want to track crawl health over time.
CSV export
If you'd rather feed the data into a spreadsheet, here’s the code snippet for generating CSV output:
The full storage.py code
Beyond JSON and CSV
Once your archive grows, you'll want something queryable:
- SQLite – a local file-based database. Drop in sqlite3, and you can query "all Reuters articles tagged AI from the last 24 hours."
- PostgreSQL – worth it once you have multiple crawlers writing to the same place, or web dashboards reading from it.
- Vector database – for LLM-powered retrieval. Embed each article's title and summary, then query by semantic similarity. Pinecone, Weaviate, and pgvector all work.
For more on storage options, see our how to save your scraped data post.
Re-run the crawler. Reuters should now work.
Here’s a sample result:
When to reach for Site Unblocker
Some websites are protected beyond what rotating residential proxies can reliably bypass. Platforms using advanced bot detection systems like Cloudflare Turnstile, DataDome, or Akamai often inspect far more than just your IP address.
They analyze:
- browser fingerprints
- TLS signatures
- request behavior
- mouse and navigation patterns
- CAPTCHA completion signals
At that level, simply rotating IPs is no longer enough.
For those, Decodo Site Unblocker handles the heavy lifting at the proxy layer. You point your Session at it the same way as a regular proxy. The work happens server-side.
The schedule library
The simplest option is the schedule library just using Python. A scheduled crawl is useful 50 times an hour without you doing anything.
Create scheduler.py and insert the following, production-ready code:
Why 30 minutes? News sites publish frequently, but most don't drop new stories every 5 minutes. A 30-minute interval keeps your data fresh without hammering the targets. For breaking-news monitoring you might go to 10 or 15 minutes. Avoid going under 10 unless you really need to.
The zero-results check matters more than it looks. If every source returns nothing, that's almost certainly a selector that broke (a publisher redesign), not a slow news day. Logging a warning instead of overwriting yesterday's good data saves your archive.
Production scheduling
The schedule library runs in the foreground. That's fine for a script you keep open, but for production, consider:
- cron – the classic Unix scheduler. Run python scraper.py every 30 minutes via crontab to keep it simple and reliable.
- APScheduler – Python-native scheduler with more features. Good if you need conditional jobs or persistence across restarts.
- Cloud schedulers – AWS EventBridge, Google Cloud Scheduler, or GitHub Actions cron. These let you run the crawler without a server you're managing.
For a full treatment of scheduling options, see our how to automate web scraping tasks post.
Final thoughts
The architecture we built keeps each piece swappable. Want to add Wired or The Verge? That's a config entry. Want to swap Requests for httpx? The crawler class is the only thing that changes. Want to swap JSON for SQLite? The storage module is the only thing that changes.
A few practical things worth remembering for production runs:
- News site HTML changes. Build a monitoring function into your crawler to get alerts when a source consistently returns zero results, because that's the main signal that a selector is broken.
- Be a polite crawler. Honor robots.txt, set realistic crawl delays, and don't hit the same page every 5 seconds.
- Save every crawl run. Storage is relatively inexpensive and historical data lets you run analyses you didn't plan for at build time.
When proxies and stealth headers stop being enough, look at managed solutions like Decodo's Web Scraping API. It handles JavaScript rendering, CAPTCHA solving, and IP rotation in a single endpoint. That helps when individual maintenance becomes the bottleneck.
Get premium proxy solutions now
Integrate our proxies and scraping API into your news crawling tool stack to stay in the loop
About the author

Kipras Kalzanauskas
Senior Account Manager
Kipras is a strategic account expert with a strong background in sales, IT support, and data-driven solutions. Born and raised in Vilnius, he studied history at Vilnius University before spending time in the Lithuanian Military. For the past 3.5 years, he has been a key player at Decodo, working with Fortune 500 companies in eCommerce and Market Intelligence.
Connect with Kipras on LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.