How to Use a Cloudflare Scraper for Data Extraction
Cloudflare protects over 20% of all websites, and its anti-bot system can shut your scraper down in seconds. A Cloudflare scraper is any tool or script that gets past those defenses to pull data from protected sites. This guide breaks down how Cloudflare spots bots, why most scrapers fail, and how to scrape with Decodo's Web Scraping API.
Mykolas Juodis
Last updated: Apr 23, 2026
7 min read
TL;DR
- Cloudflare blocks scrapers using TLS fingerprinting, JavaScript challenges, and behavior checks, not just IP bans.
- Plain Python Requests or curl won't cut it, since they can't run JavaScript or fake a real browser's fingerprint.
- Headless browsers like Playwright help, but they still need stealth patches to stay hidden.
- Residential proxies beat datacenter IPs for serious Cloudflare bypass work.
- The fastest route is a scraping API that handles JavaScript, CAPTCHAs, and proxies for you – like Decodo's Web Scraping API.
What is a Cloudflare scraper?
A Cloudflare scraper is any tool designed to extract data from websites sitting behind Cloudflare's protection. Think of Cloudflare as a bouncer at a club. It checks who you are, how you move, and whether you look like you belong. If anything feels off, you're out.
Standard HTTP libraries like Requests or curl walk up to that bouncer wearing sneakers at a black-tie event. They don't run JavaScript. They don't match real browser fingerprints. They get turned away at the door.
By the end of this guide, you'll understand how Cloudflare's detection works. You'll know the mistakes that get most scrapers blocked. And you'll have a working scraper for Cloudflare-protected sites built with the Decodo Web Scraping API – using a real example on G2.com.
If you're new to this field, start with our intro to what is web scraping.
What is Cloudflare and how does it block scrapers?
Cloudflare is a CDN (the network that speeds up websites by caching them globally) and security service sitting between users and websites. Over 20% of the web runs through it. When you send a request to a protected site, Cloudflare inspects you first, scores you, and then decides whether to let you through.
That scoring system is called Bot Management, and it runs on multiple detection layers at once.
TLS fingerprinting
TLS (Transport Layer Security) is the handshake that happens when your client connects over HTTP(S). Every browser has its own TLS "signature" – the order of ciphers it supports, the extensions it uses, and so on. Cloudflare checks that signature against known browser fingerprints. If your Python script sends a TLS handshake that doesn't match Chrome, Firefox, or Safari, it stands out like a tourist with a map.
JavaScript challenges
Cloudflare serves small JavaScript puzzles to every visitor. Real browsers solve them silently in the background. Scripts using Requests can't because they don't run JavaScript at all. No solution, no access.
For more on handling JS-heavy pages, see our guide on how to web scrape dynamic content.
Behavioral analysis
Cloudflare watches how you browse. Do you jump straight to a product page with no homepage visit? Do you click faster than humanly possible? Do you request 500 pages in 10 seconds? All red flags.
Turnstile CAPTCHAs
Turnstile is Cloudflare's replacement for the classic "I'm not a robot" checkbox. It runs behind the scenes, testing browser capabilities without bothering the user. If your scraper can't pass, you'll see a challenge page instead of the data you wanted.
When any of these checks fail, you get 1 of 3 things back: a challenge page, a 403 Forbidden error, or a full IP ban. For a deeper look at error responses, check out our breakdown of error code 1010. To see the wider picture, our article on anti-scraping techniques and how to outsmart them covers more detection methods.
Why Cloudflare blocks scrapers and common mistakes developers make
Most failed scrapers don't get caught because Cloudflare is magic. They get caught because they make the same small mistakes over and over. Let's walk through them.
Why Cloudflare blocks you
- Your browser fingerprint is missing or doesn't match a real browser. Headers say Chrome, TLS handshake says Python – game over.
- Your scraper can't execute JavaScript, so challenge scripts go unsolved.
- Your IP is suspicious. Datacenter IPs, public proxy ranges, and blacklisted addresses light up immediately.
- Your request pattern looks robotic. Too fast, too uniform, no homepage visit – these are classic bot tells.
Common developer mistakes
- Using Python Requests or curl alone. They're great tools, but they can't solve JS challenges or pass fingerprint checks. It's like showing up to a chess tournament with checkers pieces.
- Copying static headers from your browser into your script. Headers alone won't save you – Cloudflare looks at a long list of signals at once, and headers are just one.
- Using free or public proxies. These are the cheap hotels of the proxy world – everyone's stayed there, and the place is already flagged. Many are also insecure, so you're risking your own data. See our guide on how to test proxies before trusting any.
- Hammering a single IP at full speed. Rate limits kick in fast, and once you're flagged, you're stuck. If you hit timeouts, our post on Python requests retry covers graceful backoff.
- Ignoring cookies. Cloudflare drops a cf_clearance cookie once you pass its checks. Throw it away, and you'll have to re-verify on every request.
- Jumping straight to the data page. Real users visit the homepage first, load assets, maybe click around. Skipping that warm-up is like walking into a meeting halfway through and starting to talk.
Techniques for JavaScript rendering and CAPTCHA solving
Getting past Cloudflare means handling 2 separate problems: running the JavaScript challenges and solving CAPTCHAs when they appear. Here's what actually works.
JavaScript rendering options
Headless browsers – tools like Playwright and Puppeteer run a real Chrome or Firefox instance in the background. They execute JavaScript, load assets, and behave like a visitor. The catch? Out of the box, they still leak bot signals (like the navigator.webdriver flag), and Cloudflare picks those up fast. If you're new to this, our what is a headless browser post covers the basics.
Stealth plugins – libraries like playwright-stealth and puppeteer-extra-plugin-stealth patch those leaks. They spoof browser fingerprints, hide automation flags, and make your headless session look more human. We generally prefer Playwright for this work – see our Playwright web scraping guide for a full walkthrough.
Undetected ChromeDriver and SeleniumBase UC Mode – these are patched versions of Selenium that handle basic detection automatically. Good starter options if you're already in the Selenium world.
curl_cffi – this is a clever middle ground. curl_cffi is a Python library that impersonates browser TLS fingerprints without the overhead of spinning up a full browser. Lighter than Playwright, stronger than plain requests. Great when you don't need full JS execution but do need a realistic handshake.
CAPTCHA handling
Turnstile runs silently and needs a full browser environment to pass. Plain scripts can't touch it. Your options:
- Use a headless browser with stealth patches and hope Turnstile resolves on its own.
- Plug in a third-party CAPTCHA solver like 2Captcha or CapSolver. They charge per solve, but they work when automation hits a wall. For the general strategy, see how to bypass Google CAPTCHA.
- Use a scraping API that handles JavaScript execution and CAPTCHA solving in 1 call. This is where most production scrapers end up – the math on maintenance time usually favors an API.
Advanced tips: rotating proxies and geotargeting
Once you've got JavaScript and CAPTCHAs under control, your next battleground is IP reputation. Cloudflare bans by IP as fast as it bans by fingerprint. Here's how to stay ahead.
Proxy rotation
Rotating proxies spread your requests across many IPs, so no single address gets hammered into a ban. Think of it like a relay race – each runner handles a short leg, then passes off before getting tired. Our guide on rotating proxies goes deeper.
- Residential proxies – real IPs from real households. To Cloudflare, these look exactly like regular users on home internet. Highest success rate, and the top pick for serious Cloudflare work. Decodo's residential proxies pool has 125M+ IPs from real households worldwide.
- Datacenter proxies – faster and cheaper, but Cloudflare spots datacenter IP ranges easily. Fine for sites with light protection, risky for heavily guarded ones.
- ISP proxies – static residential IPs hosted on ISP infrastructure. You get the speed of a datacenter and the legitimacy of residential in one. Great for session-based scraping where you need the same IP across multiple requests. See Decodo ISP proxies.
For more on the residential vs. datacenter split, see what is a residential proxy network. If you need a new IP on every connection, our post on how to generate a random IP address breaks that down.
Geotargeting
Some Cloudflare rules are region-specific. A request from São Paulo might face a harder challenge than one from New York for the same US site. A few quick rules:
- Match your proxy country to the site's primary audience. Scraping a US retailer? Use US IPs.
- Use geotargeting to access content that's only visible in certain countries.
- Decodo's rotating proxies support country, state, and city-level targeting.
Session management
Sticky sessions let you keep the same IP across several requests. That matters when you're logged in, adding items to a cart, or scraping paginated results – breaking the session breaks your cookies.
Warm up your sessions. Visit the homepage first, load some assets, accept the cookie banner, then go to the data page. Skipping this looks unnatural. It's the difference between walking into a coffee shop and ordering, versus sprinting past the counter straight to the pastry case.
Scraping Cloudflare-protected sites with Decodo Web Scraping API
Time for the hands-on part. We'll scrape G2.com, a review platform for business software sitting behind Cloudflare. Our target: the Slack reviews page, where we'll pull ratings, reviewer names, and review bodies.
Why G2? It's a real, high-traffic, Cloudflare-protected site with structured data that's genuinely useful for market research.
Get Decodo Web Scraping API
- Sign up at Decodo's dashboard – there's a 7-day free trial, so you can test the tool before paying.
- From your dashboard, grab the Web Scraping API token.
- Store it in a .env file, never in your source code. Committing API tokens to GitHub is how weekends get ruined.
Set up your Python environment
You'll need Python 3.8+ and 3 libraries: Requests for HTTP calls, python-dotenv for loading your .env file, and Beautiful Soup for parsing HTML. Install them with pip:
Now create 2 files in your project folder:
Add your API basic authentication token to an .env file:
Make your first API request
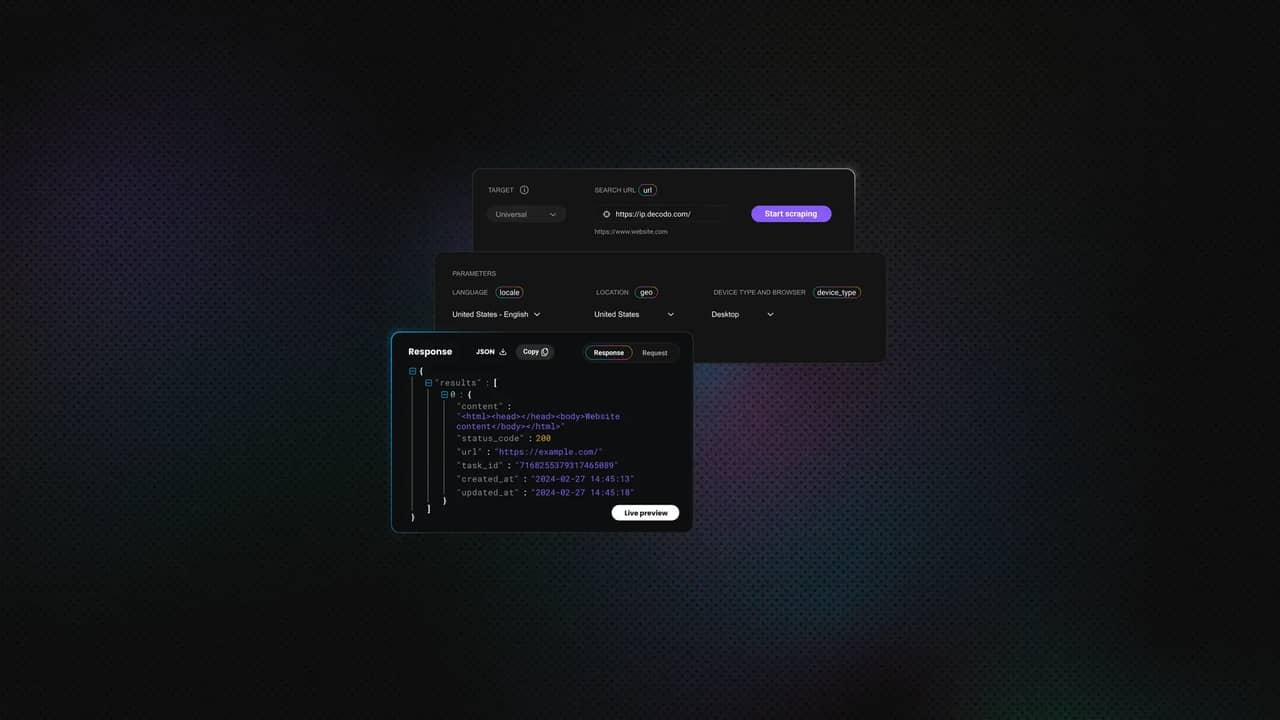
The Decodo Web Scraping API takes your target URL and runs it through a real browser. JavaScript rendering and Cloudflare bypass happen automatically. You get back the fully rendered HTML, and proxies, fingerprints, and CAPTCHAs are all handled server-side.
Heads up on timing – a Cloudflare-protected page with JavaScript rendering turned on isn't instant. Give your request a generous timeout, since 15 to 20 seconds of round-trip time is normal for these pages.
We'll build the script in 4 small pieces, then show the full thing at the end. The target is G2's Slack reviews page, and we'll extract the rating, author, and body for each review.
Imports and configuration
Open your scraper.py file and start with the imports, the token, and the two URLs. The token comes from .env via python-dotenv, which keeps your credentials out of source control.
Two things to note here:
- SCRAPING_URL is Decodo's API endpoint – that's where we POST our request, not the G2 URL directly.
- AUTH_HEADERS uses Basic {TOKEN} as the Authorization value. The API treats this as your credentials.
The scraping function
Next, a function that sends the request and handles whatever comes back. The tricky bit with scraping isn't the happy path – it's the failures. This function covers the 5 main cases. A successful response. Empty results. HTTP errors like 401 and 403. Network timeouts. And anything else that might blow up. Your calling code only ever deals with clean strings or dicts.
The 3 parameters in the JSON body are doing the heavy lifting:
- url – the target page you want rendered. G2's Slack reviews URL in our case.
- headless set to "html" – renders the page in a real browser and hands back the final HTML. This is what gets past Cloudflare.
- geo set to "United States" – sends the request from a US residential IP. This lines up with G2's main audience and avoids friction with geo-based rules.
response.raise_for_status() is the quiet hero here. Any 4xx or 5xx response jumps straight into the HTTPError branch, so we can react to specific codes. If your token is wrong you'll get 401. If Decodo reached the page but got blocked anyway (rare) you'll get 403.
Parsing the HTML
Getting the HTML back is half the job – next we pull out the reviews. G2 marks up its review elements with itemprop microdata attributes (Schema.org). These are far more stable than CSS class names, which change every time the site gets a redesign.
Walk-through of what happens inside the loop:
- soup.select('[itemprop="review"]') finds every review block on the page.
- Inside each block, we grab the rating, author, and body using the same microdata pattern.
- The title is a best-effort summary – we take the text up to the first question mark, trimmed to 80 characters. G2 reviews tend to start with a question like "What do you like best about Slack?", so this gives us a usable headline for free.
- The body is trimmed to 150 characters with an ellipsis, so console output stays readable.
Running it
Now we wire it all together at the bottom of the file – scrape, parse, and print the first 5 reviews.
Run it with:
That character count is your sanity check. A tiny response usually means a challenge page slipped through instead of the real content. Anything north of 100 KB for G2 is a good sign.
The full script
Here's everything glued together, ready to copy into scraper.py:
Example output
A successful run prints output like this:
From here, you can save to CSV, push to a database, or feed into a dashboard. Our guide on how to save your scraped data covers the common output formats.
New to the Requests library or Beautiful Soup? Our primers on mastering Python requests and Beautiful Soup web scraping cover the fundamentals.
If you need something even more hands-off, Decodo Site Unblocker handles anti-bot measures, CAPTCHAs, and fingerprinting automatically – drop-in proxy replacement, no API changes needed.
Best practices for reliable Cloudflare scraping
A scraper that works today but breaks next Tuesday isn't much use. These habits keep things running long-term:
- Rotate user agents per session, not per request, so fingerprints stay consistent within a session.
- Add randomized delays between requests – 2 to 5 seconds minimum. Uniform timing is a classic bot tell.
- Use residential proxies for heavily protected sites. The cost premium pays for itself in success rate.
- Watch response sizes. A 2 KB response when you expected 200 KB usually means a challenge page, not real content.
- Start with a single URL, confirm it works, then scale up. Don't run 10K requests before you've confirmed one.
- Log every status code and response length. When things break, logs tell you why.
- Respect robots.txt and the site's Terms of Service. Scrape the public stuff, skip the login-gated stuff, and don't overload servers.
Final thoughts
Cloudflare's protection is tough but not unbeatable. The trick isn't a single silver bullet – it's the right mix of JavaScript rendering, realistic TLS fingerprints, clean residential IPs, and sensible session handling.
If you enjoy plumbing, you can wire all of that together yourself with Playwright, stealth plugins, proxy pools, and CAPTCHA solvers. It's a good learning exercise. If you'd rather spend your time on the data itself – which is usually the point – a dedicated scraping API removes the moving parts. You get 1 thing to call and 1 thing to debug.
Whichever route you pick, scrape responsibly. Respect the site's rate limits, skip the sensitive stuff, and follow the law in your jurisdiction.
Get Web Scraping API
Choose the free plan of our scraper API and explore full features with unrestricted access.
About the author

Mykolas Juodis
Head of Marketing
Mykolas is a seasoned digital marketing professional with over a decade of experience, currently leading Marketing department in the web data gathering industry. His extensive background in digital marketing, combined with his deep understanding of proxies and web scraping technologies, allows him to bridge the gap between technical solutions and practical business applications.
Connect with Mykolas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.