Mastering Web Scraping Pagination: Techniques, Challenges, and Python Solutions
Pagination is the system websites use to split large datasets across multiple pages for faster loading and better navigation. In web scraping, handling pagination is essential to capture complete datasets rather than just the first page of results. This guide explains what pagination is, the challenges it creates, and how to handle it efficiently with Python.
Dominykas Niaura
Last updated: Oct 28, 2025
10 min read
TL;DR
- Pagination comes in four main forms. numbered URLs (e.g., ?page=2), cursor-based API tokens, infinite scroll with background API requests, and "Load More" buttons that trigger JavaScript fetches.
- For URL-based pagination, generate requests programmatically by incrementing the page or offset parameter and stop when the response returns no new data or the "Next" button disappears.
- Use Playwright to simulate button clicks or scroll actions when pagination is driven by JavaScript, and watch the Network tab to identify the underlying API endpoint, which you can often call directly.
- Cursor-based pagination requires passing the token returned by each response into the next request. store and forward it in a loop until the API signals the last page.
- When the total page count is unknown, design your scraper to stop when results duplicate or an empty response is returned, and add a hard page limit to prevent infinite loops.
- For session-based or authenticated sites, carry cookies and session tokens between requests using Playwright's context or Requests' Session object to maintain continuous access across pages.
What is pagination in web scraping?
Websites use the pagination system to split long lists of items or search results across multiple pages. Instead of loading thousands of entries at once, pages are divided into smaller chunks, each accessible through links like "Next," "Previous," or numbered buttons at the bottom of the page.
From a web design perspective, pagination improves both performance and usability. It helps pages load faster, reduces bandwidth use, and prevents browsers from crashing under too much content. It also creates a better user experience by making it easier to browse and navigate large datasets. For example, browsing 10 products per page instead of scrolling endlessly through 10,000.
For data extraction, however, pagination introduces an extra layer of complexity. Scrapers must recognize and follow these navigation links, moving from one page to the next while keeping track of what's already been scraped. Each website handles pagination differently – some rely on numbered URLs ("?page=2"), others on AJAX requests or dynamically loaded content triggered by scrolling.
This variability creates three key challenges:
- Detecting pagination structure. You first need to locate how the site organizes its pages: through query parameters, "Load more" buttons, or infinite scroll.
- Maintaining continuity. Each request must remember where the previous one left off to avoid missing or duplicating data.
- Handling dynamic loading. Many modern websites no longer use simple next-page links but instead fetch new data asynchronously as you scroll, requiring headless browsers or JavaScript rendering tools to capture it.
Common types of pagination
Websites use several patterns to organize large datasets, and each one affects how you structure your scraper. Below are the most common types you'll encounter, along with where you might see them in practice:
"Next"/"Previous" buttons
One of the simplest forms of pagination. Each page includes navigation links labeled "Next" or "Previous" to move between result sets. For instance, early versions of eBay and Google Search used this approach. It's easy to scrape by detecting anchor tags that contain those labels and following their href attributes.
Numeric page links
Many eCommerce or news sites display a row of numbered links (1, 2, 3, …) so users can jump to specific pages. Amazon's product listings and LinkedIn search results often use this structure. Scrapers typically loop through URLs by incrementing a query parameter such as "?page=2" or "&p=3."
Infinite scroll
Platforms like Twitter, Instagram, and YouTube continuously load new content as users scroll down. There are no visible page links – instead, data is fetched dynamically through background requests (XHR or API calls). Handling this type requires tools like Playwright or Selenium that can simulate scrolling and wait for new elements to appear.
"Load More" button
A hybrid between pagination and infinite scroll. Clicking a "Load more" or "Show more results" button triggers additional content without changing the URL. You'll see this pattern on websites like SoundCloud or Pinterest. A scraper must repeatedly click the button or replicate the associated network request.
API-based pagination
Many modern sites expose data through APIs that deliver paginated JSON responses. These APIs often use parameters like page, limit, offset, or cursor to navigate between data chunks. This method is common in platforms such as Reddit, GitHub, or Shopify stores. It's the cleanest and most efficient way to collect structured data when accessible.
Other variants
Some sites use dropdowns to select page numbers, arrows instead of text buttons, or ellipses to skip ranges of pages (e.g., "1 … 5 6 7 … 20"). Others rely on tabbed pagination for categories or date filters. While these variations differ visually, they follow the same logic: segmenting content for faster navigation and controlled loading.
How to identify pagination patterns
Before automating pagination, you need to understand how the target website structures and loads new data. This process starts with manual inspection using your browser's built-in developer tools:
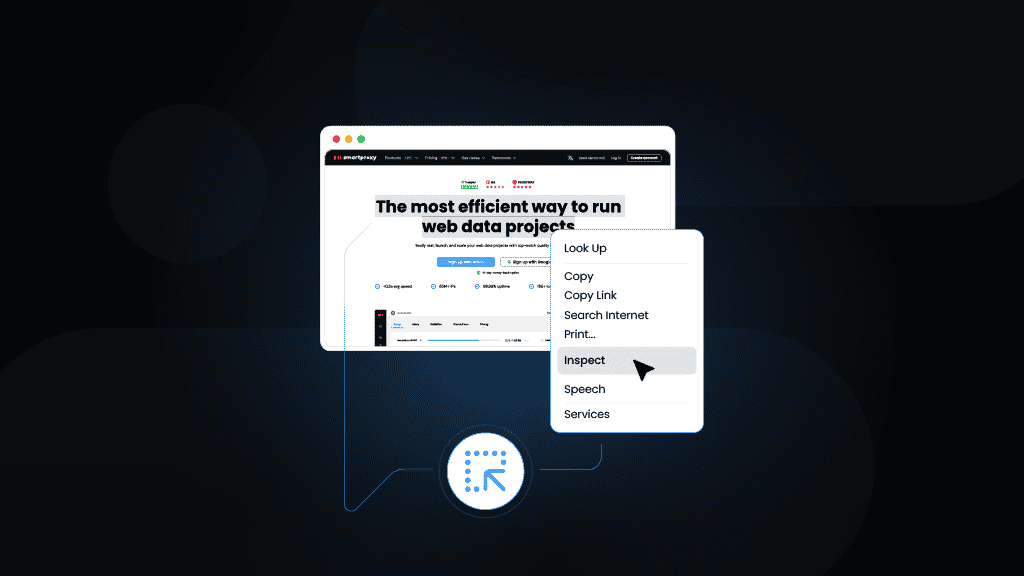
1. Use browser DevTools
To explore a site's structure, open the page you plan to scrape, right-click anywhere, and select Inspect (or press Ctrl+Shift+I / Cmd+Option+I). Switch to the Elements tab to explore the page's HTML. Look for:
- Navigation blocks near the bottom of the content – typically containing anchor tags (<a>) with text like "Next," "Previous," or page numbers.
- URLs containing query parameters such as "?page=2," "&p=3," or "start=20." These indicate server-side pagination where new pages load via URL changes.
- Buttons with attributes like "data-page," "aria-label="next," or custom classes such as ".pagination-next" or ".load-more." These are strong indicators of client-side navigation.
2. Check network requests
Open the Network tab before interacting with the page. Then click the "Next," "Load more," or scroll down if it uses infinite loading. Watch for new requests appearing in the list. Key things to look for:
- XHR or Fetch requests. These often reveal how the site fetches additional data asynchronously. If you see requests returning JSON, that means the site uses API-based pagination.
- Request parameters. Notice recurring variables such as page, offset, cursor, or limit. They show how pagination is controlled behind the scenes.
- Response structure. If the server responds with a list of items instead of full HTML, you can target this endpoint directly for faster, cleaner scraping.
3. Test behavior in the console
Use the Console tab to interact with the page dynamically. For example, you can type "window.scrollTo(0, document.body.scrollHeight)" to simulate scrolling and see whether new results load automatically. If the page updates without a reload, it likely uses infinite scroll or a JavaScript "Load more" function.
4. Identify event handlers
Still unsure? Search the HTML for keywords like "loadMore," "nextPage," or "pagination" in <script> sections. These may reveal JavaScript functions or endpoints used to fetch new data.
Python techniques for scraping paginated data
Different websites require different strategies for handling pagination. Below are common techniques – from simple URL loops to simulating infinite scroll – along with brief Python examples and best practices.
The code snippets in this section demonstrate how these three popular Python libraries can handle pagination as part of a complete scraping script:
- Requests – for sending HTTP requests and handling API-based or static HTML pages.
- Beautiful Soup – for parsing and extracting data from HTML.
- Playwright – for interacting with dynamic or JavaScript-rendered websites.
You can install them with the following two commands in your terminal (see how to run Python code in terminal for a reminder):
Implementing URL-based pagination in Python
Many websites organize paginated content through predictable URL patterns like "?page=2" or "&offset=50." In such cases, you can generate URLs programmatically and iterate through them. This method is lightweight and reliable when the URL structure is consistent. Always inspect the HTML first to confirm the query parameter controlling pagination (e.g., page, offset, or start):
Navigating "Next" buttons with Python
Some websites don't expose page numbers but rely on "Next" or arrow buttons. With tools like Playwright or Selenium, you can locate and click these buttons programmatically until no more pages remain. Here, the scraper finds the "Next" button, clicks it, and waits briefly for the next batch of content to load. Always handle relative vs. absolute URLs correctly when switching between pages:
Handling infinite scroll and "Load more" with Python
Sites using infinite scrolling (like Instagram or YouTube) require simulating user actions to load new content. You can use Playwright to scroll or repeatedly trigger a "Load more" button until no new results appear. This approach works for both endless scrolls and “Load more” buttons that append items dynamically:
Working with API-based pagination in Python
If you spot JSON responses in the Network tab, the website may rely on an API endpoint for pagination. You can scrape data directly from those endpoints, using query parameters such as page, limit, or cursor. This is the most efficient and reliable form of pagination scraping because it avoids rendering HTML altogether. Just remember to respect rate limits and handle errors gracefully with retry logic:
Advanced pagination challenges
Once you've mastered basic pagination handling, you'll often face more complex patterns in the wild. These advanced cases require more adaptive logic and the right scraping tools to maintain stability.
Handling an unknown number of pages
Not every website tells you how many pages of data exist. In such cases, you can design your scraper to continue until no new results are found. For example, after each request, check whether the page returns fewer items than expected or if the “Next” button disappears – both are signs you've reached the end. Adding a maximum page limit is also a good safeguard against infinite loops.
Dealing with JavaScript or AJAX-rendered content
Modern websites frequently use JavaScript to load new content dynamically without refreshing the page. Traditional libraries like Requests and Beautiful Soup won't see that content because it's generated after the initial page is loaded. Tools such as Playwright or Selenium can render pages just like a browser, making it possible to capture dynamically loaded elements. To inspect these requests, open the Network tab in DevTools and look for XHR or Fetch calls that return JSON – these often reveal the underlying API endpoint you can target directly.
Managing session data, cookies, or tokens
When scraping authenticated or session-based pages, your scraper may need to carry cookies, session tokens, or headers between requests. Many sites rely on these to maintain user state or access restrictions. With Requests or Playwright, you can store cookies after login and reuse them on subsequent pages. Be cautious with session expiry – tokens often need refreshing periodically to avoid losing access mid-run.
Recognizing and adapting to complex or hybrid pagination patterns
Some websites mix multiple pagination methods – for example, a "Load more" button combined with dynamic filters or category tabs. Others change pagination behavior depending on user input. These hybrid designs require flexible scraping logic. Inspect both the HTML structure and network traffic carefully to identify which mechanism is responsible for fetching data. In such setups, combining techniques (scrolling simulation, button clicking, and API calls) often gives the most reliable results.
Best practices for web scraping pagination
Scraping paginated websites requires more than just technical precision. It also calls for stability, respect for site resources, and reliable data management. Following these best practices helps ensure smooth, consistent runs even at scale:
Use rate limiting and backoff strategies
Sending too many requests too quickly is a common cause of temporary blocks. Add short, randomized delays between requests or page loads to mimic natural browsing behavior. For larger-scale scrapers, implement an exponential backoff strategy – increasing the wait time after each failed request before retrying. This not only helps you stay under rate limits but also keeps sessions stable.
Respect site guidelines
Before running your scraper, check the site's robots.txt file to understand which pages can be crawled. Many websites also outline acceptable use policies or API access rules in their terms of service. Following these helps prevent disruptions and maintains good scraping hygiene.
Add error handling and retry logic
Network hiccups, slow responses, or occasional CAPTCHA triggers are inevitable. Wrap your requests in try/except blocks and retry failed pages a limited number of times. Include timeout settings and handle different response codes (like 403 or 429) appropriately – for instance, by waiting longer or switching proxy IPs.
Perform data deduplication and consistency checks
When scraping across many pages, duplicates are common, especially if pagination overlaps or resets. Store scraped data in a structured format (like CSV or a database) and use unique identifiers such as product IDs or URLs to remove duplicates. Periodically verify that item counts, timestamps, or pagination indexes align with the expected totals to ensure your dataset remains complete and accurate.
Tools and libraries for scraping paginated sites
Choosing the right tools makes pagination handling much easier. Each Python library has its strengths, depending on whether you're working with static pages, JavaScript-rendered sites, or large-scale projects.
Beautiful Soup
A lightweight HTML parser perfect for small projects and static pages. It works best when paired with the Requests library to fetch page content. Use it when you only need to extract structured data (titles, prices, links) from simple websites that don't rely on JavaScript.
Requests
Handles HTTP requests in a clean and Pythonic way. Ideal for scraping sites with predictable URL-based pagination or API endpoints that return JSON data. It's fast, stable, and easy to debug.
Selenium
A browser automation framework that interacts with websites as if you were a real user. It's suitable for sites where content loads dynamically after scrolling or button clicks. While powerful, Selenium is slower and more resource-intensive, so it's better suited for small or moderate scraping tasks that require full rendering.
Playwright
A modern alternative to Selenium with faster performance and built-in support for headless browsers. It's particularly good for handling infinite scroll, "Load more" buttons, or pages requiring user interaction. Playwright's API is stable and developer-friendly, making it a go-to choice for dynamic pagination scenarios.
Scrapy
A full-featured scraping framework designed for scalability. It includes asynchronous request handling, built-in data pipelines, and automatic pagination through link extraction. Use Scrapy when you need to crawl hundreds or thousands of pages efficiently or maintain long-running scraping projects.
aiohttp
An asynchronous HTTP client library that shines when you need speed and concurrency. Ideal for scraping multiple paginated endpoints in parallel. It's often combined with Beautiful Soup or lxml for parsing.
Web Scraping API
An all-in-one scraper designed for extracting structured data from eCommerce marketplaces, search engine results pages, social media platforms, and many other sites with pagination support. It provides output in HTML, JSON, CSV, or Markdown, and includes 125M+ pre-integrated proxies, JavaScript rendering, and browser fingerprinting for stable, unblockable scraping at scale.
Among its 100+ ready-made scraping templates, several include pagination parameters such as from_page and limit for seamless data retrieval. These cover a wide range of use cases, including:
- Amazon Pricing, Amazon Search, and Amazon Bestsellers
- Google Search with AI Overview, Google Images
- And more!
Try Web Scraping API for free
Activate your 7-day free trial with 1K requests and scrape structured public data at scale.
When to use which tool
The right setup depends on the site's structure, the volume of data you're collecting, and how much control you need over rendering, concurrency, and error handling:
- Use Requests + Beautiful Soup for static HTML pages with simple next-page links.
- Choose Playwright (or Selenium) for JavaScript-heavy sites or when interacting with elements like "Load more" buttons.
- Go with Scrapy for production-level crawlers where scalability and efficiency matter.
- Pick aiohttp if you need asynchronous performance for many lightweight API requests.
- Use Decodo’s Web Scraping API when you want a fully managed, ready-to-use solution for complex pagination and large-scale data collection.
Troubleshooting common issues
Even well-designed pagination scrapers can run into issues like missing data or unexpected blocking. Understanding these most common causes will help you debug faster and keep your scraping sessions consistent:
Missing or incomplete data
If some pages return fewer results than expected, inspect the site's HTML structure again. It may differ between pages or categories. Check that your selectors still match the correct elements, as dynamic sites can rearrange class names or container layouts. Adding a short delay between requests can also prevent pages from loading incompletely.
Anti-bot and rate-limiting measures
Many websites restrict automated access by detecting unusual request patterns. To minimize this, rotate user agents and proxies, and randomize your request intervals. Tools like Decodo's residential proxies with the rotating session type help distribute traffic across multiple IPs, making your scraper appear more like real users.
Boost your scraper with proxies
Claim your 3-day free trial of residential proxies and explore 115M+ ethically-sourced IPs, advanced geo-targeting options, a 99.92% success rate, an average response time under 0.6s, and more.
Dynamic content not appearing
If certain results never load, the page likely relies on JavaScript or AJAX calls. Use a headless browser such as Playwright or Selenium to render the content. You can verify this by checking the Network tab in DevTools for background requests or by viewing the page source. If the data is missing there, it's being generated dynamically.
Unexpected duplicates or pagination loops
If you notice repeated data or infinite scraping cycles, review your pagination logic. Ensure you're correctly identifying the "Next" button or URL pattern and updating it after each page. For API pagination, monitor parameters like page, offset, or cursor to confirm they advance as expected.
Knowing when to stop paginating
Some websites don't explicitly show how many pages exist. In such cases, stop your loop when:
- The next-page button is no longer visible or disabled.
- The latest request returns an empty list or duplicate results.
- The number of items retrieved falls below the expected count per page.
Adding a maximum page limit is a good fallback to prevent accidental endless scraping.
Final thoughts
Pagination is both a design feature and a scraping obstacle. By understanding how pagination works, recognizing its variations, and choosing the right tools, you can reliably scale your data collection without missing valuable information. A flexible scraper built with proper delays, retries, and deduplication logic will handle any site that uses numbered URLs, JavaScript-driven "Load more" buttons, or API endpoints.
Ultimately, pagination is less about complexity and more about precision – structuring your requests, respecting site limits, and ensuring that each page adds meaningful data to your final dataset. With a careful setup and the right Python libraries, even large, multi-page sources can be scraped efficiently and responsibly.
About the author

Dominykas Niaura
Technical Copywriter
Dominykas brings a unique blend of philosophical insight and technical expertise to his writing. Starting his career as a film critic and music industry copywriter, he's now an expert in making complex proxy and web scraping concepts accessible to everyone.
Connect with Dominykas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.