How to Scrape Data and Export in Markdown Format
Want to scrape a website to Markdown? Markdown is a plain-text format that uses simple symbols for structure, making it easy to read, write, and convert. Loved by developers and platforms like GitHub, it keeps content clean and portable. In this guide, you’ll learn how to capture site content and instantly export it in this streamlined format.
Zilvinas Tamulis
Last updated: Aug 14, 2025
12 min read
What is Markdown?
Markdown was created in 2004 by John Gruber as a way to write web content in plain text without wrestling with HTML tags. Its goal was simple: make writing for the web as easy as writing an email, while still allowing clean conversion to HTML. Over the years, it's become the go-to format for developers, writers, and platforms like GitHub, Reddit, and Stack Overflow.
In essence, Markdown is a lightweight markup language that uses plain text formatting to create structured documents. Its syntax is straightforward – hashtags for headings (#), asterisks (*) for emphasis, dashes (-) for lists, and so on. This simplicity makes it effortless to write and just as easy to read. For web content, Markdown stands out for being portable, highly convertible to HTML, and ideal for creating clean, distraction-free documentation or notes.
Why scrape a website to Markdown?
Scraping a website directly to Markdown is like ordering a delicious meal, skipping the messy kitchen, and getting your meal already ready to eat. For use cases such as AI/LLM training, it delivers clean, structured text without the extra fluff, making preprocessing faster and more efficient. For documentation and knowledge bases, Markdown ensures content is both human-readable and machine-friendly, ready to drop into wikis, repos, or static site generators. Having data in Markdown means less time sifting through code soup and more time doing something useful with the content.
Compared to raw HTML, Markdown is refreshingly lean. Modern websites often produce bloated HTML files filled with nested divs, tracking scripts, style tags, and other debris courtesy of site builders and heavy frameworks. Extracting just the content can be tedious and error-prone. With Markdown, you skip the junk entirely – you get headings, lists, links, and text in a format that’s both readable and portable.
Challenges in scraping a website to Markdown
Of course, scraping sites directly to Markdown format comes with its challenges, some technical, some strategic. Knowing what you're up against will help you choose the right tools and methods to get clean, accurate results without headaches.
Handling dynamic and JavaScript-rendered content
Many modern websites load key content only after the initial page request, often via JavaScript. A simple HTML scraper might miss most of the page's actual text, leaving you with an incomplete or misleading page. To capture everything for Markdown conversion, you'll need scraping tools that can render the page, much like a real browser, allowing you to see and extract the whole picture.
Preserving formatting
Scraping isn't just about grabbing text, but also keeping the structure intact. If your scraper can't recognize headings, maintain list items, or correctly format code blocks, you'll end up with messy and difficult-to-read Markdown. Choosing a solution that understands HTML semantics and can translate them accurately into Markdown syntax is essential for clean, usable output.
Excluding unwanted elements
Web pages are often cluttered with content you don't want, such as ads, navigation menus, footers, social media widgets, and more. These elements add noise to your Markdown, making it harder to work with the data. A good scraper should let you filter out irrelevant parts of the page so you're left with just the core content you need.
Dealing with anti-bot measures and rate limits
Frequent or large-scale scraping can trigger a website's anti-bot defenses, leading to CAPTCHAs, limitations, or outright IP bans. Overcoming these barriers often means using rotating, high-quality proxies to stay undetected. Reliable residential proxies, like those offered by Decodo, can help you bypass restrictions and maintain uninterrupted data extraction.
Overview of tools and services for scraping to Markdown
Let's explore some of the tools that can help you skip the manual HTML scraping cleanup and get nicely structured Markdown data in minutes. Here's a quick look at some of the most popular options:
Simplescraper
Simplescraper is a no-code scraping tool with built-in features for exporting to Markdown. You can set it up to make automatic crawls, create reusable recipes, or call their API directly. While it's easy to get started, it's best suited for smaller to medium-scale projects rather than scraping at scale.
ScrapingAnt
ScrapingAnt offers a Markdown transformation endpoint that can take raw page content and convert it to an .MD file format. It's mainly used through the API, meaning you can integrate it directly into your workflows without touching a GUI. This makes it handy for automated pipelines, though advanced filtering may require extra configuration and technical knowledge.
Firecrawl
Firecrawl stands out by providing multi-format output: Markdown, HTML, and JSON, alongside dynamic content handling and batch scraping for multiple URLs. It's aimed at developers who need more control and flexibility in both the scraping process and the final data format.
Apify Dynamic Markdown Scraper
As part of the Apify platform, the scraper is designed specifically for JavaScript-heavy pages, ensuring complete content capture before conversion. It allows for configurable crawling rules and content filtering, so you can easily exclude irrelevant sections while preserving Markdown structure.
Decodo Web Scraping API
Decodo's API combines built-in scraping with automatic proxy rotation to help you avoid restrictions and bans. It supports multiple output formats, including Markdown, JSON, HTML, and tables without requiring extra parsing. With a simple web interface and ready-to-use code examples in cURL, Node.js, and Python, it’s easy for beginners to use and just as convenient for developers to integrate into their projects or use as a starting point.
Scrape to Markdown with Decodo
Get started with Decodo's Web Scraping API's free trial and convert target websites to Markdown right away.
Step-by-step guide: how to scrape a website to Markdown
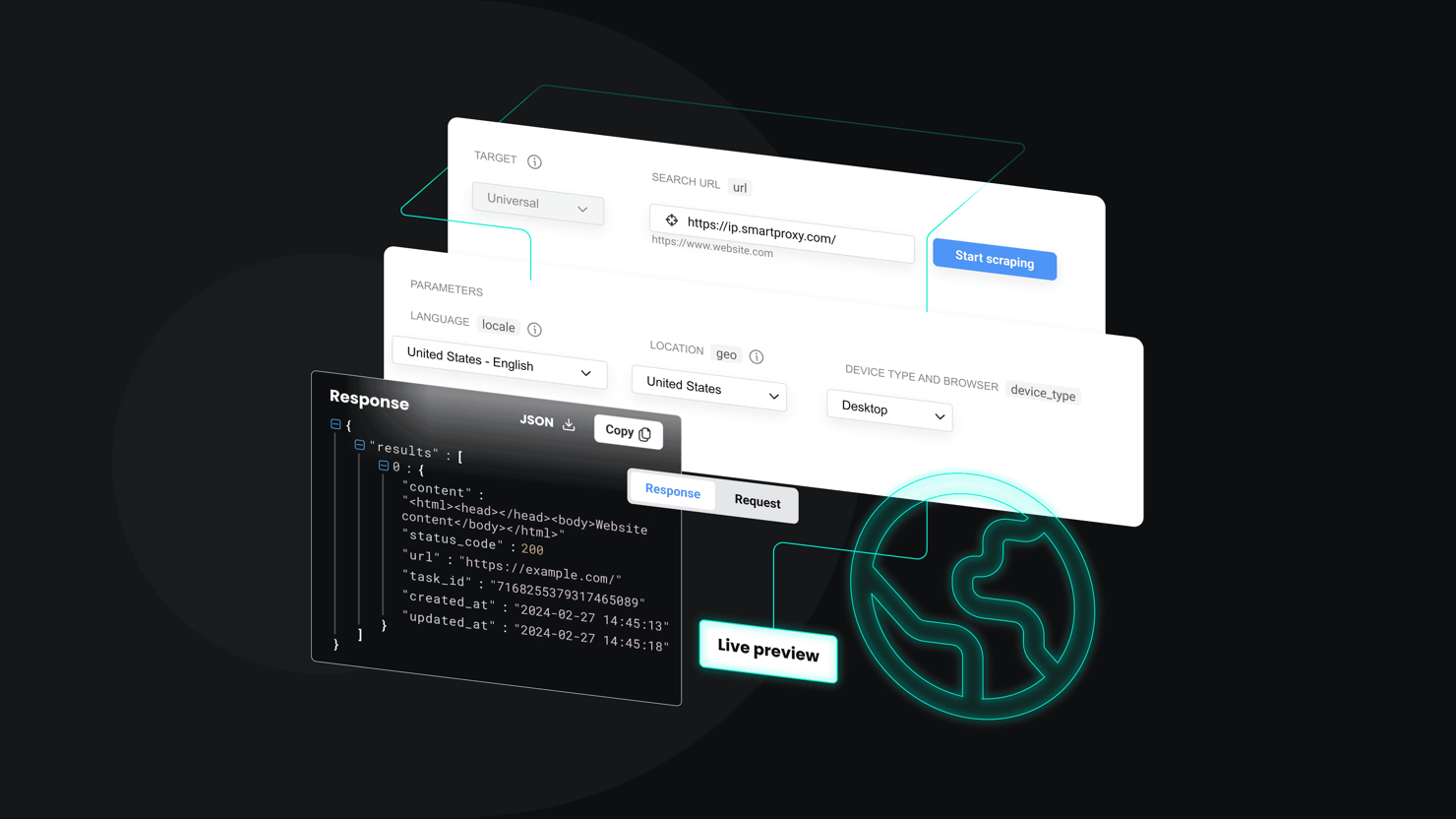
Begin by choosing a tool. In this example, we're going to use Decodo's Web Scraping API, as it's the most straightforward solution with customizability options. You'll go from setting up your first trial request to running full-scale batch jobs in just a few steps.
Use the web interface (beginner-friendly)
If you're entirely new to web scraping or simply want to avoid coding, Decodo's web UI is a great way to get the results you want.
- Sign up for a trial at the Decodo dashboard.
- In the Scraping APIs section, choose the Advanced Web Scraping API.
- Open the Web Scraping API interface.
- For the Choose target section, leave it at the default Web Scraper.
- In the URL field, enter the web page you want to scrape.
- Optionally, add custom parameters like HTTP method, location, language, device type, headers, or cookies.
- Check the Markdown checkbox to set the output format.
- Click Send Request and the API will fetch and convert the page to clean Markdown instantly.
You can see what your Markdown output looks like directly in the preview. You can then click Export and Copy to clipboard and save it in an .MD file.
Use the API with auto-generated code snippets
Once you've configured your request in the dashboard, Decodo automatically generates ready-to-use code snippets in Node.js, Python, and cURL with all your selected parameters (URL, headers, cookies, and Markdown output).
This means you can test in the dashboard for quick result, and if it looks fine, copy the snippet and integrate it into your application.
For example, if you set the output to Markdown, the Python snippet will already include the "markdown: true" parameter. No need for manual changes in the code.
Batch scraping multiple URLs with Python
If you want to scrape multiple URLs at once, you can loop over a list of URLs and send them to the Decodo API in sequence. Here's a Python example:
The above script navigates to the target websites using the Web Scraping API endpoint, scrapes them, and returns results in MD files. These files require no further parsing and can already be used immediately.
Validate and refine the Markdown output
Scraping and saving in Markdown format may possibly lead to a few quirks – malformed links, leftover HTML, spacing issues, or other problems. You can ensure a cleaner Markdown result by following these tips:
Validate the Markdown structure
The most straightforward way to validate Markdown is by manually checking for errors. Here are some of the most common ones:
- Check for broken links by using regular expressions to find [text](url) patterns and verify if URLs are valid with a quick requests.head() call.
- Look for unclosed code blocks by finding backticks (```) and ensure they come in pairs.
- Ensure headings follow a hierarchy, for example, they shouldn't jump from # to ### without ## in between.
- Fix any spacing issues, as empty lines between opening and closing tags will break the formatting.
Remove leftover HTML
Scraped Markdown sometimes contains inline HTML tags. You can clean them with Beautiful Soup or the following regular expression:
Normalize whitespace
Remove empty lines between elements and trim trailing spaces on each line:
Fix images and links
If a site uses relative paths (/images/file.png), convert them to absolute URLs based on the scraped page's base URL:
Run it through a Markdown linter
Use pre-built tools to help sanitize and clean up Markdown, so you can skip the busywork. Try options such as markdownlint, a static analysis tool that helps standardize your MD files for consistency and readability. It's available as a GitHub project and as a downloadable extension in the Visual Studio Marketplace.
Advanced features & customization
Filter for main content
Modify your script to scrape the full Markdown output first, then process it locally to extract only the main sections you need. This lets you keep your data focused and manageable without overwhelming your workflow with unnecessary clutter.
Here's an example of the modified Python file to only scrape the headings and the paragraphs under them:
Using prompts for targeted extraction
You can use AI tools to craft precise prompts that guide the scraper on what content to extract, focusing on specific sections like product details or summaries. With Decodo's MCP server, these prompts can be sent through the Web Scraping API to intelligently retrieve and parse only the most relevant information. This approach combines the power of AI with automated scraping to deliver highly targeted, clean Markdown data without manual filtering.
Setting location and language preferences
You can customize your scraping requests to fetch region or language-specific content by manually adjusting the payload. Add parameters like "geo": "United States" to simulate browsing from that location. Alternatively, Decodo's dashboard interface lets you easily select location and language options from dropdown menus and immediately add them to the code sample.
Check out the official documentation for a full list of parameters and details on how to set them.
Interacting with dynamic pages
Many modern websites rely on JavaScript to load content dynamically, requiring more than a simple HTTP request to capture the full page. Using Playwright, you can simulate real user actions like clicks, scrolls, and waiting for elements to appear before scraping. This lets you fully render interactive pages so your scraper captures all the content you need in Markdown.
Best practices and tips
When scraping to Markdown, follow the usual scraping guidelines:
- Respect robots.txt and website terms of service. Always check robots.txt and the site's terms before scraping, and honor any disallowed paths or crawl-delay rules.
- Avoid overloading servers. Throttle requests per domain, add small random delays, and back off immediately if you see 429 or error spikes to prevent getting blocked.
- Monitor and handle anti-bot protections. Watch for signs like CAPTCHAs, redirects, or unusual error codes, and adjust scraping speed, proxy rotation, or session handling to maintain access.
- Double-check Markdown output for structure and completeness. Parse and lint your Markdown to ensure headings, lists, code blocks, images, and links are correctly converted and nothing important is missing.
Use cases
Web scraping to Markdown isn’t just a neat party trick – it unlocks a variety of practical uses for developers, researchers, and content teams. Here are some of the top ones:
- Feeding data to LLMs and RAG systems. Structured, lightweight Markdown is perfect for indexing in vector databases and powering retrieval-augmented generation workflows.
- Migrating documentation or blogs. Quickly move content from a legacy CMS into Markdown-based static site generators like Hugo or Jekyll.
- Content analysis and summarization. Convert articles or reports into Markdown for easy parsing by NLP tools, sentiment analysis scripts, or summarizers.
- Creating static sites from scraped content. Combine Markdown output with a static site builder to produce lightweight, fast-loading websites.
- Archiving web content. Save pages in portable Markdown for long-term storage, offline reading, or version control in Git.
- Generating training datasets. Prepare clean, labeled content for AI machine learning models without heavy HTML cleanup.
Marking the end
In this article, you discovered how to scrape websites and convert their content into clean, easy-to-use Markdown. From understanding the basics to tackling dynamic pages and batch scraping, you now know how to set up a streamlined workflow to get the data you want. Say goodbye to messy HTML and hello to structured, portable content. Make sure to use Decodo's Web Scraping API to avoid issues, and make scraping easy and simple.
About the author

Zilvinas Tamulis
Technical Copywriter
A technical writer with over 4 years of experience, Žilvinas blends his studies in Multimedia & Computer Design with practical expertise in creating user manuals, guides, and technical documentation. His work includes developing web projects used by hundreds daily, drawing from hands-on experience with JavaScript, PHP, and Python.
Connect with Žilvinas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.