How to Scrape Nasdaq Data: A Complete Guide Using Python and Alternatives
Nasdaq offers a wealth of stock prices, news, and market reports. Manually collecting this data is a Sisyphean task, since new information appears constantly. Savvy investors, analysts, and traders turn to web scraping instead, automating data gathering to power more intelligent analysis and trading strategies. This guide walks you through building a Nasdaq scraper with Python, browser automation, APIs, and proxies to extract both real-time and historical market data.
Zilvinas Tamulis
Last updated: Nov 21, 2025
14 min read
Understanding Nasdaq's data structure
Nasdaq spreads its stock data across multiple pages and sections. Each stock page delivers real-time quotes, company overviews, financials, and related news, while the screener pages let you sift through thousands of stocks using filters like market cap, sector, and performance.
For every ticker, Nasdaq provides a rich set of data points, such as current price, trading volume, 52-week highs and lows, P/E ratio, dividend yield, and upcoming earnings dates. Historical data is also available, including price charts, trade volumes, and corporate actions like splits and dividends.
Unfortunately for web scrapers, most of Nasdaq's data doesn't show up right away – it's loaded dynamically through JavaScript. The initial HTML is more of a skeleton, while the real content – prices, charts, tables – arrives later through background API calls. That means traditional HTML parsing won't cut it. To get the whole picture, you'll either need to render dynamic content in a headless browser or tap into Nasdaq's internal API endpoints directly. The ideal method depends on what kind of data you're chasing.
Tools and technologies for scraping Nasdaq
Choosing the right tools can mean the difference between a scraper that runs smoothly and one that crashes on its first attempt.
Python is the most popular choice for web scraping thanks to its mature libraries, clean syntax, and strong data-handling capabilities. Its vast community also makes troubleshooting easy – most issues have already been solved somewhere online.
Other languages can get the job done too:
- JavaScript (Node.js). Great for scraping JavaScript-heavy websites and works seamlessly with browser automation tools.
- Ruby. Equipped with solid libraries like Nokogiri and Mechanize for lightweight extraction tasks.
- Go. Ideal for high-performance, large-scale scraping where speed and efficiency matter.
For scraping Nasdaq specifically, the essential Python libraries include:
- Requests for sending HTTP requests.
- Beautiful Soup for parsing HTML.
- Selenium or Playwright for browser automation.
- Pandas for organizing and exporting the data.
Playwright is the top choice for Nasdaq scraping. It's faster than Selenium, better at handling modern web technologies, and includes built-in waiting mechanisms for dynamic content. Its clean API and consistent performance across environments make it ideal for production use.
For enterprise-level operations, Decodo's Web Scraping API is also an essential tool of the scraping setup. It handles browser automation, JavaScript rendering, and data extraction through simple API requests – you send a URL and receive clean, structured data in return. Behind the scenes, the API uses rotating proxies to prevent IP blocks, CAPTCHAs, and rate limits. The API distributes requests across multiple IP addresses, making your scraper appear as many different users, ensuring uninterrupted data collection even when pulling thousands of records daily.
Skip the scraper setup, get straight to analysis
Decodo's Web Scraping API handles Nasdaq scraping for you so that you can focus entirely on the data.
Step-by-step guide: How to scrape Nasdaq data
Step 1: Choose your target data
Nasdaq has a wealth of data to choose from, so it's up to you to decide what's most relevant and what you're looking for. Here are some of the most popular categories to target:
- Individual stock pages. Great for live quotes, key stats, and performance insights that are perfect for tracking price movements or building real-time dashboards.
- Historical data pages. Ideal for time-series analysis and backtesting trading strategies, since they provide price data across different time ranges.
- News and press releases. Crucial for understanding market sentiment and tracking events that influence stock volatility and investor behavior.
If your target isn't on the list, don't worry, as the process for most of these pages is relatively similar. Now, let's explore how to extract information from them.
Step 2: Analyze the target page
Before scraping any page, it's important to take a peek behind the scenes to see how it works. Visit any of Nasdaq's pages, right-click, select Inspect Element or Inspect, or press the F12 button. This will bring up your browser's developer tools, where you can inspect the underlying HTML, track network activity, and performance.
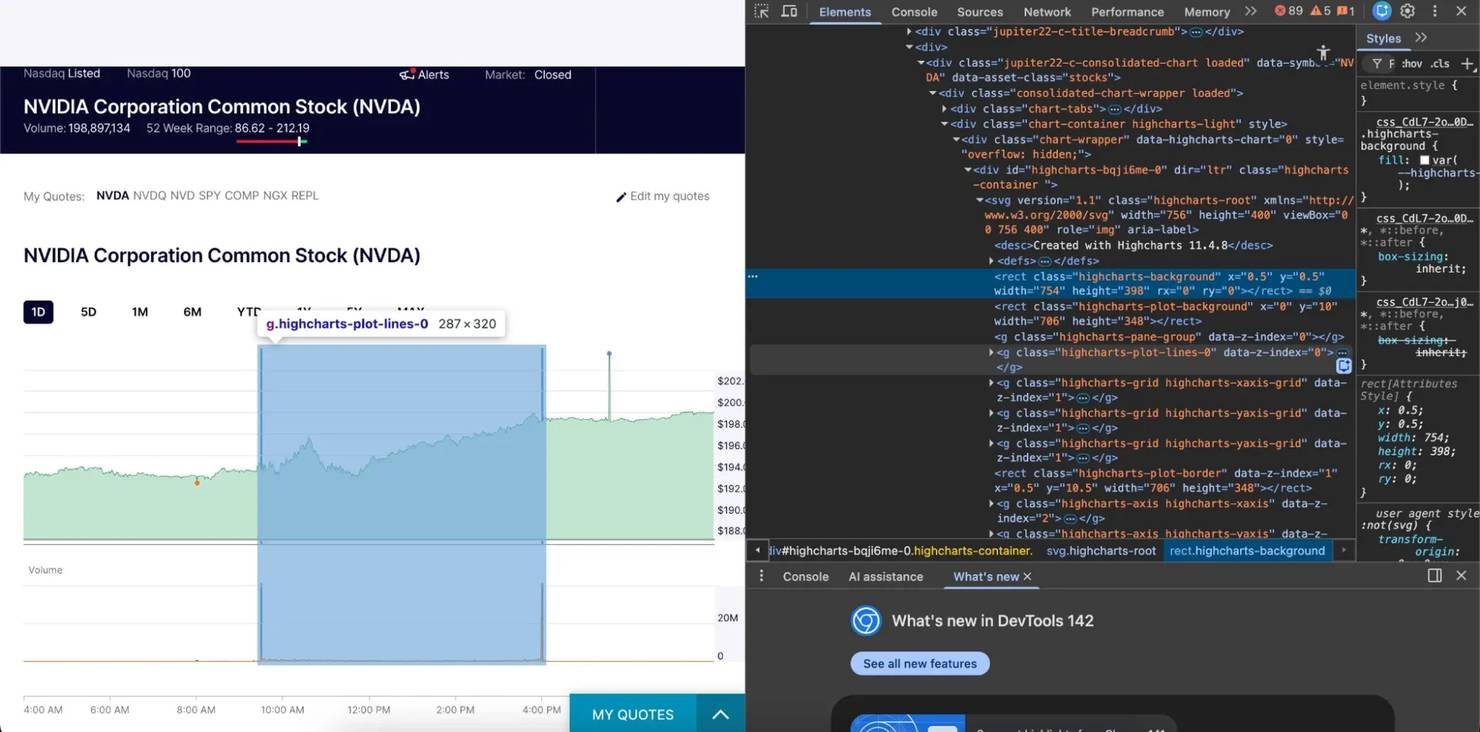
Step 3: Select your scraping method
From this point, there are two routes you can choose:
- Intercepting network requests. This approach skips the tedious work of locating HTML elements or updating selectors when the site changes. Instead, you capture the backend requests directly, giving you structured JSON data that's clean, reliable, and ready to use.
- Browser automation. A more hands-on approach where you control a real browser to navigate and extract data. It takes a bit more setup but offers greater flexibility for handling live content or accessing elements that the API doesn't provide.
For scraping Nasdaq, it's generally best to rely on intercepted network requests as your primary data source. This approach is clean, simple, and straightforward, while browser automation is better saved for cases where the API responses don't give you what you need. Regardless of choice, both methods can provide the same information accurately.
Step 4: Implement the scraper
In this section, you'll see how to collect the 3 different types of data in both API and browser automation methods. To run these scripts, make sure you have Python with Playwright installed on your computer.
Individual stock pages
To collect individual stock data using the API:
- Navigate to the URL with the corresponding ticker:
https://www.nasdaq.com/market-activity/stocks/{ticker}
2. Open your browser's developer tools.
3. Switch to the Network tab.
4. Filter requests by Fetch/XHR.
5. Find the "info?assetclass=stocks" request (there may be a few of them, depending on how long you had the page open).
6. See the Response section to find the underlying JSON data. It contains a variety of helpful information, such as last sale price, net change, bid and ask prices, the volume being traded, etc.
7. Create and run a Python script with the following code:
You'll see real-time data being printed in your terminal showing the changes in the ask price. The script will watch the requests for 1 minute, but you can increase the timeout if needed. If you want to test the code with a different stock or data, simply replace "nvda" in the URL and change the "askPrice" string with another type of data available from the JSON.
To perform the same job without using the API:
- Navigate to the target page.
- Open your browser's developer tools.
- Locate the ask price HTML element ("header-info-ask-info").
- Write and run the following code:
Since there's no way to watch for changes like with the API, the script uses the time library to check the page every second. This may lead to redundant data, such as the price staying the same and repeating multiple times without any actual update. The script also runs indefinitely, so make sure to stop it in your terminal by clicking CTRL + C or add logic that would end the script once enough data has been collected.
To test this script with another stock, you can replace the ticker in the URL as before. However, if you want to target another data point within the page, you'll have to find where it lies within the HTML manually.
Historical data pages
There are several ways to get historical data, ranging from a simple download button to intricate scraping through pagination.
If you want a stock's historical quotes or the NASDAQ Composite Index (COMP) Historical Data, you don't need to do any scraping at all. Simply navigate to the page, set the desired timeline, and click Download historical data above the table. Scraping, on the other hand, can help if you want to get data for several stocks quickly:
The script above allows you to enter a list of tickers to scrape and the timeline to set for them. It then navigates to every stock page, clicks the download button, and saves the data into one neat folder, properly labeling each CSV file with the ticker symbol.
But what if the page doesn't offer a handy download button? If, for any reason, Nasdaq decides to remove the download button, or you're scraping the historical NOCP of a stock, you'll need to get the data manually.
You can use the same method as before and intercept network requests to get all data immediately. This time target the "historical-nocp?timeframe=y[x]" request:
The script gets all of the data from the sent JSON and exports it to a CSV file. Make sure to set the timeline parameter in the URL to match the amount of data you need. You don't have to handle any pagination or look through HTML elements, as all the data is sent immediately for you to capture and save.
Manual scraping is also possible if none of the above methods fit your needs:
The script navigates to the target page, extracts data from the table, and then clicks the "Next" button to move through subsequent pages, repeating this process until the "Next" button is disabled, indicating there are no more pages.
News and press releases
Stock pages also feature articles that mention them at the bottom of the page. Scraping these can provide the latest news and valuable insights from experts in the industry.
So far, the API has proven to be the most effective option when scraping Nasdaq. However, scraping news articles can only be done manually, as there are no requests that send clean JSON data.
Here's how you can do it:
The script finds the "Latest News" heading, waits for the content to load, and scrapes the article titles, post dates, and direct URLs, then stores them in a CSV file for further reading or AI analysis.
Step 5: Using proxies to avoid blocks
Proxies help you slip past the usual roadblocks that large sites throw at high-frequency scrapers. Nasdaq isn't the strictest gatekeeper on the web, yet it still applies traffic filtering that can slow or completely halt repeated scraping. A proxy layer helps you keep your code running smoothly without setting off alarms.
Implementing Decodo proxies into your Playwright script is simple:
- Create an account on the Decodo dashboard.
- On the left panel, select Residential proxies.
- Choose a subscription, Pay As You Go plan, or claim a 3-day free trial.
- In the Proxy setup tab, configure your location and session preferences.
- Copy your proxy credentials for integration into your scraping script.
- Add a PROXY_URL = "https://user:pass@gate.decodo.com:10001" variable after library imports.
- Add a proxy parameter to the browser launch parameters.
Example:
You can apply this small change to any script in the article. It instantly boosts your scraper's reliability, reduces the chance of getting flagged, and keeps the origin of your traffic hidden.
Automated scraping with n8n
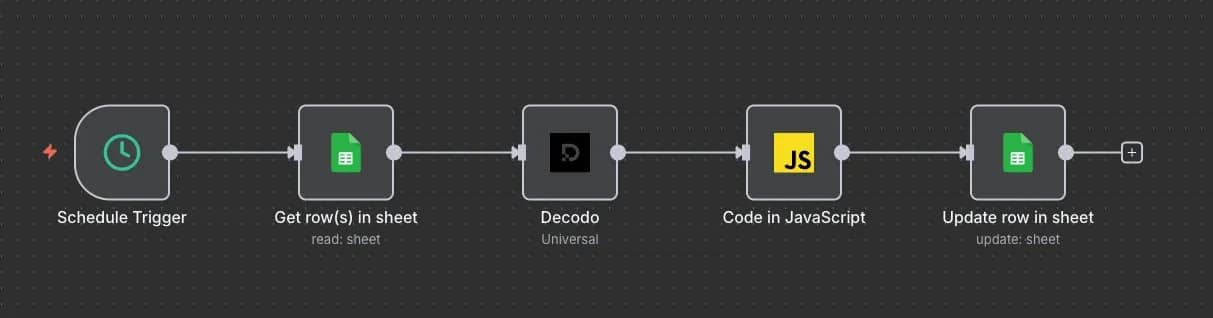
If coding isn't your strong suit, n8n is a handy tool to automate workflows that would typically require complex code. Its intuitive workflow builder lets you link nodes, with each node performing a specific task to collect and process data. Here's an example workflow that gets a stock's information:
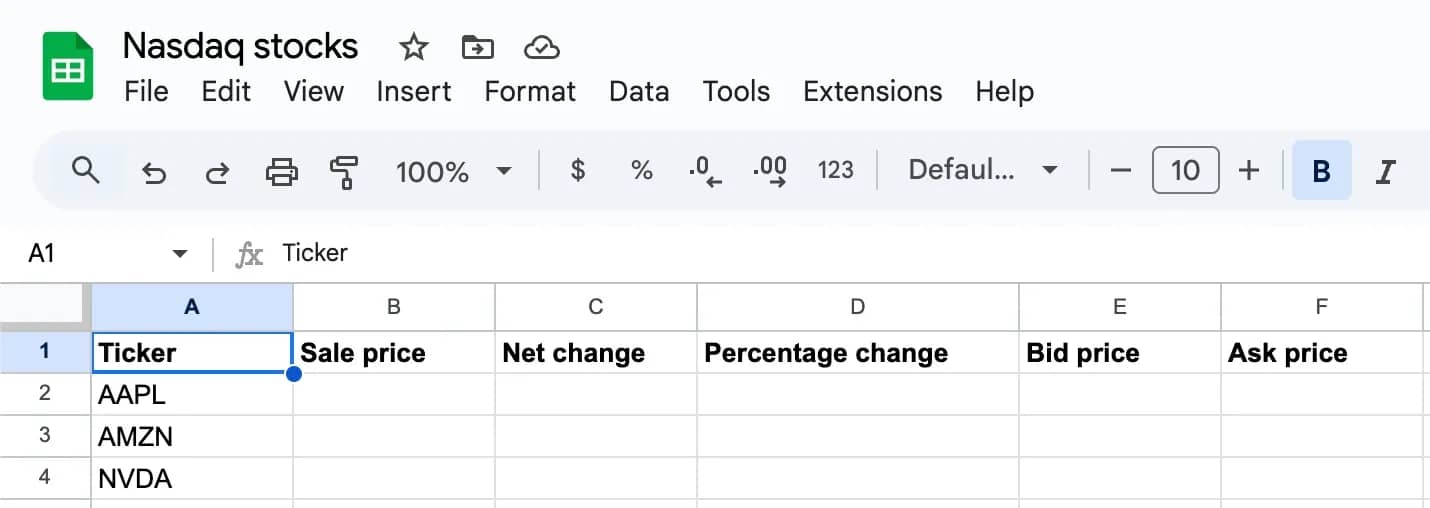
- Prepare a Google Sheets document. List a few tickers and the information you want to extract.
2. Create a new n8n workflow. Use either the cloud or a locally hosted version of n8n. On the homepage, click Create Workflow.
3. Add a Schedule Trigger node. Set the Trigger Rules to set how often the scraper should run.
4. Add a Google Sheets node. Select the Get row(s) in sheet action and connect it to the prepared spreadsheet.
5. Add a Decodo node. Select the Scrape using Universal target action. Set the URL to https://api.nasdaq.com/api/quote/{{ $json.Ticker }}/info?assetclass=stocks. It will loop through the tickers by appending them to the URL and get the data.
6. Add a Code node. Select the Code in JavaScript action. You'll need this to parse the JSON data into a more readable format. Modify the json fields to match the ones in the Google Sheet.
7. Add another Google Sheets node. This time, choose the Update row in sheet action. Set the Mapping Column Mode to Map Automatically and the Column to match on to Ticker.
8. Activate the workflow. Save the workflow and toggle it to become Active. It will now trigger at a set time (every minute in this example) and update the Google Sheet with the most recent stock data. You can check if it works at your n8n instance's /home/executions.
You can download the JSON file to get started right away.
Best practices for scraping Nasdaq data
Make the most out of scraping Nasdaq with these valuable tips:
- Use rate limiting and polite scraping to avoid detection. Don't hammer the site with nonstop requests; space them out using delays or concurrency limits. This keeps your scraper under the radar and prevents temporary IP bans.
- Respect robots.txt and the website's terms of service. Nasdaq's robots.txt specifies which areas are crawlable and which are off-limits. Always check it before scraping to avoid hitting restricted paths like API endpoints or real-time quote pages.
- Store accurate timestamps for all data points. Nasdaq data updates constantly, where every tick matters. Tag each data point with a precise UTC timestamp so you can analyze historical trends and synchronize with other market feeds.
- Regularly validate scraped data against trusted sources. Cross-check your scraped results with Nasdaq's Data Link, or another verified data provider. This ensures your scraper isn't missing fields or collecting stale values after a layout change.
- Monitor for changes in page structure or API endpoints. Nasdaq often refreshes its frontend, renames classes, or relocates data attributes. Build automatic tests or schema checks so you're alerted the moment your selectors break.
- Use rotating proxies and random user agents for reliability. Nasdaq enforces strict rate limits and can block repeated IPs or header patterns. Rotate proxies, shuffle user agents, and use session persistence when needed to maintain a consistent flow of requests.
Troubleshooting common issues
Even well-built Nasdaq scrapers can stumble from time to time. Here are a few of the usual suspects that might disrupt your work:
- Missing or incomplete data. Nasdaq pages often load dynamically, so ensure you wait for JavaScript-rendered elements before scraping. If data fields suddenly disappear, inspect the DOM for updated class names or lazy-loaded sections. A non-coding related detail to also remember is that US markets stay closed during standard exchange holidays and overnight hours, so data updates pause until regular trading resumes in the next session.
- CAPTCHA challenges or IP blocks. Frequent requests or repetitive patterns can trigger Nasdaq's bot protection. Rotate proxies, add randomized delays, and simulate realistic mouse or scroll behavior to reduce the odds of hitting a CAPTCHA. If that sounds like too much work, use a reliable scraping API that can bypass CAPTCHAs and change your IP the moment it's blocked.
- Changes in page structure. Nasdaq periodically updates its HTML layout and data containers. Keep your selectors modular by storing them in one config file, so you can quickly adjust them when the structure shifts. Make sure they're flexible and not overly reliant on frequently changing elements like IDs, class names, or very specific XPaths.
Nasdaq data on a bigger scale
Once you move beyond small-scale experiments, it's worth considering enterprise-grade data solutions. Providers like Nasdaq Data Link or other APIs offer reliable, structured feeds with guaranteed uptime – ideal when you need consistency and speed over DIY scraping. They also handle updates and compliance, freeing you from the maintenance treadmill.
Running your scraper in the cloud also makes scaling and automation much easier. Platforms like AWS Lambda, Google Cloud Run, or Azure Functions let you schedule scraping, handle retries, and store results without managing servers. Combined with containerization tools like Docker, your Nasdaq scraper can scale horizontally and run 24/7 without manual intervention.
Once you've gathered enough clean data, the next step is making it useful. Integrate it into business dashboards or internal research tools to visualize trends for real-time decision-making. With a thought-out setup, your scraped Nasdaq data becomes more than numbers – it becomes a living assistant with tips for growth and strategy.
Alternative tools and data sources
If you want broader market insights beyond Nasdaq, platforms like Yahoo Finance, TradingView, or MarketWatch can provide trend data, sector movements, and stock performance analytics. These services track price action, trading volume, and market sentiment, giving you additional angles to spot opportunities or shifts in the market.
For programmatic access, several APIs deliver stock and market trend data. Alpha Vantage, IEX Cloud, and Finnhub provide historical prices, intraday updates, and technical indicators that can be integrated into dashboards, models, or automated strategies alongside your Nasdaq data.
Final thoughts
Scraping Nasdaq opens the door to valuable market insights, but you need solid tools, innovative techniques, and dependable proxies to do it well. Whether you're writing your own scraper or pulling data from an API, aim for accuracy, scalability, and low visibility. With a clean, structured workflow, your Nasdaq data turns into practical intelligence that can fuel better analysis, dashboards, and trading decisions.
Stop getting blocked, start getting data
Scrape Nasdaq with Decodo's residential proxies that keep you under the radar and your data flows uninterrupted.
About the author

Zilvinas Tamulis
Technical Copywriter
A technical writer with over 4 years of experience, Žilvinas blends his studies in Multimedia & Computer Design with practical expertise in creating user manuals, guides, and technical documentation. His work includes developing web projects used by hundreds daily, drawing from hands-on experience with JavaScript, PHP, and Python.
Connect with Žilvinas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.