Methods, Tools, and Best Practices for Scraping Yahoo Finance
Yahoo Finance is one of the most comprehensive free financial data platforms available, offering real-time stock prices, historical data, and company fundamentals. However, scraping such a platform presents challenges like sophisticated anti-bot measures, JavaScript-heavy rendering, and dynamic content loading. This guide offers practical, tested methods for efficiently extracting Yahoo Finance data while navigating these obstacles.
Justinas Tamasevicius
Last updated: Oct 09, 2025
9 min read
Why scrape data from Yahoo Finance?
Yahoo Finance is a go-to source for free financial data. Scraping it makes collection faster, more accurate, and scalable for different uses:
Investment research & portfolio tracking
Instead of checking prices manually, automated data collection lets you track your portfolio in real time. You can set up dashboards that pull from multiple holdings, monitor performance, and trigger alerts when movements happen, all without depending on limited broker interfaces.
Automated trading strategies
Access to structured financial data is the foundation for algorithmic trading. Scraping Yahoo Finance provides the historical and live inputs you need to backtest models, refine strategies, and even automate trade execution with confidence.
Financial modeling & analysis
Why pay enterprise rates for basic market data when you can build something better? When you integrate Yahoo Finance data into trading algorithms or financial tools, you can build things that range from simple price trackers to sophisticated analytical systems requiring fresh, accurate market data.
Market analysis & news monitoring
Scraping Yahoo Finance data helps you skip the spreadsheet gymnastics. This means being able to pull stock performance metrics, track market trends, and build comparative datasets across multiple securities without losing your sanity.
You can manually get the data you want from Yahoo Finance, but the advantages of programmatically scraping the data are greater. Programmatic scraping is faster, more frequent, and less prone to errors. A simple Python script can automate hours of work and keep your datasets up-to-date with the latest figures.
Understanding Yahoo Finance’s website structure
Before you start trying to get data from Yahoo Finance, you have to first understand what you’re dealing with.
Yahoo Finance runs on a React-based architecture that loads most data dynamically through AJAX calls. Translation: if you just grab the HTML and expect complete data, you'll get loading spinners and empty divs instead of actual prices. The data you want loads after the initial page render, which means basic HTTP requests will leave you hanging.
Despite the JavaScript complexity, Yahoo Finance shares its financial information across different pages and sections:
- Real-time stock quotes. Current price, daily highs and lows, volume, market cap, P/E ratio, dividend yield, etc., on the stock’s summary page.
- Historical prices. Daily, weekly, or monthly price data going back years (available under the "Historical Data" tab for each ticker, with CSV download options).
- Financial statements. Income statements, balance sheets, and cash flow statements (annual and quarterly data under the "Financials" section).
- Options chains. Lists of call and put options with strike prices and expiration dates (under the "Options" tab for a given stock).
- Index & fund data. Information on market indices (e.g., S&P 500) or ETFs/mutual funds, such as their price, performance, and holdings, similar in structure to stock pages.
Each of these data types may be presented differently on the site, but extracting them can be a challenge. Yahoo implements multiple protection layers to prevent data extraction, including rate limiting, IP-based blocking, CAPTCHA challenges, and JavaScript detection. Understanding this structure and challenges will help you choose the right tools and approach.
But first, let’s jump into a quick demo to get a feel for scraping a simple piece of data from Yahoo Finance.
Quickstart demo (for beginners)
Let's start with a minimal Python example. We’ll fetch the current stock price for a given ticker symbol (e.g., Apple’s ticker AAPL) from Yahoo Finance and print it with a timestamp. This quick demo uses Python’s requests library and BeautifulSoup for HTML parsing.
When you run this script, it will output something like:
P.S. The actual price will vary depending on the current market data.
In this example, we constructed the Yahoo Finance URL for the ticker and sent a GET request with a User-Agent header to appear as a normal web browser (this helps avoid being blocked by Yahoo’s servers).
We then located the HTML element that holds the stock’s price. On Yahoo Finance, prices are contained in a custom <fin-streamer> tag with a data-field attribute (for example, data-field="regularMarketPrice" is the current price). Extracting the text of that tag gives us the stock price.
This quick demo shows the basic idea of scraping – fetch HTML, parse it, extract the data. Next, we’ll dive deeper into more advanced methods and how to gather various data types.
Choosing the right tools and libraries
Building an effective Yahoo Finance scraper requires the right combination of Python libraries and supporting tools:
Core Python libraries
The Requests library handles HTTP communication, while Beautiful Soup parses HTML content and extracts specific data elements. For faster and more accurate HTML parsing, it's recommended to use the lxml parser with Beautiful Soup. Together, these tools form the foundation of most web scraping projects, though Yahoo Finance's JavaScript-heavy architecture can limit their effectiveness.
Data processing tools
Pandas provides powerful data manipulation capabilities for organizing and analyzing scraped results. The csv module enables easy export to spreadsheet formats, while the json module can handle structured data storage.
Advanced browser automation
For complex scenarios requiring JavaScript execution, Selenium or Playwright can simulate full browser environments. Unlike Google Finance, Yahoo Finance's React-based architecture makes these tools essential for accessing dynamically loaded financial data.
Proxy and session management
Reliable proxy services are essential for sustained scraping operations. Yahoo Finance implements sophisticated rate limiting and bot detection, making IP rotation and proper session management crucial for consistent data collection.
For a small project or quick one-off data grab, you can start with Requests + BeautifulSoup. It’s simple and often sufficient for basic data, such as prices or static tables. If you notice that you’re not getting the data you expect (perhaps the HTML from requests is missing some fields), that’s a sign the content is dynamic – consider Selenium/Playwright in those cases.
If you need to scrape hundreds of pages quickly or repeatedly, then Decodo is the perfect choice for scalability and reliability.
Step-by-step tutorial: scraping Yahoo Finance with Python
Let’s walk through a comprehensive tutorial on scraping Yahoo Finance data using Python. We’ll cover both simple static scraping and more advanced techniques for dynamic content, as well as strategies to scale up.
Prerequisites
Ensure you have Python installed on your computer (version 3.8 or later). You can download it from the official site if needed.
Next, we need to install the Python libraries we'll use. You can do so by running this command in your terminal:
Here’s a quick breakdown of these libraries:
- requests – for HTTP requests.
- beautifulsoup4 – for parsing HTML.
- lxml – (optional) high-performance parser that Beautiful Soup can use.
- playwright – for controlling a browser (if needed for dynamic content).
- pandas – for data handling (to tabulate or export data).
- aiohttp – for asynchronous requests (optional, for advanced users).
Now that the environment is ready, let's start with scraping some static content.
Scraping static data (using yfinance)
First, we'll scrape the summary data (the key stats you see on a Yahoo Finance quote page: price, market cap, P/E ratio, etc.) for Apple (AAPL). This includes fields like Previous Close, Open, Day’s Range, 52-week Range, Volume, Market Cap, P/E (TTM), and EPS (TTM).
We’ll be using yfinance for this operation, as it’s the most straightforward option. It wraps Yahoo Finance’s internal endpoints and exposes a clean Python API, so you can query fundamentals and intraday stats directly.
When you run this, the data might look something like:
Rather than parsing HTML, yfinance calls Yahoo Finance’s internal JSON endpoints and returns a Python dictionary (ticker.info or ticker.fast_info) with fields like previousClose, open, dayLow, dayHigh, marketCap, etc. You identify data by JSON keys, not by DOM attributes like data-test.
This makes the code less brittle, that is, if Yahoo tweaks page markup, your lookups still work as long as the API keys remain consistent. This basic approach handles simple extraction but breaks down fast when Yahoo Finance decides to load data dynamically. That's where things get interesting.
Scraping different data categories
Yahoo Finance contains a lot more than just the summary stats. Depending on your goals, you might need to scrape other sections. Here’s how you can approach various data categories:
- Real-time stock data (quotes). The main quote page (/quote/TICKER) provides real-time price and trading data. We already showed how to get the price and summary stats. You can similarly extract other real-time fields like the latest bid/ask, day’s high/low, etc., using their data-test or data-field identifiers.
- Historical prices. Yahoo Finance allows downloading historical price data as a CSV, but you can also use the yfinance Python library, which unofficially uses Yahoo’s endpoints to fetch historical data easily.
- Financial statements (income, balance sheet, cash flow). Yahoo Finance provides financial statements under the "Financials" section for each company. These are usually presented in tables by year or quarter.
- News articles. Yahoo Finance also aggregates news for each stock. On the stock’s page, there’s a list of recent news headlines, and these can be scraped by finding the news section in the HTML – for instance, look for <h3> tags or anchor links that contain news titles. Each item usually has a title, source, and timestamp, and you could extract all headlines and links on that page.
- Mutual funds, ETFs, and other data. Yahoo Finance covers funds and currencies similarly to stocks. The approach to scrape those is analogous – use their ticker (e.g., an ETF like SPY or a currency pair like EURUSD=X) in the URL and parse the page. The available fields might differ (for a fund, you might see NAV instead of price, etc.). But the scraping techniques remain the same.
Pro tip: Always inspect the page with developer tools first to find unique identifiers for the data you want. Yahoo often includes handy attributes, such as data-test, and uses semantic tags like <fin-streamer> for numeric data. Searching the page’s HTML for a known value can lead you to the right element to target.
Scraping dynamic data (using Playwright)
In some cases, a simple GET request won’t retrieve the data you need because it’s populated by JavaScript after the page loads. Examples include real-time price updates (which might not appear in the initial HTML if you fetch too early) or interactive elements (like the chart or certain tabs).
To handle such scenarios, you can use Playwright to render the page, run the JavaScript, handle consent prompts, and extract live values from Yahoo Finance.
The first step sets up all necessary imports and creates a driver configuration function. Yahoo Finance relies heavily on JavaScript to dynamically load financial data, so we need to set up Playwright to handle JavaScript rendering and extract data that only appears after page scripts execute.
This Playwright-based approach enables you to systematically adapt each component to your specific scraping needs, while maintaining robust error handling and fallback strategies.
Together, the script launches a Chrome browser (headless or headed), loads the Yahoo Finance page for a given ticker (e.g., AAPL), handles the cookie consent prompt if it appears, and waits for the page’s JavaScript to render. It then extracts live financial data starting with the current price and extending to fields like Previous Close, Open, Volume, Market Cap, and PE Ratio, returning the results as structured JSON. It implements robust data extraction using multiple fallback selectors to handle Yahoo Finance's changing DOM structure.
When scraping at scale, proxies help distribute requests across multiple IP addresses, reduce the chance of being blocked, and allow you to access geo-specific market data that may vary by region. This makes your scrapers more resilient, especially when dealing with dynamic content or rate limits. For a managed residential proxy solution built for scraping and geotargeting, explore Decodo’s residential proxies.
Keep in mind that Playwright is inherently slower than traditional HTTP request libraries like Requests or httpx. Each page load takes a few seconds, and running a real browser consumes more resources. Use it only when necessary (i.e., when data cannot be retrieved with a simple request or when simulating user interaction is required).
For many Yahoo Finance scraping tasks, you can often find an underlying request or use the initial HTML without needing Playwright. However, it's a lifesaver for cases where content simply won't appear otherwise.
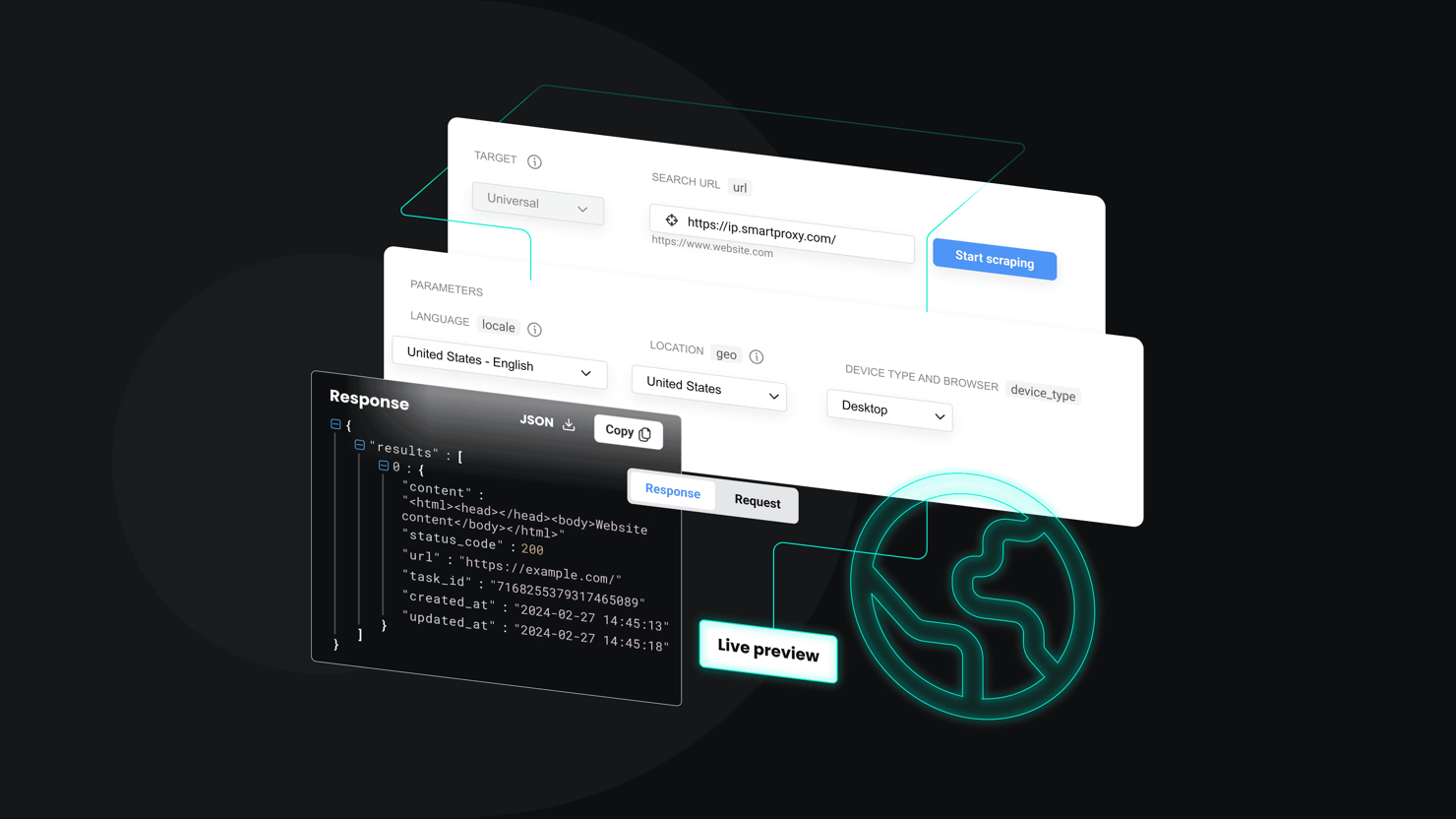
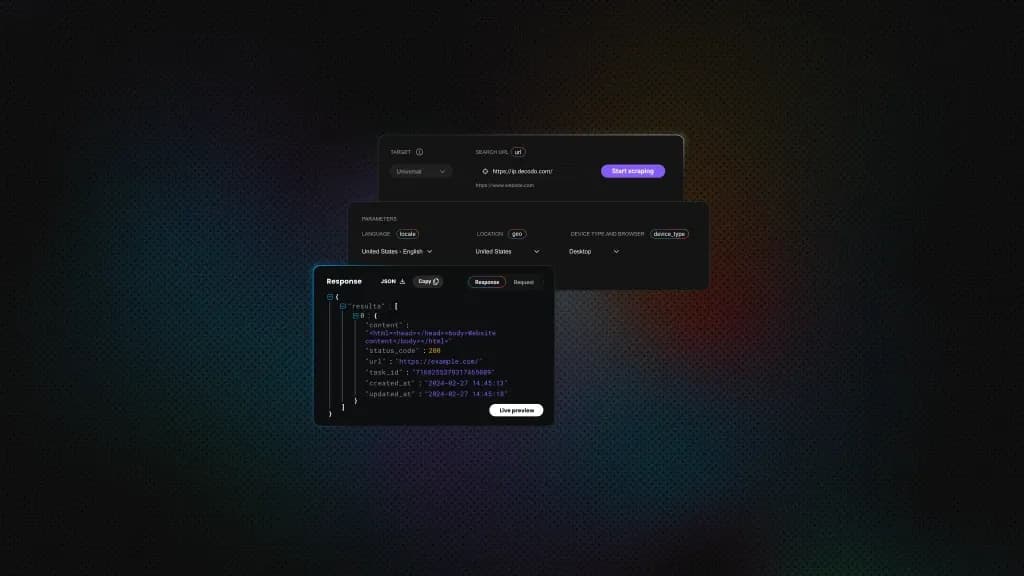
Using Web Scraping APIs
Using Playwright and other parsers is great until you’re babysitting Chrome at 3 a.m., managing drivers, fingerprints, retries, proxies, and CAPTCHAs. A more efficient and straightforward way to obtain this data is by using a Web Scraping API, like Decodo Web Scraping API, which handles IP rotation, JavaScript rendering, and CAPTCHA solving while you grab a coffee.
Essentially, you make an API call to their endpoint with the target URL, and the service returns the data in an HTML format.
The benefit here is significant. You skip the infrastructure headaches while focusing on parsing the HTML you actually need, without ever worrying about getting blocked.
Decodo's Web Scraping API mimics real user traffic, rotates through 125M+ proxy IPs, handles headless browser rendering, and automatically retries failed requests. For large-scale Yahoo Finance operations, this approach turns proxy management nightmares into a distant memory.
Get Web Scraping API
Run Yahoo Finance jobs with Decodo Web Scraping API. Complete with JavaScript rendering, geo-targeting, 115M+ residential IPs, and more.
Scalability & optimization
When you're scraping a handful of pages, sequential requests are fine. But the moment you need dozens or hundreds of tickers, you'll either scale smart or scale into a wall.
Asynchronous scraping with aiohttp enables you to send multiple requests in parallel while reusing sessions, thereby reducing latency and connection overhead. Combine this with proper timeouts and exponential backoff, and you have async scraping that dramatically boosts throughput without overwhelming Yahoo Finance's servers.
You also need to be deliberate about pacing. Rate-limiting ensures you don’t overwhelm the target site or trigger bot detection. Adding random jitter between batches of requests helps mimic natural user activity.
Retry logic is equally important: transient errors like 429 (too many requests) or 5xx server errors should trigger exponential backoff retries, while hard errors like 404 should be skipped. Together, these practices make your scraper more robust and resilient.
Finally, caching can save you from re-downloading the same content repeatedly. Company fundamentals or profile pages change slowly and can be cached for hours or days, while real-time quotes may need to be refreshed every minute. Using local SQLite caches, Redis, or libraries like aiohttp-client-cache lets you avoid redundant requests, lower your infrastructure costs, and reduce the load on Yahoo Finance.
Exporting and using the data
Once you’ve pulled useful information from Yahoo Finance, the next step is making it reusable. Two of the most common formats are CSV and JSON. CSV is ideal for tabular data because it’s easy to open in Excel or import into analytics tools, while JSON works better when you want to preserve structure or nested objects.
With Python, exporting is straightforward. If your scraper collects results into a list of dictionaries, you can turn that into a DataFrame and save it directly to CSV:
For JSON, you can use Python’s built-in json library:
Beyond just saving, Pandas makes the data analysis-ready. You can load the scraped data into a DataFrame and immediately start slicing, aggregating, or joining across tickers. For example, you might calculate rolling averages of stock prices, compare P/E ratios across multiple companies, or align historical returns. The combination of scraping plus Pandas turns raw HTML responses into actionable financial insight.
Anti-bot mitigation strategies
Websites like Yahoo Finance employ anti-scraping measures to protect their data and infrastructure. To avoid getting blocked or flagged as a bot, consider these strategies:
- Rotate IP addresses. Many scrapers fail because excessive requests from single IP addresses trigger rate limiting. Decodo's residential proxies provide access to 115M+ IP addresses with 99.92% success rates, enabling sustained scraping operations without detection.
- Vary your User-Agent and headers. Always include realistic User-Agent headers that mimic popular web browsers. Rotating through different browser signatures prevents fingerprinting and maintains anonymity.
- Use headless browsers wisely. When using Selenium or Playwright, configure headless mode with stealth settings. Modern detection systems can identify automation, so proper configuration becomes essential for consistent operation.
- Handle CAPTCHAs. Yahoo Finance may present CAPTCHA challenges during high-volume operations. Rather than integrating third-party CAPTCHA solving services, Decodo's Web Scraping API automatically handles CAPTCHA resolution, eliminating this bottleneck entirely.
- Respect robots.txt. Implement conservative crawl rates with randomized intervals. Effective scraping follows a marathon approach rather than sprint tactics – better to scrape 100 pages over 10 minutes than attempt 100 pages in 10 seconds and face immediate blocking.
Scraping multiple stocks or automating the process
Thus far, we’ve focused on scraping data for one stock at a time. But what if you want to collect data for dozens or hundreds of ticker symbols, or set up an automated pipeline that updates daily?
The simplest solution to that is looping over tickers. You can keep your scraper modular by writing a fetch_quote(ticker) function (yfinance or your parser) and iterating over a list. Batch with short sleeps or bounded concurrency to stay under bot-detection thresholds. Here’s a minimal example that does just that:
To keep data fresh, you might schedule your script to run at intervals. If you only need daily data, a simple cron job (on Linux/Mac) or Task Scheduler (on Windows) can run your Python script every day at a certain time. If you require a higher frequency (e.g., every hour or every 5 minutes for near-real-time prices), ensure your scraping remains polite and consider how to distribute the load (you may not want to scrape hundreds of stocks every 5 minutes from a single IP).
For large-scale or production use, treat your scraping code as part of a data pipeline. For example, scraped data could be inserted directly into a database (PostgreSQL, MongoDB, etc.) instead of just written to a file. You might then have analytics or a web dashboard read from that database.
Using frameworks like Scrapy (a popular Python scraping framework) can be beneficial if you want more structured pipeline management, as Scrapy has pipelines that can feed data into databases or storage after scraping. However, Scrapy might struggle with the JS content on Yahoo unless used in conjunction with a headless browser middleware.
Data validation & cleaning
Raw scraped data from Yahoo Finance arrives messy, inconsistent, and full of potential pitfalls. Transforming this chaos into reliable datasets requires systematic validation and cleaning processes.
Yahoo Finance pages don't always load completely, and selectors break when the site updates. Missing values occur frequently due to network timeouts, changed page structures, or selective data availability. Build validation checks that catch these issues early rather than discovering them during analysis when it's too late.
After the data is validated, the output still needs serious cleanup before analysis becomes possible. Dollar signs, random commas, and cryptic abbreviations like "2.5T" require translation into actual numbers. Pandas transforms this formatting nightmare into clean DataFrames with standardized data types and proper datetime objects for time-series work.
Remember, multi-ticker datasets arrive about as aligned as cats trying to march in formation. Create pivot tables with timestamps as rows and tickers as columns, then forward-fill missing values to enable portfolio-level analysis across your entire dataset.
Troubleshooting & best practices
Even with a solid plan, web scraping can involve some trial and error. Here are common challenges you might face when scraping Yahoo Finance and how to address them:
- Blocked requests / 403 errors. When Yahoo Finance starts returning HTTP 403 Forbidden errors or serving CAPTCHA pages, you've triggered their bot detection systems. This signals the need to back off immediately and implement proper anti-bot strategies. Switch to residential proxies, reduce your crawl rate significantly, and ensure your headers mimic legitimate browser requests.
- Missing data in HTML. Parser failures often indicate that Yahoo delivered incomplete HTML due to missing cookies, JavaScript requirements, or rate limiting. This typically requires either cookie simulation or switching to Playwright for JavaScript execution. Don't assume your selectors are wrong when the real problem is incomplete page delivery.
- Site structure changes. Yahoo Finance updates their layout periodically, breaking scrapers that rely on fragile selectors. While their structure remains relatively stable, class names and element attributes change without warning. Try to build resilient scrapers using multiple fallback selectors rather than depending on single CSS classes.
- CAPTCHAs. CAPTCHA pages containing "detecting unusual traffic" messages indicate sophisticated bot detection. Manual CAPTCHA solving works for isolated incidents but doesn't scale for production operations. Integrating third-party CAPTCHA solving services adds complexity and costs, while Decodo's Web Scraping API handles these challenges automatically without requiring additional integrations.
- Common errors. AttributeError exceptions during parsing indicate broken assumptions about HTML structure – elements you expected weren't found or had different properties. Implement comprehensive try-except blocks around all parsing operations. Network-related errors like timeouts or connection failures require retry logic with exponential backoff.
Anticipating these challenges during development rather than encountering them in production creates more robust scrapers. Build error handling, logging, and monitoring into your scrapers from the beginning rather than adding these capabilities after failures occur.
Alternatives to scraping
Sometimes building scrapers is unnecessary when better solutions already exist. Consider these options before diving into custom scraping infrastructure.
Official APIs and datasets
- Alpha Vantage. Comprehensive market data with generous free tiers
- IEX Cloud. Real-time and historical market data with transparent pricing
- Polygon.io. High-frequency trading data and market APIs
- Nasdaq Data Link. Historical and real-time financial datasets
Data providers offering Yahoo Finance data
- Quandl. Financial and economic datasets (now part of Nasdaq Data Link)
- Financial Modeling Prep. Real-time stock prices and financial statements
- Twelve Data. Stock market data API with Yahoo Finance-like coverage
Pros and cons of custom scraping vs. financial APIs
When building financial tools or data-driven models, custom scraping can offer a high degree of control and visibility. It allows developers to pull exactly what they need from public web pages without waiting for API access or being limited by predefined endpoints.
- Direct access to displayed data. Scraping captures exactly what appears on Yahoo Finance, including fields not exposed by APIs.
- Full flexibility. Any section of the page can be targeted, from common stats to niche metrics.
- No API limits. You control the frequency of requests without hitting strict quotas.
- Lower cost for small projects. For a few tickers, scraping can be cheaper than premium API subscriptions.
- Fast prototyping. You can experiment immediately without API keys or onboarding delays.
Despite its flexibility, scraping comes with long-term drawbacks related to reliability, legality, and scalability. These issues often make APIs a more sustainable solution for production-level systems or larger-scale applications.
- Fragile maintenance. Changes in Yahoo’s HTML or data payloads can break scrapers and require constant fixes.
- Scalability challenges. Scraping works for small tasks, but handling large volumes of tickers or high-frequency updates can become resource-intensive.
Bottom line
Yahoo Finance scraping requires balancing technical complexity with practical results. Start with Beautiful Soup for static content, escalate to Playwright for JavaScript rendering, and integrate residential proxies early to avoid blocking. Build modular scrapers with proper error handling, data validation, and rate limiting that respect Yahoo Finance's infrastructure while providing reliable financial data extraction.
For production applications, your best option might be to combine Decodo’s Web Scraping API with solid data parsing logic and automation. This provides the reliability and scale needed for professional financial data collection while maintaining Yahoo Finance's comprehensive coverage.
Get residential proxies
Bypass CAPTCHAs and blocks using real-device IPs, essential for any Yahoo Finance scraping setup.
About the author

Justinas Tamasevicius
Director of Engineering
Justinas Tamaševičius is Director of Engineering with over two decades of expertise in software development. What started as a self-taught passion during his school years has evolved into a distinguished career spanning backend engineering, system architecture, and infrastructure development.
Connect with Justinas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.