Yahoo Scraper API
Scrape Yahoo search results effortlessly with our powerful Yahoo scraping API* to track keyword rankings, gather competitor insights, and extract data from various SERP features in just a few clicks.
* This scraper is now a part of the Web Scraping API.
14-day money-back option
Zero
CAPTCHAs
99.99%
success rate
195+
locations
Task
scheduling
Free
starter plan
Be ahead of the Yahoo scraping game
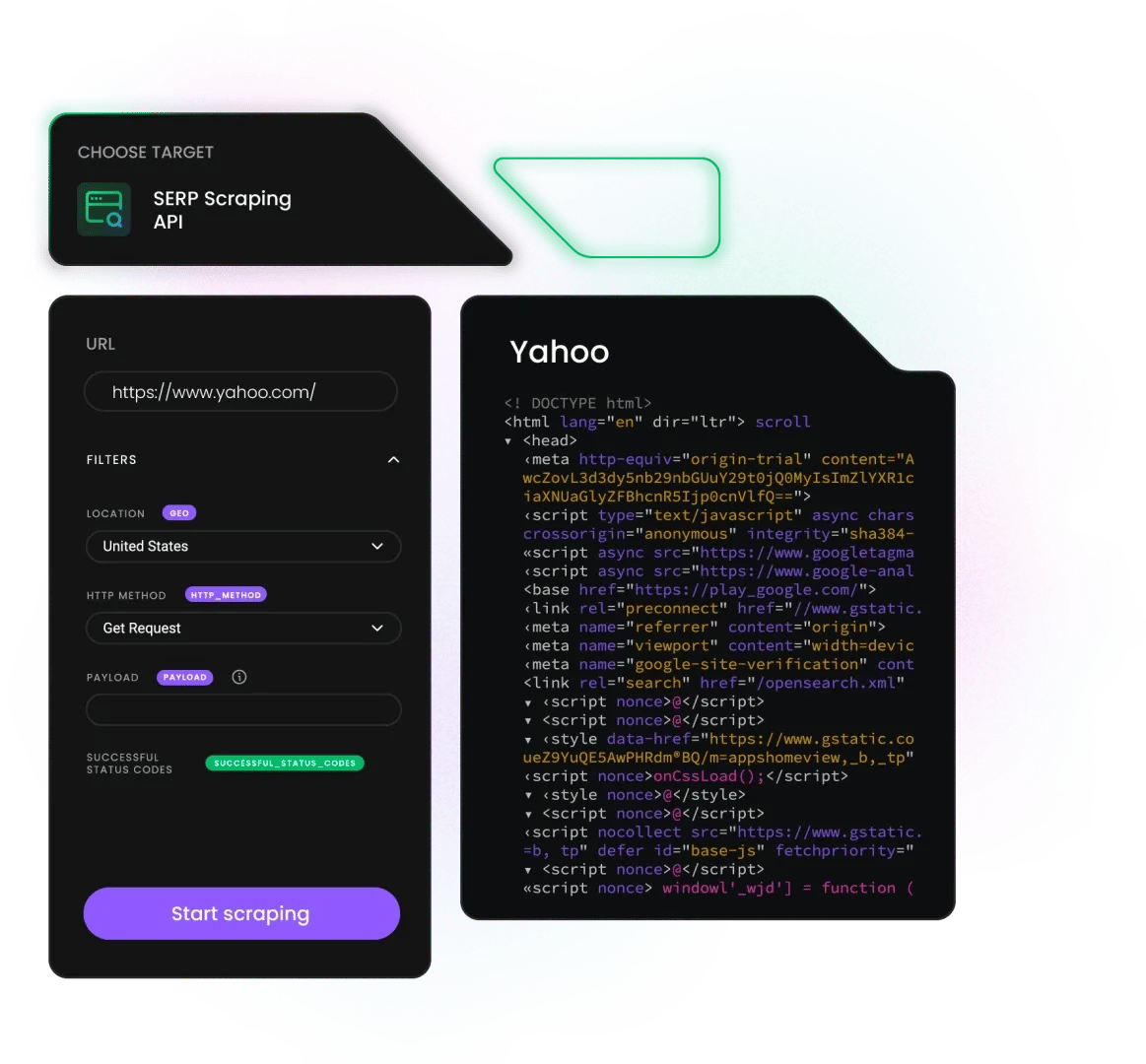
Extract data from Yahoo
Our SERP Scraping API is a powerful data collector that combines a web scraper and a pool of 125M+ residential, mobile, ISP, and datacenter proxies. That’s all you need to collect up-to-date product data from Yahoo.
Here are some of the key data points you can extract with it:
- Search result titles and URLs
- Meta descriptions and snippets
- Domain and display URLs
- Knowledge panel data
- Top stories, images, and video carousels
- Related searches and suggested queries
What is a Yahoo scraper?
A Yahoo Search scraper is a tool that extracts data from Yahoo’s web search results. This includes result titles, URLs, snippets, related searches, and other key data points for research, SEO analysis, or competitor monitoring.
With our Yahoo scraper API, you can send a single request to get the data you need in HTML format. Even if a request fails, we’ll automatically retry until the data is retrieved – you're only paying for successful requests.
The API is designed by our experienced developers and offers a range of handy features:
- Built-in scraper
- JavaScript rendering
- Integrated browser fingerprints
- Easy real-time API integration
- Vast country-level targeting options
- CAPTCHA handling
- AI Parser
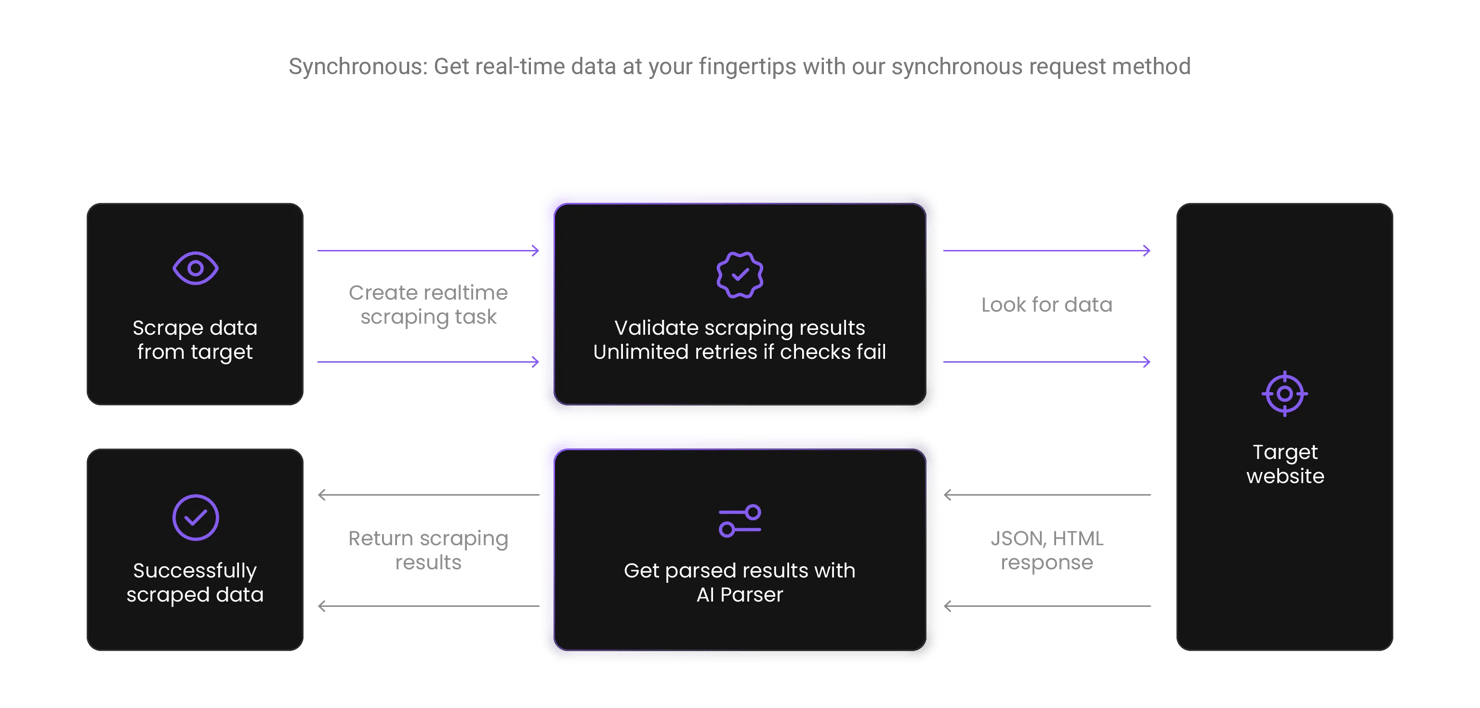
How does Yahoo scraper API work?
Yahoo scraper API imitates real user behavior to bypass anti-bot systems, extracting data from the website. You’ll get data in HTML, and the API will automatically retry whenever a request fails so that you reach the data you’re looking for.
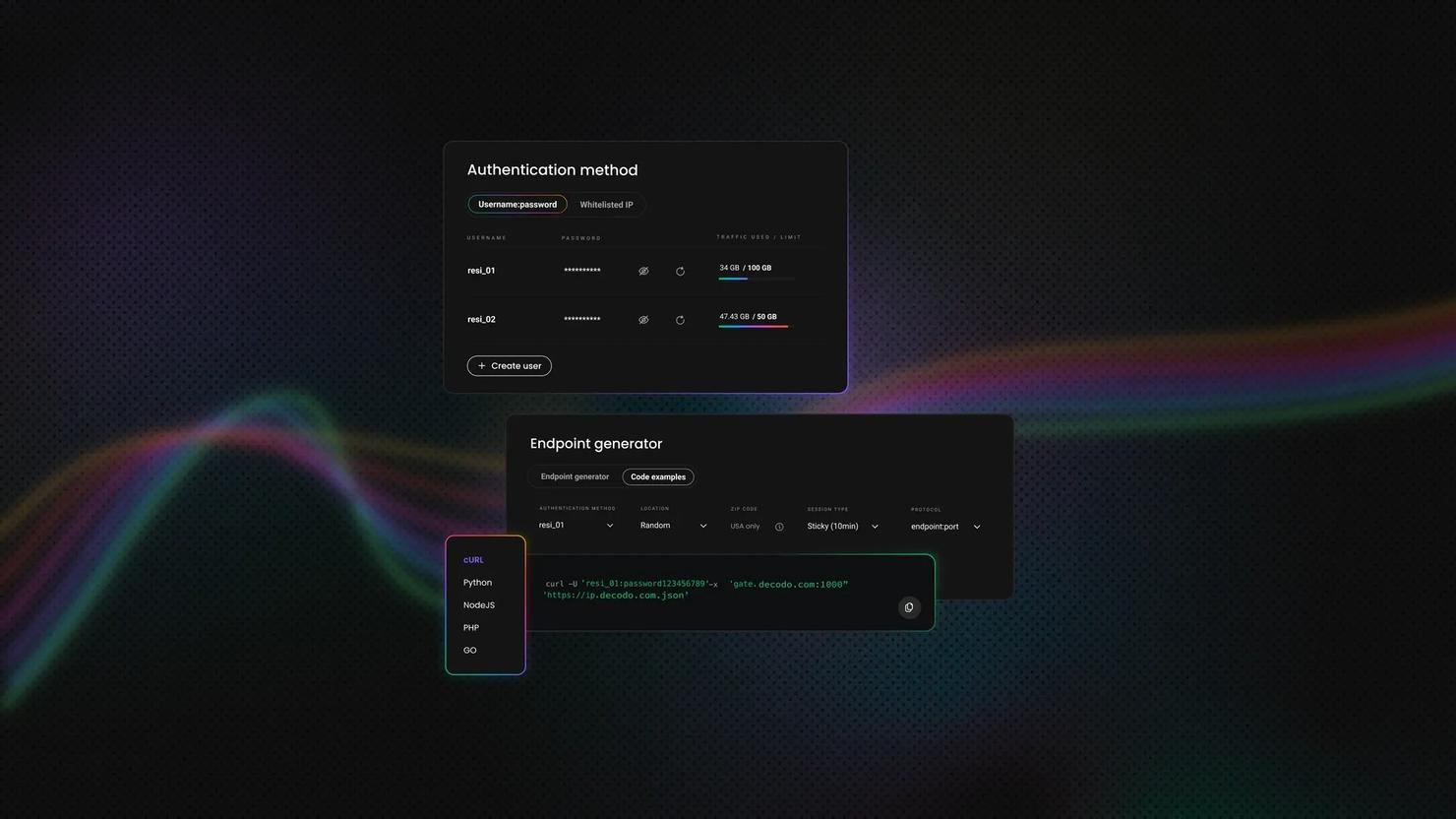
Scrape Yahoo with Python, Node.js, or cURL
Our Yahoo scraper API supports all popular programming languages for hassle-free integration with your business tools.
Collect data effortlessly with the Yahoo scraper API
Scrape Yahoo seamlessly using our powerful API. With built-in proxies and browser fingerprints, avoid CAPTCHAs and blocks for smooth, uninterrupted data collection.
Accurate results
Retrieve real-time HTML data right after submitting your Yahoo scraping request.
100% success
Scrape risk-free with pay-for-success pricing because you only pay for the news data you actually get.
Real-time or on-demand results
Get search data instantly or set up automated extractions for later.
Advanced anti-bot protection
Use integrated browser fingerprints to avoid detection and scrape without interruptions.
Simple setup
Launch our Yahoo scraper API in minutes using our quick start guide and code examples.
Proxy integration
Access region-specific news with 195+ locations, including country-, state-, and city-level targeting.
API Playground
Experiment with your Yahoo scraping requests in our interactive API Playground.
Get the most out of the Yahoo scraper API
Turn search results into insights by collecting various data points from Yahoo Search results.
SEO & search ranking monitoring
Track keyword rankings, featured snippets, and SERP elements to monitor your SEO performance and beat competitors.
Content & competitor research
Analyze competitor positioning by extracting search results to see what keywords they rank for and how their content performs.
Trendspotting
Spot rising search trends and emerging keywords to fuel your content strategy and ad targeting.
Local business & map listings
Collect local campaign results to track regional visibility, local competition, and other SEO data.
News tracking
Extract top stories from Yahoo News to stay on track with relevant topics and innovations in your industry.
Market & brand monitoring
Collect data on competitor presence and customer sentiment in Yahoo search results for reputation management and market analysis.
What does Web Scraping API cost?
Choose a plan based on your scraping volume. All plans include the same powerful features – you only pay for what you use. Start with the free plan to test before committing.
Plan prices
+VAT / Billed monthly
Rate limit
All prices shown are per 1K req.
Plan price
$0
+VAT / Billed monthly
Request type
Price per 1k req.
2K req.
$0.50
1K req.
$0.75
1K req.
$1.00
667 req.
$1.50
Rate limit
10 req/s
Plan price
$19
+VAT / Billed monthly
Request type
Price per 1k req.
38K req.
$0.50
25K req.
$0.75
19K req.
$1.00
12K req.
$1.50
Rate limit
10 req/s
Plan price
$49
+VAT / Billed monthly
Request type
Price per 1k req.
163K req.
$0.30
75K req.
$0.65
54K req.
$0.90
39K req.
$1.25
Rate limit
25 req/s
Plan price
$99
+VAT / Billed monthly
Request type
Price per 1k req.
707K req.
$0.14
165K req.
$0.60
116K req.
$0.85
82K req.
$1.20
Rate limit
50 req/s
Need more?
Request type
Price per 1k req.
Custom
Custom
Custom
Custom
Rate limit
Custom
For low-security sites and simple access
For accessing guarded or sensitive pages
With each plan, you access:
99.99% success rate
Results in HTML, JSON, CSV, XHR or PNG
MCP server
JavaScript rendering
AI integrations
100+ pre-built templates
Supports search, pagination, and filtering
LLM-ready markdown format
24/7 tech support
14-day money-back
SSL Secure Payment
Your information is protected by 256-bit SSL

Get support every step of the way
We’re proud to support a thriving community of 85K+ users. Explore customer feedback and join our community to share your experience, ask questions, and get the most out of our Yahoo scraper API.
Attentive service
The professional expertise of the Decodo solution has significantly boosted our business growth while enhancing overall efficiency and effectiveness.
N
Novabeyond
Easy to get things done
Decodo provides great service with a simple setup and friendly support team.
R
RoiDynamic
A key to our work
Decodo enables us to develop and test applications in varied environments while supporting precise data collection for research and audience profiling.
C
Cybereg
Featured in:
Decodo blog
Build knowledge on our solutions, or pick up some fresh ideas for your next project – our blog is just the perfect place.
Most recent
What is SOCKS Proxy?: Definition, Benefits & Use Cases
A SOCKS proxy is an internet protocol that routes network traffic through a third-party server and masks your IP address. It operates at the transport layer, handling any traffic type – TCP, UDP, web, gaming, torrenting, and more – without inspecting or modifying the data. In this blog entry, we’ll cover the ins and outs of SOCKS proxies, including how they work, key benefits, use cases, and how they compare against HTTP proxies.
Dominykas Niaura
Last updated: Jul 17, 2026
10 min read
Most popular
How to Scrape Google Images: A Step-By-Step Guide
Google Images is arguably the first place anyone uses to find photographs, paintings, illustrations, and any other visual files on the internet. Its vast repository of visual content has become an essential tool for users worldwide. In this guide, we'll delve into the types of data that can be scraped from Google Images, explore the various methods for scraping this information, and demonstrate how to efficiently collect image data using our Web Scraping API.
Dominykas Niaura
Last updated: Oct 28, 2024
7 min read

Google Sheets Web Scraping: An Ultimate Guide for 2026
Google Sheets is a powerful data management tool, but few people know it can also pull data directly from the web without a single line of code. Using built-in import functions, you can scrape website content, parse tables, and pull live feeds straight into your spreadsheet. In this guide, you'll learn how to use IMPORTXML for XPath-based data extraction, IMPORTHTML for grabbing tables and lists, IMPORTFEED for RSS and Atom content, IMPORTDATA for CSV files, and IMPORTRANGE to link scraped data across spreadsheets. We'll also cover Google Apps Script for automation, common errors and how to fix them, and when to reach for a dedicated scraping tool instead.
Zilvinas Tamulis
Last updated: Mar 30, 2026
6 min read

The Ultimate Guide to Web Scraping Job Postings with Python in 2026
Since there are thousands of job postings scattered across different websites and platforms, it's nearly impossible to keep track of all the opportunities out there. Thankfully, with the power of web scraping and the versatility of Python, you can automate this tedious job search process and land your dream job faster than ever.
Vilius Sakutis
Last updated: Mar 31, 2026
5 min read

Master VBA Web Scraping for Excel: A 2026 Guide
Excel is an incredibly powerful data management and analysis tool. But did you know that it can also automatically retrieve data for you? In this article, we’ll explore Excel's many features and its integration with Visual Basic for Applications (VBA) to effectively scrape and parse data from the web.
Zilvinas Tamulis
Last updated: Jan 29, 2026
7 min read

OnlyFans Scraping: The Complete Guide 2026
In recent years, there has been a significant shift in the way content creators, influencers, and artists connect with their audience and monetize their talents. OnlyFans, a subscription-based social media platform, has emerged as a website that allows creators to share exclusive content directly with their dedicated followers for a subscription fee.
OnlyFans scraping, which involves extracting publicly available data from the website, has sparked an interest. In this blog post, we’ll delve into this scraping world, its possible use cases, and the benefits it offers. Excited to learn more? Buckle up, and let’s begin!
Justinas Tamasevicius
Last updated: Jan 15, 2026
6 min read
What Is Web Scraping? A Complete Guide to Its Uses and Best Practices
Web scraping is a powerful tool driving innovation across industries, and its full potential continues to unfold with each day. In this guide, we'll cover the fundamentals of web scraping – from basic concepts and techniques to practical applications and challenges. We’ll share best practices and explore emerging trends to help you stay ahead in this dynamic field.
Dominykas Niaura
Last updated: Jan 29, 2025
10 min read

What Is SERP Analysis And How To Do It?
SERP (Search Engine Results Page) analysis involves examining search engine results for specific keywords to understand website rankings. It helps identify the content, format, and optimization strategies used by top-ranking pages and uncovers opportunities for improving rankings. In this blog post, we’re exploring what SERP analysis is, how to conduct it, and how it can help you.
James Keenan
Last updated: Feb 20, 2023
7 min read
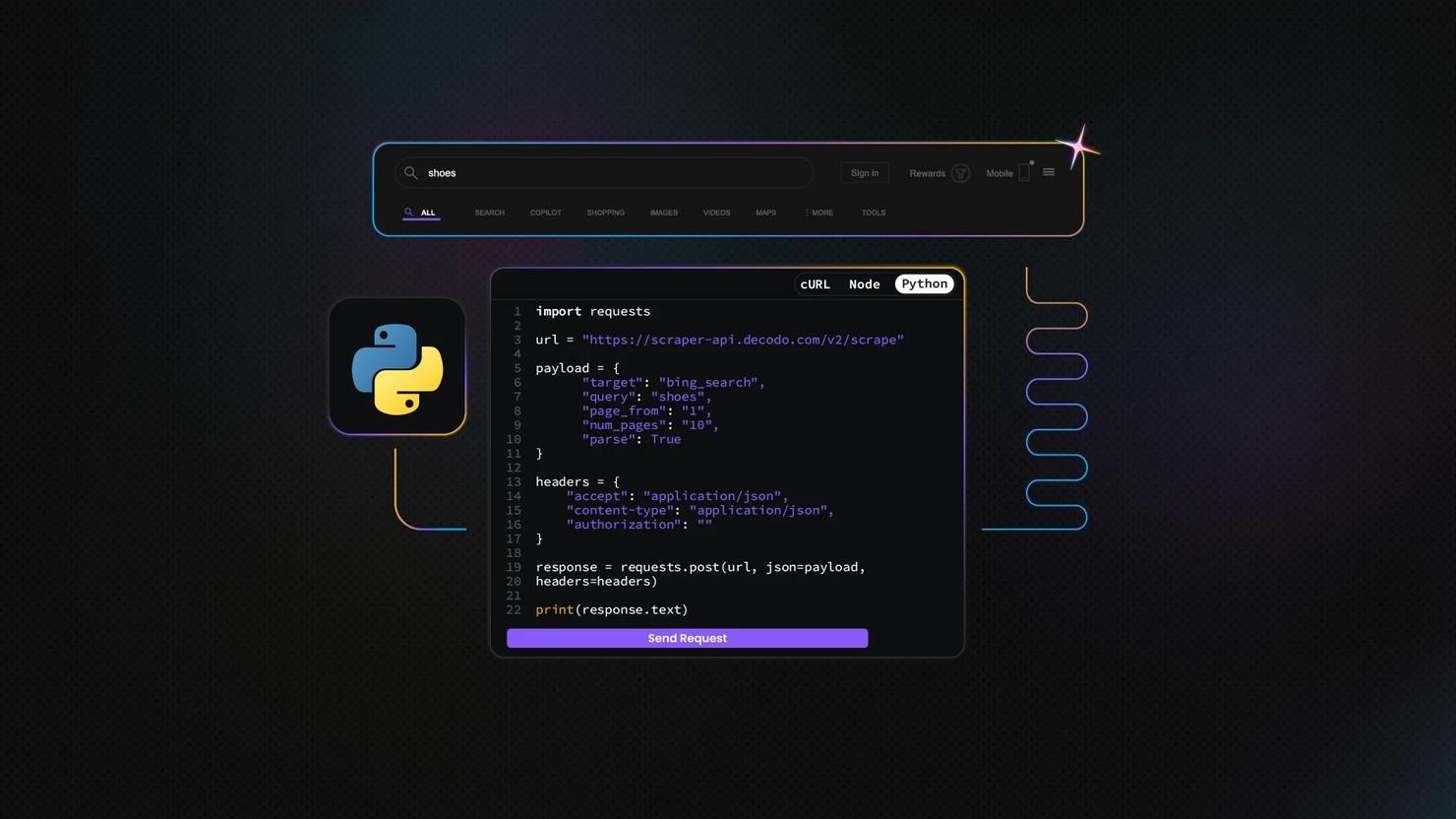
How to Scrape Bing Search with Python
Bing scraping is the automated extraction of rankings, ads, snippets, and search features from Bing's SERPs. Since Microsoft retired all official Bing Search APIs in 2025, scraping and third-party SERP APIs are the main ways to access this data programmatically. This guide covers Python-based approaches using Requests, Beautiful Soup, Playwright, and Decodo's Web Scraping API.
Zilvinas Tamulis
Last updated: Jul 13, 2026
12 min read

How to Scrape Data from Google Play Store
Ever wondered how some app developers always seem one step ahead on Google Play? The secret often comes down to data – lots of it. Instead of waiting around for monthly “Top Charts” updates, the smartest teams use Google Play scrapers to track real-time metrics and stay ahead of the competition. In this article, you’ll learn how to do exactly that, gaining the tools to effortlessly scrape everything from download totals to one-star rant emojis.
Lukas Mikelionis
Last updated: Jul 07, 2025
6 min read
How to Scrape Google Finance
Google Finance is one of the most comprehensive financial data platforms, offering real-time stock prices, market analytics, and company insights. Scraping Google Finance provides access to valuable data streams that can transform your analysis capabilities. In this guide, we'll walk through building a robust Google Finance scraper using Python, handling anti-bot measures, and implementing best practices for reliable data extraction.
Dominykas Niaura
Last updated: Jun 25, 2025
10 min read

How to Scrape Google Shopping: Extract Prices, Results & Product Data (2025)
Google Shopping is a product search engine that aggregates listings from thousands of online retailers. Businesses scrape it to track competitor pricing, spot trends, and gather valuable eCommerce insights. Using APIs, no-code tools, or custom scripts, you can extract data like product titles, prices, ratings, and more. In this guide, we’ll build a custom scraping script using Python and Playwright!
Dominykas Niaura
Last updated: May 30, 2025
10 min read
How to Scrape Google Scholar With Python
Google Scholar is a free search engine for academic articles, books, and research papers. If you're gathering academic data for research, analysis, or application development, this blog post will give you a reliable foundation. In this guide, you'll learn how to scrape Google Scholar with Python, set up proxies to avoid IP bans, build a working scraper, and explore advanced tips for scaling your data collection.
Dominykas Niaura
Last updated: May 12, 2025
10 min read

How to Scrape Google Without Getting Blocked
Nowadays, web scraping is essential for any business interested in gaining a competitive edge. It allows quick and efficient data extraction from a variety of sources and acts as an integral step toward advanced business and marketing strategies.
If done responsibly, web scraping rarely leads to any issues. But if you don’t follow data scraping best practices, you become more likely to get blocked. Thus, we’re here to share with you practical ways to avoid blocks while scraping Google.
James Keenan
Last updated: Feb 20, 2023
8 min read
Frequently asked questions
What are the main advantages of using a Yahoo scraper API over manual data collection?
The biggest benefit of using a Yahoo scraper is that it’s automated. This means it’s faster, more efficient, and simply more streamlined over manual tasks – especially with large amounts of data. For businesses serious about leveraging data, powerful tools like Yahoo scraper API are simply non-negotiable.
How does using a Yahoo scraper API enhance data accessibility for analysis?
The Yahoo scraping API delivers data in HTML, which you can parse with your own custom solutions or AI Parser to make it instantly usable in analytics, machine learning, and other pipelines. Also, our Yahoo scraper has a built-in pool of 125M+ IPs and integrated browser fingerprints that open up content that’s behind geo-restrictions.
What are the minimum requirements to start using Yahoo scraper API?
A Decodo account with an active Yahoo scraper API subscription (or a free plan ) is enough to start scraping. Read our quick start guide to help you set up and customize your scraping requests with our intuitive and user-friendly dashboard – no coding required.
How do I troubleshoot common Yahoo scraper API setup issues?
If you run into issues with the Yahoo scraper API, you can start troubleshooting with our extensive documentation or Knowledge Hub. It houses everything from quick start guides to frequently asked questions to help you pinpoint the solution. You can also join our Discord community to ask questions for hands-on help. If you don’t find the answers there, reach out to our 24/7 tech support via LiveChat.
Are proxies required to scrape Yahoo, or can I scrape without them?
Yes, you need a powerful scraper backed up with a large pool of proxies to be able to scrape Yahoo effectively – especially on a larger scale. Huge platforms like Yahoo have sophisticated anti-bot systems that flag unusual traffic patterns. Without a robust proxy solution, your IP address will be quickly detected and blocked, making any high-volume data collection impossible.
Get the Yahoo scraper API for Your Data Needs
Gain access to real-time data at any scale without worrying about proxy setup or blocks.
14-day money-back option