Real Estate Data Scraping: Ultimate Guide
Real estate web scraping has become an essential way to collect up-to-date property data from platforms like Zillow, Realtor.com, Redfin, Rightmove, and Idealista without manual effort. Automated extraction helps individuals and businesses track prices, compare neighborhoods, and monitor supply trends with higher accuracy. In this guide, you'll get a practical overview of the tools, methods, and considerations involved in working with real estate listings as structured data for analysis, research, and everyday business use.
Dominykas Niaura
Last updated: Dec 10, 2025
8 min read
What is real estate scraping?
Real estate scraping is the practice of collecting publicly available property data from listing platforms and aggregators with automated tools. It helps analysts, investors, and businesses monitor markets, track price trends, compare locations, and feed internal dashboards without manual data entry.
Most workflows rely on HTTP requests or browser automation to fetch listing pages, parse their structured and unstructured elements, and export the extracted fields into a usable format.
Common data points extracted include:
- Listing titles
- Prices and price histories
- Property types and categories
- Addresses and GPS coordinates
- Descriptions and amenities
- Square feet/meters and lot sizes
- Bedroom and bathroom counts
- Photos and media URLs
- Agent or seller information
- Availability and posting dates
Why scrape real estate data?
Scraping real estate data offers a direct way to understand market movements and support data-driven decisions. Automated collection ensures that information stays current and consistent across regions and platforms, which is valuable for anyone working with property trends or portfolio planning.
Key benefits and use cases of scraping real estate websites include:
- Market analysis. Track pricing patterns, supply changes, and neighborhood dynamics.
- Competitive research. Compare listings across multiple platforms and monitor how other agencies position similar properties.
- Lead generation. Build lists of agents, landlords, or property owners for outreach.
- Price comparison. Identify undervalued properties or benchmark pricing strategies.
- Investment insights. Evaluate potential yields by combining scraped attributes with external datasets.
- Automation. Reduce repetitive manual research and keep internal databases up to date.
Tools for real estate scraping
Building a real estate scraping stack usually comes down to three main options: using official public APIs where available, building custom scrapers for direct control, or relying on third-party scraping APIs for scale and stability. Most production workflows combine these approaches depending on the platform and data volume.
Official public APIs
Some real estate platforms provide official APIs that deliver structured, well-documented data for listings, property details, and market insights. These options are more stable than HTML parsing and reduce long-term maintenance.
However, most major platforms covered here don't offer open public APIs. Zillow's API is deprecated, and Realtor.com, Redfin, and Rightmove provide no public endpoints. Idealista has an official API but requires a commercial agreement. Because accessible APIs are limited, scraping remains the primary method for gathering real estate data.
Custom scrapers
Python is one of the best options for most real estate scraping projects thanks to its readability, broad ecosystem, and strong community support. It offers a straightforward toolkit for sending requests, parsing HTML, and running headless browsers when pages rely on dynamic content.
Popular libraries and frameworks include:
- Requests. A simple way to fetch HTML for static pages.
- Beautiful Soup. A lightweight HTML parser for extracting text and attributes.
- Selenium. A browser automation tool that handles dynamic pages, logins, and interactive flows.
- Playwright. A modern alternative to Selenium with faster execution and reliable automation across Chromium, Firefox, and WebKit.
- Scrapy. A full-featured scraping framework that helps manage spiders, pipelines, throttling, and structured exports.
Third-party scraper APIs
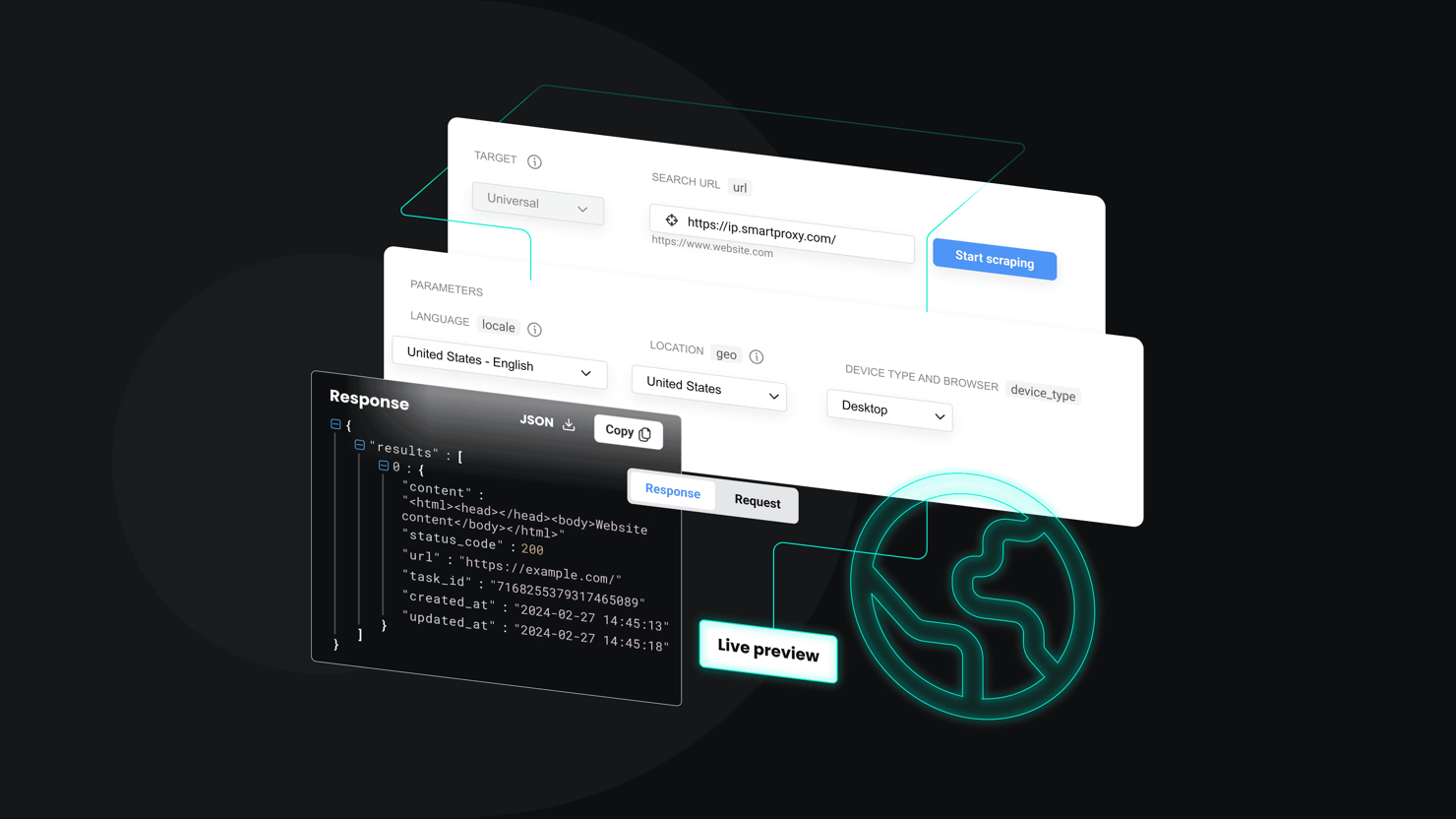
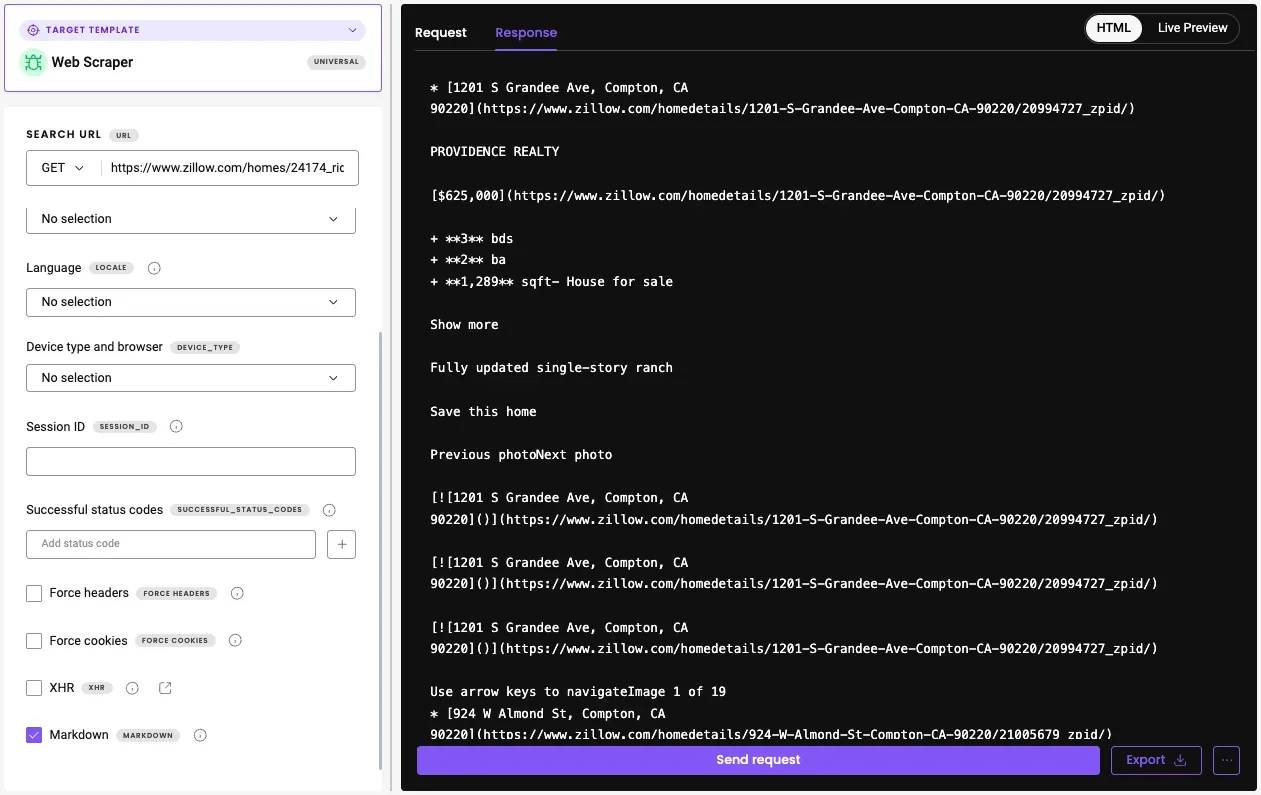
For teams that prefer not to manage proxies, CAPTCHAs, or browser overhead, third-party solutions can simplify the workflow. Decodo's Web Scraping API handles dynamic content rendering, IP rotation, automatic retries, and anti-block responses, returning HTML, JSON, CSV, or Markdown results for any target page. This reduces maintenance and helps scale data extraction across multiple real estate platforms.
The API includes 100+ ready-made templates for popular websites. If the real estate platform you want to scrape isn't in the list, use the Web (universal) target, which returns the HTML of any page. You can then build a parsing logic for this output.
But if you prefer a more readable format right out of the box, enable the Markdown option – real estate pages work especially well with it, since they contain little unnecessary markup and present data in a clear, text-oriented structure.
Get Web Scraping API for real estate sites
Claim your 7-day free trial of our scraper API and explore full features with unrestricted access.
How to scrape popular real estate websites
Each real estate platform structures and delivers its data differently, so scraping methods need to adapt to the site's layout, pagination, dynamic content, and anti-bot measures. The following sections outline practical considerations for Zillow, Realtor.com, Redfin, and major international platforms such as Rightmove and Idealista. By understanding how these sites load and present their listings, you can choose the right tools and build more resilient scrapers.
Scraping Zillow
Zillow remains one of the largest real-estate marketplaces in the United States. That makes it a frequent target for scraping – yet its technical setup and protections present real obstacles. Zillow's pages often rely on dynamic JavaScript and employ anti-scraping protections.
Website structure overview
Zillow relies heavily on JavaScript for loading full listing pages, maps, and interactive elements. However, many key summary data points, such as price, address snippets, and basic property labels, are still present directly in the initial HTML. For example, price values on search result cards are often exposed through clear, structured HTML elements with stable data attributes.
Technical challenges
While some core fields are available in raw HTML, deeper listing details, image galleries, history data, and user interaction elements are typically loaded dynamically. Zillow also applies bot detection, traffic fingerprinting, and request pattern analysis, which can lead to temporary blocks or CAPTCHAs during larger crawls. As a result, simple HTTP scraping may work for small-scale price tracking but becomes unreliable for full dataset extraction.
Example approach and tools
Because of the above issues, scraping Zillow effectively usually requires tools that can render JavaScript just as a real browser does – for example, headless browsers or browser-automation frameworks. Others take a different route: some third-party scraping services combine rendering, proxy rotation, and anti-bot bypass into managed APIs. Using these approaches can improve reliability and reduce the risk of blocks when scraping large numbers of listings over time.
Scraping Realtor.com
Realtor.com is one of the largest real-estate listing platforms in the United States, offering a wide variety of public property listings aggregated from MLS (Multiple Listing Services) and other sources. Its popularity and volume of listings make it a common target for scraping, but the site also presents a mixture of opportunities and challenges.
Navigating search results
On Realtor.com, each search result is often wrapped as a single clickable <a> block, where only limited details are directly exposed as separate HTML elements. Basic identifiers such as the full address and unit are usually accessible via attributes like aria-label, while visible fields such as price, bedroom, bathroom count, and square footage are rendered visually but not always cleanly separated in the markup. As a result, scraping purely from HTML can reliably capture high-level summary data, but richer listing attributes are more consistently extracted from embedded JSON data or internal search endpoints.
Handling anti-bot measures
Realtor.com enforces strict rate limiting and traffic filtering that can return 429 responses even at low request volumes. Blocks often occur before any meaningful HTML is delivered, which suggests that access control happens at the network level rather than only through front-end bot detection. As a result, both simple HTTP requests and headless browser sessions may be denied without additional traffic management layers.
Example approach and tools
Reliable scraping of Realtor.com typically requires high-trust residential or ISP proxies along with careful request pacing. User-agent rotation and realistic browser headers help, but are often not sufficient on their own.
For production-scale extraction, managed scraping APIs are commonly used because they combine proxy rotation, fingerprint management, retries, and optional JavaScript rendering into a single workflow. Without these protections, stable access is difficult to maintain even for small crawls.
Scraping Redfin
Redfin is a major US real estate platform that aggregates MLS data and also represents its own brokerage services. Compared to Zillow and Realtor.com, Redfin often emphasizes accuracy, frequent updates, and detailed transaction history, which makes it especially valuable for market trend analysis.
Unique features and data points
Redfin listings commonly include real-time status indicators such as active, pending, and sold, along with detailed price history, time on market, and estimated value ranges. Many listings also include map-driven neighborhood insights, school ratings, walk scores, and comparable sales. This combination supports deeper analysis of pricing movement and local demand.
Tips for accessing and parsing data
Redfin's listing cards are rendered as deeply nested, JavaScript-driven components, which makes it difficult to isolate a single clean HTML block using standard inspection tools. Even when individual data points like price, address, or stats are visible in the DOM, they are often spread across multiple dynamic elements that are re-rendered as the map or list view updates. This makes selector-based scraping fragile for long-term use.
A more reliable approach is to extract listing data from the structured sources Redfin uses internally, such as JSON-LD scripts embedded in the page or JSON responses loaded through background network requests. These sources usually contain cleaner, more complete data for prices, beds, baths, square footage, coordinates, and listing status. Combining this JSON-first method with headless browsers or realizing it through a scraping API helps maintain stability as the front-end layout shifts.
Scraping international platforms (Rightmove, Idealista, etc.)
Real estate platforms outside the US follow different frontend strategies and access controls. Rightmove dominates the UK market, while Idealista is widely used across Spain, Italy, and Portugal. Unlike many US platforms, both expose core listing data such as prices directly in the HTML, which makes selector-based scraping technically straightforward. However, access to this HTML is often gated by strict traffic filtering.
Key differences
Rightmove and Idealista display key fields like price, property type, and location in clean, readable HTML elements. This allows lightweight parsing once access is granted. At the same time, pagination, filters, and map interactions are still dynamically loaded. Localization adds further complexity through currencies, number formatting, and unit systems.
Adjusting scraping strategies
To adapt your scraper to these platform-specific differences, focus on the following techniques:
- Use developer tools to target clean HTML selectors for prices and core attributes only after access is confirmed.
- Use residential or ISP proxies from the target country to pass geographic and reputation checks.
- Maintain low request frequency and stable sessions with cookies.
- For high-volume or production scraping, rely on managed scraping APIs that handle fingerprinting, retries, and session rotation automatically.
Popular real estate website scraping compared
Platform
Typical data access method
Main challenges
Recommended tooling
Zillow
Core data in HTML, deeper data via JavaScript
Bot detection, CAPTCHAs, traffic fingerprinting
Headless browser + proxies or scraping API
Realtor.com
Limited HTML, most reliable data via internal JSON
Aggressive rate limiting, instant IP blocking
High-trust residential or ISP proxies or scraping API
Redfin
JavaScript-rendered components + background JSON
Dynamic re-rendering, fragmented DOM, selector instability
Headless browser + proxies + JSON endpoint parsing or scraping API
Rightmove / Idealista
Core listing data in clean HTML
Strict WAF filtering, 403 blocks, session fingerprinting, geo checks
Playwright + proxies or scraping API
Overcoming common scraping challenges
Real estate platforms often employ anti-scraping systems that limit repeated requests, detect automated traffic, or hide content behind dynamic scripts. These measures can interrupt data collection or lead to incomplete results, so a stable setup usually combines several techniques.
Anti-scraping technologies and solutions
Real estate websites frequently add friction to automated access, using tools that monitor traffic patterns or restrict how much data a visitor can load in a short time. Knowing how these systems work makes it easier to design scrapers that stay consistent and avoid unnecessary blockers:
- Rate limiting. Slow down your request frequency, randomize intervals, and avoid patterns that resemble bots.
- Bot detection. Rotate user-agents, handle cookies, and mimic normal browser behavior.
- Dynamic rendering. Use tools that can execute JavaScript when essential content appears only after the page loads.
- CAPTCHA triggers. Incorporate a scraping API that offers automatic retries and bypass handling.
Proxy rotation, headless browsers, API usage
To keep scrapers reliable at scale, you often need extra tooling that masks automation, handles dynamic content, and distributes traffic safely across IPs. These methods strengthen your setup and improve success rates.
- Proxy rotation. Switching IPs reduces the chance of blocks on large crawls. Residential or ISP proxies offer higher trust signals than datacenter IPs.
- Headless browsers. Selenium or Playwright can render JavaScript, scroll through listings, and simulate real interactions. This helps when the page structure is heavily dynamic.
- Scraping APIs. Services such as Decodo's Web Scraping API combine proxy rotation, headless execution, and anti-block logic into a single endpoint. They reduce maintenance and keep the extraction flow consistent across platforms.
Scrape real estate data
Bypass anti-scraping restrictions and save time with our all-in-one Web Scraping API.
Storing and using scraped data
After extracting real estate listings, the focus shifts to keeping the information structured, accessible, and ready for analysis. A clear storage strategy helps maintain long-term value, while thoughtful integrations ensure the data supports reporting, forecasting, and everyday business workflows.
Exporting to CSV, databases, or cloud storage
After collecting listings, save your scraped data in a format that supports easy retrieval and later analysis. Different storage options work better depending on scale and how frequently the data will be updated.
- CSV files. Simple to generate and easy to open in spreadsheets or import into most tools. Good for small to medium datasets and quick checks.
- Databases. Use PostgreSQL, MySQL, or NoSQL stores when you need indexing, deduplication, or frequent queries. This is better suited for ongoing crawls and larger volumes.
- Cloud storage. Save raw HTML, JSON, and exports in S3-compatible buckets or similar services so you can reprocess data later without scraping again.
Integrating with analytics or business tools
Once your data is stored in a structured way, you can connect it to internal systems that help you turn raw listings into insights and workflows.
- BI and dashboards. Connect your database or CSV exports to tools like Looker Studio, Power BI, or Tableau to track price trends, inventory changes, and regional comparisons.
- CRM and lead tools. Pipe agent or owner data into your CRM to power outreach campaigns and follow-ups.
- Custom apps. Feed cleaned property data into internal tools, valuation models, or recommendation systems that support your investment or sales workflows.
Advanced strategies and automation
As your data needs grow, automation helps keep scrapers consistent and responsive without manual oversight. These approaches support continuous data collection and faster reactions to market changes.
Scheduling scrapers
Set your scrapers to run at fixed intervals so datasets stay fresh and aligned with platform update cycles. Use tools like cron, Airflow, or cloud task schedulers to manage timing, retries, and logging. Regular schedules also help track long-term trends without rebuilding data from scratch.
Real-time monitoring and alerts
Real-time monitoring helps you catch important listing changes as they happen, such as sudden price drops, new properties in a target area, or scraping failures. Alerts can be sent to email, Slack, or internal dashboards so you can react immediately and keep your data pipeline reliable.
Tools like n8n make this easier by automating the full flow from scraping to notifications. With visual workflows, you can schedule checks, compare fresh results with past data, and trigger alerts or updates without writing custom monitoring logic.
Best practices for scraping real estate websites
Scraping real estate platforms works best when approached with care. Clear boundaries and thoughtful execution help maintain smooth access and reduce the risk of disruption to your data workflows.
Legal and ethical boundaries
Each platform has its own rules for how its public content may be accessed. Review a site's terms of service, use scraped data responsibly, and avoid collecting information that isn't meant to be public. Maintain transparency inside your organization about how data is sourced and how it will be used.
Minimizing server load
Scraping shouldn't strain the target website. Keep request rates moderate, space out crawls, and avoid patterns that resemble aggressive harvesting. Cache previously collected pages when possible and fetch only what you need. Responsible scraping helps preserve stable access for both you and other visitors.
Advanced tips and resources
Once you have a stable scraping workflow, a few extra techniques can help you speed up development, reduce maintenance, and discover new approaches used by the wider scraping community.
Using headless browsers for speed
Modern tools like Playwright and headless Chromium offer faster execution and more reliable automation than older setups. They handle dynamic elements smoothly and allow parallel sessions, which helps reduce overall run times when scraping high volumes of listings.
Integrating third-party services
Services such as Decodo's Web Scraping API combine rendering, proxy rotation, retries, and anti-block features into a single request. This removes the need to maintain your own browser cluster or proxy pool and simplifies scaling when targeting multiple real estate platforms.
Further reading and community resources
When scraping challenges get specific or technical, developer communities and official documentation become essential. These sources help validate approaches, troubleshoot errors, and discover platform-specific quirks faster:
- Reddit r/webscraping. An active community for real-world scraping problems, blocking behavior, tool comparisons, and workflow advice.
- Playwright DevDocs. The most reliable reference for browser automation methods, selectors, and debugging tools.
- GitHub. Search for platform-specific open-source scrapers to see how others handle Zillow, Realtor.com, or Idealista. Real projects often reveal hidden edge cases.
- Stack Overflow. Search by platform name (like Zillow) to find solutions to errors, blocking issues, and selector problems others have already solved.
Final thoughts
Real estate scraping gives teams a direct way to track market activity, compare listings across platforms, and build consistent datasets without manual effort. With the right tools and strategies in place, it becomes possible to capture property details at scale, monitor changes over time, and support informed decisions across analytics, investment, and sales workflows.
By combining thoughtful scraping methods with automation, proper storage, and responsible practices, you create a reliable system that continues delivering value. The result is a flexible foundation for market analysis, lead generation, and any data-driven projects built around real estate insights.
Access real estate platforms with our scraper
Unlock superior scraping performance with a free 7-day trial of Decodo's Web Scraping API.
About the author

Dominykas Niaura
Technical Copywriter
Dominykas brings a unique blend of philosophical insight and technical expertise to his writing. Starting his career as a film critic and music industry copywriter, he's now an expert in making complex proxy and web scraping concepts accessible to everyone.
Connect with Dominykas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.