How to Scrape Indeed for Job Data: A Comprehensive Guide
Indeed hosts millions of job listings across industries and locations, making it a valuable data source for analysts, recruiters, data engineers, and founders who need real-time job intelligence. Scraping job data is challenging because sites change and anti-bot defenses evolve. This guide walks you through a resilient, modern approach that works reliably today – and scales when you need it to.
Zilvinas Tamulis
Last updated: Sep 12, 2025
14 min read
What data can you extract?
Indeed is a popular job search platform, operating in over 60 countries, with 615M+ job-seeker profiles and 3.3M+ employers, resulting in approximately 27 hires per minute. It offers various job types across country-specific sites, making its dataset a widely used source for labor-market analysis.
Standard Indeed job scraping yields the essentials:
- Job titles, company data, locations
- Posting timestamps, job URLs/IDs
- Descriptions, benefits, and salary ranges where disclosed
- Job type (full-time, part-time, or contract)
Why it matters – data engineers use this to build real-time job intelligence pipelines. Analysts track hiring velocity across tech stacks and geographies. Founders monitor competitor hiring patterns to spot market opportunities.
Now that you know what data you can collect, let's understand how Indeed's website is structured and how that affects our approach to scraping.
Understanding Indeed's data architecture
Indeed organizes job information in a consistent structure that allows efficient extraction once you understand the moving parts.
How Indeed search works
Indeed constructs search URLs with stable parameters that you can modify programmatically. A basic search looks like:
https://www.indeed.com/jobs?q=data+analyst&l=Chicago%2C+IL
Key parameters you’ll use:
- q – query keywords (for example, data analyst)
- l – location (for example, Chicago, IL; use remote for remote roles)
- start – pagination offset in increments of 10 (0, 10, 20, …)
- sort=date – newest results first
- fromage – posting age filter (for example, 1 = last 24 hours)
- radius – distance from the location center (for example, 100 = within 100 miles)
Regional domains include:
- USA – www.indeed.com
- Canada – ca.indeed.com
- UK – uk.indeed.com
- Australia – au.indeed.com
Others vary by country.
A reliable shortcut – embedded JSON beats brittle HTML
Scraping Indeed is challenging due to its dynamic, JavaScript-rendered content and complex HTML structure, which can be difficult to navigate reliably. Targeting embedded JSON data offers a more stable and efficient alternative to parsing the DOM. Rather than maintaining many CSS selectors, parse the structured payload that Indeed injects into the page. The most useful data appears under:
This JSON contains the job listings before HTML rendering and typically offers:
- A more stable structure than the rendered DOM
- Complete listing fields in one place
- Faster extraction without deep DOM parsing
To locate this data:
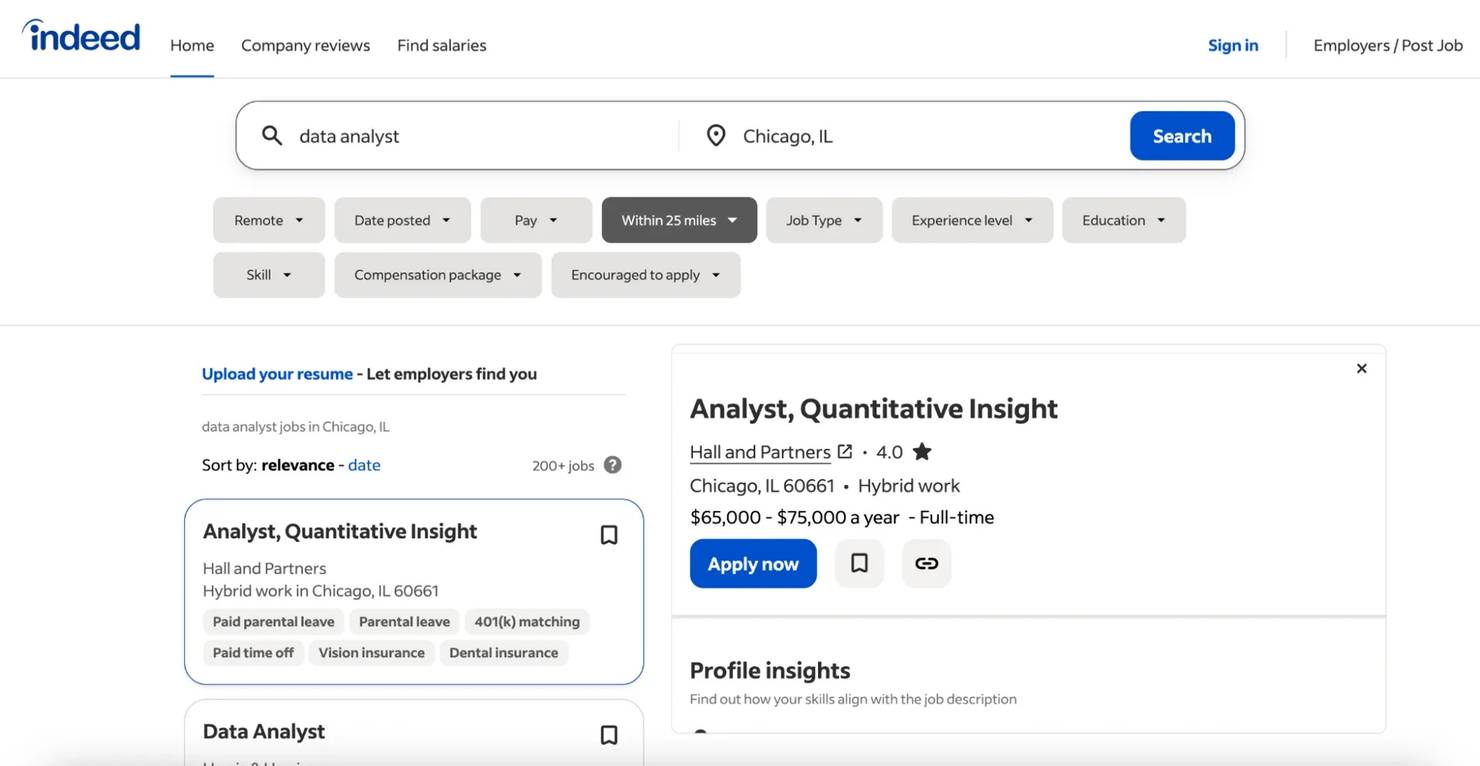
Step 1. Open an Indeed search results page:
Step 2. Open your browser developer tools.
Step 3. Go to the Network tab, refresh the page to populate results, then filter by Doc:
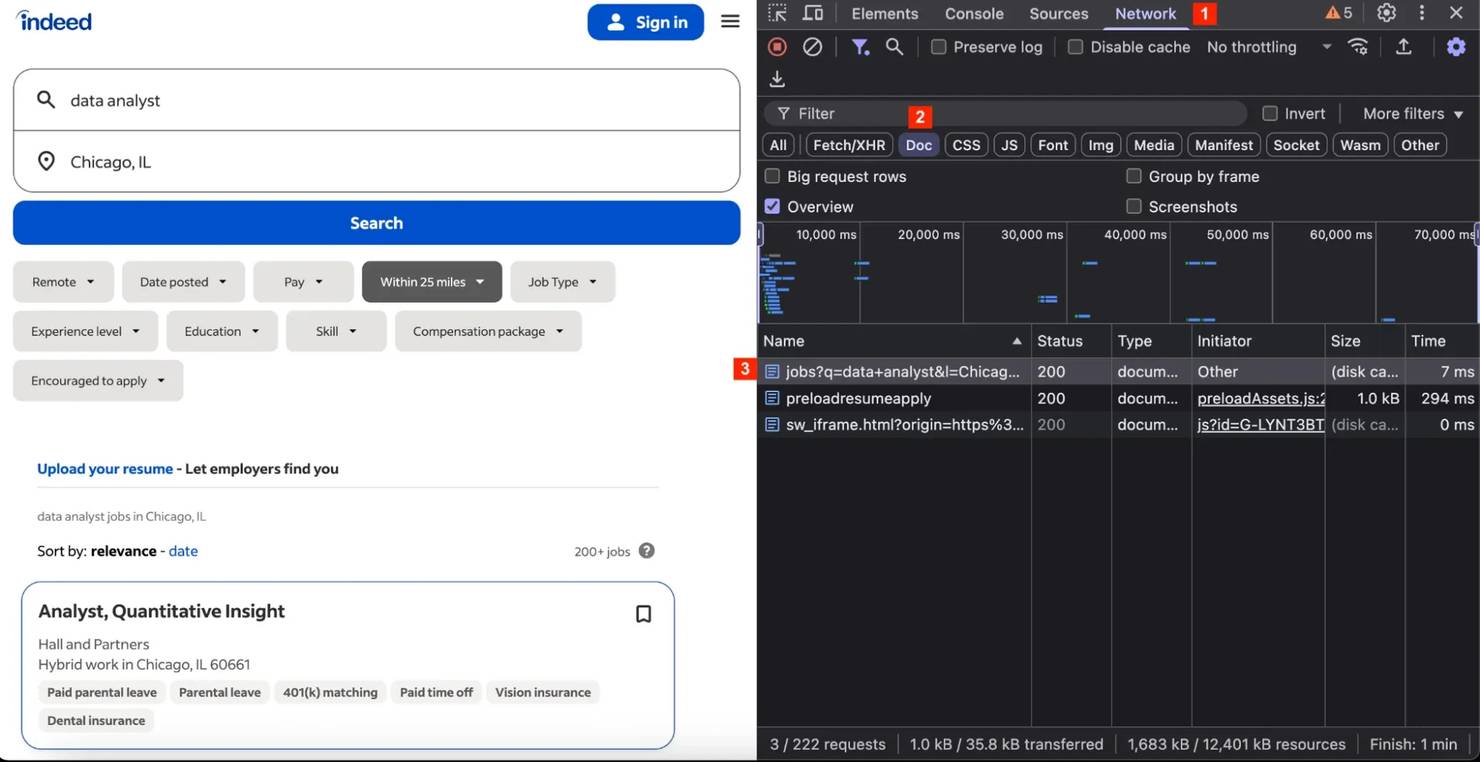
Step 4. Select the main HTML response.
Step 5. Search for window.mosaic.providerData["mosaic-provider-jobcards"] in the response to view the embedded JSON:
![DevTools Network panel showing window.mosaic.providerData["mosaic-provider-jobcards"] = {"metaData": JSON response in browser Network tab with request list](https://decodo.com/cdn-cgi/image/width=1480,quality=70,format=auto/https://images.decodo.com/indeed_scraping_step5_png_61313aad9f/indeed_scraping_step5_png_61313aad9f.webp)
Inside you’ll find results (an array of job records):
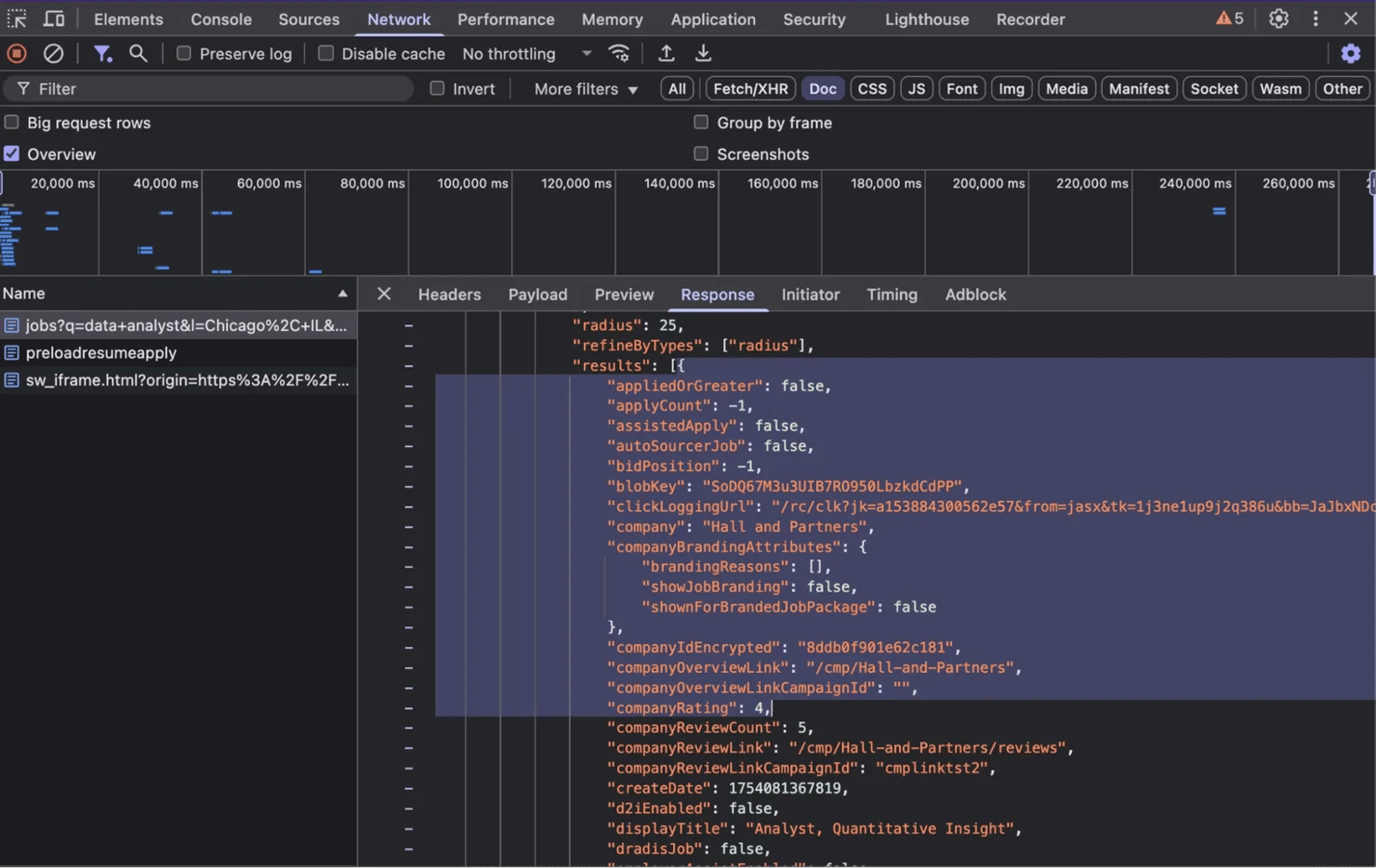
The hierarchy commonly looks like:
With Indeed’s URL patterns and JSON structure in mind, we can now cover common scraping challenges.
Common anti-scraping challenges
Indeed employs multiple layers of bot mitigation to flag and block automated traffic.
- CAPTCHA and behavioral detection. Cloudflare Turnstile or sign-in gates appear when traffic shows automated patterns such as high request rates, headless browser defaults, or mismatched geo.
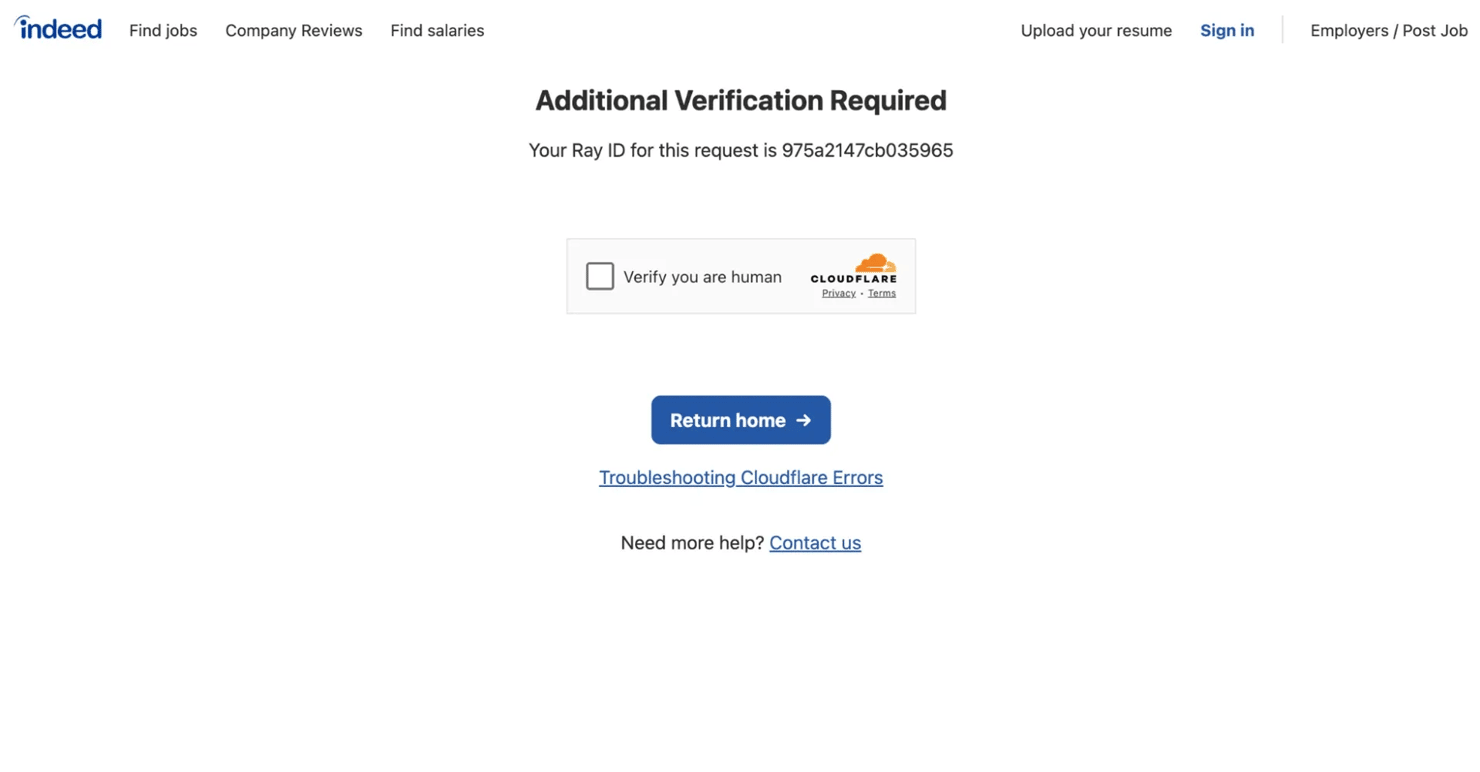
- Rate limiting and IP blocks. Excessive bursts from a single IP trigger throttling or temporary bans.
- Browser fingerprinting. TLS signatures and JavaScript execution patterns that don’t resemble human browsing are flagged quickly.
- Login walls. After rapid navigation, you may be required to create an account or sign-in.
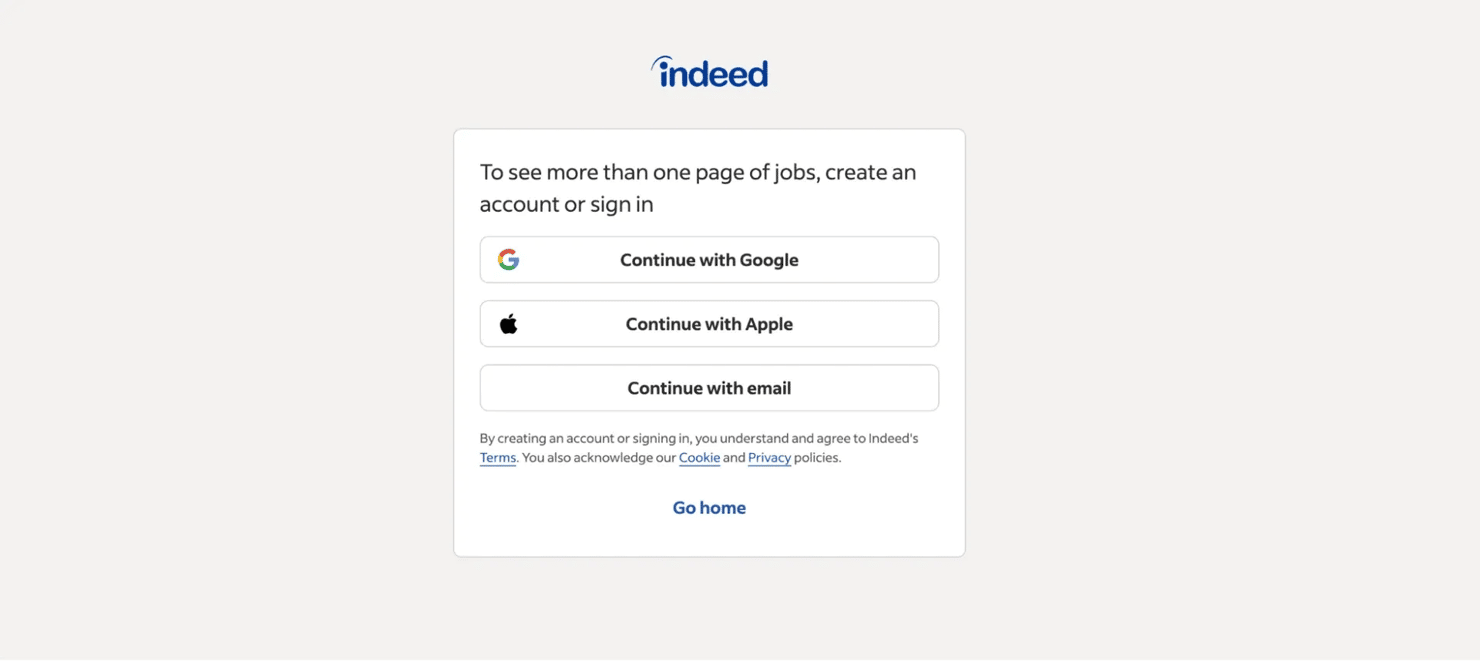
With the challenges in mind, let’s pick the right tool for the job.
Overcome obstacles with ease
Bypass CAPTCHAs, rate limits, and IP blocks to get unrestricted Indeed data.
Choosing the right technology stack
Indeed, a high-friction target: basic HTTP clients, such as Requests, often encounter CAPTCHAs or login walls before any job data appears, and vanilla Playwright, Puppeteer, or Selenium setups are easily fingerprinted. We’ll use SeleniumBase (over plain Selenium) for its built-in antidetect capabilities:
- Stealth modes (UC/CDP) for high-friction sites.
- UC mode (based on undetected-chromedriver) to minimize detection.
- User-agent handling and Chromium flags; optional selenium-stealth integration for deeper fingerprint masking.
- Antidetect helpers (disconnect/reconnect flows, incognito mode, CAPTCHA helpers).
- Simplified API for common actions.
For targets like Indeed, these features strengthen stealth and enable more human-like interaction patterns. Pairing SeleniumBase with disciplined retry/backoff patterns helps bypass CAPTCHAs and provides a durable baseline for collection.
We’ll cover additional techniques for scaling Indeed job scraping later in this guide. For a deeper dive into bypass strategies, see our pro tips on navigating anti-bot systems.
Building Indeed scraper – step-by-step implementation
Let’s build a scraper that works reliably on Indeed’s listings – step by step.
Step 1 – installation and setup
Make sure you have Python 3 or a later version installed. If not, download it from the official Python website. Use a virtual environment to isolate dependencies:
The inscriptis library converts HTML snippets (job description snippets) into clean text.
Create an indeed_scraper.py file in your editor, and you're ready to build.
Step 2 – import dependencies
Import the libraries needed for browser control, text parsing, and data handling:
These are standard libraries for JSON handling and regex, urllib.parse for URL encoding, typing hints for code clarity, random for delay generation, SeleniumBase for browser automation, and inscriptis for clean text extraction from HTML.
Step 3 – class initialization
Set up the scraper class with configuration, methods, and regex patterns:
A regex constant is used to capture embedded job data and regional support for building correct base URLs like ca.indeed.com or uk.indeed.com.
Step 4 – set up the scrape
Orchestrate the main scraping loop to construct search URLs, iterate through pages, and collect results:
Use uc=True for undetected Chrome mode, headless=False for debugging visibility, and quote_plus for URL encoding. The start parameter handles pagination (0, 10, 20...), while built-in deduplication filters overlapping results.
Step 5 – anti-detection and retry logic
Build resilience with retry logic, exponential backoff, and human-like delays:
Combine exponential backoff with randomized delays, waiting for [data-jk] elements to load, and handling failures gracefully. Return empty results instead of crashing when all retries are exhausted.
Step 6 – extract job data
Target Indeed's embedded JSON data and extract the job listings:
Use regex to find the JavaScript variable containing job data, then safely navigate Indeed's nested structure with chained .get() methods. Handle JSON parsing errors gracefully without crashing.
Step 7 – processing and normalization
Transform Indeed's raw data into clean, structured job objects:
Filter for essential fields, clean HTML snippets with inscriptis, and build complete URLs.
Step 8 – save results
After scraping, results are saved as JSON.
Step 9 – usage example
This implementation accepts flexible parameters, including region codes (e.g., in, ca, au), job keywords (e.g., content manager, AI engineer), location targeting (e.g., city, state, remote positions), radius, and page limits. Since each page yields 15 job listings, the max_pages parameter controls the scope of your extraction.
Complete code
Here's the complete implementation combining all the steps:
Run the code using python indeed_scraper.py, and you'll see the browser open and start scraping jobs from multiple pages. It saves the JSON data to your project directory, looking like this:
You've built a functional Indeed scraper that navigates result pages and collects structured data. Next, we'll explore advanced techniques to make the scraper more resilient and harder to detect.
Scaling up scraping operations
The basic scraper works, but scaling introduces anti-bot defenses. If you’re only fetching a handful of pages, your script is fine. However, when you need to collect hundreds of thousands of job listings across multiple locations on a regular basis, scaling up becomes essential. Here’s how to prepare for large-scale scraping.
Use proxies
Proxies are the foundation of large-scale scraping. By routing traffic through rotating residential proxies, requests appear to originate from real devices worldwide. This distributes requests across diverse user footprints, reducing automation signals.
Key advantages:
- Rotation – IPs change automatically per request or session, minimizing detection patterns.
- Geographic flexibility – match IPs to the target’s Indeed domains.
- Anonymity and stability – mask your origin while maintaining high success rates.
Not all proxies deliver. Some are slow, easily blocked, or insecure. Before deploying at scale, test proxies to confirm performance and reliability.
For production workloads, proxy rotation is critical. Premium providers like Decodo offer 115M+ residential IPs with geo-targeting and automatic rotation. Setup takes only a few steps via Decodo’s residential proxies quick-start guide or this 2-minute video. Once configured, route your scraper through proxies aligned to the Indeed domains you’re targeting.
Use a Web Scraping API for tough cases
Even with proxies and careful throttling, tough targets like Indeed can trigger CAPTCHAs, rate limits, or fingerprinting. When this happens, it’s often more efficient to use an Indeed Scraper.
Decodo’s Indeed Scraper abstracts away the hardest parts of scaling:
- Automatic proxy rotation
- Built-in CAPTCHA solving
- JavaScript rendering
- Retries on failures
With a single API call, you can reliably fetch an Indeed page. The API shifts the heavy lifting – including headless browsers, IP pools, and concurrency – into the cloud, allowing you to focus on data rather than infrastructure. It also uses 100% success-based billing – you only pay for successful scrapes.
For developers, the API includes code examples, monitoring dashboards, and structured outputs. Setup requires only a few steps through the Web Scraping API quick-start guide.
Conclusion
This guide walked through building an Indeed scraper step by step and showed how to scale from small projects to production workloads. Reliable large-scale scraping combines two core strategies: starting with residential proxies to distribute requests, and transitioning to a Web Scraping API when challenges become too complex. Together, these tools provide the reliability, coverage, and scale required for enterprise-grade data collection.
Further reading
To continue learning and stay current, explore these resources:
- Tutorials and blogs. Explore Decodo’s articles for guides on scraping techniques, scaling data collection, AI-driven workflows, and strategies for bypassing anti-bot systems.
- AI for scraping. Discover how Claude and ChatGPT enhance productivity throughout your scraping workflow.
- MCP integration. Explore the Decodo MCP Web Scraper to see how Model Context Protocol (MCP) connects with tools like Cursor, VS Code, and Claude Desktop to extend scraping workflows.
- Comparison of providers. If you’re evaluating vendors, review Decodo’s web scraping services comparison to make an informed choice.
- Best practices. Follow web scraping best practices to ensure efficiency, compliance, and reliability.
About the author

Zilvinas Tamulis
Technical Copywriter
A technical writer with over 4 years of experience, Žilvinas blends his studies in Multimedia & Computer Design with practical expertise in creating user manuals, guides, and technical documentation. His work includes developing web projects used by hundreds daily, drawing from hands-on experience with JavaScript, PHP, and Python.
Connect with Žilvinas via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.