How to Web Scrape a Table with Python: a Complete Guide
HTML tables are one of the most common ways websites organize data – financial reports, product listings, sports scores, population statistics. But this data is locked in the webpage's layout. To use it, you need to extract it. This guide will show you how to do it using Python, starting with simple static tables and working up to complex dynamic ones.
Justinas Tamasevicius
Last updated: Nov 10, 2025
9 min read

Understanding HTML tables
Before you can scrape a table, you need to understand its structure. HTML uses tags to organize content. To see this, visit any webpage with a table, right-click it, and select Inspect (check out our guide on how to inspect elements if you need help).
You only need to know 4 tags:
1. <table> – the entire table container (think: the whole spreadsheet file)
2. <tr> – "table row" – a single row (like one row in a spreadsheet)
3. <th> – "table header" – a header cell (column titles like "Name" or "Price")
4. <td> – "table data" – a data cell (individual values like "$19.99")
Tables are nested: a <table> contains <tr> (rows), which contain <th> (headers) and <td> (data). Understanding this structure is important for choosing the right CSS or XPath selectors later.
Prerequisites
You'll need Python installed and a few libraries:
- Requests – send HTTP requests to download web pages
- BeautifulSoup4 – parse HTML into searchable objects
- Pandas – organize scraped data into tables and export to CSV/Excel
- lxml – a fast parser that pandas.read_html needs to read the HTML
- Selenium – automate browsers for JavaScript-heavy sites
To install all of them, open your terminal (or command prompt) and run the following command:
We'll use requests and BeautifulSoup for static sites, and Selenium when you need to scrape dynamic content.
How to scrape static HTML tables
A static table has all its data in the initial HTML – no JavaScript loading required. There are two ways to scrape them.
Method 1 – the easiest way (pandas.read_html)
For simple static tables, pandas has a function that does the heavy lifting: read_html().
This function scans HTML, finds all <table> tags, and converts them into a list of pandas DataFrames.
Here's what the console output looks like when you run the script:

Method 2 – the manual way (BeautifulSoup)
Sometimes pandas.read_html fails, or you need more control. Here's the manual approach using Beautiful Soup.
We'll scrape the same Wikipedia page in 5 clear steps.
Step 1: Fetch the web page
Use requests to download the page's HTML.
Step 2: Parse HTML with BeautifulSoup
Pass the raw HTML to BeautifulSoup to create a searchable object.
Step 3: Locate and extract the table
Right-click the table in your browser and select Inspect. You'll see it has a class attribute of "wikitable".
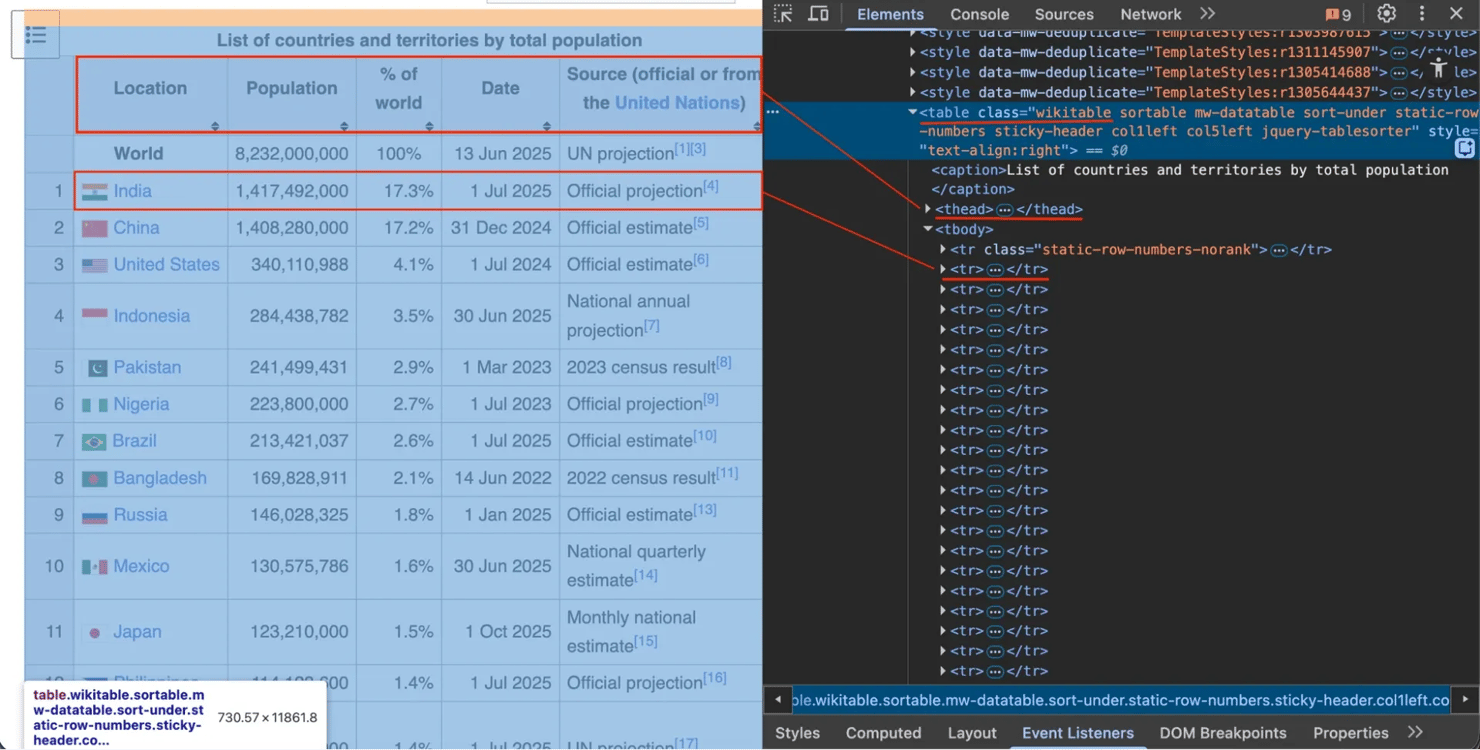
Use this class to find the table, then extract all headers (<th>) and rows (<tr>).
Step 4: Convert data to a pandas DataFrame
Convert your list of lists into a structured DataFrame.
A pandas DataFrame is a powerful, in-memory table, similar to a spreadsheet. While our all_rows variable is just a Python list of lists, converting it to a DataFrame allows us to easily label the data with our headers, clean it, analyze it, and, most importantly, export it to formats like CSV or Excel with a single command.
Step 5: Save the data
Export your DataFrame to CSV.
The final CSV file will look like this:
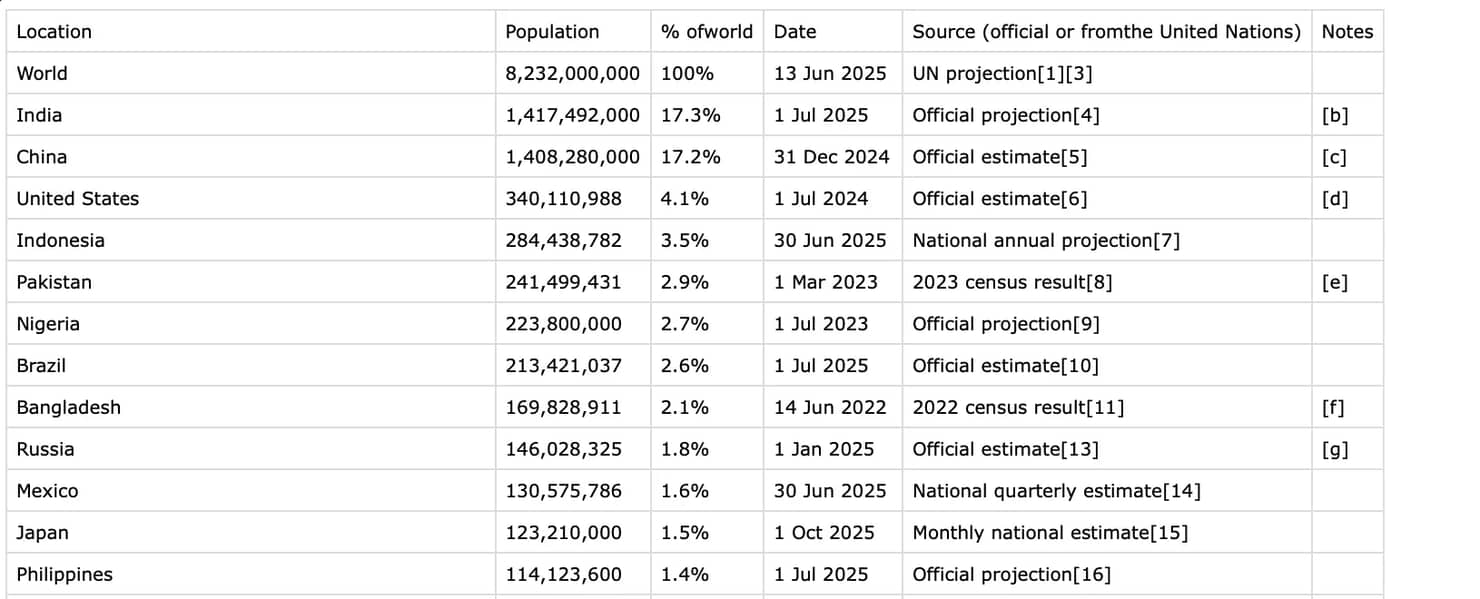
This method uses all of the basic fundamentals of Python web scraping and gives you complete control. You can further modify the code to only extract specific rows or columns, or filter for relevant data.
Quick tip – always try method 1 first. It's fast and simple. If it fails or you need more control, use method 2.
Handling complex table structures (colspan and rowspan)
Some tables have merged cells using colspan (spanning multiple columns) or rowspan (spanning multiple rows).
The issue – a simple loop will put data in the wrong columns.
The fix – try pandas.read_html first. It's often smart enough to correctly parse tables with colspan and rowspan automatically.
Let's take the comparison of web browsers page. The row that mentions "Arora" browser uses rowspan to span 6 rows:
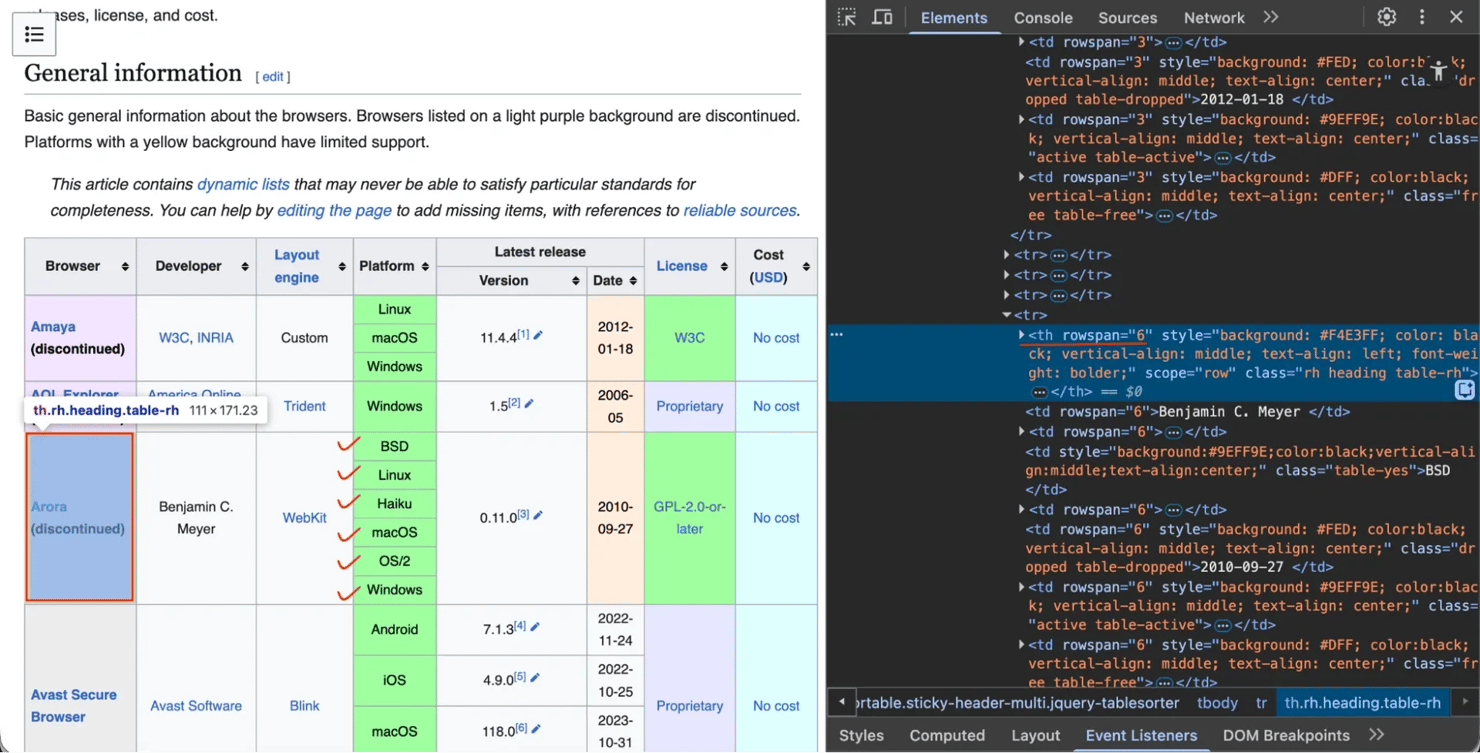
And the "Latest release" header uses colspan to span 2 columns ("Version" and "Date"):
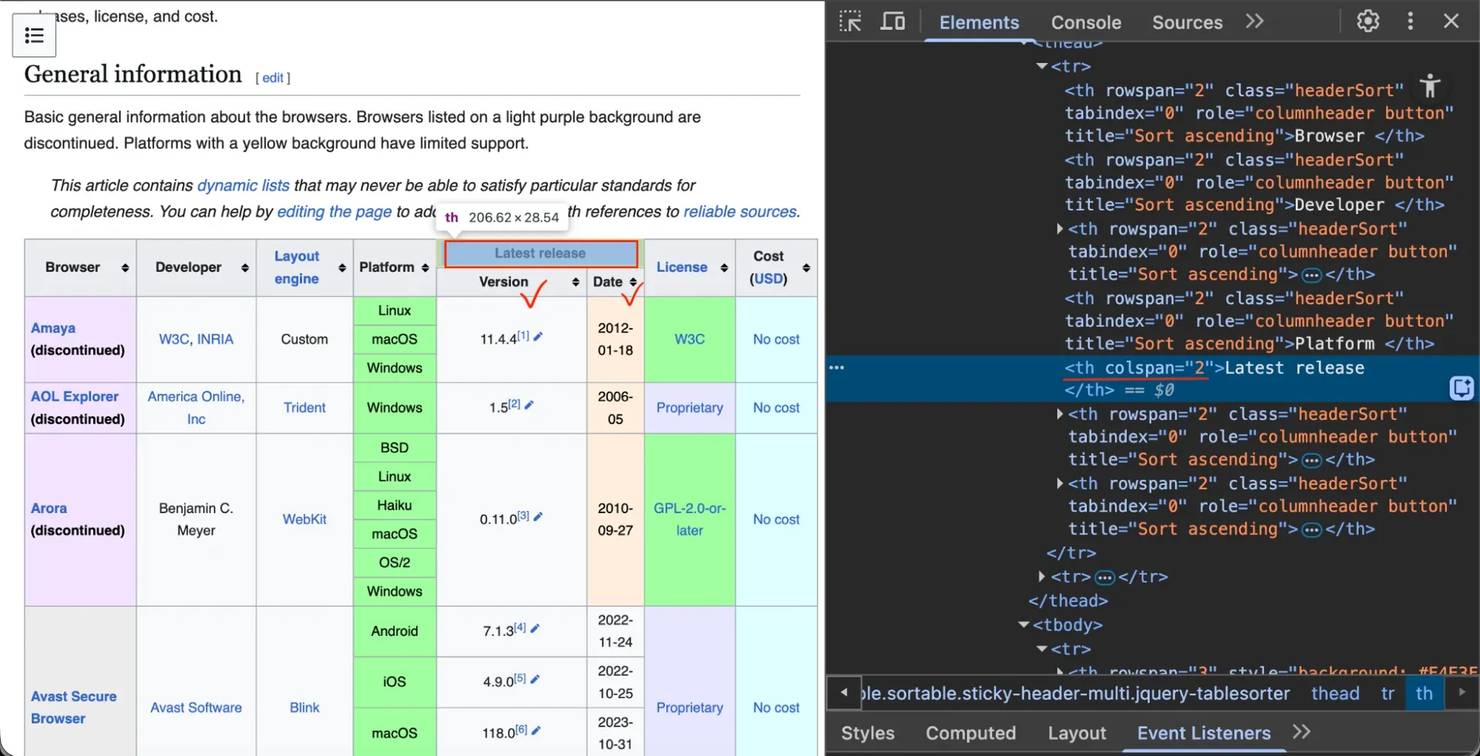
Let's see if pandas can handle it.
And then you'll get the CSV with successfully flattened complex headers and rows.
When pandas.read_html (Method 1) fails on a complex table, you can use a specialized library like html-table-extractor. Its primary purpose is to correctly parse complex tables, automatically expanding merged cells to build a clean, rectangular grid of data.
First, you'll need to install it:
Here is the code combining BeautifulSoup to find the table and html-table-extractor to parse it:
Cleaning and saving your data
Raw scraped data is usually messy. For example, in the DataFrame we created in Method 2 (BeautifulSoup), the Population column contains strings like "1,417,492,000". Because that's a string, not a number, you can't perform calculations with it. Let's clean it.
You can add the following lines to your Method 2 script to clean the data. This code continues directly from the df variable you created earlier:
Once clean, save your data. For more formats (JSON, databases, etc.), check out our guide on how to save your scraped data.
How to scrape dynamic (JavaScript) tables
You run your scraper, but the table data is empty. You inspect the HTML and see "Loading..." or an empty <div>. This happens because the website loads data dynamically with JavaScript. requests.get() only retrieves the initial HTML – it doesn't execute JavaScript. If the table data loads after the page renders, your scraper won't see it.
Solution #1: Find the hidden API
Many sites load data through background API requests. You can intercept this API and request the data directly:
- Open Developer Tools (F12) in your browser
- Go to the Network tab – filter by Fetch/XHR
- Reload the page
- Look for requests returning JSON data (that's your table content)
Financial sites like Google Finance and Google Finance commonly use this pattern. In the image below, you can see the Fetch/XHR tab capturing a request that returns clean JSON data.
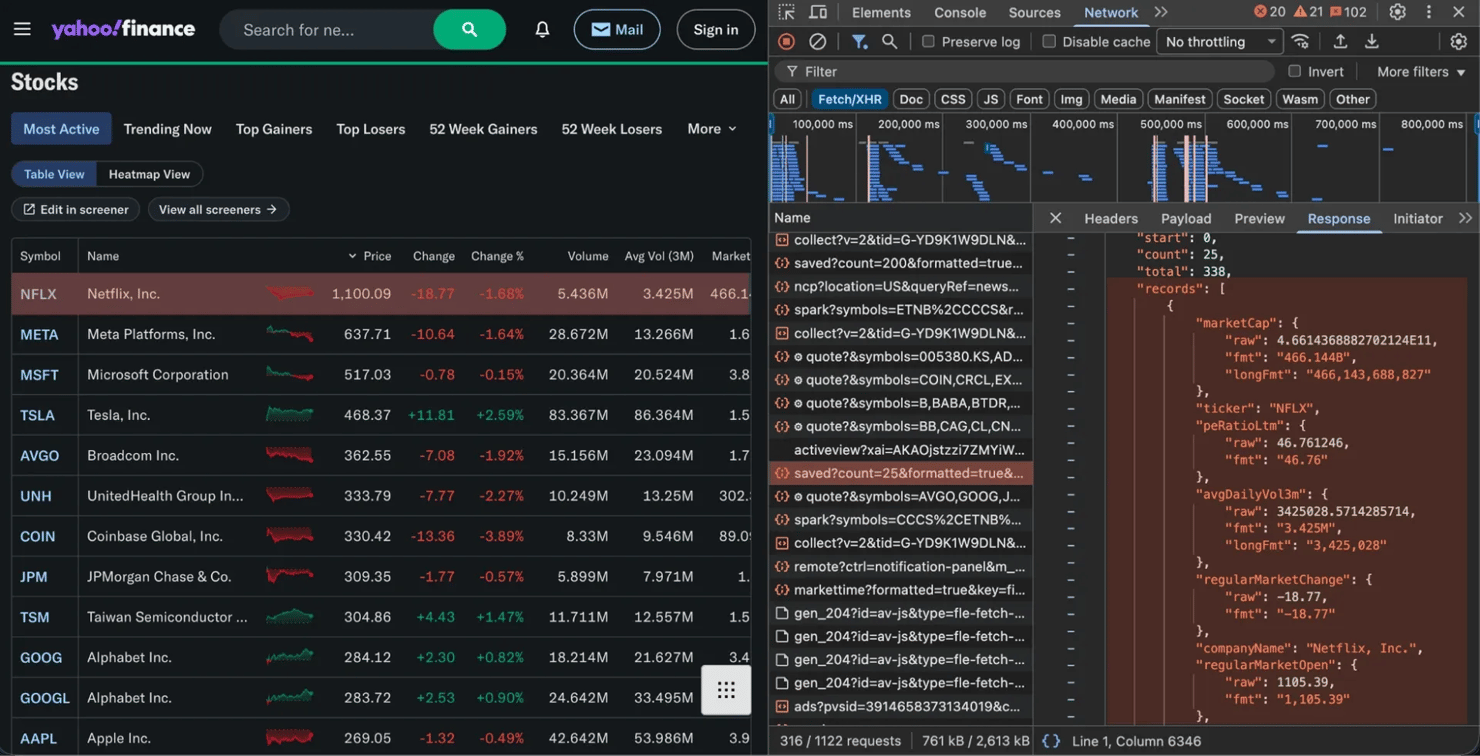
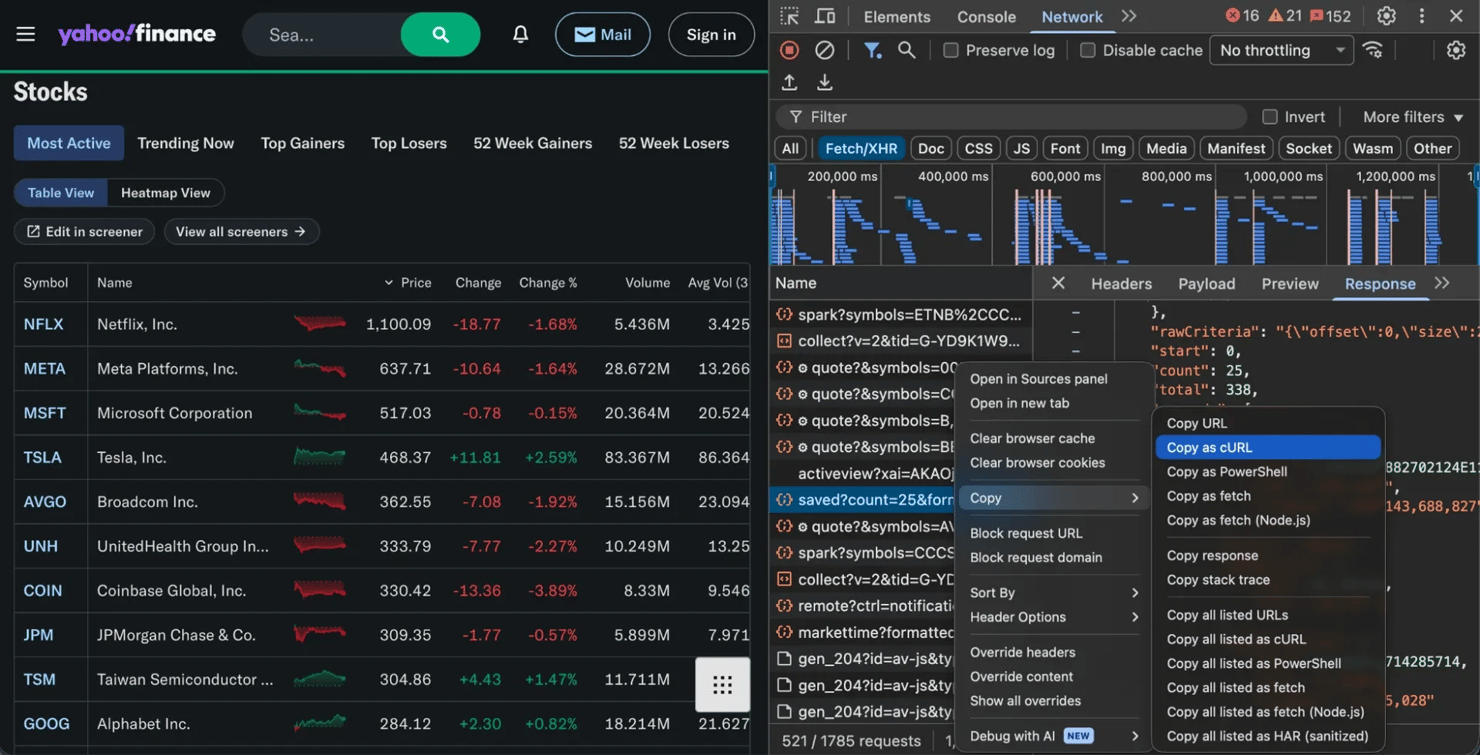
Once you find the right request, right-click it and select Copy as cURL (or note the URL, headers, and parameters). You can then recreate that request in Python.
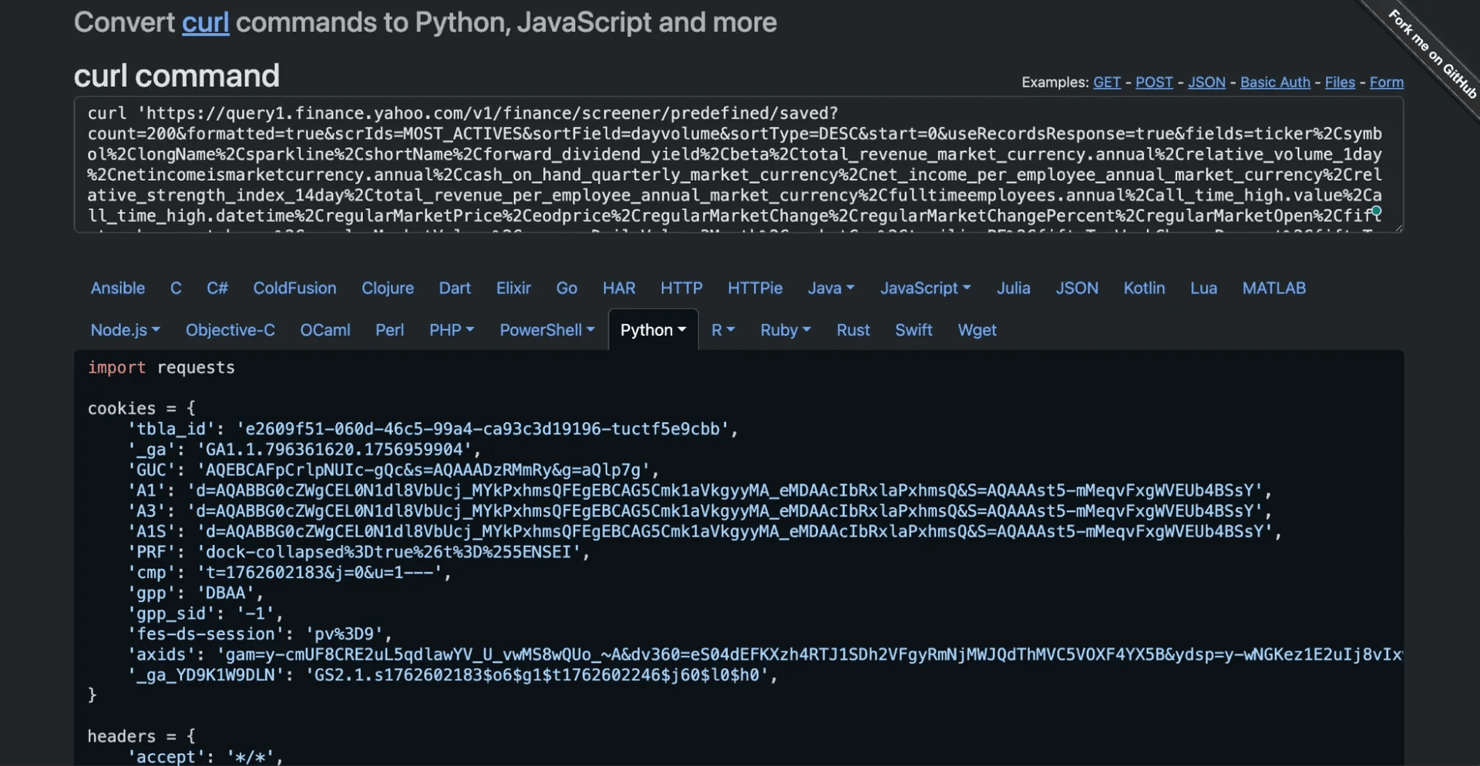
A pro tip for converting that "Copy as cURL" command into Python is to use an online tool like the curl converter. You can paste the entire cURL command, and it will automatically generate the equivalent code using the requests library.
Running this code will print the clean JSON data, which will look something like this:
Important note: If your request fails or you get no data, the website is likely blocking your script. To get around this, you need to make your request look more like a real user. We cover the techniques for this in the "Best practices and ethical considerations" section later in this guide.
Solution #2: Use a headless browser
If there's no API to target, you'll need to automate a real browser to render the JavaScript. This is called a headless browser when run on a server. Tools like headless browser will:
- Open a real browser (like Chrome)
- Wait for the JavaScript to execute and the table to load
- Give you the final rendered HTML to parse
This is also the only way to handle dynamic pagination – when you need to click Next buttons that trigger JavaScript. We'll cover that in the next section.
This approach is slower and more resource-intensive than direct API requests, so always check for hidden APIs first.
How to scrape paginated tables
Tables are often split across multiple pages ("page 1", "page 2", etc.). The key is figuring out how the "Next" button works.
Case #1: Static pagination
What to look for – click "Next" and check if the URL changes (e.g., to /?page=2). If it does, you're dealing with a static site.
Solution – use requests in a loop. Take CoinMarketCap as an example. It uses URLs like /?page=2, /?page=3. If you inspect the "Next" button, you'll see it's just a simple link (<a> tag) with a static href attribute.
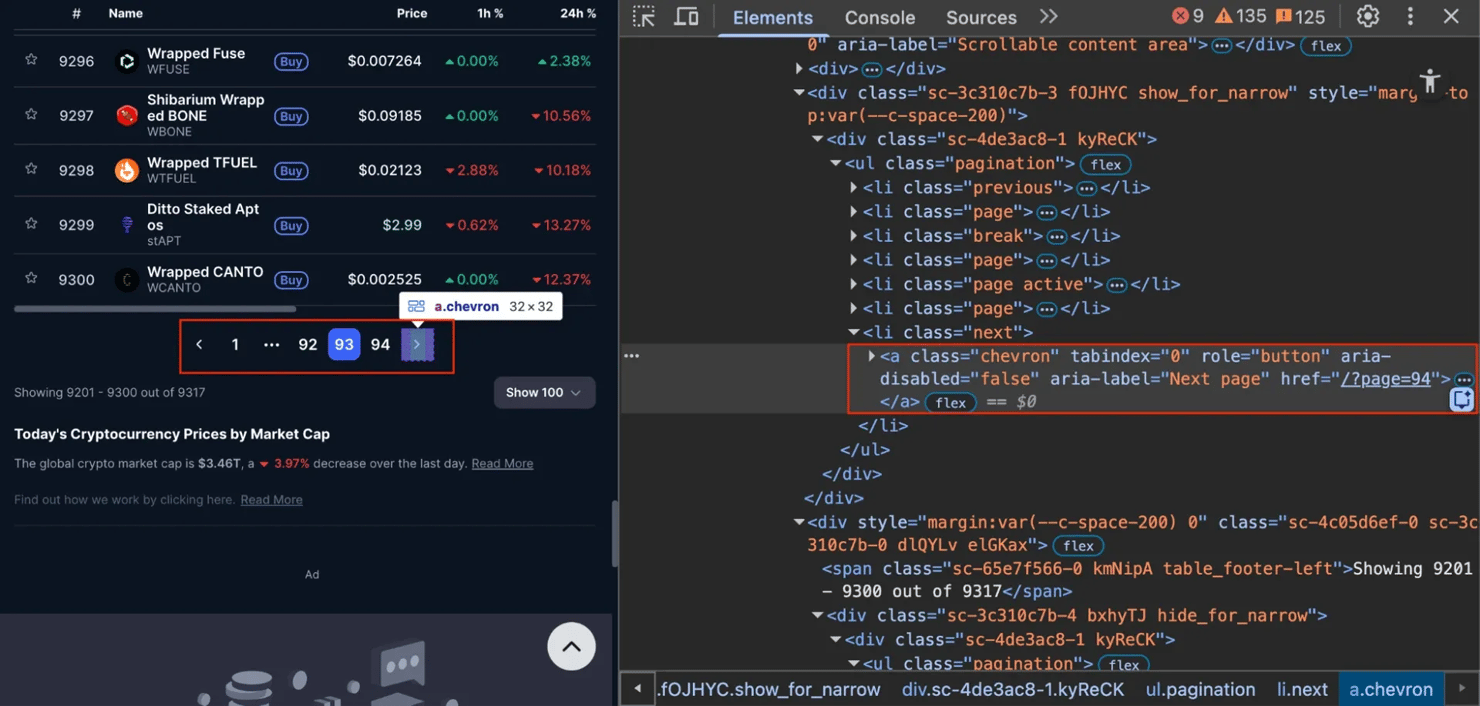
Because the URL is simple and predictable, you can scrape it with requests and pandas loop:
Case #2: Dynamic pagination
What to look for – click "Next" and check if the URL stays the same, but the table content changes. This means the site uses dynamic pagination.
Solution – use a headless browser like Selenium to simulate clicking the "Next" button.
Let's scrape Datatables as an example. This page loads its data and pagination using JavaScript.
This same logic can be applied using other modern tools like Playwright for web scraping.
The modern method: Can't AI scrape tables?
This is the most common question today, and the short answer is "yes, but with caveats".
AI as a co-pilot
AI chatbots are great for generating code. Copy a table's HTML, paste it into ChatGPT or Claude, and ask it to write a BeautifulSoup script. You'll get working code in seconds instead of writing it manually. You can learn more about using ChatGPT for web scraping or Claude for web scraping in our other guides.
But chatbots have limits. They write code – they don't run it for you. They can't render JavaScript, manage proxies, or handle getting blocked. And when a website changes its HTML (which happens constantly), the code breaks.
AI as the scraper itself
A real AI scraping solution doesn't just generate code – it understands the page structure and adapts to changes. Instead of writing brittle CSS selectors like soup.find(class_="wikitable"), you tell it what data you want in plain English.
That's what Decodo's AI Parser does. It's one of the best AI data collection tools because it stays resilient when websites change. For more on this approach, see how Decodo handles AI data collection.
Best practices and ethical considerations
Scraping is powerful, but you need to be respectful. Hammering a server with hundreds of requests per second will get you blocked fast. Here's how to scrape responsibly (and avoid getting banned):
- Check robots.txt first. Most websites have a file at website.com/robots.txt that states rules for bots. We have a full guide on how to check if a website allows scraping.
- Respect terms of service (ToS). The ToS is a legal document. Review it to ensure you aren't violating policies, especially for commercial use. This helps answer the question, "is web scraping legal?".
- Use a proxy network. Your home IP address is a dead giveaway to a website. After 10 or 100 requests, you will get blocked. A proxy, especially from a residential proxy network, routes your request through a different, real device, making you look like a regular, unique user every time. This is the key to reliable scraping at scale.
- Use a User-Agent. As shown in our examples, a User-Agent string makes your request look like it's from a browser, not a script. This bypasses many basic anti-bot systems.
- Add delays between requests. Add time.sleep(2) inside your loops. This is polite to the server and makes you look less like a bot. (You can even build a Python requests retry system to handle this automatically.)
Troubleshooting common issues
The most common error is AttributeError: 'NoneType' object has no attribute 'find'. This is probably the most common scraping error. It means you tried to call a method on None, which happens when your selector doesn't find anything.
The fix – check the line before the crash. Your soup.find() returned None because it didn't match anything. Double-check your selector for typos or inspect the actual HTML to see what the class name really is.
Other common issues
Here are some common scraping errors and fixes:
- 404 Not Found. Your URL is wrong, or the page doesn't exist. Check for typos.
- 403 Forbidden. The server is blocking you. Add a User-Agent header to look like a browser. If that doesn't work, you need a proxy to hide your identity.
- 429 Too Many Requests. You're scraping too fast. Add time.sleep(2) between requests to slow down. If you still get blocked, use a proxy network to rotate your IP address.
- Empty data / missing content. The data is probably loaded with JavaScript. Use your browser's Network tab to find the hidden API endpoint, or switch to headless browser automation tools to wait for the page to fully load.
Bottom line
You've learned how to scrape tables in Python – from simple pandas one-liners to complex Selenium setups. These tools work great for small projects and learning.
But scrapers are fragile, and websites change their HTML constantly. Scaling to thousands of pages means dealing with proxies, headless browsers, and CAPTCHAs. If that sounds tedious, there's another option.
Instead of building and maintaining scrapers yourself, you can use the Decodo Web Scraping API. Send a URL, the API handles the messy stuff (proxies, JavaScript rendering, anti-bot measures), and you get clean JSON back.
Plus, you can integrate with LangChain and n8n if you're building AI agents or automation workflows.
Try Web Scraping API for free
Collect real-time data without a single line of code – start your 7-day free trial today.
About the author

Justinas Tamasevicius
Director of Engineering
Justinas Tamaševičius is Director of Engineering with over two decades of expertise in software development. What started as a self-taught passion during his school years has evolved into a distinguished career spanning backend engineering, system architecture, and infrastructure development.
Connect with Justinas via LinkedIn.
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.