Data Collection
The process of data collection is vital in all kinds of industries. It helps businesses learn about the market, know their customers better and adapt to their needs. Data collection can be automated by scraping a set target. It’s extra useful for analyzing business competition, records, trends, and other data.
14-day money-back option


Web Scraping With Perl: A Step-by-Step Guide for 2026
Web scraping with Perl is popular for elite text processing and superior execution speed. Perl has first-class regex built right into the language, no imports, no setup, which makes extracting structured data fast and precise. In this guide, you'll go from a Perl HTTP request to a scraper that fetches and parses web data, handles sessions, and exports data.
Justinas Tamasevicius
Last updated: Jul 22, 2026
21 min read

How to Set Up an Apache Proxy Server: Forward, Reverse, and Scraping Use Cases
An Apache proxy server can work in two directions. As a forward proxy, it sits between your client and the internet, hiding who's making the request. As a reverse proxy, it sits in front of your backend servers, hiding what's running behind them. Apache HTTP Server handles both well, and it's already installed on most Linux boxes, has a mature module ecosystem, and costs nothing. This guide walks you through setting up both modes from scratch, configuring a reverse proxy in front of Tomcat, and routing Selenium scraper traffic through your forward proxy.
Zilvinas Tamulis
Last updated: Jul 21, 2026
19 min read

Best Web Scraping Proxies in 2026: Providers, Types, and How To Choose
The best web scraping proxies stop your scraper from getting rate-limited, CAPTCHA-walled, or banned outright. Pick the wrong one and the blocks start within minutes. What works depends on your target, your scale, and your budget. This guide walks through the proxy types, how to choose, the providers worth knowing, and how to actually run them.
Benediktas Kazlauskas
Last updated: Jul 21, 2026
8 min read
What is SOCKS Proxy?: Definition, Benefits & Use Cases
A SOCKS proxy is an internet protocol that routes network traffic through a third-party server and masks your IP address. It operates at the transport layer, handling any traffic type – TCP, UDP, web, gaming, torrenting, and more – without inspecting or modifying the data. In this blog entry, we’ll cover the ins and outs of SOCKS proxies, including how they work, key benefits, use cases, and how they compare against HTTP proxies.
Dominykas Niaura
Last updated: Jul 17, 2026
10 min read

Web Scraping with Linux and Bash
Web scraping with Linux is more capable than most people expect. Bash may not be the go-to tool for web scraping, but with a handful of pre-installed command-line utilities you can build a working scraper without touching Python or a browser. This guide covers how to make HTTP requests in Linux, parse into HTML and JSON, set up proxy support with Decodo, and build a fully working Bash-based scraper from scratch.
Vilius Sakutis
Last updated: Jul 16, 2026
25 min read

How to Scrape Perplexity: Methods, Tools, and a Python Tutorial
Perplexity is slowly becoming one of the more prominent LLMs in 2026 because it delivers output in a unique way that sets it apart from the rest. When you send a prompt, Perplexity AI will return a direct answer, along with cited sources (URLs and titles), related follow-up questions to that prompt, and supporting images as well. All this information can be worth tracking for businesses that care about their brand visibility, and how Perplexity is representing them and their competitors to a typical user.
Mykolas Juodis
Last updated: Jul 14, 2026
16 min read
JavaScript vs. Python: Which Is Better for Web Scraping in 2026?
Python and JavaScript are 2 languages that dominate web scraping, but for different reasons. The real question isn't which language is "better," but rather what task you're building for. This article compares both languages in terms of libraries, performance, support for dynamic content, and anti-bot strategies, while also showing why the overall architecture matters more than your language choice.
Justinas Tamasevicius
Last updated: Jul 14, 2026
8 min read

Playwright Get Cookies: How to Get, Save, and Load Cookies in Playwright
When you need to get cookies in Playwright and reuse them across runs, the key concept is the browser context. Cookies live in the context, not the page. Getting cookies in Playwright starts with the context.cookies() method, and returns every cookie stored in the browser context, which you can save and load from a file later. This guide walks through how to get, save, and load cookies in Playwright.
Mykolas Juodis
Last updated: Jul 14, 2026
5 min read

Playwright Stealth: Configure Anti-Detection for Web Scraping in Python and Node.js
Headless browsers in Playwright can leak fingerprint signals that anti-bot systems notice. While Playwright is great for automation, its default settings make these signals easy to spot. Stealth plugins help cover these leaks so your scripts look like real user traffic. This guide explains detection methods, how to set up stealth in Python and Node.js, what gets patched, how to test, and the limits and scaling options.
Kipras Kalzanauskas
Last updated: Jul 13, 2026
11 min read
Playwright Wait for Page to Load: A Guide to Every Waiting Method
Knowing how to wait for a page to load in Playwright is the difference between a scraper that returns clean data and one that fails silently. In this guide, you'll learn how to handle waiting in Playwright, including how it behaves in a headless browser environment, covering auto-waiting, selectors, network events, timeouts, custom conditions, and error handling across dynamic pages.
Dominykas Niaura
Last updated: Jul 13, 2026
6 min read
undetected ChromeDriver in Python: Avoid Bot Detection When Web Scraping
Undetected ChromeDriver is a Python library that patches Selenium’s ChromeDriver to avoid bot detection when web scraping. Standard Selenium ChromeDriver is blocked by most protected websites within the first few requests: anti-bot services like Cloudflare, DataDome, and HUMAN (formerly PerimeterX) read automation flags, WebDriver properties, and browser-fingerprint gaps before the first page finishes loading. The undetected_chromedriver library works as a drop-in Selenium WebDriver replacement (swap webdriver.Chrome() for uc.Chrome()) and reduces those signals. But it does not hide your IP address, so this guide also shows how to pair it with residential proxies and behavioral techniques to stay unblocked.
Justinas Tamasevicius
Last updated: Jul 13, 2026
18 min read
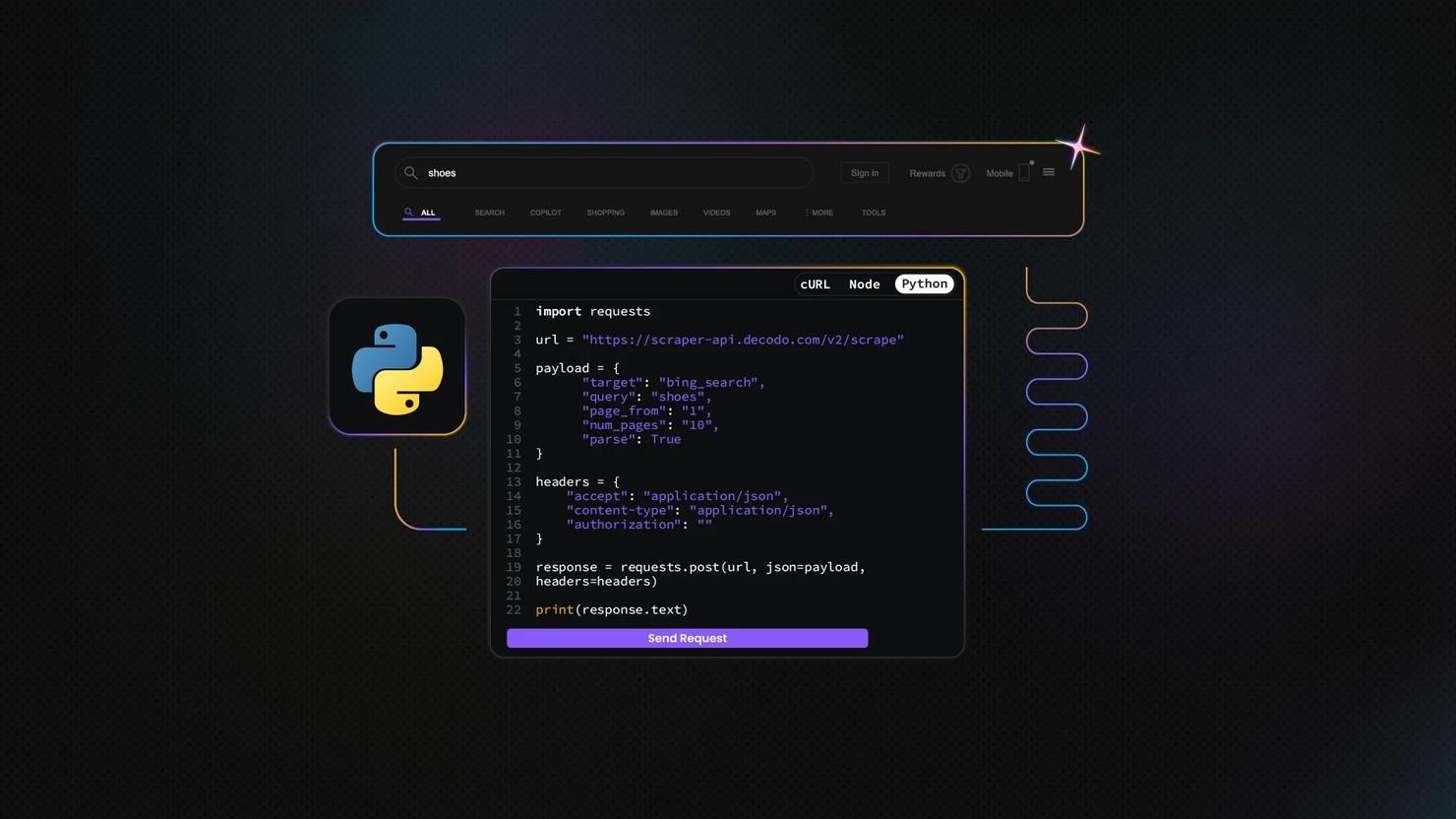
How to Scrape Bing Search with Python
Bing scraping is the automated extraction of rankings, ads, snippets, and search features from Bing's SERPs. Since Microsoft retired all official Bing Search APIs in 2025, scraping and third-party SERP APIs are the main ways to access this data programmatically. This guide covers Python-based approaches using Requests, Beautiful Soup, Playwright, and Decodo's Web Scraping API.
Zilvinas Tamulis
Last updated: Jul 13, 2026
12 min read

How To Scrape JSON Data in Python: Complete Tutorial
JSON is the format that most web APIs and modern websites use to send their data. This tutorial shows how to scrape JSON data in Python – fetching it, parsing it, modifying it, and exporting clean files. You'll also learn about the tools for messy or oversized responses, and how to get data when sites block you with fingerprinting.
Justinas Tamasevicius
Last updated: Jul 03, 2026
19 min read
Scrapy With JavaScript: How To Scrape Dynamic Sites Without Losing Your Pipeline
Scrapy is an asynchronous Python framework for crawling and extracting data at scale, but it doesn't execute JavaScript on its own. A spider can get a clean 200 response and still return empty selectors on a modern site. This guide covers the rendering options (Splash, Selenium, Playwright, managed APIs) and the cache and concurrency settings that matter once browser rendering comes into play.
Vilius Sakutis
Last updated: Jul 01, 2026
14 min read

How to use a proxy with Ruby: configure, authenticate, and rotate with Net::HTTP and Faraday
As a Ruby developer, you must have used proxies for multiple applications, including web scraping, API integration, and geo-targeted testing. Without a proxy, every request leaves from the same IP, which is the fastest way to get rate-limited or blocked. In this guide, you'll learn how to configure a Ruby proxy with Net::HTTP and Faraday, add authentication, rotate IPs, and connect Ruby applications to Decodo residential proxies.
Justinas Tamasevicius
Last updated: Jun 26, 2026
7 min read
Puppeteer in Python With Pyppeteer: Setup, Scraping, and 2026 Alternatives
Pyppeteer is an unofficial Python port of Puppeteer, the Node.js library that drives headless Chromium through the DevTools Protocol. It brings the same async model to Python for clicking, filling forms, waiting, and scraping JavaScript-heavy sites. It works, but it's no longer the 2026 default. This guide covers using it and when to switch to Playwright or nodriver.
Lukas Mikelionis
Last updated: Jun 18, 2026
10 min read
Crawlee Python: Complete Tutorial with Beautiful Soup, Playwright, and Proxies
Building reliable web scrapers can get complex and difficult to maintain, but Crawlee aims to simplify the process. As project needs grow, developers often encounter challenges that require multiple tools and configurations. Crawlee eliminates the need to build these configurations from scratch or migrate to a different tool mid-crawl, allowing you to focus on your scraping logic instead. In this guide, you'll learn how to scrape using Crawlee's 3 main crawler classes. We'll also explore the routing architecture, proxy integration with Decodo, and data storage.
Kipras Kalzanauskas
Last updated: Jun 16, 2026
15 min read
Python Cloudscraper: Bypass Cloudflare Protection, Configure Proxies, and Handle Common Errors
Most Python scrapers that use Requests stop working as soon as a site is protected by Cloudflare. You might see a 403 error, get stuck in a redirect loop, or land on a "Just a moment..." page that never loads. Cloudscraper solves this problem without needing a headless browser. It builds on Requests, handles Cloudflare's JavaScript challenges, and gives you a working session. This guide explains how to set up Cloudscraper, configure proxies, choose an interpreter, handle CAPTCHAs, parse data, fix common errors, and understand the library's limitations. If you're new to Python scraping, start with the Python web scraping guide first.
Mykolas Juodis
Last updated: Jun 16, 2026
17 min read